引子
18年的时候做过一些 6.824,旧文在此,无奈做到 Part 2C,无论如何也跑不过测试,便一直搁置起来。但在后来的日子,却时时念起此门神课,心下伤感。拖到今日,终于可以来还愿了。
这次能跑过所有测试,原因有三:一来,之前做过一次,很多原理还留有印象;二来,这一年多在工作上有了很多分布式系统的实践;三来,golang 的驾驭上也精进了一些。但是在做的过程中,仍然遇到了大量令人纠结的细节,为了方便日后回顾,将这些细节梳理一下,记在此处。若能好巧对其他做此门课的人有些微启发,则又是快事一件了。
6.824 与 Raft
6.824 是一门关于分布式系统的非常棒的公开课,做课程实验的过程中时时惊叹于其构思之精巧、材料准备之翔实。MIT 的大师们能将这样精华的课程开放出来,实乃名校和大师们的气度,更是我们计算机人的幸事。
Raft 是一个面向理解的分布式共识(consensus)协议。分布式共识算法是分布式领域非常非常经典的问题,同时也是分布式系统中非常难的一块,直观的说,就如同流沙上打下分布式系统大楼的地基。不可靠的网络、易故障的主机,造成的状态变化之复杂,实在不是一般人能在脑中模拟得了的。本人愚钝,只能是感性把握加细节堆叠,堪堪有些认识。说回 Raft,有同领域 Paxos 珠玉在前,何以 Raft 仍能脱颖而出?应该是抓住了以下两点:
- 易于理解。Paxos 是出了名的难以理解,因此也就难以飞入寻常百姓家。而 Raft 通过解耦出多个模块,将算法复杂度进行降维,大大降低了一般人的理解难度。此外,Raft 还有很多精巧的设计,以尽可能避免引入复杂度,从而进一步减轻大家的心智负担。
- 易于实现。易于理解客观上会导致利于实现,但不等同于就能据此产出优秀系统。如果理解流于感性,则实现成空中楼阁。Raft 论文的厉害之处就在于既有感性把握又有细节组织,几乎就是一个系统的设计文档,还是详细设计文档。
要想做好该实验,需要涉猎大量的材料,我把实验中提到的和我看到的汇总在文末。当然,还有英文劝退。虽然我最后测试用例都过了,但仍有很多没实现好的点以及不理解之处。
注:后续,2023 年又做了一次,终于理清楚了大部分点。
作者:木鸟杂记 https://www.qtmuniao.com, 转载请注明出处
整体结构
该实验(2020年版本)分为三个部分,分别是 Part 2A:leader 选举、Part 2B: 日志同步、lab2C:状态备份。
我在实现的时候没有用过多的 channel,状态都是通过加锁来阻塞式改变的。我注意到网上有一些实现将所有状态变化都用 channel 控制,这样异步实现可能会效率高些,但可读性稍差。我的实现基本遵从论文叙述,在代码组织上可以概括为三个状态和三个 Loop。
三个状态
Follower、Candidate、Leader。并据此定义了三个函数:becomeFollower、becomeCandidate、becomeLeader,分别封装了一些 Raft Peer 内部的状态变化。
1 | func (rf *Raft) becomeCandidate() { |
三个循环
三个 goroutine:electionLoop,pingLoop,applyLoop。其中,前两个 loop 都由 timer 驱动, electionLoop 只在 Peer 不为 Leader 时执行选举逻辑,而 pingLoop 是在每次 Peer 当选为 Leader 时启动,并在失去 Leader 身份后及时退出的。也就是说,对于同一个 Peer,这两个 Loop 实现为了互斥的。
