导读
继 Spark 之后,UC Berkeley AMP 实验室又推出一重磅高性能AI计算引擎——Ray,号称支持每秒数百万次任务调度。那么它是怎么做到的呢?在试用之后,简单总结一下:
- 极简 Python API 接口:在函数或者类定义时加上
ray.remote的装饰器并做一些微小改变,就能将单机代码变为分布式代码。这意味着不仅可以远程执行纯函数,还可以远程注册一个类(Actor模型),在其中维护大量context(成员变量),并远程调用其成员方法来改变这些上下文。 - 高效数据存储和传输:每个节点上通过共享内存(多进程访问无需拷贝)维护了一块局部的对象存储,然后利用专门优化过的 Apache Arrow格式来进行不同节点间的数据交换。
- 动态图计算模型:这一点得益于前两点,将远程调用返回的 future 句柄传给其他的远程函数或者角色方法,即通过远程函数的嵌套调用构建复杂的计算拓扑,并基于对象存储的发布订阅模式来进行动态触发执行。
- 全局状态维护:将全局的控制状态(而非数据)利用 Redis 分片来维护,使得其他组件可以方便的进行平滑扩展和错误恢复。当然,每个 redis 分片通过 chain-replica 来避免单点。
- 两层调度架构:分本地调度器和全局调度器;任务请求首先被提交到本地调度器,本地调度器会尽量在本地执行任务,以减少网络开销。在资源约束、数据依赖或者负载状况不符合期望时,会转给全局调度器来进行全局调度。
当然,还有一些需要优化的地方,比如 Job 级别的封装(以进行多租户资源配给),待优化的垃圾回收算法(针对对象存储,现在只是粗暴的 LRU),多语言支持(最近支持了Java,但不知道好不好用)等等。但是瑕不掩瑜,其架构设计和实现思路还是有很多可以借鉴的地方。
作者:木鸟杂记 https://www.qtmuniao.com, 转载请注明出处
动机和需求
(开发 Ray 的动机始于强化学习(RL),但是由于其计算模型强大表达能力,使用绝不限于 RL。这一小节是以描述 RL 系统需求为契机,引出 Ray 的初始设计方向。但是由于不大熟悉强化学习,一些名词可能表达翻译不准确。如果只对其架构感兴趣,完全可以跳过这一节)
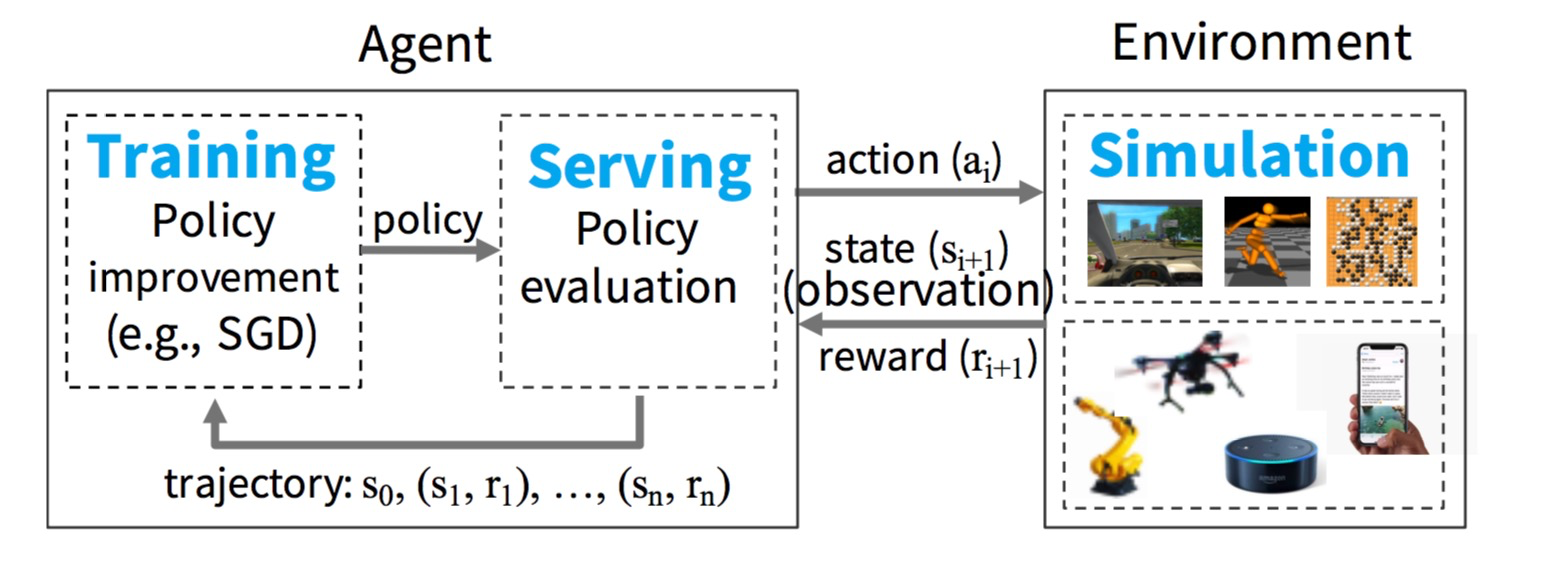
图1:一个 RL 系统的例子
我们从考虑 RL 系统的基本组件开始,逐渐完善 Ray 的需求。如图1所示,在一个 RL 系统的的设定中,智能体(agent)会反复与环境(environment)进行交互。智能体的目标是学习出一种最大化奖励(reward)的策略。策略(policy)本质上是从环境中状态到行为抉择(action)的一种映射。至于环境,智能体,状态,行为和奖励值的详细定义,则是由具体的应用所决定的。
为了学习策略,智能体通常要进行两步操作:1)策略评估(policy evaluation)和 2)策略优化(policy improvement)。为了评估一个策略,智能体和环境持续进行交互(一般是仿真的环境)以产生轨迹(trajectories)。轨迹是在当前环境和给定策略下产生的一个二元组(状态,奖励值)序列。然后,智能体根据这些轨迹来反馈优化该策略,即,向最大化奖励值的梯度方向更新策略。图2展示了智能体用来学习策略一个例子的伪码。该伪码通过调用 rollout(environment, policy) 来评估策略,进而产生仿真轨迹。train_policy() 接着会用这些轨迹作为输入,调用 policy.update(trajectories) 来优化当前策略。会重复迭代这个过程直到策略收敛。
1 | // evaluate policy by interacting with env. (e.g., simulator) |
图2:一段用于学习策略的典型的伪代码
由此看来,针对 RL 应用的计算框架需要高效的支持模型训练(training),在线预测(serving)和平台仿真(simulation)(如图1所示)。接下来,我们简要说明一下这些工作负载(workloads)。
模型训练一般会涉及到在分布式的环境中跑随机梯度下降模型(stochastic gradient descent,SGD)来更新策略。而分布式 SGD 通常依赖于 allreduce 聚合步骤或参数服务器(parameter server).
