 ray-task-state-transfer.png
ray-task-state-transfer.png
之前文章写了 Ray 的论文翻译。后来我花了些时间读了读 Ray 的源码,为了学习和记忆,后续预计会出一系列的源码解析文章。为了做到能持续更新,尽量将模块拆碎些,以保持较短篇幅。另外,阅历所限,源码理解不免有偏颇指出,欢迎大家一块讨论。
作者:木鸟杂记 https://www.qtmuniao.com, 转载请注明出处
概述
Ray 核心的设计之一就是基于资源定制的细粒度、高吞吐的任务调度。为了实现这一点,Ray 将所有输入和输出存在基于共享内存的 Plasma 中;将所有状态存在基于 Redis 的 GCS 中,然后基于此进行去中心化的调度。即每个节点都可以拿到全局信息来进行局部调度决策,不过这也是不好做复杂调度策略的原因之一。
Ray 任务分为两种,无状态的 Task 和有状态的 Actor Method,后者又可以细分为 Actor Create Method (对应构造函数)和普通 Actor Method(对应成员函数)。
Ray 是可以显式指定任务的资源(主要是 CPU 和 GPU)约束的,因此需要对所有节点的资源在框架层进行量化(ResourcesSet),以感知增加,进行分配、实现回收等等。在调度时,需要找到满足任务资源约束的节点,将任务调度过去。
由于所有 Task 的输入存在分布式的内存存储 Plasma 中,因此将 Task 调度到某个节点之后,需要对所依赖的输入进行跨节点传输。或者直接将任务调度到满足依赖的节点上,但事实上 Ray 对于一般 Task 并没有这么做,后面会详细讲原因。对于 Actor Method 来说,由于其对应 Actor 常驻某个节点,其相关的所有 Actor Method 定会调度到该节点上。
上面所说的任务所在节点、当前的状态、依赖对象的位置等等信息,都是存在全局控制存储 GCS 中的。因此每次改变状态后,要和 GCS 交互将状态写入。在由于节点失联或者宕机导致任务失败时,会根据 GCS 存的任务的状态信息对任务进行重试。通过订阅 GCS 的某些状态的变化事件,可以驱动任务状态变化。
其他的还有根据 lineage + snapshot 进行快照恢复,Actor lineage 的构建等等,这里先卖个关子,后面系列文章会详细来说。
本文主要针对所有任务的状态转移和组织形式进行展开。
状态机
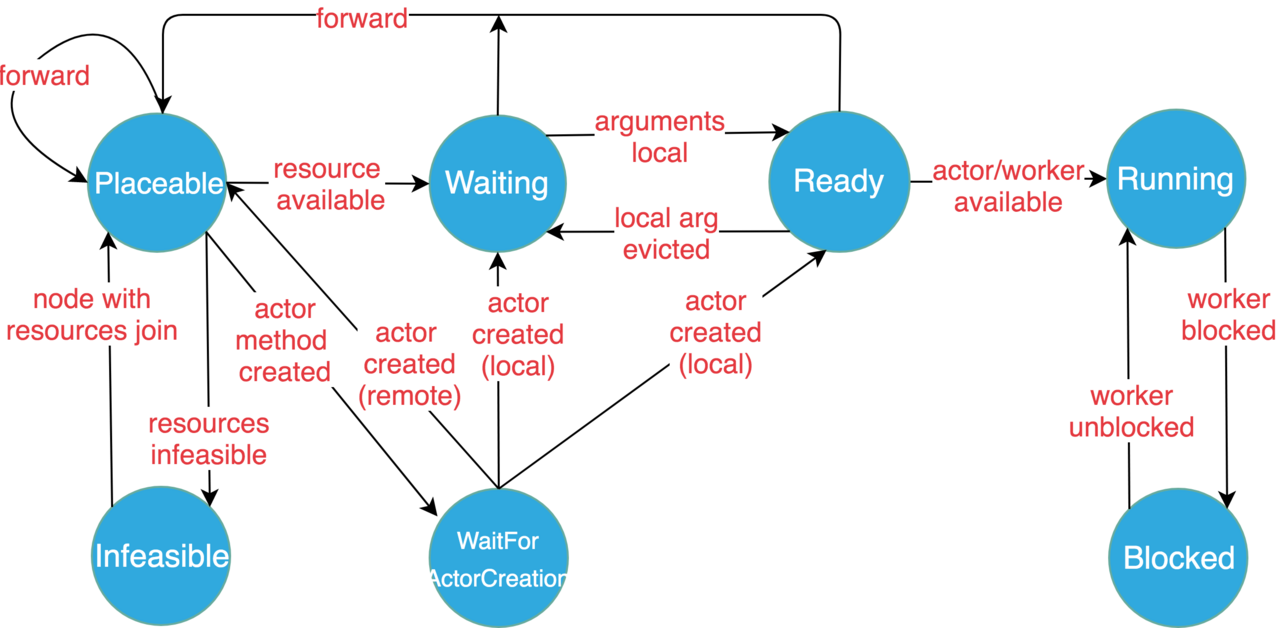
复杂的任务调度必然需要一个合理的状态机来描述。以下是 Ray 文档 给出的任务状态定义和转移图。
状态定义
- 可放置(Placeable): 任务准备好了被调度到某个节点上(本地或者远程)。调度决策主要是依据任务资源约束和节点剩余资源的匹配程度。当前没有考虑任务依赖对象的位置信息。如果本地节点满足任务资源需求,那么任务就被安排在本地进行执行,否则将会被转发(forward)到其他满足资源需求的节点。不过该状态决策不一定是最终决策,该任务稍后仍然可能被挤(spill over)到其他节点(因为调度那一刻满足资源,但是执行时,发现已经执行了其他任务,导致节点不满足资源约束了)。