electionLoop 是 Follower 超时变为 Candidate 后进行选举的 Loop。它为后台常驻 goroutine,但是检测到自己是 Leader 时会跳过执行循环体(跳过选举),毕竟谁也不会主动发起选举推翻自己。
1 | func (rf *Raft) electionLoop() { |
pingLoop 是 Candidate 当选为 Leader 后进行心跳的 Loop,并在心跳的来回中完成日志同步。该 Loop 是在 becomeLeader 函数中被启动的 goroutine,一旦检测到自己不为 Leader 后便立即退出,毕竟 Peer 都是高度自觉的,若是人人欺诈,就永远达不成一致了。
1 | func (rf *Raft) pingLoop() { |
applyLoop 最简单,就是将已经 commit 的 log 不断应用到状态机,也是个后台常驻 goroutine。如此设计的妙处在于解耦。即不是每次 commit 后立即 apply,而是由额外的 goroutine 统一执行,以避免多次 commit 同一个 index(由于大多数 Peer 响应后就可以 commit,之后再收到其他 Peer 的响应,就可能造成多次 commit),进而导致多次 apply。
1 | func (rf *Raft) applyLoop() { |
加锁原则
我是按照实验材料中建议的,用的比较粗暴,基本都是函数粒度的。仅在发生长耗时操作(网络IO)前会释放锁:即每次 RPC (sendRequestVote 和 sendAppendEntries)前。因此效率不会太高,但是易于实现和理解。同时为了保证这次发送过程是原子的(不被中断),使用了一个 channel 来同步,保证给下个 Peer 发送 RPC 前,前一个 RPC 已经准备完了 Args;当然也可以将准备 Args 的过程,拿到 goroutine 之外。
1 | func (rf *Raft) pingLoop() { |
日志
我给主要结构体都实现了 String() 函数,以方便返回当前 Peer 的关键状态、 RPC 前后的参数和返回值,从而易于跟踪、调试。以 Raft 结构体为例:
1 | func (rf *Raft) String() string { |
领导者选举(Part 2A: leader election)
Raft 中的任何 Peer(或者说 server) 都处在三种状态之一:Follower、Candidate、Leader。其状态转移图如下:
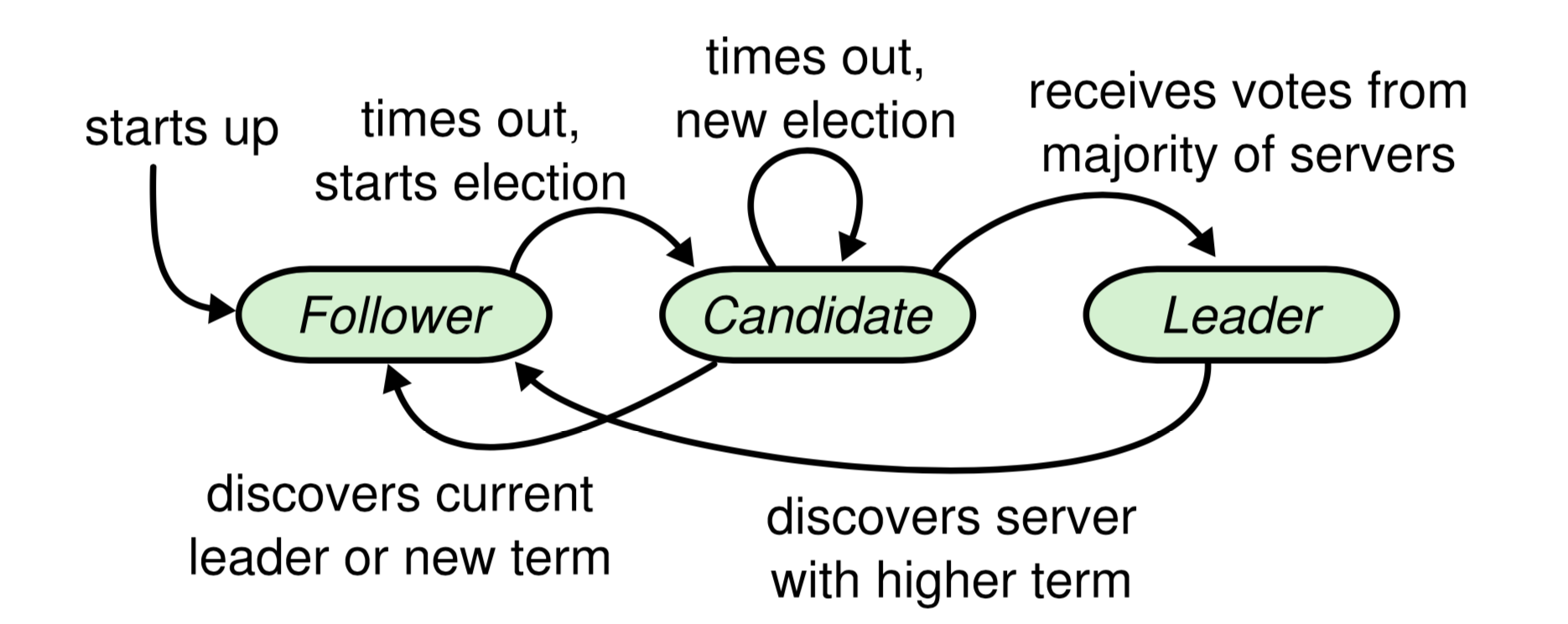 raft-server-state.png
raft-server-state.png
其中所有 Peer 在启动时都是 Follower,经过一个随机超时后先后变为 Candidate。Candidate 是一个为竞选 Leader 而设计的中间过渡状态。所有的任期( term) 始于 Candidate(即变成 Candidate 时 term+1),如果能当选则持续到 Leader结束。
Raft 中有一条铁律,就是不论出于什么状态,只要发现自己所处 term 落后于人,就立即改变自己 term 变成 Follower。 term 即为事实上的逻辑时钟,所有投票行为(Candidate 和 Voter[1])和日志同步(Leader 和 Follower)动作需要所涉及双方在同一个 term 中。
