知乎上有个问题:如何实现一个数据库?手痒忍不住又水了一篇。以计算机中最常用的分析、理解问题的思想,我们可以从两个维度:逻辑和物理,来思考如何实现一个数据库。
逻辑维度
数据模型(对外,面向用户)
想要实现一个数据库,首先你得定义给给用户什么样的数据模型?在前些年,这些可能不是个问题,彼时,数据库约等于关系型数据,约等于 Oracle/SQLServer/MySQL/PostgreSQL 。但随着数据量的不断增大、用户需求的不断细化,关系模型已经不能一招鲜、吃遍天。
作者:木鸟杂记 https://www.qtmuniao.com/2022/12/11/how-to-build-a-database 转载请注明出处
时下(2022)常见的有 Relational 模型(Oracle)、Document 模型(MongoDB)、Search Engine(Elasticsearch) KV 模型(Redis)、Wide Column 模型(Cassandra),Graph 模型(Neo4j)、Time Series 模型(InfluxDB)。更多模型及其产品可见 DB-Engines 排名[1]。
数据组织(对内,面向系统)
数据库,本质上就是存取数据。从程序员的角度来说,就是如何在计算机存储层次体系[2]中组织数据。
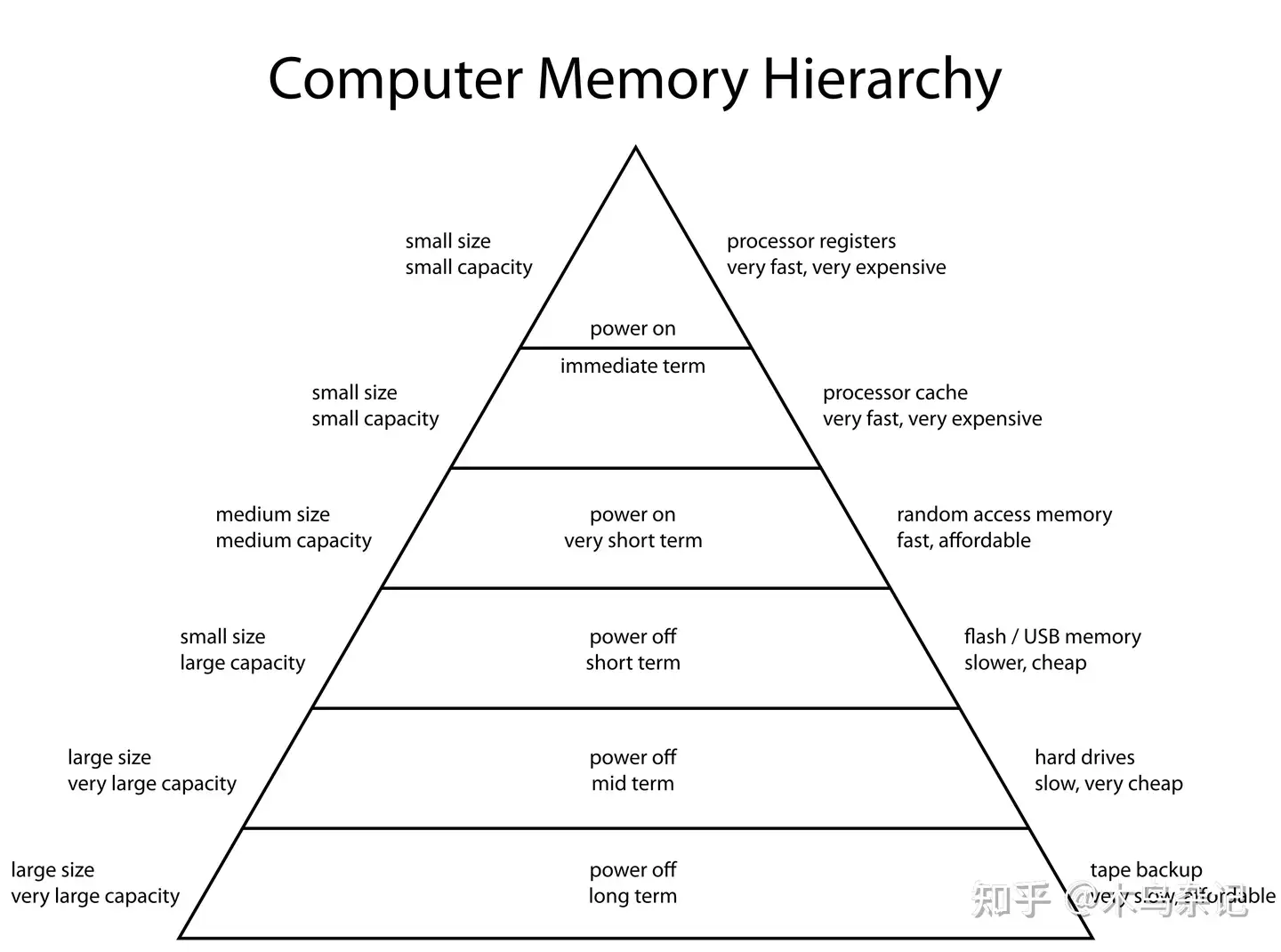 计算机存储层次体系
计算机存储层次体系
学过操作系统、计算机体系结构的同学都知道,对于计算机来说:
- 离 CPU 越近,如寄存器(Register)、缓存(Cache)、内存(Memory),速度越快、容量越小、造价越昂贵。
- 离 CPU 越远,如闪存(SSD)、磁盘(Disk)、磁带(Tape),速度越慢、容量越大、造价越便宜。
近年出现了一些新产品。如可持久化内存(Persistent Memory[3]),代表产品是 Intel 的傲腾[4],大致介于内存和SSD 之间,但由于定位不明确(向上走不够快,向下走不够便宜),还没能大规模应用;又如云上的对象存储,代表产品是 AWS S3[5],大致是几种非易失性存储的替代产品,价格足够感人、带宽足够高、扩展性足够强,因此大获成功,已经成为云上的存储基础设施,所有需要上云的数据库都会考虑在底层使用对象存储。
物理维度
数据库在物理上可以粗分为查询引擎和存储引擎。从感性上理解,存储引擎负责数据在外存的组织与将数据载入内存,查询引擎负责解析用户查询为数据层的读写与数据在内存中的计算。
限于篇幅,此处我们略去了另外几个重要的模块:并发控制、宕机恢复等。
查询引擎
每个数据模型都有与其契合的数据查询方式。当然,我们最熟知便是 SQL 之于关系模型。SQL 也是一门计算机语言,既是语言,就需要一套所有类似编译器前端需要流程:
-
Parser:对使用形式语言抽象的查询语法,利用自动机模型进行解析,构建抽象语法树[6]
-
Validator:对语法树进行依据 Schema 进行校验
不同的是,由于查询语言属于声明式语言[7],因此在执行上可以有很大的自由发挥的空间,所谓:
- Planner:使用模式信息将语法树中对用户有意义的元素(如名字),转为内部标识(如 ID)
- Optimizer:利用关系代数对计划树进行逻辑变换、利用统计信息对执行路径(比如使用哪个索引)进行选择,以期付出最小代价,实现用户查询需求
- Executor:将优化好的执行计划在存储层进行执行,真正的去访问我们存储于计算机体存储体系结构中的数据
树是在数据系统中应用非常深入的一种数据结构。大部分的数据查询,在逻辑上都可以抽象为对数据集的不断变换,对应到树中:
- 叶子节点:数据集合。有不同粒度,如一列、一行、一个表
- 中间节点:变换算子。有不同类型,如 selection、project、join、dedup、top 等
广义上来说,像 Hadoop、Spark、Flink 这些大数据范畴的中间件,也都有查询引擎的影子,只不过要么算子更为简单、要么侧重多机、要么侧重流等等。
存储引擎
对应数据组织,系统程序员需要根据数据库应用场景,在外存(SSD 和 Disk 中)组织数据。如:
- 考虑事务型还是交易型:在列存还和行存中权衡
- 考虑读写比例:在原地更新(B+ tree)和增量更新(LSM-Tree)间权衡
- 考虑安全性:在是否加密间权衡
然后,考虑如何将数据从外存向内存搬运。
- 我们知道,外存尺寸要比内存大的多,因此只能将部分数据载入内存,供用户访问。那每次载入哪些数据、每次逐出哪些数据,就是一个需要设计的策略,或者说算法——Buffer Pool,LRU
- 我们又知道,IO 相比 CPU 慢的多,数据访问多有局部性原理,因此每次去外存拿数据总倾向于“批发”,那每次批发的量,也是一个需要考量的点——Block,Page
[8]
最后,还需要考虑如何将数据从内存向每个 CPU 腾挪,准确来说,这已经属于查询引擎范畴,为了逻辑连贯,我们将其放在此处。
- 单核 CPU 遭遇瓶颈,只能向多核发展,那如何将内存中的数据喂给每个 CPU —— Cache Line 对齐
- 多个 CPU 需要进行协同,如何编排多个 CPU 的执行,如何串接多个 CPU 的输入输出——锁、信号量、队列
而数据如何在内存中组织,是两个引擎都会涉及到的事情。
- 行存还是列存。后者可以使用 SIMD 优化。
- 稀疏还是稠密。NULL 数据多少。
- 同构还是异构。是否需要支持动态类型和嵌套类型。
然而,上述只考虑了数据在单机中的组织。如果单机无法提供目标存储容量和吞吐量,就需要考虑分布式系统——将多个机器通过网络连接在一起,作为一个整体对外提供服务。
于是我们又引入了很不靠谱(相比单机总线)的网络和难以严格同步的时钟,如何对齐进行处理,又是另外一个长长的故事了。虽然当代数据库无一不需要多机协同,但限于篇幅问题,就此打住了。对此感兴趣的可以看看我们的 DDIA 读书会的分享:https://ddia.qtmuniao.com/
参考
- 数据库权威排名 DB-Engines https://db-engines.com/en/ranking
- 计算机存储体系 https://en.wikipedia.org/wiki/Memory_hierarchy
- 可持久化内存 https://en.wikipedia.org/wiki/Persistent_memory
- 英特尔® 傲腾™ 持久内存 https://www.intel.cn/content/www/cn/zh/architecture-and-technology/optane-dc-persistent-memory.html
- Amazon Simple Storage Service (Amazon S3) https://aws.amazon.com/cn/s3/
- 自动机编程 https://en.wikipedia.org/wiki/Automata-based_programming
- 声明式语言 https://en.wikipedia.org/wiki/Declarative_programming
- 访问的局部性原理 https://en.wikipedia.org/wiki/Locality_of_reference