在线预测 使用已经训练好的策略并基于当前环境来给出动作决策。预测系统通常要求降低预测延迟,提高决策频次。为了支持扩展,最好能够将负载均摊到多节点上来协同进行预测。
最后,大多数现存的 RL 应用使用仿真(simulations) 来对策略进行评估——因为现有的 RL 算法不足以单独依赖从与物理世界的交互中高效的进行取样。这些仿真器在复杂度上跨度极大。也许只需要几毫秒(如模拟国际象棋游戏中的移动),也许会需要几分钟(如为了一个自动驾驶的车辆模拟真实的环境)。
与模型训练和在线预测可以在不同系统中进行处理的监督学习相比, RL 中所有三种工作负载都被紧耦合在了单个应用中,并且对不同负载间的延迟要求很苛刻。现有的系统中还没有能同时支持三种工作负载的。理论上,可以将多个专用系统组合到一块来提供所有能力,但实际上,子系统间的结果传输的延迟在 RL 下是不可忍受的。因此,RL 的研究人员和从业者不得不针对每个需求单独构建多套一次性的专用系统。
这些现状要求为 RL 开发全新的分布式框架,可以有效地支持训练,预测和仿真。尤其是,这样的框架应具有以下能力:
支持细粒度,异构的计算。RL 计算的运行持续时间往往从数毫秒(做一个简单的动作)到数小时(训练一个复杂的策略)。此外,模型训练通常需要各种异构的硬件支持(如CPU,GPU或者TPU)。
提供灵活的计算模型。RL 应用同时具有有状态和无状态类型的计算。无状态的计算可以在系统中的任何节点进行执行,从而可以方便的进行负载均衡和按需的数据传输。因此,无状态的计算非常适合细粒度的仿真和数据处理,例如从视频或图片中提取特征。相比之下,有状态的计算适合用来实现参数服务器、在支持 GPU 运算的数据上进行重复迭代或者运行不暴露内部状态参数的第三方仿真器。
动态的执行能力。RL 应用中的很多模块要求动态的进行执行,因为他们计算完成的顺序并不总是预先确定(例如:仿真的完成顺序),并且,一个计算的运行结果可以决定是否执行数个将来的计算(如,某个仿真的运行结果将决定我们是否运行更多的仿真)。
除此之外,我们提出了两个额外的要求。首先,为了高效的利用大型集群,框架必须支持每秒钟数百万次的任务调度。其次,框架不是为了支持从头开始实现深度神经网络或者复杂的仿真器,而是必须和现有的仿真器(OpenAI gym等)和深度学习框架(如TensorFlow,MXNet,Caffe, PyTorch)无缝集成。
语言和计算模型
Ray 实现了动态任务图计算模型,即,Ray 将应用建模为一个在运行过程中动态生成依赖的任务图。在此模型之上,Ray 提供了角色模型(Actor)和并行任务模型(task-parallel)的编程范式。Ray 对混合计算范式的支持使其有别于与像 CIEL 一样只提供并行任务抽象和像 Orleans 或 Akka 一样只提供角色模型抽象的系统。
编程模型
任务模型(Tasks)。一个任务表示一个在无状态工作进程执行的远程函数(remote function)。当一个远程函数被调用的时候,表示任务结果的 future 会立即被返回(也就是说所有的远程函数调用都是异步的,调用后会立即返回一个任务句柄)。可以将 Futures传给 ray.get() 以阻塞的方式获取结果,也可以将 Futures 作为参数传给其他远程函数,以非阻塞、事件触发的方式进行执行(后者是构造动态拓扑图的精髓)。Futures 的这两个特性让用户在构造并行任务的同时指定其依赖关系。下表是 Ray 的所有 API(相当简洁而强大,但是实现起来会有很多坑,毕竟所有装饰有 ray.remote 的函数或者类及其上下文都要序列化后传给远端节点,序列化用的和 PySpark 一样的 cloudpickle)。
| Name | Description |
|---|---|
| futures = f.remote(args) | Execute function f remotely. f.remote() can take objects or futures as inputs and returns one or more futures. This is non-blocking. |
