概述:流控为啥重要
上云的好处在于池化资源,让多租户共享,然后按需分配,从而降低成本。但进行:
- 多租户隔离:用户要求可以使用其买到的流量,并且不会被其他租户影响。
- 资源共享:资源只能逻辑隔开,不能物理隔开,否则无法充分动态分配(超发)。
是一对相对矛盾的事情,我认为,也是云原生数据库最要解决的问题。不把这个问题解决好,则数据库:
- 要么平台不赚钱:比如资源静态预留,虽然可以让用户满意,总能随时用到卖给他的资源配额,但会存在巨大资源浪费,要么价格贵,要么用户不买单。
- 要么用户不满意:多用户共享物理资源,但非常容易进行互相影响,造成用户不能用到平台声称的配额。
DynamoDB 从静态分配开始,逐步演化出一套全局和局部组合的准入控制机制,从而实现了物理上资源共享,但又在逻辑上给用户以配额隔离,从而实现了数据库真正的云原生。下面,我依据 Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service 这篇论文披露的细节,对其流控机制的演进过程做一个梳理,以飨诸君。
水平所限,谬误之处,欢迎随时指出。
作者:木鸟杂记 https://www.qtmuniao.com/2022/09/24/dynamo-db-flow-control 转载请注明出处
开始:静态预留
这里面对的其实是一个常见的调度问题,如何将表的分片副本(table-partition-replication)调度到集群(一组物理机)上,并兼顾以下特性:
- 可用性:将物理机划分 AZ(Availability Zones,可用域),将不同副本调度到不同 AZ。
- 数据容量:其实是针对存储资源,每个物理机有容量总额,每个副本也有容量预期(能随着容量自动分裂,所以刚开始可能都比较小),表的分区副本创建时,需要为其寻找物理机资源余量大于其需求量的目标机器。比如,一个很简单的撮合策略是每次找集群中最空闲的那个机器。
- 流量:文中称 performance,其实包括计算资源和网络带宽。分配方式和 2 类似。
本文关注重点主要在 3 上,并且引入了流量单位:读容量单位 (RCUs) 和写容量单位 (WCUs)。
最开始的策略是将表的总配额(provisioned capacity)平均分配给每个分区,比如表的总配额是 1000 RCUs,一共十个分区,每个分区 100 RCUs。则每个分区的流量不得超过 100 RCUs。
这种策略最大的优点就是实现简单,而缺点繁多。让我们仔细审视下该策略,发现它其实蕴含了一个假设:分区间的流量是均匀的。但在现实中,这种模型太理想了。而一旦分区流量不均匀,就有可能出现,某些分区由于流量大,达到了该分区配额 100 WCUs 而被限流;而另外一些流量小的分区的配额却被浪费。
初步:突发策略和自适应流量
为了给上述纯静态分配策略打个补丁,DynamoDB 开始引入了流量突发(busting)和流量自适应(adaptive)策略。
突发策略
