Introduction
In certain workloads, memory usage gradually grows over time until an OOM occurs. Later, it was found to be a memory fragmentation issue. Replacing the system’s default memory allocator (glibc malloc) with jemalloc can effectively control the upper bound of memory growth.
To understand the principles behind it, I sought out jemalloc’s original paper: A Scalable Concurrent malloc(3) Implementation for FreeBSD. Of course, compared to when the paper was published in 2006, the current jemalloc may have changed significantly. Therefore, this article is only responsible for the content of the paper at that time. For more jemalloc mechanisms, you can check the documentation and source code in its GitHub repository.
Background
Before discussing the main ideas of the paper, let’s briefly review the role and boundaries of a memory allocator. In short:
- Downward, it requests large chunks of memory from the operating system (using system calls like
sbrk,mmap) - Upward, it handles memory allocation requests of various sizes from the application layer (
malloc(size)), and releases them after the application layer indicates it is no longer needed (free)
In the simplest terms, the allocator’s functions are very simple: allocation and deallocation (malloc and free). One might imagine the implementation is also very straightforward—just use a table to keep track of all used and unallocated memory (a bit of bookkeeping), and then:
- When a malloc request comes in, first look in the free list; if there’s not enough, ask the OS for more
- When a free request comes in, return it to the free list; if there’s too much free memory, return it to the OS
Author: Muniao’s Notes https://www.qtmuniao.com/2024/10/27/jemalloc/ Please indicate the source when reposting
But to achieve efficient memory allocation and reclamation and to control memory utilization, there is a great deal of depth involved—CPU caches, RAM characteristics, and virtual memory all have an impact. The most central point is how to organize and arrange memory so that after users make highly concurrent, multi-sized, and unpredictably timed allocation and deallocation requests, it can still guarantee low call latency and high utilization. Of course, for this paper, there is one more point: more cores should support higher concurrency, which is called scalability.
It should be noted that one should not confuse the memory allocator in this article with various programming language runtimes that have automatic GC functionality (such as Java’s JVM, Golang’s Runtime). The latter builds another layer on top of malloc/free, automatically reclaiming space by tracking the lifecycle of each object through reference relationships between objects.
You can understand it this way: C/C and other languages require users to manage memory manually through malloc/free; while with Java/Golang/Python, users can blindly create new objects, and when to reclaim them is the job of the language “runtime.” This article only discusses the former.
But from another perspective, storage engines also implement similar functions. Because storage engines essentially also face user put/delete requests to perform storage allocation and deallocation. It’s just that the storage here is not limited to memory (storage engines are mostly disk-based). But the main ideas are very similar, such as using a free list to track allocatable memory.
Main Ideas
From the paper’s title, it can be seen that when jemalloc was proposed, it was mainly aimed at solving the problem of memory allocator performance scaling with the number of cores in the multi-core era. But in fact, the paper spends quite a lot of space explaining how to arrange memory layout to solve the fragmentation problem. Below, we will roughly explore its principles around these two directions.
Multi-core Concurrency
When allocating memory in the multi-core era, the main problems faced are:
- Lock contention
- Cache sloshing
To ensure the consistency of global data structures, some means (such as locks) must be introduced for coordination. But if multiple threads contend for locks too frequently, it will cause serious performance degradation. To reduce lock contention, the natural idea is to split the granularity of the main global data structures (for example, Java’s ConcurrentHashMap divides hash buckets into multiple segments for locking).
The most important data structure in an allocator is the free list. We can split the free list into multiple ones, each using a separate lock. This can alleviate the contention problem of multiple threads, but it cannot solve another problem of multi-core architecture—cache sloshing.
In a multi-core architecture, if two threads do not correctly share the cache. For example, thread A and thread B share a cache line, and the two threads will repeatedly modify different parts of the cache line. If A and B are scheduled to different CPUs, it will cause repeated contention for cache line ownership.