Raft 使用强势 Leader,只能由 Leader 向 Follower 同步日志,而不能反过来。并且 Leader 本身的日志只会由 Client 进行 Append,不会更改或者删除;由于 Leader 权势巨大,必须为选举设置严苛的门槛,即保证当选的 Candidate 的 log 比过半数的 Peer 更 up-to-date 。因此需要在选举阶段逐一比较 Candidate 和其他 Peer 谁更 up-to-date。根据论文中这段描述:
Raft determines which of two logs is more up-to-date by comparing the index and term of the last entries in the logs. If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date.
只考虑两组日志的最后一条日志的 index 和 term 即可:
1 | func notLessUpToDate(currTerm, currIndex int, dstTerm, dstIndex int) bool { |
实现的详细描述可以看论文图二,该描述要当做编程语言而非自然语言来对待,因为它十分精确,尤其要特别注意不要遗漏其状态转换时的触发条件。这里不再赘述,仅列出我觉得在实现时,可能有困惑的一些点:
-
RequestVoteArgs结构体的字段都要大写,这是测试程序所要求的。 -
AppendEntries请求、回应结构体、以及发送RPC 的实现,需要自己比对RequestVote依样画葫芦。 -
logEntry也需要自己定义,我实现的就只包含 Term 和 Command 两个字段。 -
Peer 每一轮(term)至多投一次票,可以通过在给出投票前判断
rf.votedFor是否为 null [5] 来保证;但同时有另一层意思,即每一轮至少可以投一次票,这就要求在发生 term 改变时,需要及时改变 votedFor 。分两种情况:一是 Follower/Candidate 超时变为 Candidate 时,term 会增加 1,这时候先无脑投自己(rf.votedFor = rf.me),然后发起选举;二是在收到其他 Peer 的 RPC 时(包括 Request 和 Reply),发现别人 term 高,变为 Follower 时,也需要及时清空自己之前投票结果(rf.votedFor = -1)以使本轮次可以继续投票。但同 term 的 Candidate 变回 Follower 时,记得不要重置rf.votedFor。 -
Peer 在实现 AppendEntries 时,只要本 Peer 的 term 不高于发起心跳的 Leader 的 term,都要及时变为 Follower,这包含以下几种情况:a. 如果 Peer 较小,则需 term 跟上,然后变 Follower;b. 本来为 Candidate 且 term 相同,要停止选举变为 Follower;c. 本来就是 Follower 且 term 相同 ,便重置下 electionTimer。
1
2
3
4
5
6if args.Term < rf.currentTerm {
DPrintf("%v reject append entry rpc from %v for (term)", rf, args)
return
}
