Princeton COS 597R “Deep Dive into Large Language Models” 是普林斯顿大学的一门研究生课程,系统探讨了大语言模型原理、准备和训练、架构演进及其在多模态、对齐、工具使用等前沿方向中的应用与一些问题。注意,该课程侧重概念的理解上,而非工程的实现上。
我之前是在分布式系统和数据库内核方向,但这两年转到一家大模型公司做数据。本笔记主要是我对课程论文的梳理和精要。不同的是,我会结合在工作中解决实际问题的一些体感,给出一点转行人不同视角的思考,希望能对同样想从工程入门算法的同学一点帮助。本文来自我的付费专栏《系统日知录》,欢迎订阅查看更多大模型解析文章,文末有优惠券信息。
本篇主要关注大模型的奠基之作——Transformer。
首先要明确问题域,Transformer 试图解决的是序列建问题,最主要的代表就是语言建模和机器翻译。其次,需要知道前驱方法—— RNN(循环神经网络)和 CNN(卷积神经网络)存在的一些问题,才能知道 Transformer 的创新之处。最后,Transformer 的解决要点的在于“多头注意力机制”和“位置编码”。
作者:木鸟杂记 https://www.qtmuniao.com/2025/09/10/llm-1-transformer/ 转载请注明出处
序列建模
序列建模是对一个有顺序的元素序列进行建模,以捕捉元素间的依赖关系(因果性,万物的法则),从而可以:
- 预测序列中下一个元素(语言建模)
- 判断序列的合法性(语法检查)
- 将一个序列转化为另一个序列(机器翻译)
序列建模是一个相当泛化的概念,很多 NLP 任务本质上都是序列建模问题。更进一步,现实中的很多问题自动化,都可以转化为序列建模问题。
再看一些序列建模的例子感受下:
| 领域 | 输入/输出序列的形式 | 例子 |
|---|---|---|
| 编程语言 | 代码 token 序列 | 代码自动补全、代码翻译、代码生成 |
| 分子结构 | 化学式序列(SMILES) | 药物生成 |
| 图像描述 | 图像 → 描述序列 | 对图片内容进行总结 |
| 多模态理解 | 图像序列 + 文字序列 | 对图片内容进行问答、定位 |
| 操作轨迹 | GUI 操作序列 | 自动执行任务的 Agent |
因此,随着大模型的成功,这个方法也是现在被看做最有希望通向 AGI 的路径之一。
前序方案