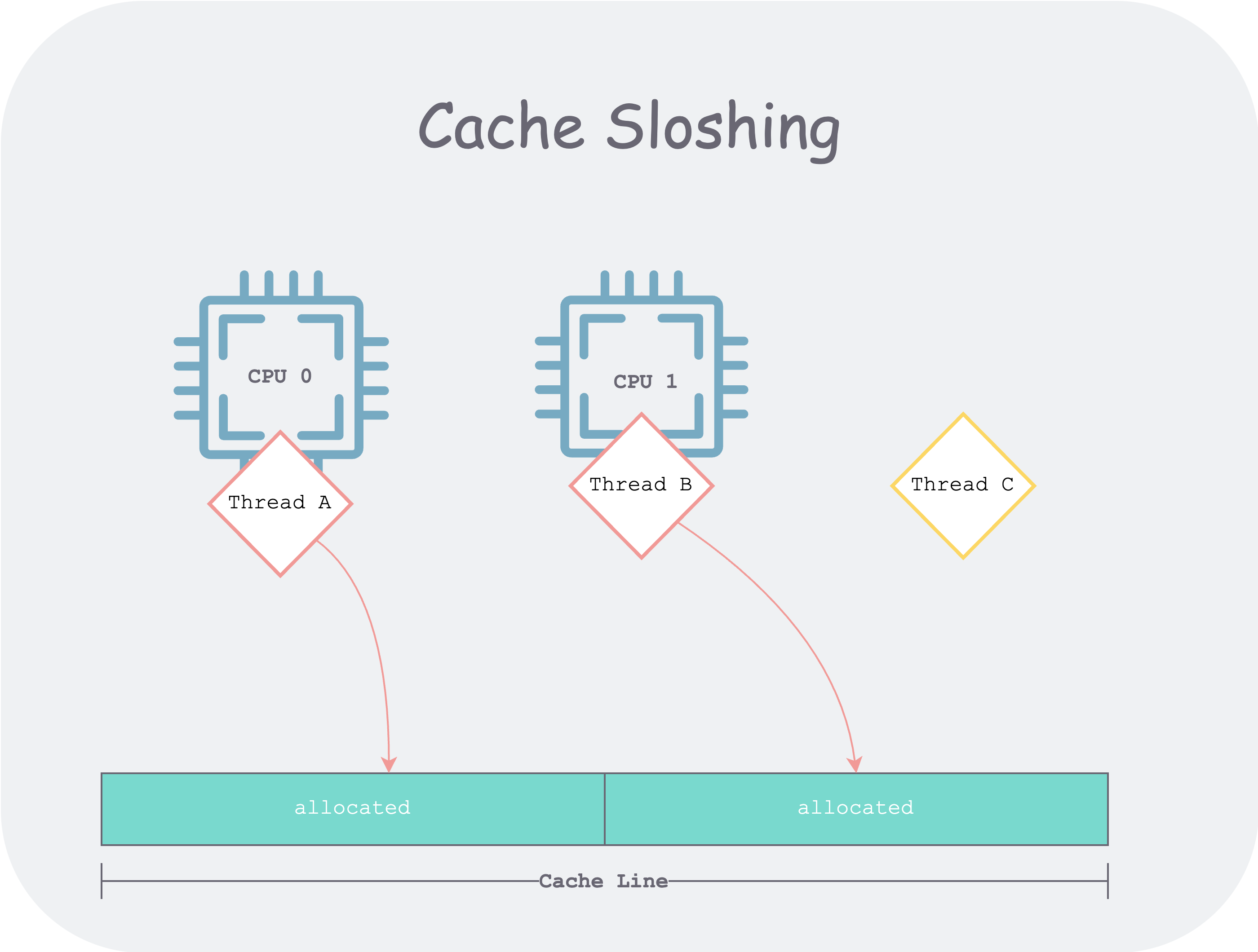 cache-sloshing.png
cache-sloshing.png
To solve this problem, jemalloc divides the managed memory into several regions (called Arenas, usually four times the number of CPU cores). When clients from different threads arrive, they are evenly bound (round robin) to an Arena, and all subsequent memory allocation and deallocation for that client occur within that Arena. The paper also mentions the hash method previously used by Larson and Krishnan (1998) for binding, but because the hashing process is pseudo-random, it is difficult to ensure uniformity of threads to Arenas.
