小引
曾经在一个面试中让谈谈对 CAP 的理解,当时凭着准备面试时谷歌到的N手资料,类似于小学生背书一样,生挤出只言片语。面试官无奈的笑笑,简练的概括出他想要听到的要点,听的我心下惭愧。面试自然是挂了,后来工作时偶尔接触到这个词汇,初不得要领,后通过不同资料的多侧面理解、印证,渐渐拼凑出了一个轮廓,在这里梳理下,将影子撵到纸上,以供日后索引。
面试官大约是这么概括的:在分布式系统中,失败必然的,分区容错(P)是一定需要的,因此设计系统时需要在可用性(A)和一致性(C)间进行权衡。当时被教育印象很深,现在看来,这句概括是点出了小荷才露尖尖角的那个角。
作者:木鸟杂记 https://www.qtmuniao.com, 转载请注明出处
历史
埃里克·布鲁尔(因此 CAP 定理又被成为 Brewer’s theorem )大约在 1998 年就有了相关想法,然后在 1999 年作为一个原则将其发表出来,并且最终在 1999 年的 PODC 上作为一个猜想将其正式提出。2002 年,MIT 的 Seth Gilbert 和 Nancy Lynch 做了一个非常收束条件下的证明,使其成为一个定理。
这里想说明的一点是,说到 CAP 原则(类似的意思,这个是我随口起的),可以是定义模糊、涵盖广泛、启发分布式系统设计的原则。但是 CAP 定理,则属于每个性质都有严格数学定义、结论有完善推导的理论计算科学范畴的概念。大多数人想表达前者的意思,但用的却是后者的术语。DDIA 作者 Martin Kleppmann 老爷子,还专门就此吐槽了一番。
概念
CAP 原则指出,一个分布式存储系统提供的服务,不可能同时满足以下三点:
- 一致性(Consistency):对于不同节点的请求,要么给出包含最新的修改响应、要么给出一个出错响应。
- 可用性(Available):对于每个请求都会给出一个非错响应,但是不保证响应数据的时效性。
- 分区容错性(Partition tolerance):当系统中节点间出现网络分区时,系统仍然能够正常响应请求。
一致性
分布式系统通常会包含多个数据节点(Data Server),将一个数据集(Dataset)分散到多个节点的方法常用的有三种:
- 冗余(Replication):在多个节点上各存一份相同的全量数据集,每份称为副本(Replica)。
- 分片(Partition):将数据集切成大小合适的几个分片,分别存到不同的节点上。
- 冗余和分片:将数据集切成多片,每片又冗余多份,将其存放到不同节点上。
正是数据的多机冗余和分片引出了分布式系统中的一致性问题。举个例子简单说明:
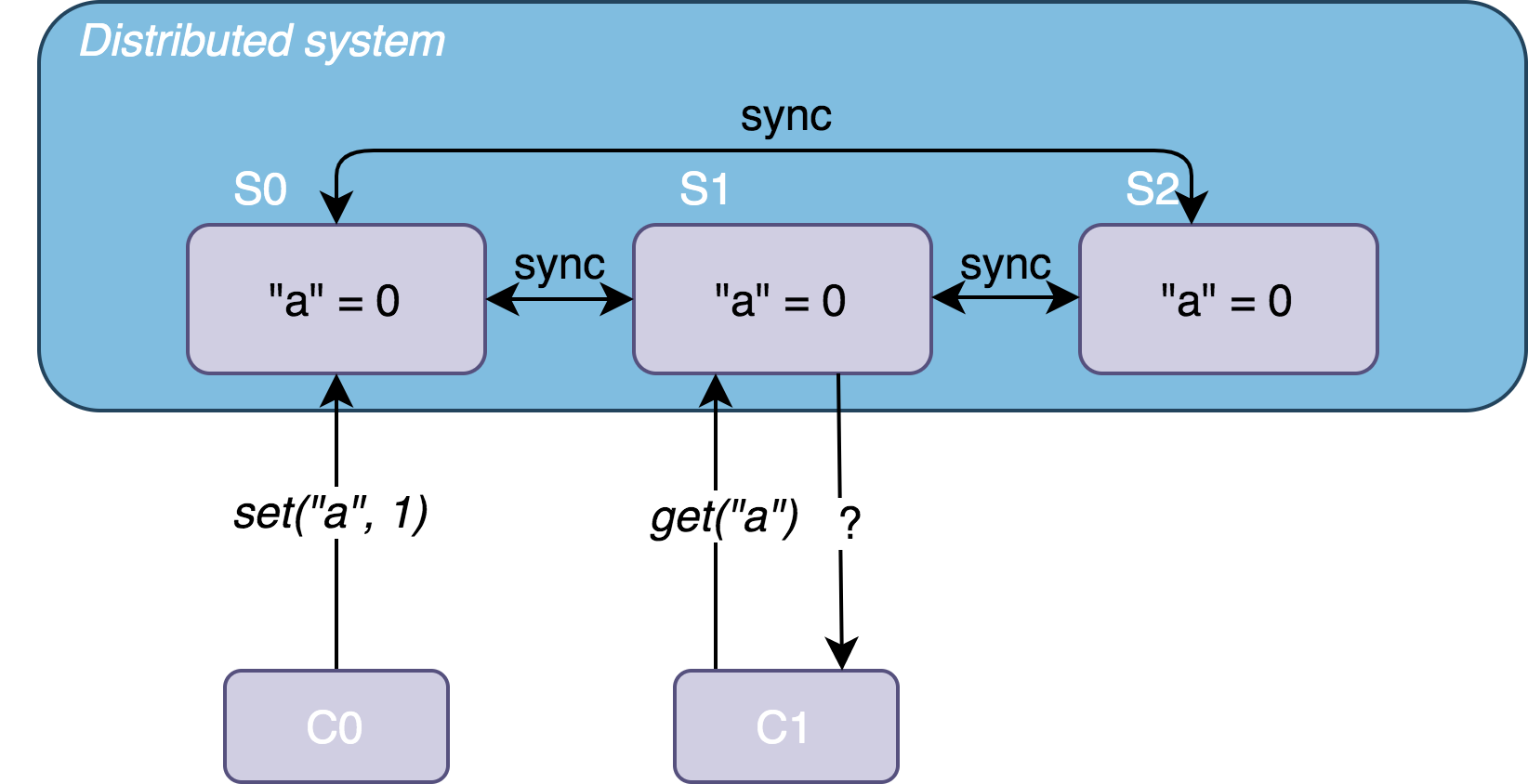
拿只有数据冗余的策略来说,假设有 S0、S1、S2 三个节点组成的一个数据系统,分别存放了某数据集 D 的三个副本 D0、D1、D2 ,该数据集是个简单的键值对(Key-value)集合。初始,集合中 "a" = 0;某时刻 t,客户端 C0 向 S0 发送写请求 set("a", 1) ,并得到成功响应;紧跟 t 之后,另一个客户端 C1 向 S1 发送了一个读请求 get("a"),
如果系统如下设计:
- S0 改变了 “a” 的值,并且将其同步到了 S1,C1 得到带有全局最新数据
"a" = 1的响应 - 系统检测到 S1 尚未同步最新数据,于是返回给 C1 一个出错响应,提示其进行重试
则该系统满足一致性。
可用性
这个性质比较好理解,即系统必须在有限的时间内给出非错响应。如果响应时间超过可以容忍时间的几个数量级,那么该服务基本不可用。系统反应很快,但是给出了一个出错响应,比如 bad file、data stale 等等,则服务仍然不可用。
分区容错性
这个性质曾经比较困扰我(当然现在也是),尚给不出一个精确的描述,只能从几个侧面来刻画一下。
这里面的难点在于如何理解网络分区(network partitioning)。
首先,一个简单的理解是,系统中的一部分和其他部分发生了网络隔离,互相不能够通信,进而不能及时完成数据同步,则可认为发生了网络分区。如上述例子中 {S0} 和 {S1, S2} 出现了网络隔离,则 {S0} 中更新的数据不能够及时同步给 {S1, *S2}*,则 {S0} 和 {S1, S2} 间产生了分区。
然后,将限制进一步放宽,如果系统中存在两个部分,其间通信时延很大,不能够在时限内进达成一致,则仍然可认为发生了网络分区。如上述例子中 {S0} 更新了数据后,尚未同步给 {S1, S2} 时,C1 的请求来了,用户仍会访问到旧的数据,也可认为{S0} 和 {S1, S2} 间产生了分区。
如果发生了网络分区以后,系统仍然能够正常提供服务,则该系统具有分区容错性。
抽象来说,如果系统组件之间的通信时延大于系统事件(比如说系统请求)的间隔,则会发生网络分区,这也是分布式系统的常态。极端情况下,如果某个系统运行在单机上,但是该机器内内存和 CPU 等组件间的通信延迟很高,则该单机可以认为是分布式系统,并且发生了网络分区。
以上都是从实践角度的一些理解,理论上严格定义的发生网络分区的条件更为苛刻,后面会详细说明。
解释
在一个分布式系统中,网络故障和节点宕机是常态,因此网络分区是一定会出现的。在网络分区发生时,根据业务需求,系统需要在可用性和一致性之间二选一:
- 优先保证可用性。网络分区使得有些节点不可达,导致系统不能够及时同步数据。尽管被请求节点试图返回其可见范围内的最新数据,但仍不能保证该数据是全局最新的,即牺牲一致性保证可用性。
- 优先保证一致性。网络分区使得被请求节点不能够保证数据全局最新时,返回一个出错信息给用户;或者什么也不返回,直到客户端超时。
但该原则并不是说,系统在任何时候都必须抛弃 CAP 中的一个。比如系统网络状况良好时,并不需要在三者间进行取舍,此时不需要分区容错,可兼顾一致性和可用性。
深入理解这个原则,需要把握分布式系统设计时的两个关键因素:网络环境和业务需求。尤其要注意,原则是理想情况下的断言,而实践是实际场景下的取舍,CAP 原则只是点出了系统设计的三个重要权衡方向。
网络环境,不同系统所要面对网络环境变化范围极大。
如果网络状况很好,网络分区很少发生,则系统设计时不需要过分考虑分区容错,比如可以简单设计为出现分区就停止服务,稍好一点可以让客户端进行重试等等。看起来似乎牺牲了可用性,但要注意到这种情况很少发生,所以系统可能仍然能提供N个9的服务。