下面我们来看看传统的 递归结构(RNN/LSTM) 和 卷积结构(CNN) 在进行序列建模时存在的主要问题。
递归结构
递归结构如 RNN / LSTM / GRU 曾长期主导序列建模,其公式是:
$$
h_{t}=f(h_{t−1},x_{t})
$$
可以用图片来辅助理解:
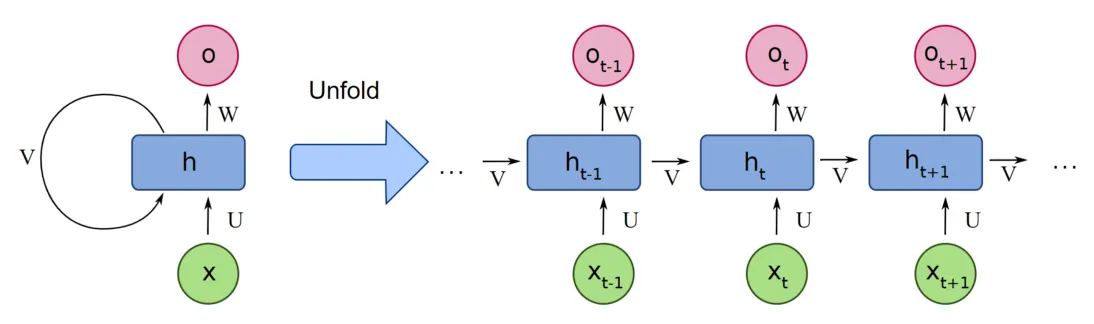
其中 $h_{t}$ 是 t 位置(或者说“时刻”)的隐藏状态, $x_{t}$ 是 t 位置的输入。直观上很好理解,就是将之前的输入序列压缩到一个隐藏状态 $h_{t}$ (hidden state)中,然后不断向后传递。从图中的圈,可以更好理解为什么叫递归结构。
这种结构主要有两个问题:
- 无法进行并行计算
- 长路径信息稀释
可以看出,这个结构中每一个隐藏状态的计算( $h_{t}$ ),都依赖上一个结果( $h_{t-1}$ ),这种前后相继的依赖关系导致我们想得到最后的状态时,只能一步步地进行串行计算。从而没有办法充分利用 GPU 的并行能力,网络稍微一大训练起来就非常慢。
另外,不同元素间的状态传递都依赖这样一步步的计算,可想而知,当距离足够远之后,序列前面元素的信息将会被稀释到什么地步。因此,RNN 结构很难捕捉过长距离的两个词之间的依赖。
卷积结构
卷积神经网络(CNN)在上一波以 CV 为主要应用领域的人工智能浪潮中大放异彩,核心特点就在于其并行性,以及可深层堆叠性(当然主要依赖同时期创造的残差网络等技巧),从而构建出足够复杂的网络结构以容纳足够多信息。
因此 CNN 被引入序列建模,代表如 ByteNet、ConvS2S,试图通过局部感受野+多层堆叠来并行化建模。但 CNN 也有其问题:
- 单层卷积视野有限
- 不能捕捉绝对位置信息
由于单个卷积核通常不会太大(比如图像中的卷积核通常是 33 or 55,太大效果不太好),因此为了捕捉长距离依赖,通常会进行多层堆叠,以扩大感受野。但网络过深,不仅会让训练更难,也会大大推高训练成本。本质在于,卷积方式对长距离建模效率较低。
不同于图像,对于序列来说,我们通常在位置或者时间维度上进行一维卷积。由于卷积核本质上是位置无关的(没有位置信息,只是一个权重,左边和右边参数一样),因此只能捕捉卷积核视野内的相对位置信息。另外,卷积在图像领域很好用的一大原因是:平移不变性。举个例子,一个猫出现在左上角和右下角,都是一个猫。但在语言序列中,一个词的含义是非常依赖上下文的。因此,卷积对序列来说,并非一个原生的结构。