为了应对某些分区短时突发流量(short-live spikes)的问题,DynamoDB 引入了一个补丁(workaround),如果发现某个分区瞬时流量较大,且分区副本所在节点还有余量,就临时给该副本调配一些。具体到实现上,DynamoDB 用了三个令牌桶:
- 分区预留令牌桶。对应前面例子中的那 100 RCUs,当分区流量不超过这个值时,允许读写且从该令牌桶中扣除相应数量令牌。
- 节点总量令牌桶。对应单机容量限制,所有请求到来时,都要消耗此桶中令牌。
- 分区突发令牌桶。当分区流量超过预留时,会检查节点总量令牌桶是否还有余量,如果有就允许该分区进行突发。
需要注意,RCU 配额用上述策略就够了,但对于 WCU 配额,DynamoDB 还加了一条限制:需要检查该分区所有副本的 WCU 总额是否超限。其想法是,RCU 可以适当多给,但 WCU 不行。实现也很朴素,每个分区(多副本会构成一个复制组) Leader 会充当协调者,进行容量信息收集和分发。
最后,该策略只用于解决 300 秒内的短时突发流量,超过了时间窗口,借调的流量是要被释放出来的。因为这部分流量属于机器中的超发流量,需要随时准备调配给本机上的其他分区副本使用。
自适应策略
那对于长时突发流量(long-live spikes)怎么解决呢?只能在不同分区中进行流量调配了。
DynamoDB 使用某个中心服务(论文中就叫 Adaptive capacity,不确定该组件是额外引入的还是属于某个中心服务的一部分),来监控每个表的总配额和已耗容量。
当某个表还有余量,但表的某些分区因为流量突发被限流时,可以通按成比例控制算法(a proportional control algorithm,应该就是按流量大小比例)来给这些分区调配一些配额。并且,如果调配后,触到了所在存储节点整机配额上限,自动管理系统(autoadmin system)会将该分区迁移到相对空闲、可以提供所需配额增量的机器。
反思:分区和流控耦合
前两者最大特点是将流控和分区过紧地耦合到了一块,即在分区级别做的流量控制,因此很难对一个表进行跨分区进行流量调度。而我们对用户提供的是表级别的配额抽象,因此最好隐藏分区这个物理实现,保证只要表的总配额还有余量,就能给有突发流量的数据进行分配。而不能说,一些分区流量小,但仍然占用着配额,另外一些分区流量大,但在用完了分配给其的配额后,就要被限流。
虽然自适应策略在跨分区方向做了一些改进,但仍然是补丁范畴,而不是将动态流控作为第一思想来设计。为此,DynamoDB 引入全局准入控制机制来彻底解决此问题。
改进:全局准入控制
全局准入控制(global admission control,GAC)同样使用令牌桶的实现方式,但与之前局部令牌桶不同,全局准入控制使用一种全局令牌桶,或者说分布式令牌桶。由 GAC 服务来产生令牌,请求路由实例消费令牌,来达到表粒度准入控制。
组件
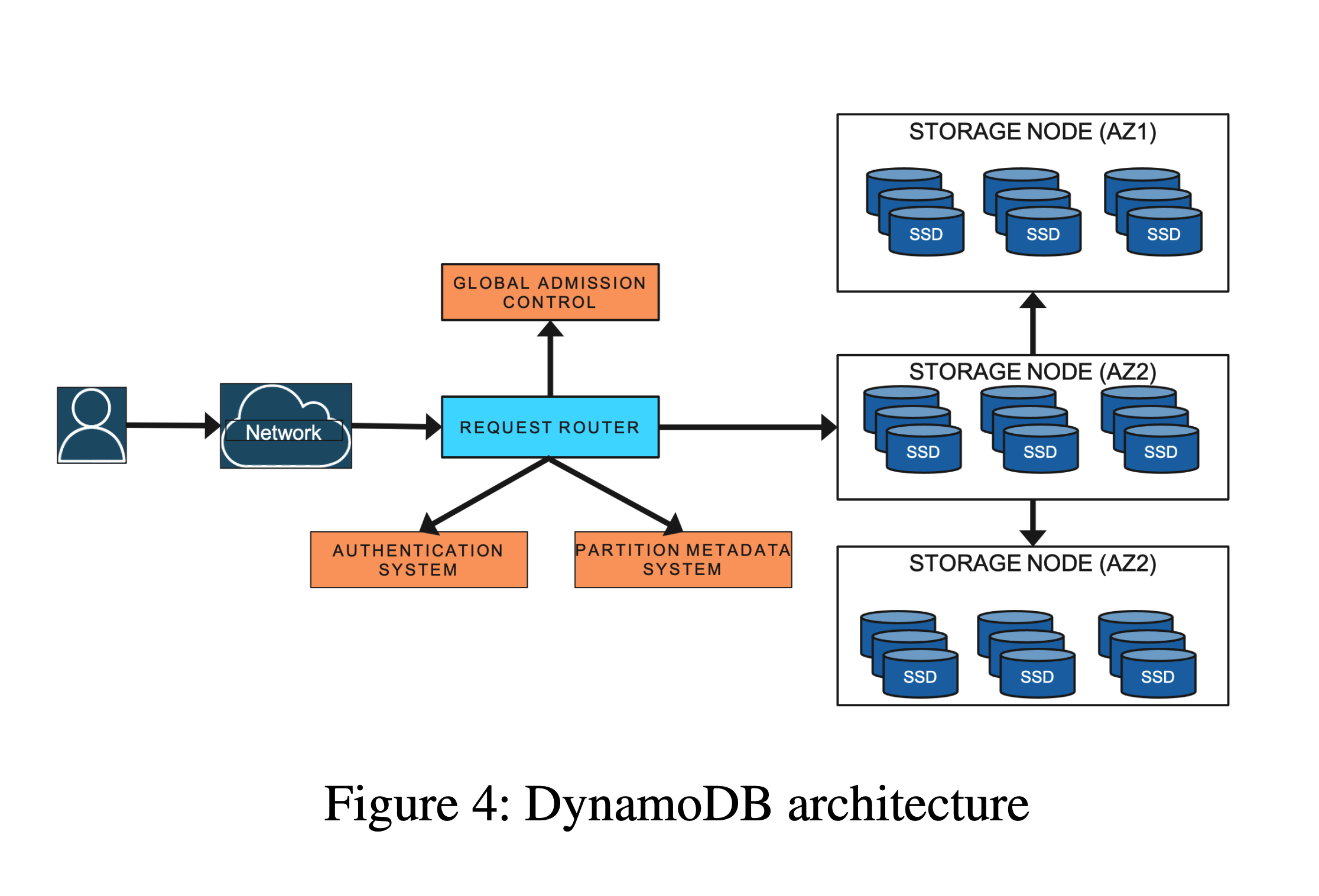 架构图
架构图
- GAC 服务:由一组 GAC 实例构成,以一致性哈希的方式进行流量均摊。
- GAC 实例:使用令牌桶方式产生令牌,每个实例会维护一个或者多个表级别的令牌桶。