| objects = ray.get(futures) | Return the values associated with one or more futures. This is blocking. |
| ready futures = ray.wait(futures, k, timeout) | Return the futures whose corresponding tasks have completed as soon as either k have completed or the timeout expires. |
| actor = Class.remote(args) futures = actor.method.remote(args) |
Instantiate class Class as a remote actor, and return a handle to it. Call a method on the remote actor and return one or more futures. Both are non-blocking. |
表1 Ray API
远程函数作用于不可变的物体上,并且应该是无状态的并且没有副作用的:这些函数的输出仅取决于他们的输入(纯函数)。这意味着幂等性(idempotence),获取结果出错时只需要重新执行该函数即可,从而简化容错设计。
角色模型(Actors)。一个角色对象代表一个有状态的计算过程。每个角色对象暴露了一组可以被远程调用,并且按调用顺序依次执行的成员方法(即在同一个角色对象内是串行执行的,以保证角色状态正确的进行更新)。一个角色方法的执行过程和普通任务一样,也会在远端(每个角色对象会对应一个远端进程)执行并且立即返回一个 future;但不同的是,角色方法会运行在一个有状态(stateful)的工作进程上。一个角色对象的句柄(handle)可以传递给其他角色对象或者远程任务,从而使他们能够在该角色对象上调用这些成员函数。
| Tasks | Actors |
|---|---|
| 细粒度的负载均衡 | 粗粒度的负载均衡 |
| 支持对象的局部性(对象存储cache) | 比较差的局部性支持 |
| 微小更新开销很高 | 微小更新开销不大 |
| 高效的错误处理 | 检查点(checkpoint)恢复带来较高开销 |
表2 任务模型 vs. 角色模型的对比
表2 比较了任务模型和角色模型在不同维度上的优劣。任务模型利用集群节点的负载信息和依赖数据的位置信息来实现细粒度的负载均衡,即每个任务可以被调度到存储了其所需参数对象的空闲节点上;并且不需要过多的额外开销,因为不需要设置检查点和进行中间状态的恢复。与之相比,角色模型提供了极高效的细粒度的更新支持,因为这些更新作用在内部状态(即角色成员变量所维护的上下文信息)而非外部对象(比如远程对象,需要先同步到本地)。后者通常来说需要进行序列化和反序列化(还需要进行网络传输,因此往往很费时间)。例如,角色模型可以用来实现参数服务器(parameter servers)和基于GPU 的迭代式计算(如训练)。此外,角色模型可以用来包裹第三方仿真器(simulators)或者其他难以序列化的对象(比如某些模型)。
为了满足异构性和可扩展性,我们从三个方面增强了 API 的设计。首先,为了处理长短不一的并发任务,我们引入了 ray.wait() ,它可以等待前 k 个结果满足了就返回;而不是像 ray.get() 一样,必须等待所有结果都满足后才返回。其次,为了处理对不同资源纬度( resource-heterogeneous)需求的任务,我们让用户可以指定所需资源用量(例如装饰器:ray.remote(gpu_nums=1)),从而让调度系统可以高效的管理资源(即提供一种交互手段,让调度系统在调度任务时相对不那么盲目)。最后,为了提灵活性,我们允许构造嵌套远程函数(nested remote functions),意味着在一个远程函数内可以调用另一个远程函数。这对于获得高扩展性是至关重要的,因为它允许多个进程以分布式的方式相互调用(这一点是很强大的,通过合理设计函数,可以使得可以并行部分都变成远程函数,从而提高并行性)。