核心架构
在分析了问题域和前序方案的短板之后,我们来看看 Transformer 是如何设计网络结构来解决这两个问题的。但在详解之前,我们再铺垫一些相关的概念。
相关概念
编码器-解码器结构(encoder-decoder structure)。是为了解决我们之前提到的序列建模中的 seq2seq 的一类问题而提出的,主要应用于基于神经网络的机器翻译领域。最早被提出时(2014)是基于 RNN 的。
其基本工作原理是:
- 编码器将输入序列编码为固定长度的上下文向量(context vector)。从直觉上理解,该向量类似于输入句子的”摘要“。
- 解码器利用该上下文向量作为起始的隐藏状态,通过”自回归“的方式逐步生成输出序列。
因此,最初的编码器解码器结构,是通过一个固定长度的中间向量来“桥接”输入和输出序列的。可想而知,当输入序列的信息量变大(比如序列变长),这个固定长度的”桥“会成为瓶颈。
自回归(auto-regressive)。自回归最开始是统计学和时间序列分析中的一个概念,其基本含义是一个变量当前的值等于过去值的线性组合,再叠加一个随机扰动项。在大模型中,就是输出下一个 token 时,模型会将已经输出的 token 作为上下文一起送入模型。
举个例子,当 GPT 生成“天空是蓝色的”这句话时:
- 首先生成“天空”。
- 然后利用“天空”作为上下文,生成“是”。
- 再利用“天空是”作为上下文,生成“蓝色”。
- 最后利用“天空是蓝色”作为上下文,生成“的”。
这中间会有一些冗余信息,也是推理 infra 的着重发力的一个方向:KVCache。当然,这里的 KV 概念会涉及到 Attention 一些概念了,之后会展开讲。
自注意力(self-attention)。注意力机制的最开始引入是为了解决编码器解码器结构中间桥接向量“信息瓶颈”的问题。其基本做法是:
- 编码时:(粒度作细)不再将整个输入序列编码成一个固定长度向量,而是为每个词生成一个“关系”向量,该向量包含了该词和序列中其他词的“亲疏”关系,当然,该词的位置信息也被以某种方式编码了进去。
- 解码时:(分亲疏)生成每个词时,也不再仅依赖固定长度的上下文向量,而是动态的关注输入序列不同部分。实现上,就是利用之前得到的每个词的“关系”向量,来对输入序列按”注意力“(亲疏性)进行加权,得到下一个词。
形象来说,注意力机制:
- 粒度作细:不再为整个输入序列生成做”摘要“,而为每个词逐词做摘要。