Next, let’s discuss how to arrange memory within each Arena to respond to user object allocation and deallocation.
Memory Layout
Before starting the discussion, we first introduce an indicator to measure memory utilization—memory fragmentation, divided into internal fragmentation and external fragmentation. To understand this concept, we can think about how the “Hive Box” parcel locker works in daily life, using this imagery to compare and understand how the allocator arranges memory.
“Hive Box” generally asks the property management for a space to set up a parcel locker (corresponding to an Arena), providing nearby service to community residents. For each parcel locker, it is further divided into individual compartments, but how to divide them is the art.
Since packages usually vary in size, what would be the problem if the parcel locker were divided equally?
- For small packages, each compartment would waste a lot of space (internal fragmentation)
- For large packages, none of the compartments would fit (the total space is clearly sufficient, but it can’t fit; at this point, the entire compartment becomes external fragmentation)
To solve this problem, the parcel lockers we see in daily life usually have compartments of varying sizes. But there may still be couriers who choose a large compartment for a small package. For the real world, there is no solution, because all compartments are divided when the locker leaves the factory, that is, they are “statically allocated”; but in the computer world, our division of memory is “logical,” so we can achieve “dynamic allocation.”
If someone puts a small object in a large compartment, the remaining space can be split out to form a new compartment for later objects. And, after that small object is taken away, the two compartments can be merged back into a large compartment to accommodate larger objects.
This is the basic idea of the “buddy allocation algorithm,” which, of course, was not originally created by jemalloc. But jemalloc, based on the “binary buddy algorithm,” further refines memory management through statistics on user workloads, thereby controlling the uncontrolled growth of fragmentation.