rf.becomeFollower(args.Term) // become follower with term args.Term and reset timer -
关于
electionTimer的重置:每次变为 Follower 时,可以重置下 timer。此外,对于Follower/Candidate ,还有两种情况需要重置:一是收到 AppendEntries RPC 时;一是投票给某个 Candidate 时。这个推断从图二中 Followers 中这句话来:If election timeout elapses without receiving AppendEntries RPC from current leader or granting vote to candidate: convert to candidate
-
每次在收到 RPC 的 reply 时,(Candidate 和 Leader)都要检查一下此时是否和发送 RPC 之前状态一致,如果不一致,需要及时退出 goroutine,不在其位,不谋其政。term + role 可以唯一确定某个 Peer 的状态。
1
2
3
4
5
6
7
8
9// in pingLoop()
if rf.role != LEADER || rf.currentTerm != args.Term {
return
}
// in electionLoop()
if rf.role != CANDIDATE || rf.currentTerm != args.Term {
return
}
在做的时候我还想到了一种极端情况,做了下推演。某个 Peer A 与其他 Peer 产生了网络隔离,于是不断超时-选举-超时,从而不断更新 term 到一个很大的值 T。某个时刻 A 与其他 Peer 恢复通信,它发起选举,向每个 Peer 要票。于是剩下的所有 Peer 包括 Leader 发现更大 term:T,就会立即变为 Follower。不过由于 up-to-date 的保证,A 也是成不了 Leader 的。所以这样场景的唯一后果就是 A 一下把大家带入了更高的 term,且成就了别人(可能选出一个不为 A 、不为原 Leader 的其他 Peer)。当然,工程上通常通过 prevVote 来避免 Leader 老被隔离很久的 Peer 中断。
日志同步(Part 2B: log replication)
Leader 接收到 client 请求到应用其包含 command 到状态机大概需要这么几个过程:
- 收到 client 的请求,包含一个 command 参数(
Start(command interface{}))。 - Leader 把该请求追加到本地日志(
rf.log = append(rf.log, &logEntry{rf.currentTerm, command}))。 - 通过心跳并行通知所有 Follower 写入该日志(AppendEntries RPC)。
- 待大多数 Follower 成功写入后,提交该日志。
- 通过下次的心跳把 LeaderCommit 广播给所有的 Follower。
- 每个 Follower 各自 Apply。
心跳是定时的,而同步日志则是在定时的心跳的过程中完成的。如果 RPC 参数中不携带日志条目,则就是一个简单心跳;如果 RPC 参数中携带日志条目,则是 Leader 告诉该 Follower,我认为你需要同步这些日志。
那么 Leader 是如何得知每个 Follower 需要同步哪些日志呢?