- 等待Actor创建(WaitForActorCreation):一个 Actor Method 等待其 Actor 实例被创建(大多数发生在Actor 错误恢复时,否则一般来说是 Actor Create Method 先执行)。一旦 Actor 实例被创建,并且通过 GCS 被该 Actor Method 感知到,它就会被调度到 Actor 实例所在的节点。
- 等待(Waiting):任务等待其输入对象被满足,比如,等待任务函数参数对象从其他节点调度到本地的对象存储中。
- 就绪(Ready):任务所依赖的对象都在本地的对象存储中了,因此任务已经准备好在本地(指的是任务当前所在节点,下面也是)运行了。
- 运行(Running):任务已经调度到本地执行了,运行在本地的 Actor 或者 Worker 进程中。
- 阻塞(Blocked):任务某些依赖对象不可用(即不在本地)。不在本地怎么之前能跑呢,这里说明一下,Ray 的任务是支持嵌套调用的(对应远程函数的嵌套调用),那么一个任务 A 在运行时生成了一个任务 B ,并且等待其结果返回的话(
ray.get)。任务 A 就会被阻塞(Blocked),等待 B 的执行结束。 - 不可放置(Infeasible):任务的资源需求不能被当前集群内任何一台机器的所有资源(注意不是剩余资源)所满足。但如果有机器新加入集群,就可以试探这些 任务的资源需求是否能够被满足了。
状态转移图
任务状态转移图
状态枚举类
状态枚举类定义在 scheduling_queue.h 中:
1 | enum class TaskState { |
相对于状态机中的状态,此处多了几个枚举值。包括 SWAP、DRIVER。此外还有个神奇的 kNumTaskQueues,这个先按下不表,说说前两个。
- SWAP:任务的分派是异步的,即 Ray 将一个处于 Ready 状态的任务分配给某个 Worker 后。只有在回调函数中才能最终知晓是分配成功了,还是分配失败了,从而将任务状态转移到 Running 或者 Ready。但是在这个空当中,任务应该处于什么状态呢?这就是 Swap 的作用了(但不知道为什么没有显式的作为状态机中的一个状态)。
- DRIVER:这个就是标识某个任务是用户代码进程,从而将所有任务都统一来管理。
任务队列(TaskQueue)
Ray 将所有任务按状态(TaskState)聚集组织在一个个队列中, 这些队列即任务队列(TaskQueue)。每个队列定义了任务增加、删除和查找等基本操作。此外,还有一个重要的接口,就是获取该队列中所有任务所需资源的总和。比如说在调度某个任务时,想要知道某个节点对剩余可用资源,就需要用该节点的总资源,减去正在运行的任务的所需资源和就绪任务的所需资源(需要优先本地调度)。
值得一提的是,在删除任务的时候,如果 removed_tasks 参数不为空指针,则将删除的任务放到里面。这样如果多次删除,可以将任务收集到一个数组中。
还有一个比较冗余的点,即通过 task.GetTaskSpecification.TaskId() 可以获取到 task_id,不知道为什么还在 AppendTask 参数中增加 task_id 呢,为了一致性?