- 分亲疏:不是粗暴利用一个固定长度上下文做解码,而是每次解码时,动态的获取当前最应该关注的输入序列的部分词,来做加权。
架构
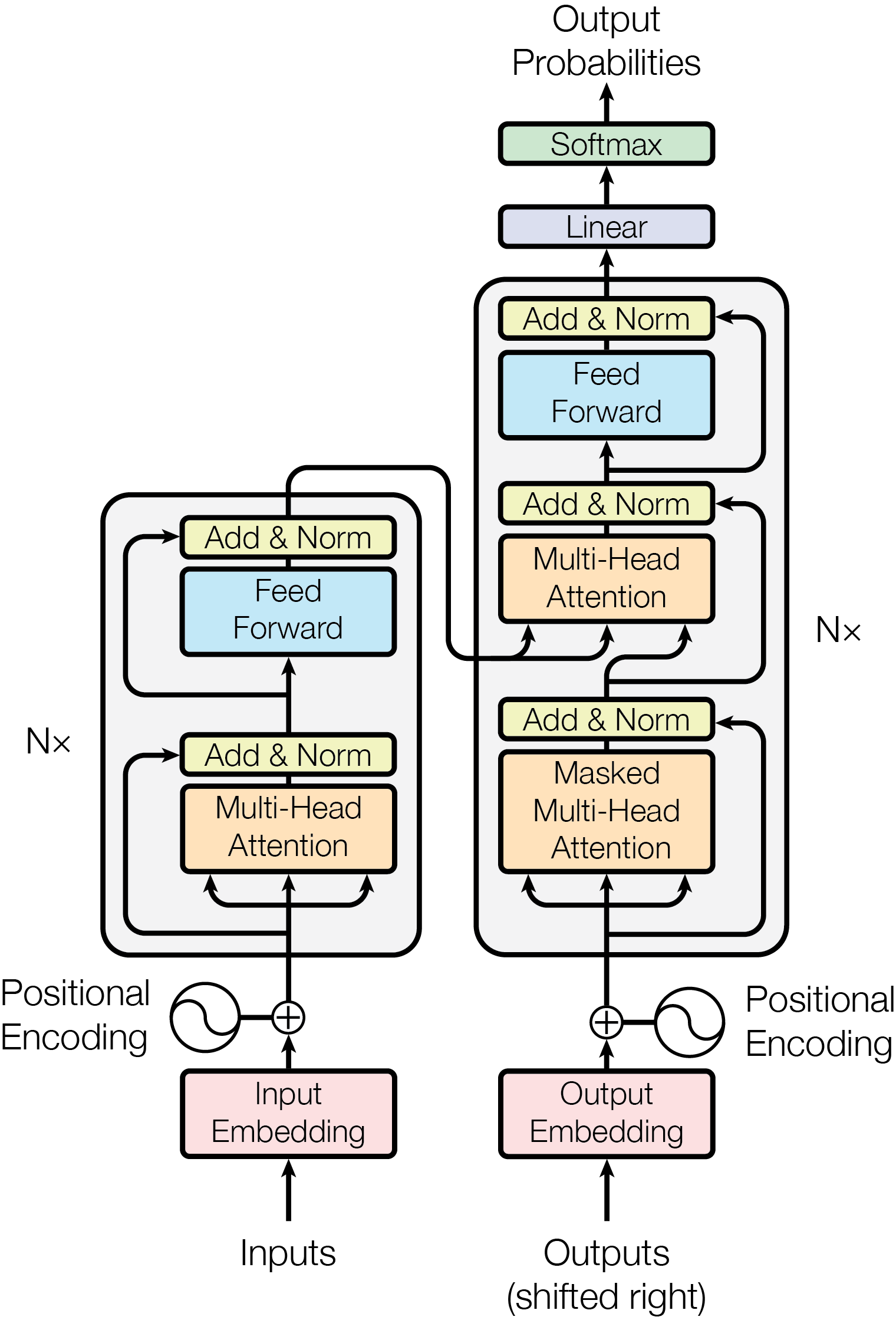
有了上面铺垫,我们再来看论文中这张 Transformer 经典的架构图。
主干的左右两侧遵循了经典的编码器-解码器结构。
在编码器一侧,堆叠了 N=6 个基本层,堆叠的时候通过残差和归一化(Add & Norm)方式来规避深层神经网络的梯度消失和爆炸问题。每个基本层包含两个基本单元,多头注意力(Multi-Head Attention)和前馈网络(Feed Forward)。前馈网络其实就是有一个隐藏层的三层全连接网络,后面会详细解析这两个基本构件。
右侧的解码器结构和编码器基本结构大体相同,层数也相同,变化有二。第一,加了一层交叉注意力模块,以将编码器抽取的“上下文”桥接过来。第二,注意力计算时是要先做掩码的,使得每个词只能关注到其以前的词,而看不到其之后的词。
最后就是通过一个线性层,然后利用 softmax 进行概率归一化。
另外,输入时也可以分成两块:
- token 到向量转换:tokenizer 这里没画。token 到向量的转换函数也是可以学的。
- 叠加位置信息:给每个 token 的向量叠加一个其所在句子中的位置信息。
注意力
在计算注意力的时候,我们会为每个 token 的向量引入三个额外表征:Q(query),K(key),V(value)。即从 token 原向量(设为 x)中通过“投影”(矩阵变换)的方式在另外空间抽取(或者说衍生)三种不同用途的表征。下面我们通过一个“去图书馆查资料”的例子来理解下。
想象一下,你要写一篇关于“人工智能对经济的影响”的论文,需要去图书馆查找一些相关文献。
- **原始输入向量 (x)**:就像你脑海中模糊的想法或一个高度抽象的词,比如“经济”。这个想法本身包含了很多维度的含义。
- 查询 (Query - Q):为了查找资料,你不能只抱着“经济”这个模糊的想法。你需要把它具化成一个问题或查询,比如“寻找关于AI技术如何改变就业市场的书籍”。这个具体的查询就是Q。它是从你的原始想法“经济”派生出来的,但更具方向性。
- 键 (Key - K):在图书馆里,为了让每一本书能被快速检索到,都会有自己的标签或关键词,比如“AI”、“就业”、“自动化”、“市场分析”等。这些标签就是K。它们代表了这本书的摘要,是用来和“查询”进行相关性匹配的。
