This is an interview basics series I started on a whim while drawing with Procreate. It strives to be richly illustrated, with both code and videos, making it the best-looking interview series. Welcome likes, shares, and tips from those who enjoy it. If there is enough support, I will continue updating.
 3-basic-sort.png
3-basic-sort.png
Author: 木鸟杂记 https://www.qtmuniao.com/2023/09/18/three-basic-sort please indicate the source when reposting
{[order-list], [unorder-list]}
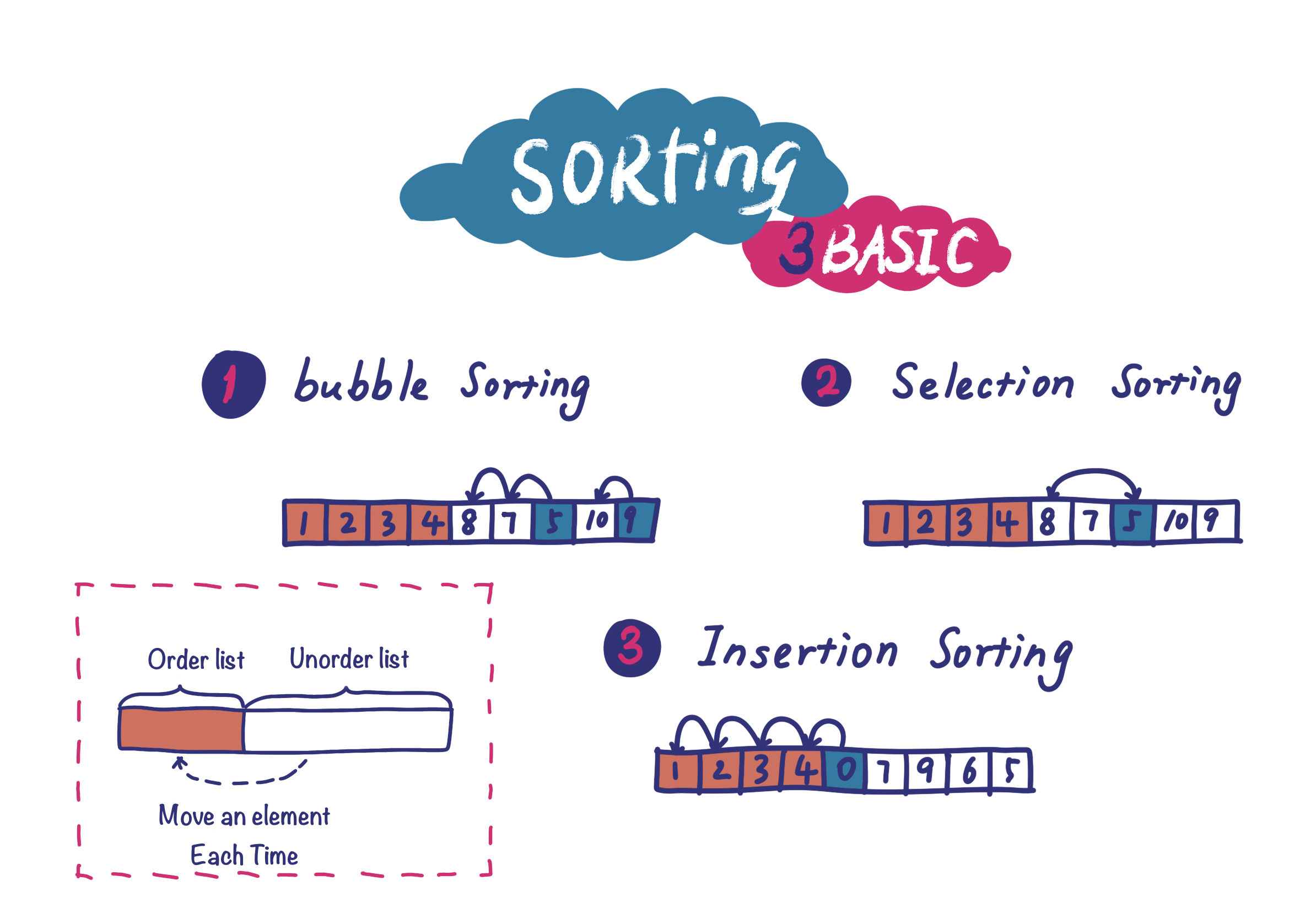
Bubble sort, selection sort, and insertion sort are the three most basic sorting algorithms. Their principles are connected:
- Divide the array into two subsets: the front is the ordered set, and the back is the unordered set.
- All three methods linearly move one element at a time from the unordered set to the ordered set, but the moving method differs:
- Bubble: Starting from the end of the unordered set, compare one by one and “bubble” one to the end of the ordered set.
- Selection: Traverse the unordered set, select one, and place it at the end of the ordered set.
- Insertion: Select one from the boundary and insert it into the appropriate position in the ordered set.
The complexity of all three sorting methods is O(n^2).
Bubble Sort
S-order <–bubble-- S-unorder
Like bubbles, each time let the smallest number bubble up from the remaining dataset (unordered) to the “surface,” reaching the ordered set.
Mnemonic:
- The array is divided into two parts; initially, the front is empty;
- Swap from the back and squeeze forward, terminate when the front is full and the back is empty.
Selection Sort
S-order <–selection-- S-unorder
Select the extreme value from the remaining dataset (unordered) and place it into the ordered set.
Mnemonic:
- The array is divided into two parts; initially, the front is empty;
- Select the extreme from the back and append to the front, terminate when the front is full and the back is empty.
Insertion Sort
S-order <–insertion-- S-unorder
Randomly pick a value from the remaining dataset (unordered), then compare and “insert” it (which can also be understood as bubbling forward) into the ordered set.
Mnemonic:
- The array is divided into two parts; initially, the front is empty;
- Select a value from the boundary and insert it into the front, terminate when the front is full and the back is empty.
The code repository is here. Welcome to open issues to let me know what common interview questions you’d like to see illustrated. If you find any omissions, PRs are also welcome.
Bilibili video: https://www.bilibili.com/video/BV1du41177iu
Youtube video: https://www.youtube.com/playlist?list=PLSISRu2b2N55Htp_3tUQoqMPP4EsTLGxv
Finally, if you like my articles, you can subscribe to my paid column “System Daily Notes” on Xiaobot, focusing on the most fundamental direction of the internet — large-scale data systems. It includes series on graph databases, code interpretation, high-quality English podcast translations, database learning, paper interpretation, and more. Welcome friends who like my articles to subscribe 👉 Column to support me. Your support is very important for me to continue creating high-quality articles.

