Memgraph 是一个内存型图数据库,使用 OpenCypher 作为查询语言,主打小数据量、低延迟的图场景。由于 Memgraph 是开源的(repo 在这,使用 C++ 实现)我们可以一窥其实现。根据这行注释,我们可以看出,其内存结构实现灵感主要来自论文:Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems。
本系列主要分为两大部分,论文解读和代码串讲,每一部分会根据情况拆成几篇。本篇,是论文解读(一),主要讲论文概述以及如何使用链表巧妙的存储了多版本、控制了可见性。论文解析(二)和(三),会讲如何实现可串行化以及回收多版本数据。
概述
从论文题目可以看出,本论文旨在实现一种针对内存型数据库的、基于多版本(MVCC)实现的、支持可串行化隔离级别的高性能数据结构。其基本思想是:
- 使用列存
- 复用 Undo Buffer 数据结构
- 使用双向链表来串起数据的多版本
- 巧妙设计时间戳来实现数据的可见性
- 通过谓词树(PT)来判事务读集合(Read Set)是否被更改
与一般的多版本不同的是,本论文会在原地更新数据,然后将旧版本数据“压”到链表中去,使用 “压”是因为链表采用头插法:表头一侧数据较新、表尾一侧数据较旧。所有数据的链表头由一个叫 VersionVector 的数据结构维护,如果某一行没有旧数据,对应的位置就是 null。
作者:木鸟杂记 https://www.qtmuniao.com/2024/02/06/memory-mvcc-serial 转载请注明出处
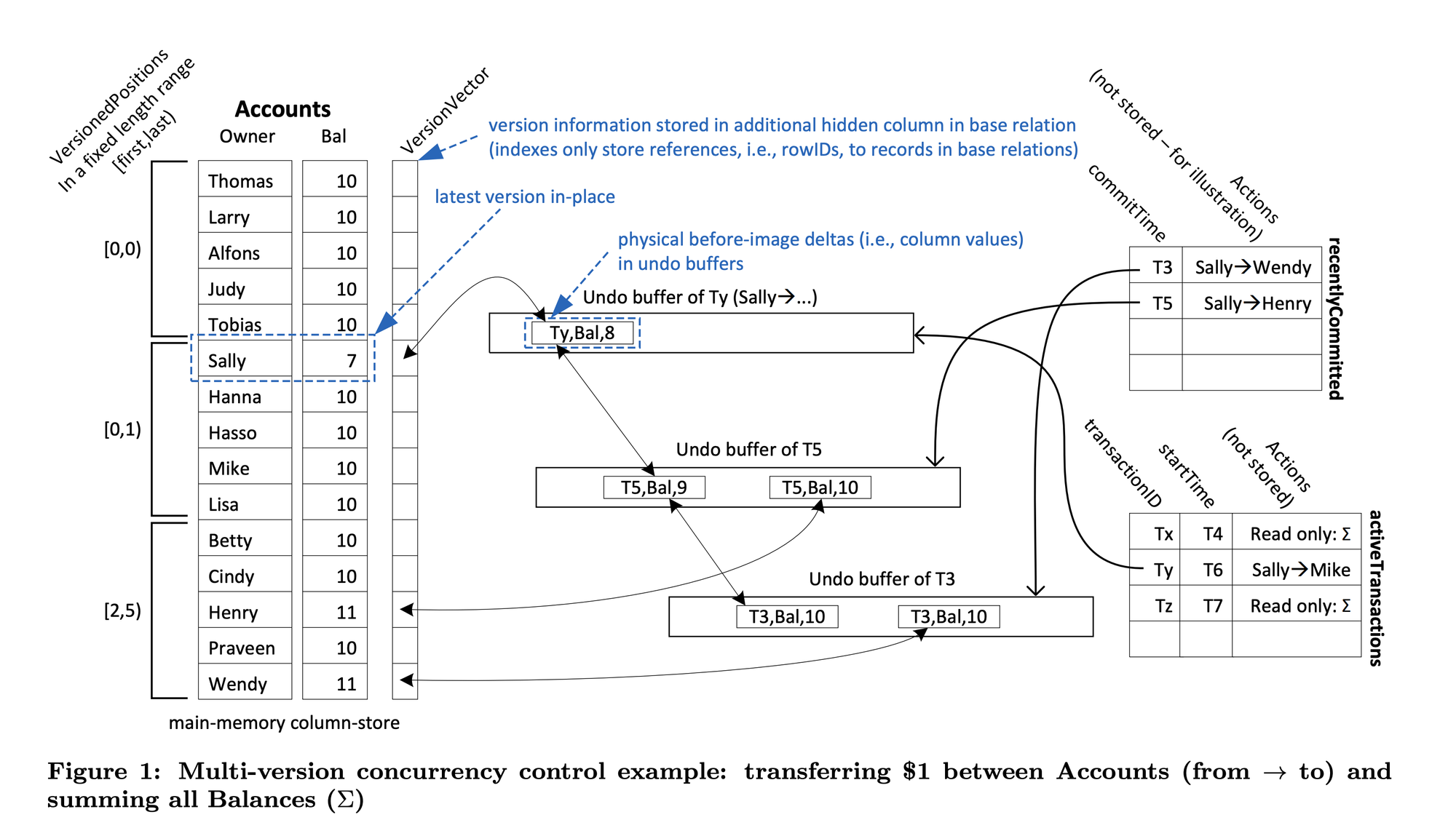 MVCC-memory.png
MVCC-memory.png
之后,我们之后会一直使用上图例子来辅助理解原理。这是一个 Sally 持续向别人转账的例子。开局时(T0)每人十块钱,然后 Sally 每次转给别人 1 块钱,一共转了三笔,当前时刻前两笔已经完成:
- Sally → Wendy,提交时间戳为 T3
- Sally → Henry,提交时间戳为 T5
正在进行第三笔:
- Sally → Mike,事务 ID 是 Ty,起始时间戳为 T6
中间穿插着两次全表扫描(求所有账户总额)事务 Tx 和 Tz,起始时间戳分别为 T4 和 T7 ,都已经开始,但还没结束。
版本管理
每个事务在进入系统时会获取两个时间戳(uint64):
- transactionID:事务 ID 也是一个时间戳(从 2^63 开始自增),上图中的 Tx, Ty, Tz。
- startTime-stamp:一个自增的时间戳(从 0 开始自增),上图中的 T4, T6, T7。
如前所述,所有的更新是原地的(in-place),但会在 undo buffer 中保存旧值。旧版本的数据有两个作用:
- before-image value,作为事务 undo log 的一部分。
- 作为该字段多版本的一个旧值。
对于快照隔离和可串行化隔离级别来说,原地更新的值,是不为其他事务所见的,下一小节我们会讲如何控制可见性。
在事务提交时,会获取另外一个时间戳:commitTime-stamp,该时间戳和 startTime-stamp 共用一个自增计数器。