至于具体实现上,用了比较经典的链表+哈希方式组织。可以使得增删改查的时间都是O(1),获取全部任务的时间是 O(n)——遍历链表即可。
1 | class TaskQueue { |
在此基础上针对 Ready 这个状态又造了个 ReadyQueue;主要是增加了 ResourceSet -> Task Ids 的映射:即增加了一个索引,将所有具有相同资源需求的就绪任务集合在一块。这样在进行调度(DispatchTasks)时,如果发现某个任务的资源需求本地节点不能满足,那么就跳过所有具有同样资源需求的任务,算是一个调度的优化(对应逻辑在NodeManager::DispatchTasks 中)。
调度队列(SchedulingQueue)
按状态集合上述任务队列,再加以不同队列之间的任务换入换出操作,则成为调度队列(SchedulingQueue)。当 Ray 发生不同事件时,驱动任务状态机内状态进行转移,即调用 SchedulingQueue 暴露的接口,将任务从一个状态队列移到另一个状态队列中,并且做一些上下文的转换工作,以此来实现任务的调度。
需要注意的是,每个节点会维护一个调度队列,存储本节点持有的所有任务。
1 | class SchedulingQueue { |
从上面代码我们可以看出以下几点:
- 所有函数基本是围绕单个任务或者一组任务的增删改查而来的。
- 所有任务实际上按二层索引组织 task state -> (task id -> task);因此定位到一个任务需要先经过 task state 这一层,于是造了辅助函数来进行这层操作:
GetTaskQueue。此外,还有大量的在不同任务队列间倒来倒去的辅助函数。 - 上面所说的 kNumTaskQueues 是一个假状态,它本质上是一个界标。将其转换为整形后,所有小于它的状态都是按任务队列组织任务,所有大于它的状态只是用集合来存了任务ID(blocked 任务和 driver 任务)。
- 对于就绪队列,有一些特殊的照顾,因为实际将就绪任务安排到某个 worker 执行时很大的一块调度内容。这些额外照顾包括: a. 单独给就绪队列维护了一个指针、 b. 提供获取就绪队列资源需求之和接口、 c. 提供按同样资源需求聚集所有就绪任务接口。
- 还有两个按照其他维度获取一组资源的接口:
GetTaskIdsForJob和GetTaskIdsForActor可以分别根据给定 JobId 和 ActorId 来获取一组任务。
名词释义
**Task Required Resources:**任务资源需求或者任务资源约束,通过在函数上添加注解 ray.remote(num_cpus=xx, num_gpus=xx) 来指定。其中 GPU 还可以指定小数个,以使多个任务共享一个 GPU。
**Task argument:**任务输入或者任务参数。如果翻译为输入是相对任务来说的,如果翻译为参数,是相对任务所执行的函数参数来说的。
**Object:**这里翻译为了数据对象。
Object Store:基于内存的不可变对象存储,是分散在各个节点的节点内、进程间的共享存储。
Node,Machine:指的是组成集群的每个机器。如果非要区分的话,Node可能更偏重逻辑上的节点,Machine 更偏重逻辑节点所在的物理机。但是在 Ray 中他们是一一对应的,即一个机器只有一个节点。
本篇就先到这里,下一篇计划写写调度策略或者资源定义。