- 值 (Value - V):书本的实际内容就是V。一旦你的查询(Q)和某本书的标签(K)高度匹配,你就可以去阅读这本书的详细内容(V)来获取更多信息。
那为啥不直接用原始向量 x 与其他 token 的向量做乘积就好了?原因有多方面:
- 角色解耦:如果将 QKV 都使用 x,则需要该向量同时“分饰三角”,其实是做了一种“先验”的强约束关系。交叉注意力时更能明显体现这一点。
- 表达能力:将原始向量投影到不同空间中,本质上是一种更内聚的抽取,而且这个抽取方式也是可以进行参数化学习的,从而极大提升了灵活性和表达能力。
- 支持多头:正因为同一个 x 可以有不同的“抽取”方式,Transformer 的多头并行地进行不同维度的 feature 抽取才有意义。
Transformer 中用到了两种注意力方式:
- 自注意力(self-attention):编码器部分中的注意力层,捕捉序列中 token 的的内在依赖关系。此时,QKV 都来自同一个序列的不同投影。
- 交叉注意力(cross-attention):编码器和解码器间的桥接部分,利用编码器捕捉到的内在依赖关系,进行下一个 token 的预测,此时 Q 来自解码器,KV 来自于编码器。
在给定窗口内,注意力模块会为每个 token 计算和其他 token 的关联性,从而为每个 token 得到一个对其他所有 token 的关系向量。计算相关性时,可以用加法注意力或点积(乘积)注意力,两者效果类似,但因为 GPU 对点乘进行了高度优化,所以选择了后者。最后为了保持输出的分布稳定性(点乘后均值会放大 $\sqrt{d_k}$,搜下点积公式就可以看出),因此要加一个缩放(除以 $\sqrt{d_k}$)将均值搞回去,以避免将 softmax 函数推入梯度极小的区域。
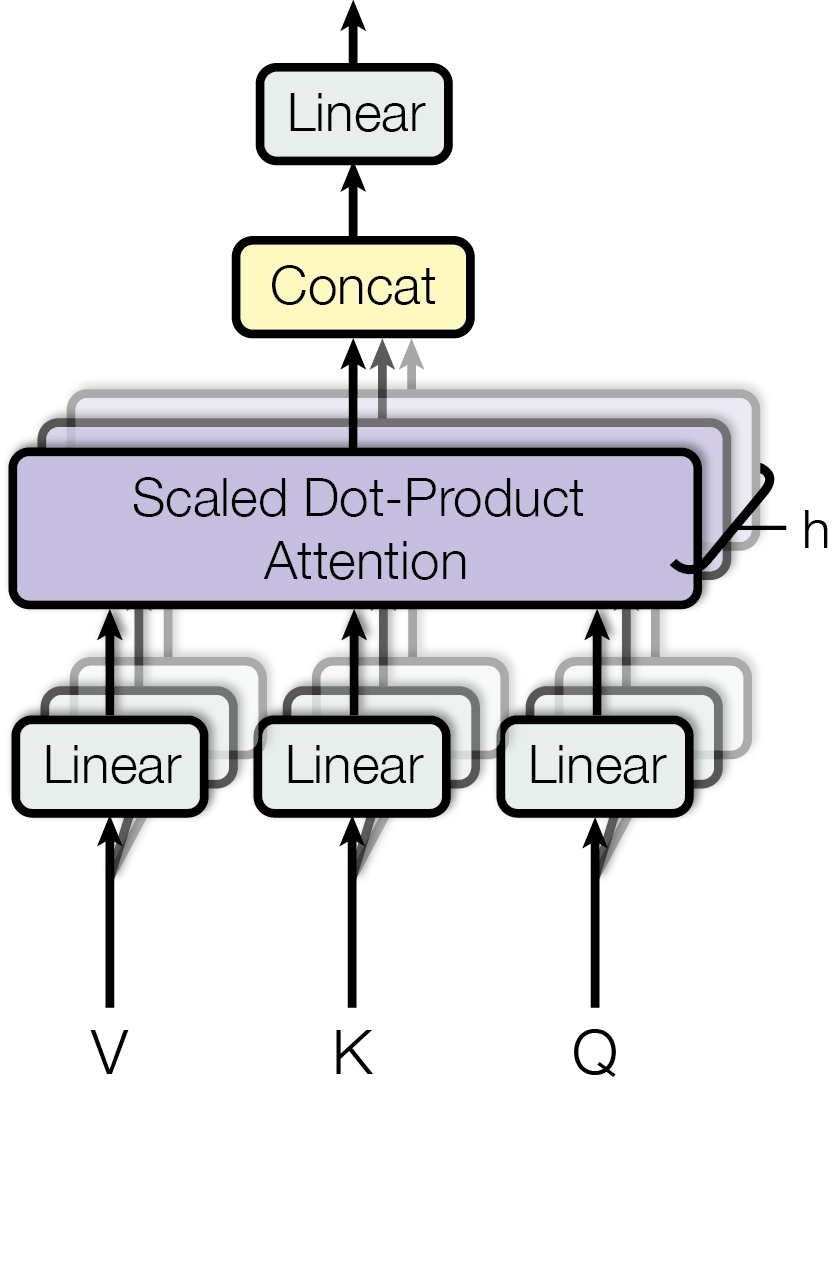
那为什么用多头呢?这点其是借鉴了卷积神经网络(CNN)中的多头抽取、深层堆叠的特点,分别抽取不同维度的特征,最后利用线性层重新组合到一块,效果更佳。
论文中采用了 h=8 个并行注意力层,或称为头(head)。对于每一个头,使用 $d_{k} = d_{v} = d_{model} / h = 64$,即增加数量的同时,减小每个头的维度。从而在保持计算量差不多的同时,可以并行抽取多个特征。
前馈神经网络层(FNN)
