streamlit 是一款可以快速进行简单网页开发的 Python 库,其 slogan 是:
A faster way to build and share data apps
即“一种快速构建、分享数据应用的方法”。其在机器学习、数据科学,甚至当今大模型领域非常流行。其优点非常突出:
- 使用上述领域开发者最喜欢的语言:Python。不用写前端,pip 安装就能用。
- 简单几行代码就能快速攒出一个数据可视化、打标等小工具的网页。
- 还支持丰富的第三方组件扩展,比如社区开发的 code_editor 。
当然,如果你还想要低延迟、高并发、深度定制等需求,那对不起,这是 streamlit 被 tradeoff 出去的那一部分。但对于面向内部少数人使用的小工具来说,streamlit 简直是利器。可以说这个小生态位被它卡的太好了,所以能在 2022 年以 8 亿美金卖给 Snowflake。
本文我们就一块来看看其基本设计哲学和一些简单实践。
设计哲学
其基本设计哲学可以概括为:
- 用后端语言写前端
- 收到新事件会重新构建
- 支持会话级别的缓存
作者:木鸟杂记 https://www.qtmuniao.com/2025/03/18/streamlit/ 转载请注明出处
上面三点是依次递进的设计:由于是用后端语言写前端,因此每次响应用户请求都会全部重新执行一遍代码,当然也就不支持局部刷新;为了避免每次全部执行带来的不必要的数据加载,引入了细粒度(每次用户主动刷新页面会丢失)的缓存,从而达到了类似局部刷新的目标——不需要刷新的部分缓存起来复用就好了。
总结成一句话就是:顺序执行以保持简洁,按需缓存来提高效率。
看个例子
我们把功能搞简单一点:用户输入一个 parquet 格式本地路径,我们将其读出展示可视化。
1 | # app.py |
简单构造了包括学生名和绩点两列的数据,存在 parquet 文件中(构造代码会放在附录中)。运行以下命令:
1 | streamlit run app.py |
然后访问 http://localhost:8501 即可看到页面:
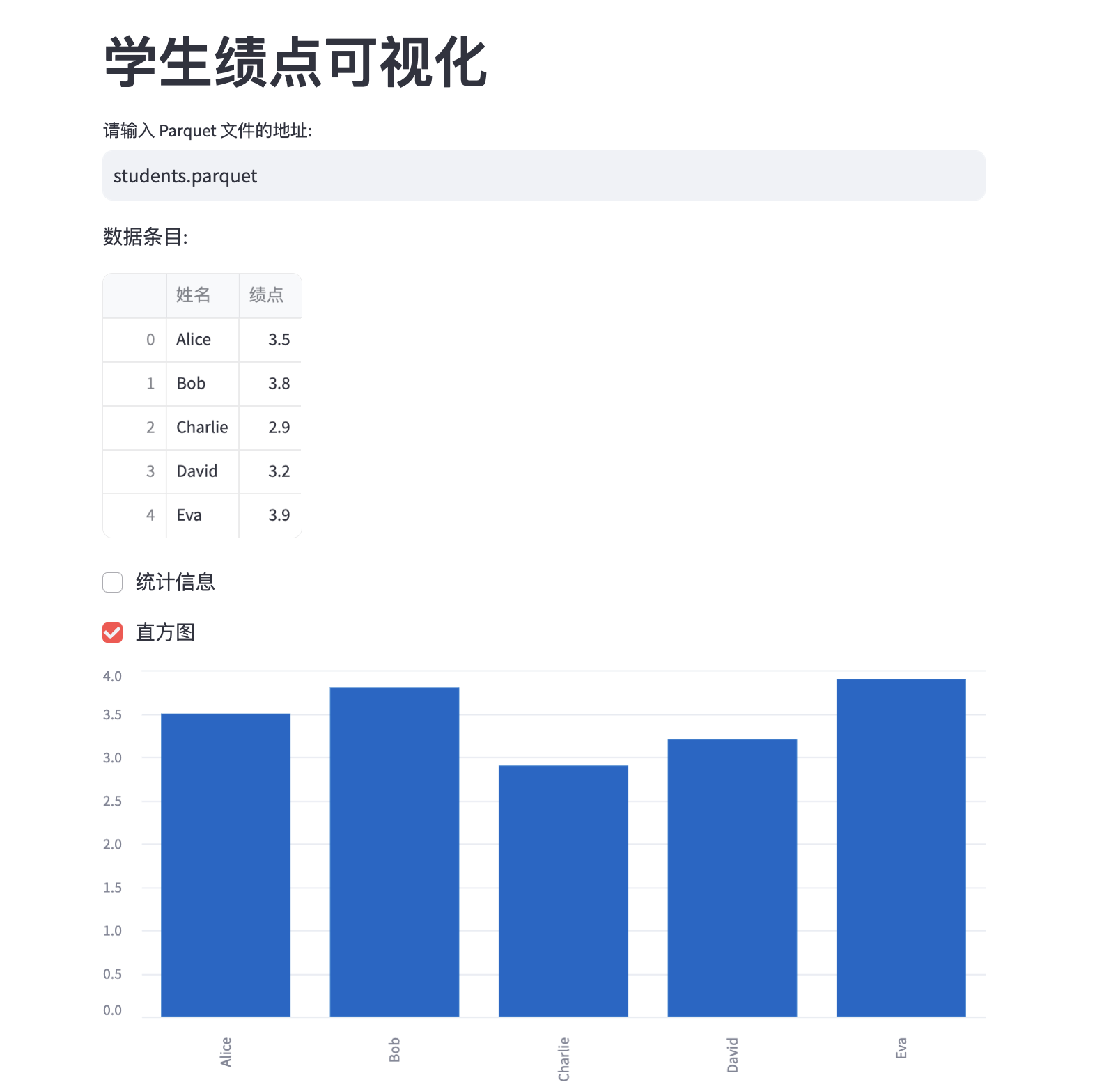
从该例子可以大致看出 streamlit 的语法相当简洁:
- 组件构造:通过
st.title,st.dataframe,st.checkbox等接口就可以快速构造很多标准组件,而不用在意其样式。 - 顺序执行:和 js 事件驱动不同,streamlit 的代码就是自上而下顺序执行的,非常容易理解和调试。每次重新输入路径、重新点击复选框后整个页面都会重新渲染。
缓存
那么问题来了,如果学生表的数据量很大,每次重新输入路径后都会全部重新执行、重新加载,岂不是冗余且很慢?为此,我们可以通过 streamlit 的缓存机制,将数据缓存下来。
可以使用 st.session_state 显式的进行缓存:
1 | st.session_state[file_path] = data |
也可以通过在加载数据上的函数增加注解 st.cache_data进行缓存,此时缓存的 key 就是函数的输入参数,本例中也是 file_path。
1 |
|
但其实,在 streamlit 中,我们不仅可以缓存数据,也可以缓存组件(widget)。比如说 st.dataframe,如果我们不想其每次都重新渲染怎么办?给其一个 key!
1 | st.dataframe(data, key=f"df-{file_path}") |
这样,只要 key 不变,该 dataframe 就不会重新渲染。
至此,我们大概从感性上明白了 streamlit 的哲学:通过顺序执行来保持简洁、通过按需缓存来保持效率。下面用一张图来概括下:
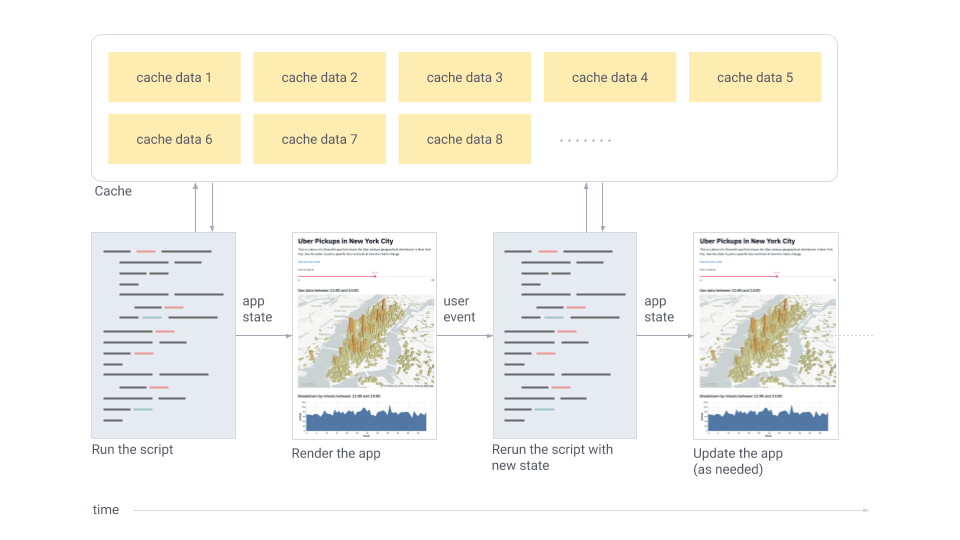
小结
本文非常浅显的通过一个小例子来分析了下 streamlit 的设计哲学,帮助大家建立一个感性的认识,如果有类似面向团队内部的可 GUI 需求,不妨一试。
但囿于篇幅,并没有剖析其背后是如何实现的,也没有讲更多的进阶使用,如果大家对这些东西感兴趣,欢迎留言告诉我。
参考资料
官方文档:https://docs.streamlit.io/get-started/fundamentals/advanced-concepts
附录
需要安装的库:
1 | pip install streamlit pyarrow pandas |
构造数据的代码:
1 | import pandas as pd |