试探。
通过试探得到匹配点,Leader 在匹配点之后的日志便是需要同步给 Follower 的部分。试探匹配点即是 Leader 会依照自己的日志条目,从后往前,不断询问,你有没有存这一条日志?只要发现某条日志 Follower 存了,那么它就是个匹配点,其之前的日志必然一样 [2]。为了实现这个逻辑,raft 论文主要使用了这几个变量: matchIndex[]、nextIndex[] 和 prevLogIndex、prevLogTerm。
matchIndex 和 nextIndex
这两个数组只对 Leader 有用。其中,matchIndex[] 跟踪 Leader 和每个 Follower 匹配到的日志条目, nextIndex[] 保存要发送每个 Follower 的下一个日志条目。
Candidate 在当选为 Leader 时,会将所有 matchIndex 初始化为 0 [3],表示现在我不知道每个 Peer 的进度;同时会将所有 nextIndex 初始化为 len(rf.log),表示要从其前面,即最后一条日志,开始试探。
1 | func (rf *Raft) becomeLeader() { |
这里面隐含一个情况,即第一次试探时 args.Entries 是空的,因此对应论文中图二所说的心跳:
Upon election: send initial empty AppendEntries RPCs (heartbeat) to each server; repeat during idle periods to prevent election timeouts (§5.2)
以后随着不断向前试探,心跳中携带的日志条目将会越来越多,在实际工程中可能会引发性能问题。
prevLogIndex 和 prevLogTerm
每次心跳会带上试探信息:prevLogIndex 和 prevLogTerm。Follower 在收到该 RPC时,会看自己是否有这这条日志。如果没有,则其 prevLogIndex 以及之后的日志必然也不匹配,可以删掉。如果有,那 RPC 参数中携带的日志条目就有用了,将其追加到匹配点之后,同时根据 Leader 要求更新 commit 信息 。
1 | if args.PrevLogIndex >= len(rf.log) || rf.log[args.PrevLogIndex].Term != args.PrevLogTerm { |
Leader 处理回应
当 Leader 收到该 Follower 的回复时,如果发现匹配上了,则更新 matchIndex 和 nextIndex;否则,继续试探前一条,当然,为了加快匹配速度,我们采用了大跨步向前策略,每次跳过一个 term 而非一个 index[4]。不这么优化,有个测试就跑不过去。
当然,有可能这样也过不了,还得给 Follower 的回复增加一些字段,提示 Leader 快速向前。
1 | if reply.Success { |
一些点
照例,列出我实现中遇到的一些问题 or Bug:
-
如何决定哪些日志可以提交,即根据 matchIndex 数组得到大多数 Peer 的匹配点(
getMajoritySameIndex)?我的实现比较粗暴,复制一份,从大到小排个序,取len/2处的值。1
2
3
4
5
6
7
8
9func getMajoritySameIndex(matchIndex []int) int {
tmp := make([]int, len(matchIndex))
copy(tmp, matchIndex)
sort.Sort(sort.Reverse(sort.IntSlice(tmp)))
idx := len(tmp) / 2
return tmp[idx]
} -
rf.applyCh不要忘记在Make函数中使用传入的参数applyCh进行赋值。 -
Leader/Candidate/Follower 在接收到比自己大的 term 的 RequestVote RPC,需要立即转为 Follower,并且重置 electionTimer。
-
在 Leader 收到 AppendEntries 的 Reply 时,需要先判断 term,然后再判断状态是否变了,即下面两个 if 语句顺序不能换。否则可能由于某种原因,该 Peer 状态变了(即不再是 Leader 或者 term 发生了更改),就直接返回了, 但有可能其更改后 Term 仍然比 reply.Term 小,从而没有及时变成 Follower。
1
2
3
4
5
6
7
8if reply.Term > rf.currentTerm {
rf.becomeFollower(reply.Term)
}
if rf.role != LEADER || rf.currentTerm != args.Term {
DPrintf("%v is not leader or changes from previous term: %v", rf, args.Term)
return
} -
每次 Leader 丢掉领导者身份后,其
commitIndex需不需要回退?以及每次 Candidate 上位 Leader 时,需不需要对commitIndex = 0?答案是都不需要,因为根据论文中 Leader Completeness 特性,所有被提交了日志必定会出现在后面的 Leader 的日志中。 -
AppendEntries 收回 reply 的时候更新
rf.matchIndex 和 rf.nextIndex需要注意,不能依赖len(rf.log),因为他可能被改变,比如由于客户端请求,被追加新的日志条目了。最好用发出RPC 请求时的参数中的字段值:args.PrevIndex + len(arg.Entnries),上面代码有相应注释。 -