- 请求路由器:request router,GAC 的客户端,与 GAC 服务通信,获取令牌进行流控。其中,令牌是有时限的,过期不被消费也会自动销毁。
其中有个关键问题是,GAC 每次给某个请求路由实例分配多少令牌?
DynamoDB 会根据历史信息,追踪每个请求路由实例的消费速率,按速率等比例分配。那如何进行追踪呢?论文中没有提,估计是使用滑动时间窗口之类的,但这类信号也不太好做,总会出现刻画不准或延迟太大的情况,不知道 DynamoDB 具体是如何实现的。
动态均衡
与静态分区和流量配额不同,GAC 视角下的分区流量会随时变化。为了避免热点聚集导致某些存储节点被打垮,DynamoDB 实现了一套可以主动根据吞吐消耗和存储量来对分区进行跨节点均衡的机制:
- 每个存储节点会各自进行资源用量核算,如果节点资源总用量超过节点某个百分比阈值,该存储节点就会主动向自动管理服务(autoadmin service)汇报,并给出一组待迁移副本候选列表。
- 自动管理服务在收到请求后,会根据全局资源分布,为每个候选副本找到一个合适存储节点,同时满足开篇提到的可用性和资源用量约束。
流量拆分
如果某个分区上有很大的热点,受限于所在节点负载可能仍会被限流。DynamoDB 会追踪这些热点,并统计该分区上数据的流量分布,按流量对分区进行切分。相比单纯的按中点(均衡存储资源)进行分裂,按流量分布(计算和带宽)进行切分,对于消除热点来说,可能更为本质。分区拆分后,可以按需进行迁移。
分区分裂的所需时间通常在分钟量级。
但有一些访问热点,并不能通过分区分裂来进行消除:
- 单数据条目热点
- 范围访问热点
DynamoDB 能够识别这类访问模式,从而避免在这样的分区上进行拆分。
自动配给
在创建表时就为表设定固定配额是一件很难的事情,就跟你需要预知将来一样。如果设置的多了,会造成资源浪费;设置的少了,又容易触发限流。这是静态配额的一个弊端,因此 DynamoDB 提供一种动态配额表(on-demand provisioning table,然后按用实际用量计费,这也是云计算的一大特征)。
为了精确描述配额,DynamoDB 引入了衡量吞吐的概念:读写容量单位(read and write capacity units)。如果单纯用 QPS 刻画流量,显然不合适,因为每个请求所涉及的数据量是不等的。因此 DynamoDB 引入单位时间内单位流量额度:RCU 和 WCU 来对读写流量进行刻画。
在进行自动配额时,首先要准确追踪读写流量。在检测到流量突发且要触发限流时,会对配额进行指数扩充(二倍)。如果应用持续流量大于之前尖峰的二倍,则会通过按流量拆分分区等方法进一步提高整体配额。
小结
云上一个重要特征就是资源池化、按需分配和精准计费,从而在整体上实现资源的充分利用,通过规模化优势抵消通用性带来的成本。
具体到云原生数据库中,便是多租户流量的自动配给。DynamoDB 通过论文披露了其从配额静态划分、打补丁演进,到全局动态划分的一个演进过程。对于国内各路号称要做云原生数据库的厂商来说,想要在保证用户体验(资源隔离)的前提下真正赚钱(资源共享),DynamoDB 的经验想必有诸多可借鉴之处。