For example, jemalloc found that most objects are no larger than 512 B, so it introduced “quantum-spaced.” For compartments near and below this size, it does not use the buddy algorithm but instead uses static allocation within a page, making them all compartments of the same size—what are the benefits of this? Since each compartment is the same size, a bitmap can be used as the free list, thereby speeding up free list lookups.
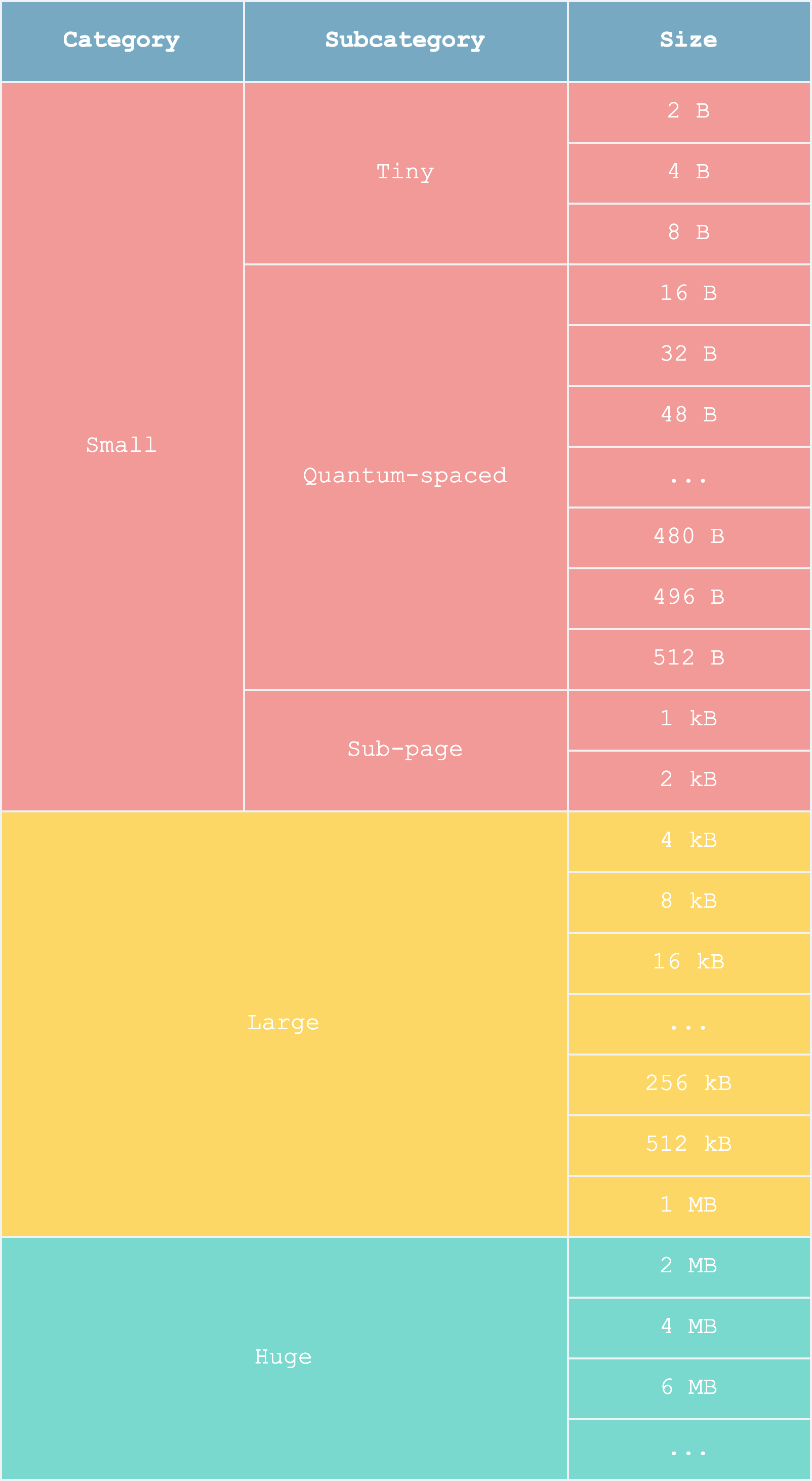 memory-layout.png
memory-layout.png
Although this refined management will bring more external fragmentation (many compartments cannot be used), it can more greatly reduce internal fragmentation (most compartments can be fully utilized), making it a worthwhile trade-off.
Evaluation
Because in practice, the memory workloads of different applications vary greatly, measuring allocator quality is itself a very complex problem. It is very likely that after an allocator is designed, it performs well in some user workloads but extremely poorly in others. At this point, it is difficult to say that it is a good allocator. A good allocator should be balanced in most aspects and outstanding in some aspects—because when facing such a complex real world, it is impossible to be good in all aspects; there will always be trade-offs.
Therefore, the authors spent a great deal of effort designing a set of allocator performance evaluation tools to prove jemalloc’s advantages, but this part is not the focus of this article. Interested readers can refer to the original paper.
Summary
We first laid out some background on memory allocators, explaining what an allocator is (malloc/free), what it is not (auto GC), and what it is similar to (storage engine put/get). Then we analyzed the main goal of implementing jemalloc in the paper—multi-core scalability. Next, we discussed its main implementation ideas: to avoid contention and cache sloshing, it introduces even memory partitioning; to reduce fragmentation, it refines the management of partitioned memory based on the buddy algorithm, and uses the “Hive Box parcel locker” analogy to aid understanding.
Finally, we mentioned how to evaluate the quality of an allocator. It should be emphasized that this article aims to help you build intuition. For any points you wish to investigate further, we strongly recommend reading the original paper.
References
- A Scalable Concurrent malloc(3) Implementation for FreeBSD
- Memory Allocation for Long-Running Server Applications

