Zookeeper
本篇要介绍 Patrick Hunt 等人在 2010 年发表的、至今仍然广泛使用的、定位于分布式系统协调组件的论文 —— ZooKeeper: Wait-free coordination for Internet-scale systems。我们在多线程、多进程编程时,免不了进行同步和互斥,常见手段有共享内存、消息队列、锁、信号量等等。而在分布式系统中,不同组件间必然也需要类似的协调手段,于是 Zookeeper 应运而生。配合客户端库,Zookeeper 可以提供动态参数配置(configuration metadata)、分布式锁、共享寄存器(shared register)、服务发现、集群关系(group membership)、多节点选主(leader election)等一系列分布式系统的协调服务。
总体来看,Zookeeper 有以下特点:
- Zookeeper 是一个分布式协调内核,本身功能比较内聚,以保持 API 的简洁与高效。
- Zookeeper 提供一组高性能的、保证 FIFO的、基于事件驱动的非阻塞 API。
- Zookeeper 使用类似文件系统的目录树方式对数据进行组织,表达能力强大,方便客户端构建更复杂的协调源语。
- Zookeeper 是一个自洽的容错系统,使用 Zab 原子广播(atomic broadcast)协议保证高可用和一致性。
本文依从论文顺序,简要介绍下 Zookeeper 的服务接口设计与模块粗略实现。更多细节请参考论文和开源项目主页。
作者:木鸟杂记 https://www.qtmuniao.com/2021/05/31/zookeeper, 转载请注明出处
服务设计
我们在设计服务接口的时候,首先要抽象出服务组织和交互所涉及到的基本概念,进而才能厘清围绕这些基本概念的动作集合。对于 Zookeeper 来说,这些基本概念称为术语(Terminology),动作集合称为服务接口(API)。
术语集
- 客户端:client,使用 Zookeeper 服务的用户。
- 服务器:server,提供 Zookeeper 服务的进程。
- 数据树:data tree,Zookeeper 中所有的数据以树形结构进行组织。
- z-节点:znode、Zookeeper Node,数据树中的节点,是基本数据单元。
- 会话:session,客户端与服务器会新建一个会话来标识一个连接,之后客户端每次请求都会通过该会话句柄来进行。Watch 事件的生命周期也是和会话绑定的。
后面行文中,对应术语的中英文可能会交杂使用。
数据组织
Zookeeper 对所存数据进行类似文件系统的树形层次化组织,可以提供给使用者更强大的灵活性。比如可以很自然的表示命名阈(namespace),比如使用同一父节点的所有孩子表示成员关系(membership)。一个路径(Path)可以定位到一个唯一的数据节点,进而能够唯一标识一个基本数据单元。
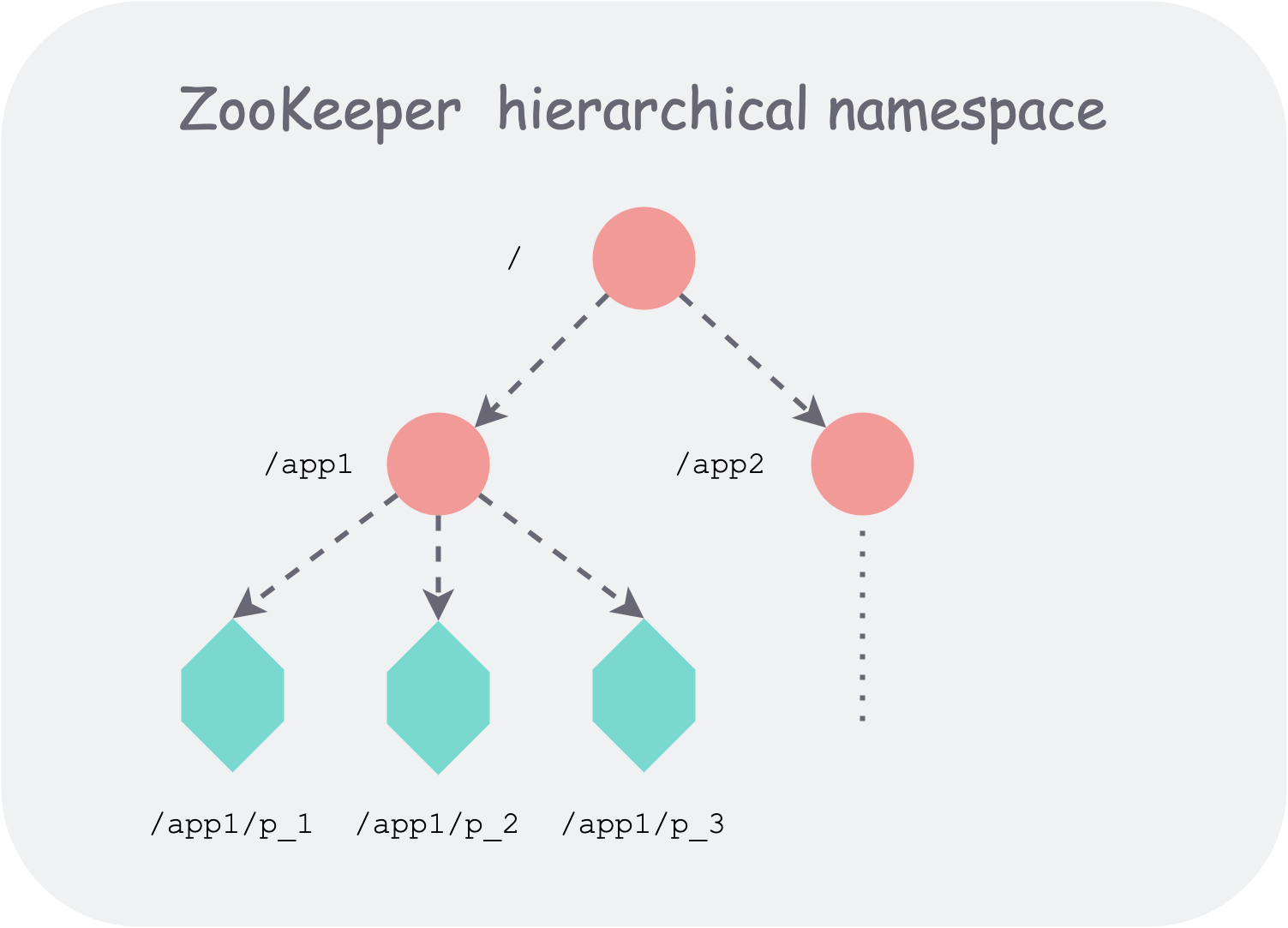 zookeeper 层次化的命名空间组织
zookeeper 层次化的命名空间组织
树中支持两种类型的 znode:
- 普通节点:Regular,生命周期无限,客户端需要调用接口显式的对这类节点进行增删。
- 暂态节点:Ephemeral,生命周期绑定到会话上,会话销毁,节点删除。
此外,Zookeeper 允许客户端在创建 znode 时,附加一个 sequential 标志。Zookeeper 便会自动给节点名字添加一个全局自增的计数作为后缀。