如果网络状况堪忧、集群规模很大,网络不通、节点宕机是常态,则系统设计时需认真考虑出现网络分区时可用性和一致性间的取舍。这里在此强调一下,CAP定理中的分区容错性是非常理想化的:
网络将被允许任意丢失从一个节点发送到另一节点的许多消息 —— Gilbert,Lynch
如果网络任意丢失节点间的消息,经典的分布式共识协议(如 Paxos 和 Raft)将不能稳定的选出主节点并正常提供服务;工业级别的分布式数据库系统(如 HBase 和 Dynamo)也将不能多机同步数据,正常的提供存储服务。但是一般系统所面对的网络环境都没有这么糟糕,我们因此可以通过共识算法、冗余备份等手段兼顾某种程度的可用性和一致性。
而这个某种程度,就是接下来要谈的业务需求。
业务需求,针对不同业务场景偏好进行设计,就产生了市面上形形色色的分布式系统中间件。在这里,我们只考虑可用性和一致性两个需求。这里也要再次强调,在实际情况中,大部分系统都不会要求原子一致性(atomic consistency )或者完全的可用性(perfect availability) 。
对一致性来说,根据需求可以有强一致性、弱一致性、最终一致性等选择。工业级别的系统,为了提供高可用性,在业务可以容忍的范围内,往往选择弱一致性或者最终一致性,如 Amazon 的键值对存储 Dynamo。
对可用性来说,需要考虑系统用户请求的多少、并发的高低、数据的大小等等方面来定义系统的可用性。任何系统都不可能做到全场景覆盖,只要系统设计能够满足其面向的业务场景,就可以说系统满足可用性需求。比如一个私有云对象存储服务,所面对的流量可能只是每天几十 QPS、读远大于写、并发很低;在这个情况下,我们完全可以在把系统设计的不是很复杂的基础上兼顾一致性和可用性。但如果把该服务用作淘宝双十一等场景,那系统可用性基本上就没有了。
结语
CAP 在分布式系统未火热之时,归纳出了分布式系统设计中所需权衡重要的方向。在云计算、大数据如火如荼的今天,一大批优秀的分布式系统涌现出来,给了我们更多的系统设计的考虑方向和实践细节。如今做系统设计时,不用太过拘泥于 CAP 原则,根据所面对业务场景,大胆进行取舍即可。
推荐阅读
- 维基百科, CAP theorem: https://en.wikipedia.org/wiki/CAP_theorem
- 分布式小册,Distributed Systems for Fun and Profit: http://book.mixu.net/distsys/abstractions.html
- Jeff Hodges,写给分布式系统初学者的笔记:https://www.somethingsimilar.com/2013/01/14/notes-on-distributed-systems-for-young-bloods/#cap
- https://codahale.com/you-cant-sacrifice-partition-tolerance/
- 左耳朵耗子推荐,分布式系统架构经典资料: https://www.infoq.cn/article/2018/05/distributed-system-architecture