计算模型
Ray 采用的动态图计算模型,在该模型中,当输入可用(即任务依赖的所有输入对象都被同步到了任务所在节点上)时,远程函数和角色方法会自动被触发执行。在这一小节,我们会详细描述如何从一个用户程序(图3)来构建计算图(图4)。该程序使用了表1 的API 实现了图2 的伪码。
1 |
|
图3:在 Ray 中实现图2逻辑的代码,注意装饰器 @ray.remote 会将被注解的方法或类声明为远程函数或者角色对象。调用远程函数或者角色方法后会立即返回一个 future 句柄,该句柄可以被传递给随后的远程函数或者角色方法,以此来表达数据间的依赖关系。每个角色对象包含一个环境对象 self.env ,这个环境状态为所有角色方法所共享。
在不考虑角色对象的情况下,在一个计算图中有两种类型的点:数据对象(data objects)和远程函数调用(或者说任务)。同样,也有两种类型的边:数据边(data edges)和控制边(control edges)。数据边表达了数据对象任务间的依赖关系。更确切来说,如果数据对象 D 是任务 T 的输出,我们就会增加一条从 T 到 D 的边。类似的,如果 D 是 任务 T 的输入,我们就会增加一条 D 到 T 的边。控制边表达了由于远程函数嵌套调用所造成的计算依赖关系,即,如果任务 T1 调用任务 T2, 我们就会增加一条 T1 到 T2 的控制边。
在计算图中,角色方法调用也被表示成了节点。除了一个关键不同点外,他们和任务调用间的依赖关系基本一样。为了表达同一个角色对象上的连续方法调用所形成的状态依赖关系,我们向计算图添加第三种类型的边:在同一个角色对象上,如果角色方法 Mj 紧接着 Mi 被调用,我们就会添加一条 Mi 到 Mj 的状态边(即 Mi 调用后会改变角色对象中的某些状态,或者说成员变量;然后这些变化后的成员变量会作为 Mj 调用的隐式输入;由此,Mi 到 Mj 间形成了某种隐式依赖关系)。这样一来,作用在同一角色对象上的所有方法调用会形成一条由状态边串起来的调用链(chain,见图4)。这条调用链表达了同一角色对象上方法被调用的前后相继的依赖关系。
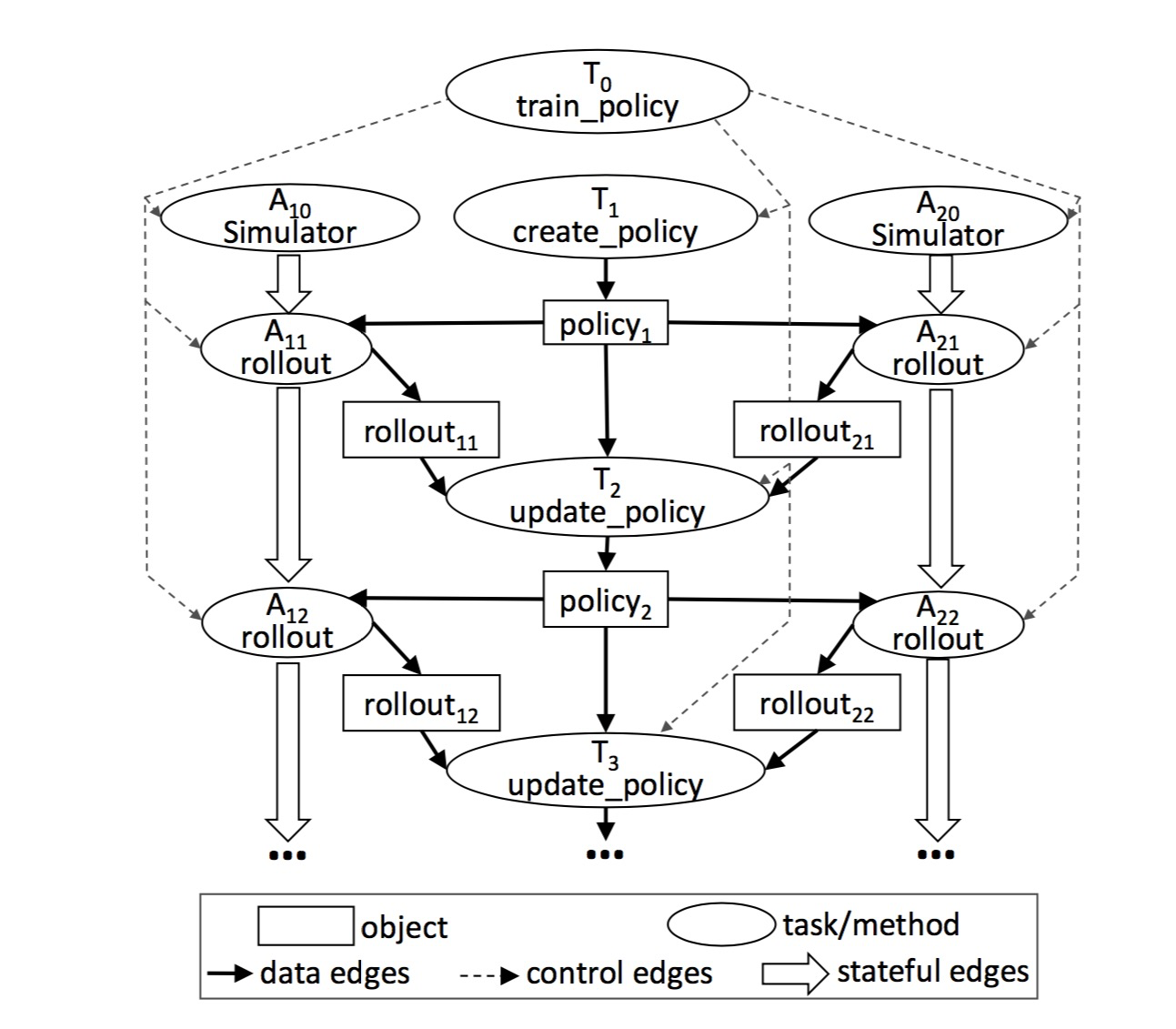
图4:该图与图3 train_policy.remote() 调用相对应。远程函数调用和角色方法调用对应图中的任务(tasks)。该图中显示了两个角色对象A10和A20,每个角色对象的方法调用(被标记为 A1i 和 A2i 的两个任务)之间都有状态边(stateful edge)连接,表示这些调用间共享可变的角色状态。从 train_policy 到被其调用的任务间有控制边连接。为了并行地训练多种策略,我们可以调用 train_policy.remote() 多次。
状态边让我们将角色对象嵌入到无状态的任务图中,因为他们表达出了共享状态、前后相继的两个角色方法调用之间的隐式数据依赖关系。状态边的添加还可以让我们维护谱系图(lineage),如其他数据流系统一样,我们也会跟踪数据的谱系关系以在必要的时候进行数据的重建。通过显式的将状态边引入数据谱系图中,我们可以方便的对数据进行重建,不管这些数据是远程函数产生的还是角色方法产生的(小节4.2.3中会详细讲)。
架构
Ray 的架构组成包括两部分:
- 实现 API 的应用层,现在包括 Python 和 Java分别实现的版本。
- 提供高扩展性和容错的系统层,用 C++ 写的,以CPython的形式嵌入包中。
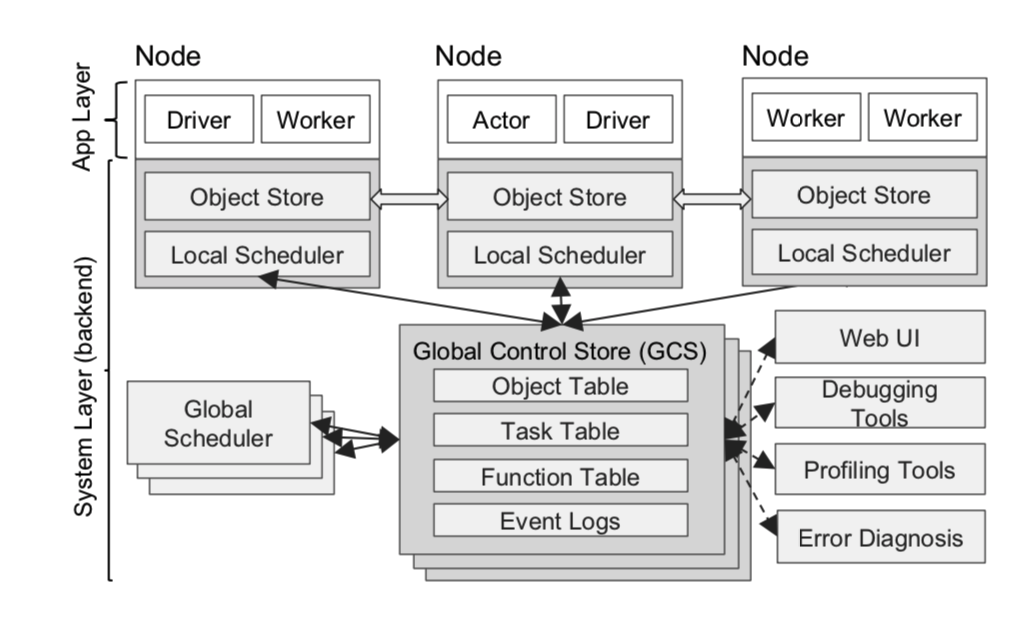
图5:Ray 的架构包括两部分:系统层和应用层。前者实现了API和计算模型,后者实现了任务调度和数据管理,以满足性能要求和容错需求
应用层
应用层包括三种类型的进程:
- 驱动进程(Driver): 用来执行用户程序。
- 工作进程(Worker):用来执行 Driver 或者其他 Worker 指派的任务(remote functions,就是用户代码中装饰了