在事务进行中,所有的 Undo Buffer 中的旧值会被打上 transactionID 的时间戳(图中第三笔转账:Ty);在事务提交时,会统一替换为 commitTime-stamp (图中前两笔转账: T3 和 T5)。
版本可见性
某个事务在访问一个字段的值时,会首先进行原地访问,然后沿着该值对应的 VersionVector 指向链表进行访问,直到满足以下条件后停止:
1 | // pred 表示下一个链节 |
下面我们逐一看下三个子条件各自适用情况:
v.pred == null:当该值没有多版本,或者链表到头时成立。v.pred.TS == T:正在进行的事务访问自己更新的数据。v.pred.TS < T.startTime:通过事务起始时间戳,访问已经提交的老版本数据。
上述条件比较抽象,我们结合例子来看。Sally 的多次转账会形成以下链表:
1 | 7(in-place) -pred-> (Ty, Bal, 8) -pred-> (T5, Bal, 9) |
然后来看不同事务访问 Sally 的 Bal(Balance)数据的可见性:
- 事务 Ty:(Ty 是一个 > 2^63 的值),所以会在后继节点满足:
pred == (Ty, Bal, 8)(条件2,Ty == Ty)时停住,此时访问到的值为 7 ,也即事务 Ty 更新到的值。 - 事务 Tx:起始时间戳为 T4,所以会在后继节点满足
pred == (T3, Bal, 10)(条件3,T3 < T4)时停住,此时访问到的 Sally 账户的值为 9,也即此时刚转过一次账,即提交时间戳为 T3 的那次转账。 - 事务 Tz:起始时间戳为 T7,所以会在后继节点满足
pred == (T5, Bal, 9)(条件 3,T5 < T7)时停住,此时访问到 Sally 的账户值为 8,也即此时完成了两次转账,第三次转账尚未完成,对 Tz 不可见。
可以看出,上述链表把时间轴分成了四段:
1 | 临时值(7)----Ty--(8)---T5---(9)---T3---(10)---T0 |
比较事务起始时间戳和后继链节时间戳,是为条件 1:
- T0 ~ T3:见到的值是 10
- T3 ~ T5:见到的值是 9
- T5 ~ ∞:见到的值是 8
其中,Ty (事务 ID)相对起始时间戳来说就是无穷大,这就是我们在前一小节提到的将 uint64 对半劈开的妙用之处:
- 起始和提交时间戳:0 ~ 2^63 -1
- 事务ID:2^63 ~ 2^64 - 1
另外,null 就相当于 T0 ,是为条件 1 。
最后,为了让事务能够看到自己的更新,于是额外加了条件 2 。
下篇,我们会详细讲如何基于上述数据结构来实现可串行化隔离级别的。
参考资料
- 开源项目:https://github.com/memgraph/memgraph
- 相关论文:https://db.in.tum.de/~muehlbau/papers/mvcc.pdf
- 解析博文:https://wangziqi2013.github.io/paper/2018/07/10/Fast-Serializable-Multi-Version-Concurrency-Control-for-Main-Memory-Database-Systems.html
本篇文章来自我的小报童专栏,第二篇解读也已经在专栏更新,欢迎喜欢我文章的朋友订阅支持,激励我产出更多优质文章。订阅方式见这里。