是一个三层的全连接神经网络(输入层,隐藏层,输出层)。类似于 CNN 中多头后面的卷积核 = 1 的组合层,提供了额外的非线性(主要是通过激活函数)。直观上理解,自注意力层是“横向”地(在窗口内跨 token)整合信息,它将所有相关词的上下文信息聚合到每个 token 的表示中。而 FFN 层是“纵向”地(词间不互相影响,在每个词内的特征维度上)深化和提炼这些聚合后的信息。它在每个位置上独立地进行特征学习和重塑,使其能够更好地捕捉该位置上更抽象、更高层次的特征。
位置编码
由于注意力模块是计算的序列中不同 token 的相对关系,是没有位置信息的。为了让网络学到 token 间的位置信息,也即我们之前提到的因果关系,Transformer 额外引入了位置编码。为了让位置编码能够简便地叠加到 token 的 embeding 上,让其保持了和 embeding 同样的维度 512 。从而可以利用简单的加法方式进行叠加。
这个编码可以通过参数学出来,也可以事先固定。Transformer 选择了后者,因为发现和学出来的差不多(但当然,后面不同工作进行了大量改良)。Transformer 采用了一种正弦波的编码方式,特点在于可以捕捉位置的可加性。
小结
本文从首先明确了问题领域——序列建模,讨论了为什么序列建模可以成为解决一大类通用问题的基础;然后简单分析了之前 RNN 和 CNN 存在的一些问题:难以并行和长距离依赖捕获;最后剖析了 Transformer 的解决方案和主要架构——多头自注意力机制。
此外,我们可以追踪一个 token 对应的 embedding 的变换过程(变换过程中维度是保持 512 不变的),来更深的理解 Transformer。
编码器部分:
- 位置编码:加法,叠加位置信息
- 自注意力层:捕捉输入序列中 token 向量间关系压缩到表征向量中(两头看)
- FNN 线性层:增加一些非线性性,锤炼每个 token 的表征向量
解码器部分:
- 掩码自注意力层:捕获输出序列中的 token 和其前序 token 的间依赖,压缩到表征向量中(只向前看)
- 交叉注意力:将编码学到输入序列的 token 在句子中的相关性表征送给解码器,从而让新的表征向量既带有输入序列的信息、也带有输出前序 token 的信息。从而准备好了预测下一个 token 的所有信息。
- FNN 线性层:锤炼每个 token 的表征向量,增加一些非线性性
多层堆叠:通过残差和正则,以在保持训练稳定性的前提下加深网络。从而进行反复抽取提炼,以更多参数容纳更多信息量。