@ray.remote的那些函数)的无状态进程。工作进程在节点启动时被自动启动,一般来说会在每个物理机上启动与 CPU 同样数量的 Worker(这里还有些问题:如果节点是容器的话,获取的仍然是其所在物理机的 CPU 数)。当一个远程函数被声明时,会被注册到全局,并推送到所有 Worker。每个 Worker 顺序的执行任务,并且不维护本地状态。 - 角色进程(Actor):用来执行角色方法的有状态进程。与 Worker 被自动的启动不同,每个 Actor 会根据需求(即被调用时)被工作进程或者驱动进程显示启动。和 Worker 一样,Actor 也会顺序的执行任务,不同的是,下一个任务的执行依赖于前一个任务生成或改变的状态(即 Actor 的成员变量)。
系统层
系统层包括三个主要组件:全局控制存储(GCS,global control store),分布式调度器(distributed scheduler)和分布式对象存储(distributed object store)。所有组件都可以进行水平扩展并且支持容错。
全局控制存储(GCS)
全局状态存储维护着系统全局的控制状态信息,是我们系统独创的一个部件。其核心是一个可以进行发布订阅的键值对存储。我们通过分片(sharding)来应对扩展,每片存储通过链式副本(将所有数据副本组织成链表,来保证强一致性,见04年的一篇论文)来提供容错。提出和设计这样一个GCS的动机在于使系统能够每秒进行数百万次的任务创建和调度,并且延迟较低,容错方便。
对于节点故障的容错需要一个能够记录谱系信息(lineage information)的方案。现有的基于谱系的解决方法侧重粗粒度(比如 Spark 的 rdd)的并行,因此可以只利用单个节点(如Master or Driver)存储谱系信息,而不影响性能。然而,这种设计并不适合像仿真(simulation)一样的细粒度、动态的作业类型(workload)。因此我们将谱系信息的存储与系统其它模块解耦,使之可以独立地动态扩容。
保持低延迟意味着要尽可能降低任务调度的开销。具体来说,一个调度过程包括选择节点,分派任务,拉取远端依赖对象等等。很多现有的信息流系统,将其所有对象的位置、大小等信息集中存储在调度器上,使得上述调度过程耦合在一块。当调度器不是瓶颈的时候,这是一个很简单自然的设计。然而,考虑到 Ray 要处理的数据量级和数据粒度,需要将中心调度器从关键路径中移出(否则如果所有调度都要全局调度器经手处理,它肯定会成为瓶颈)。对于像 allreduce 这样的(传输频繁,对延迟敏感)分布式训练很重要的原语来说,每个对象传输时都经手调度器的开销是不可容忍的。 因此,我们将对象的元数据存储在 GCS 中而不是中央调度器里,从而将任务分派与任务调度完全解耦。
总的来说,GCS 极大地简化了 Ray 的整体设计,因为它将所有状态揽下,从而使得系统中其他部分都变成无状态。这不仅使得对容错支持简化了很多(即,每个故障节点恢复时只需要从 GCS 中读取谱系信息就行),也使得分布式的对象存储和调度器可以进行独立的扩展(因为所有组件可以通过 GCS 来获取必要的信息)。还有一个额外的好处,就是可以更方便的开发调试、监控和可视化工具。
自下而上的分布式调度系统(Bottom-up Distributed Scheduler)
如前面提到的,Ray 需要支持每秒数百万次任务调度,这些任务可能只持续短短数毫秒。大部分已知的调度策略都不满足这些需求。常见的集群计算框架,如 Spark, CIEL, Dryad 都实现了一个中心的调度器。这些调度器具有很好的局部性(局部性原理)的特点,但是往往会有数十毫秒的延迟。像 work stealing,Sparrow 和 Canary 一样的的分布式调度器的确能做到高并发,但是往往不考虑数据的局部性特点,或者假设任务(tasks)属于不同的作业(job),或者假设计算拓扑是提前知道的。