TestRPCBytes2B 这个测试用例我一开始老过不了,后来发现是我心跳的时间间隔太小了,后来发现是单位写错了,将毫秒写成了微秒。从而导致对于同一个 Follower,同样的 AppendEntries 包发了太多次(稍微多发一两次测试程序是可以忍的)。
-
随机种子用
rand.Seed(time.Now().UnixNano())好一些。 -
发送 AppendEntries RPC 时,当 peerID 是 Leader 自己时,也要注意更新 nextIndex 和 matchIndex:
1
2
3
4
5if peerID == rf.me {
rf.nextIndex[peerID] = len(rf.log)
rf.matchIndex[peerID] = len(rf.log) - 1
continue
}
状态备份(Part 2C: state persist)
光从实现上来说 2C 比较简单,就是实现序列化(rf.persist())和反序列化(rf.readPersist())的函数,以对需要持久化的状态进行保存或者加载。并且在这些状态发生改变的时候,及时调用 rf.persist()。
但却很容易跑不过,我前年做的时候,就是卡在这了好久。因为这一个部分的测试用例更加复杂,很容易将前两个部分没实现好的点测试出来。
序列化和反序列化
需要持久化的状态论文中图二说的很清楚,labgob 的用法,注释中也给的很详细。需要注意的就是 rf.log 这个 Slice 不用区别对待,和普通变量一样处理即可,以序列化为例:
1 | func (rf *Raft) persist() { |
状态改变
代码中涉及到状态改变的主要有四个地方:
- 发起选举,更新 term 和 votedFor 时。
- 调用 Start 追加日志,rf.log 改变时。
- RequestVote 和 AppendEntries 两个 RPC handler 改变相关状态时。
- Candidate/Leader 收到 RPC 的 reply 更新自身状态时。
但是测试用例 TestFigure8Unreliable2C 就是过不了。Google 一番后发现别人也有这个问题。将 pingInterval 再改小一些,拉大其与 electionTimeout 的差距可解决。最后我将参数改为如下值,该用例就过了。
1 | const ( |
但我开始将心跳间隔设置得比较大,是因为看到了材料中这么一句话:
The paper’s Section 5.2 mentions election timeouts in the range of 150 to 300 milliseconds. Such a range only makes sense if the leader sends heartbeats considerably more often than once per 150 milliseconds. Because the tester limits you to 10 heartbeats per second, you will have to use an election timeout larger than the paper’s 150 to 300 milliseconds, but not too large, because then you may fail to elect a leader within five seconds.
但是我改成 heartbeatInterval = 50 * time.Millisecond tester 也让过了,这里我暂时有些不解。
参考材料
-
Raft 论文:https://pdos.csail.mit.edu/6.824/papers/raft-extended.pdf
-
Lab2 Raft 课程材料页:https://pdos.csail.mit.edu/6.824/labs/lab-raft.html
-
助教总结往年经验:https://thesquareplanet.com/blog/students-guide-to-raft/,顺便说一嘴,这个助教的博客也挺不错。
-
助教 Q&A:https://thesquareplanet.com/blog/raft-qa/
-
Raft 用锁建议:https://pdos.csail.mit.edu/6.824/labs/raft-locking.txt
-
Raft 实现结构组织建议:https://pdos.csail.mit.edu/6.824/labs/raft-structure.txt
-
Raft 主页,上面有个可视化动图,能帮你直观的感受下 raft,并且具有一定的交互性。此外还有更多 raft 相关的材料,也可以参考:https://raft.github.io/
-
某个网上同学实现:https://wiesen.github.io/post/mit-6.824-lab2-raft-consensus-algorithm-implementation/
注解
[0] Raft 中的每个 Server 文中统一称为 Peer。
[1] 投票者可能为 Follower,也可能为 Candidate。
[2] 参考论文 Figure 3 的 Log Matching 性质。
[3] 0 其实表示 nil,因为rf.log[0] 是一个无意义的空日志条目,起到哨兵的作用,可以减少一些判断,类似于链表中的 dummy Head node。
[4] raft 论文 7~8 页的引用文字有提到该策略。
[5] 我在实现时, votedFor 用的 int 类型,并且用的 -1 代表 null。

