概览
首先说下 BLOB 的意思, 英文全称是 Binary Large OBjects,可以理解为任意二进制格式的大对象;在 Facebook 的语境下,也就是用户在账户里上传的的图片,视频以及文档等数据,这些数据具有一次创建,多次读取,不会修改,偶尔删除 的特点。
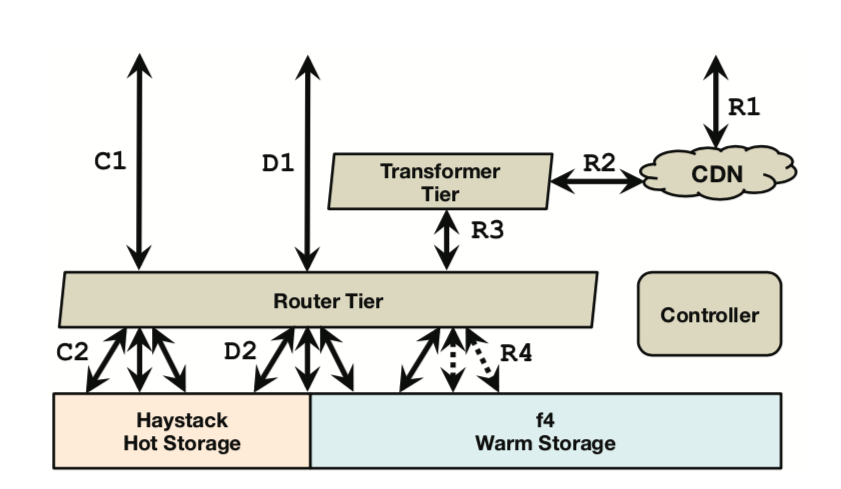
之前简单翻译了 Facebook 的前驱之作 —— Haystack,随着业务量发展,数据量进一步增大,过去玩法又不转了,如果所有 BLOG 都用 Haystack 存,由于其三备份的实现,在这个量级下,性价比很低。但是完全用网络挂载+传统磁盘+Unix-like(POSIX)文件系统等冷存储,读取跟不上。于是计算机科学中最常用的分而治之的思想登场了。
他们首先统计了 BLOBs 的访问频次与创建时间的关系,然后提出了随着时间推移 BLOB 访问出现的冷热分布概念(和长尾效应差不多)。并据此提出了热、温分开的访问策略:用 HayStack 当做热存储去应对那些频繁访问的流量,然后用 F4 去响应剩下的不那么频繁访问的 BLOB流量,在此假设(F4只存储那些基本不怎么变动,访问量相对不大的数据)前提下,可以大大简化 F4 的设计。当然有个专门的路由层于两者之上进行了屏蔽,并进行决策和路由。
对于 Haystack 来说,从其论文出来时,已经过去了七年(07~14)。相对于当时,做了少许更新,比如说去掉了 Flag 位,在 data file,Index file 之外,增加了 journal file,专门用来记录被删除的 BLOB 条目。
对于 F4 来说,主要设计目的在于保证容错的前提下尽可能的减小有效冗余倍数(effective-replication-factor),以应对日益增长的温数据 存取需求。此外更加模块化,可扩展性更好,即能以加机器方式平滑扩展应对数据的不断增长。
我总结一下,本论文主要高光点就是温热分开,冗余编码,异地取或。