为了满足上述需求,我们设计了一个两层调度架构,包括一个全局调度器(global scheduler)和每个节点上的本地调度器(local scheduler)。为了避免全局调度器过载,每个节点(node)上创建的任务会被先提交到本地调度器。本地调度器总是先尝试将任务在本地执行,除非其所在机器过载(比如任务队列超过了预定义的阈值)或者不能满足任务任务的资源需求(比如,缺少 GPU)。如果本地调度器发现不能在本地执行某个任务,会将其转发给全局调度器。由于调度系统都倾向于首先在本地调度任务(即在调度结构层级中的叶子节点),我们将其称为自下而上的调度系统(可以看出,本地调度器只是根据本节点的局部负载信息进行调度,而全局调度器会根据全局负载来分派任务;当然前提是资源约束首先得被满足)。
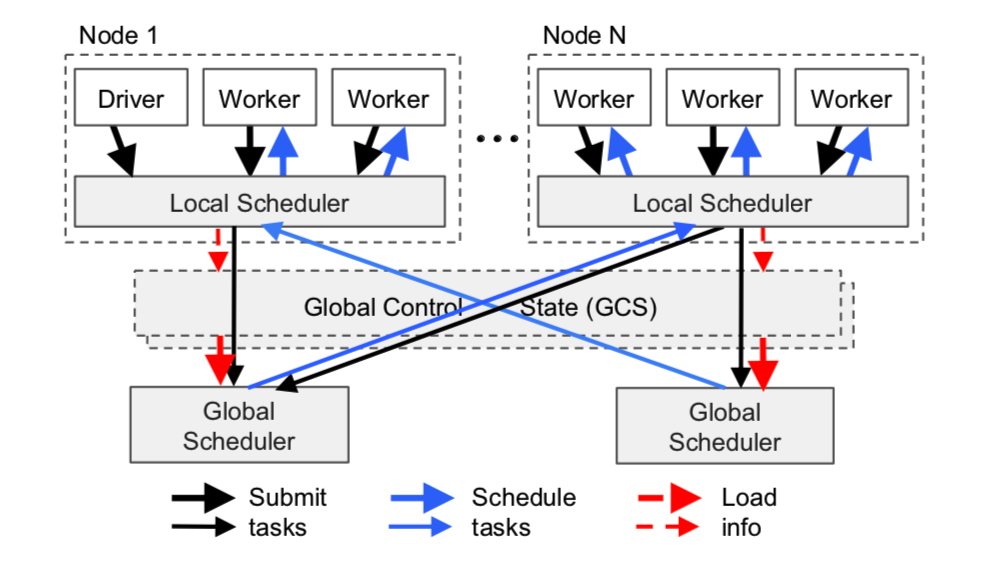
图6 这是调度系统示意图,任务自下而上被提交:任务首先被驱动进程(Drivers)或者工作进程(Workers)提交到本地调度器,然后在需要的时候会由本地调度器转给全局调度器进行处理。图中箭头的粗细程度代表其请求的繁忙程度。
全局调度器根据每个节点的负载状况和资源请求约束来决定调度策略。细化一下就是,全局调度器首先确定所有满足任务资源要求的节点,然后在其中选择具有最小预估排队时间(estimated waiting time)的一个,将任务调度过去。在给定的节点上,预估排队时间是下述两项时间的和:1)任务在节点上的排队时间 (任务队列长度乘上平均执行时间); 2)任务依赖的远程对象的预估传输时间(所有远程输入的大小除以平均带宽)。全局调度器通过心跳获取到每个节点的任务排队情况和可用资源信息,从 GCS 中得到任务所有输入的位置和大小。然后,全局调度器通过移动指数平均(exponential averaging)的方法来计算任务平均执行时间和平均传输带宽。如果全局调度器成为了系统瓶颈,我们可以实例化更多的副本来分摊流量,它们通过 GCS来共享全局状态信息。如此一来,我们的调度架构具有极高可扩展性。
任务生命周期
(注:这部分是从代码中的设计文档翻译而来,注意这只是截止到2019.04.21 的设计)
在实现的时候,每个任务具有以下几种状态。任意时刻,任务都会处在这几种状态之一。
- **可放置(Placeable)**:任务已经准备好被调度到(本地或者远程)节点上,具体如何调度,前一段已经说明。注意该状态不表示放置位置已经最终确定,还可能被再一次被从某处调度出去。
- **等待角色创建(WaitActorCreation)**:一个角色方法(task)等待其所在角色实例化完毕。一旦角色被创建,该任务会被转给运行该角色的远端机器进行处理。
- **等待中(Waiting)**:等待该任务参数需求被满足,即,等待所有远端参数对象传送到本地对象存储中。
- **准备好(Ready)**:任务准备好了被运行,也就说所有所需参数已经在本地对象存储中就位了。
- **运行中(Running)**:任务已经被分派,并且正在本地工作进程(worker)或者角色进程(actor)中运行。
- **被阻塞(Blocked)**:当前任务由于其依赖的数据不可用而被阻塞住。如,嵌套调用时,该任务启动了另外的远程任务并且等待其完成,以取得结果。
- **不可行(infeasible)**:任务的资源要求在任何一台机器上都得不到满足。
1 | --------------------------------- |
基于内存的分布式对象存储
为了降低任务的延迟,我们实现了一个基于内存的分布式存储系统以存储每个任务(无状态的计算过程)的输入和输出。在每个节点上,我们以共享内存(shared memory)的方式实现了对象存储。这使得同一节点上的不同任务以零拷贝的代价进行数据共享。至于数据格式,我们选择了 Apache Arrow。
如果一个任务的输入(即函数的参数对象)不在本地,在该任务执行之前,输入会被拷贝到本地的对象存储中。同时,任务执行完毕后,会将输出也写到本地得对象存储中。对象拷贝消除了热数据所造成的潜在的瓶颈,并且通过将任务的数据读写都限制在本地内存中以缩短执行时间。这些做法增加了计算密集型工作任务的吞吐量,而很多 AI 应用都是计算密集型的。为了降低延迟,我们将用到的对象全部放在内存中,只有在内存不够的时候才通过 LRU 算法将一些对象挤出内存(从API 可以看出,每个节点的内存上限可以在启动节点时通过参数指定。此外用 LRU 作为垃圾回收算法还是有点粗暴,如果不同类型的任务负载跑在同一个 ray 集群上,可能导致资源的互相争抢,从而有大量的资源换出然后重建,从而严重影响效率)。
和现有的计算框架的集群(如Spark, Dryad)一样,对象存储只接受不可变数据(immutable data)。这种设计避免了对复杂的一致性协议的需求(因为对象数据从来不需要进行更新),并且简化了数据的容错支持。当有节点出现故障时,Ray 通过重新执行对象谱系图来恢复任意所需对象(也就是说不用整个恢复该宕机节点所有状态,只需要按需恢复后面计算所需数据,用不到的数据丢了就丢了吧)。在工作开始之前,存放在 GCS 的谱系信息追踪了所有无状态的任务和有状态的角色;我们利用前者对丢失对象进行重建(结合上一段,如果一个任务有大量的迭代,并且都是远程执行,会造成大量的中间结果对象,将内存挤爆,从而使得较少使用但是稍后可能使用的全局变量挤出内存,所以 LRU 有点粗暴,听说现在在酝酿基于引用计数的GC)。
为了简化实现,我们的对象存储不支持分布式的对象。也就是说,每个对象必须能够在单节点内存下,并且只存在于单节点中。对于大矩阵、树状结构等大对象,可以在应用层来拆分处理,比如说实现为一个集合。
实现
Ray 是一个由加州大学伯克利分校开发的一个活跃的开源项目。Ray 深度整合了 Python,你可以通过 pip install ray 来安装 ray。整个代码实现包括大约 40K 行,其中有 72% C++ 实现的系统层和 28% 的 Python 实现的应用层(截止目前,又增加了对 Java 的支持)。GCS 的每个分片使用了一个 Redis 的 key-val 存储,并且只设计单个键值对操作。GCS 的表通过按任务ID、数据对象集合进行切分来进行平滑扩展。每一片利用链式冗余策略(chained-replcated)来容错。我们将本地调度器和全局调度器都实现为了单线程、事件驱动的进程。本地调度器缓存了本地对象元信息,被阻塞的任务队列和等待调度的任务队列。为了在不同节点的对象存储之间无感知的传输超大对象,我们将大对象切片,利用多条 TCP 连接来并行传。
将所有碎片捏一块
图 7 通过一个简单的 a 加 b (a,b可以是标量,向量或者矩阵)然后返回 c 的例子展示了 Ray 端到端的工作流。远程函数 add() 在初始化 ( ray.init ) 的时候,会自动地被注册到 GCS 中,进而分发到集群中的每个工作进程。(图7a 的第零步)
图7a 展示了当一个驱动进程(driver)调用 add.remote(a, b) ,并且 a, b 分别存在节点 N1 和 N2 上时 ,Ray 的每一步操作。驱动进程将任务 add(a, b) 提交到本地调度器(步骤1),然后该任务请求被转到全局调度器(步骤2)(如前所述,如果本地任务排队队列没有超过设定阈值,该任务也可以在本地进行执行)。接着,全局调度器开始在 GCS 中查找 add(a, b) 请求中参数 a, b 的位置(步骤3),从而决定将该任务调度到节点 N2 上(因为 N2 上有其中一个参数 b)(步骤4)。N2 节点上的本地调度器收到请求后(发现满足本地调度策略的条件,如满足资源约束,排队队列也没超过阈值,就会在本地开始执行该任务),会检查本地对象存储中是否存在任务 add(a, b) 的所有输入参数(步骤5)。由于本地对象存储中没有对象 a,工作进程会在 GCS 中查找 a 的位置(步骤6)。 这时候发现 a 存储在 N1 中,于是将其同步到本地的对象存储中(步骤7)。由于任务 add() 所有的输入参数对象都存在了本地存储中,本地调度器将在本地工作进程中执行 add() (步骤8),并通过共享存储访问输入参数(步骤9)。
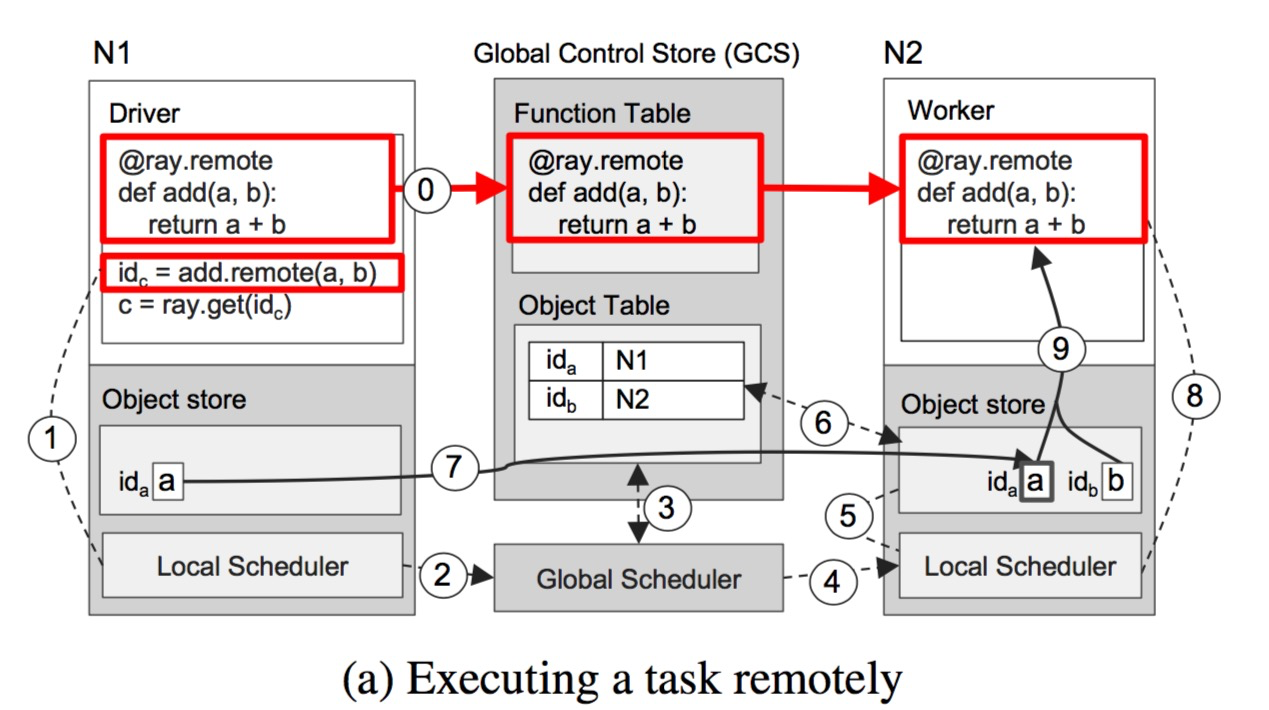
图 7b 展现了在 N1 上执行 ray.get() 和在 N2 上执行 add()后所触发的逐步的操作。一旦 ray.get(id)被调用,N1 上的用户驱动进程会在本地对象存储中查看该 id (即由远程调用 add() 返回的 future 值,所有 object id 是全局唯一的,GCS 可以保证这一点)对应的对象 c 是否存在(步骤1)。由于本地对象存储中没有 c , 驱动进程会去 GCS 中查找 c 的位置。在此时,发现 GCS 中并没有 c 的存在,因为 c 根本还没有被创建出来。 于是,N1 的对象存储向 GCS 中的对象表(Object Table)注册了一个回调函数,以监听 c 对象被创建事件(步骤2)。与此同时,在节点 N2 上,add() 任务执行完毕,将结果 c 存到其本地对象存储中(步骤3),同时也将 c 的位置信息添加到 GCS 的对象存储表中(步骤4)。GCS 监测到 c 的创建,会去触发之前 N1 的对象存储注册的回调函数(步骤5)。接下来,N1 的对象存储将 c 从 N2 中同步过去(步骤6),从而结束该任务。
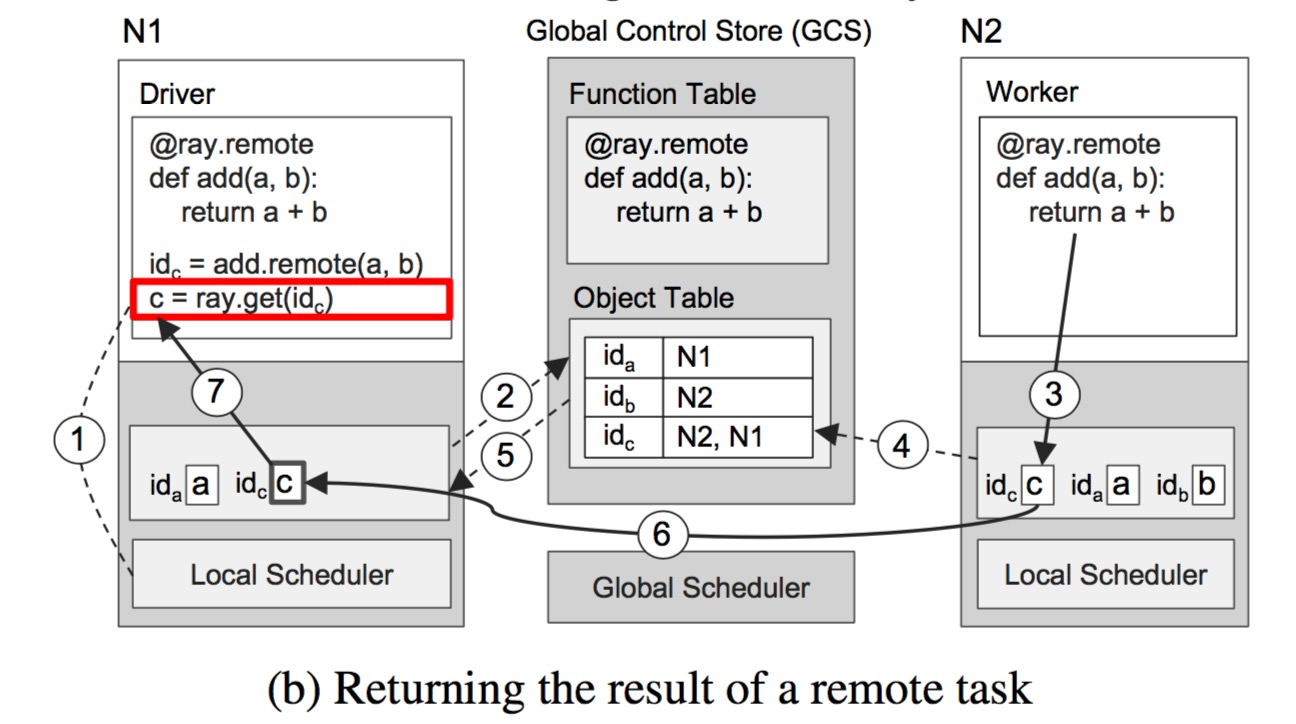
尽管这个例子中涉及了大量的 RPC调用,但对于大部分情况来说,RPC 的数量会小的多,因为大部分任务会在本地被调度执行,而且 GCS 回复的对象信息会被本地调度器和全局调度器缓存(但是另一方面,执行了大量远程任务之后,本地对象存储很容易被撑爆)。
名词对照
workloads:工作负载,即描述任务需要做的工作。
GCS: Global Control Store,全局控制信息存储。
Object Table:存在于 GCS 中的对象表,记录了所有对象的位置等信息(objectId -> location)。
Object Store:本地对象存储,在实现中叫 Plasma,即存储任务所需对象的实例。
Lineage:血统信息,谱系信息;即计算时的数据变换前后的相继关系图。
Node:节点;Ray 集群中的每个物理节点。
Driver、Worker:驱动进程和工作进程,物理表现形式都是 Node 上的进程。但前者是用户侧使用 ray.init 时候生成的,随着 ray.shutdown 会进行销毁。后者是 ray 在启动的时在每个节点启动的无状态的驻留工作进程,一般和物理机 CPU 数量相同。
Actor:角色对象,语言层面,就是一个类;物理层面,表现为某个节点上的一个角色进程,维护了该角色对象内的所有上下文(角色成员变量)。
Actor method:角色方法,语言层面,就是类的成员方法;其所有输入包括显式的函数参数和隐式的成员变量。
Remote function:远程函数,即通过 @ray.remote 注册到系统的函数。在其被调度时,称为一个任务(Task)。
Job,Task:文中用到了不少 Job 和 Task 的概念,但是这两个概念在 CS 中其实定义比较模糊,不如进程和线程一般明确。Task 在本论文是对一个远程函数(remote action)或者一个 actor 的远程方法(remote method)的封装。而 Job 在当前的实现中并不存在,只是一个逻辑上的概念,其含义为运行一次用户侧代码所所涉及到的所有生成的 Task 以及产生的状态的集合。
Scheduler:paper 中统一用的 scheduler,但是有的是指部分(local scheduler 和 global scheduler),这时我翻译为调度器,有时候是指 Ray 中所有调度器构成的整体,这时我翻译为调度系统。
exponential averaging:我翻译成了移动指数平均,虽然他没有写移动。对于刚过去的前 n 项,以随着时间渐进指数增长的权重做加权平均。计算时候可以通过滑动窗口的概念方便的递推计算。
Future:这个不大好翻译,大概意思就是对于异步调用中的返回值句柄。相信信息可以参见维基百科 Future 和 promise。
引用
[1] 官方文档:https://ray.readthedocs.io/en/latest/
[2] 系统论文:https://www.usenix.org/system/files/osdi18-moritz.pdf
[3] 系统源码:https://github.com/ray-project/ray