Zookeeper 使用推的方式实现订阅机制,即用户在订阅(watch)了某个节点后,当该节点发生变化时,客户端会收到一次通知(边缘触发),一个订阅是绑定到会话上的,因此会话销毁后,订阅的事件也会消失。
会话机制(session)。可以看到,Zookeeper 使用会话机制管理客户端一次连接的生命周期。在实现时,会话会关联一个超时间隔(timeout)。如果客户端死掉或者与 Zookeeper 断开连接,超时时限内客户端未进行心跳,Zookeeper 会在服务器端销毁该会话。
数据模型(Data model)。Zookeeper 本质上提供树形组织的 KV 模型。除存储键值对数据外,Zookeeper 更多的是以其空间结构和生命周期管理作为表达能力,来提供协调语义。当然,Zookeeper 也允许客户端为节点附加一些元信息(meta-data)和配置信息(configuration),并且提供版本和时间戳支持,从而提供更强大的表达能力。
API 细节
下面是以伪码的形式列出 Zookeeper 对客户端提供的 API 细节和注释。所有操作对象都是路径( path) 所对应的数据节点(znode)。
1 | // 在路径 path 处创建一个 znode,存入数据 data |
上面的 API 有以下特点:
- 异步支持。所有接口都有**同步(synchronous)和异步(asynchronous)**版本。异步版本以回调函数方式进行执行,客户端可以根据业务需求,选择阻塞等待以获取重要更新,或者异步调用以获得更好性能。
- 路径而非句柄。为了简化接口设计,并减少服务端维护的状态, Zookeeper 使用路径而非 znode 句柄的形式来提供对 znode 的操作接口。毕竟,句柄类似于 session,是有状态的,会增加分布式系统的实现复杂度。使用路径,可以配合版本信息做成类似幂等的接口,在处理多客户端并发时,更容易实现。
- 版本信息。所有的**更新操作(set/delete)**都需要指明对应数据的版本号,版本号不匹配则终止更新并返回异常。但可以通过指定特殊版本号 -1 ,跳过版本号检查。
语义保证
在处理多个客户端向 Zookeeper 发出的并发请求时, API 有两个基本顺序的保证:
- 线性化写(Linearizable writes)。所有 Zookeeper 状态的更新请求会被串行化执行。
- 客户端内的先入先出(FIFO client order)。给定客户端的请求会按其发送的顺序进行执行。
但这里的线性化是一种异步线性化: A-linearizability。即单个客户端可以同时有多个正在执行的请求(multiple outstanding operations),但是这些请求会按发出顺序进行执行。对于读请求,可以在每个服务器本地(不需要通过主)执行。因此,可以通过增加服务器(Observer)提升读请求的吞吐。
此外,Zookeeper 还提供可用性和持久性的保证:
- 可用性(liveness):Zookeeper 集群中过半数节点可用,则可对外正常提供服务。
- 持久性(durability):任何被成功返回给客户端的修改请求,都会作用到 Zookeeper 状态机中。即使不断有节点故障重启,只要 Zookeeper 能正常提供服务,就不会影响这一特性。
Zookeeper 架构
为了提供高可靠性,Zookeeper 使用多台服务器对数据进行冗余存取。然后使用 Zab 共识协议处理所有的更新请求,然后写入 WAL,进而应用到本地内存状态机(data tree)。
在 Zab 协议中,所有节点分为两种角色,Leader 和 Followers,前者只有一个,剩余的都是 Followers。但后来实践中,可能有 Observers。
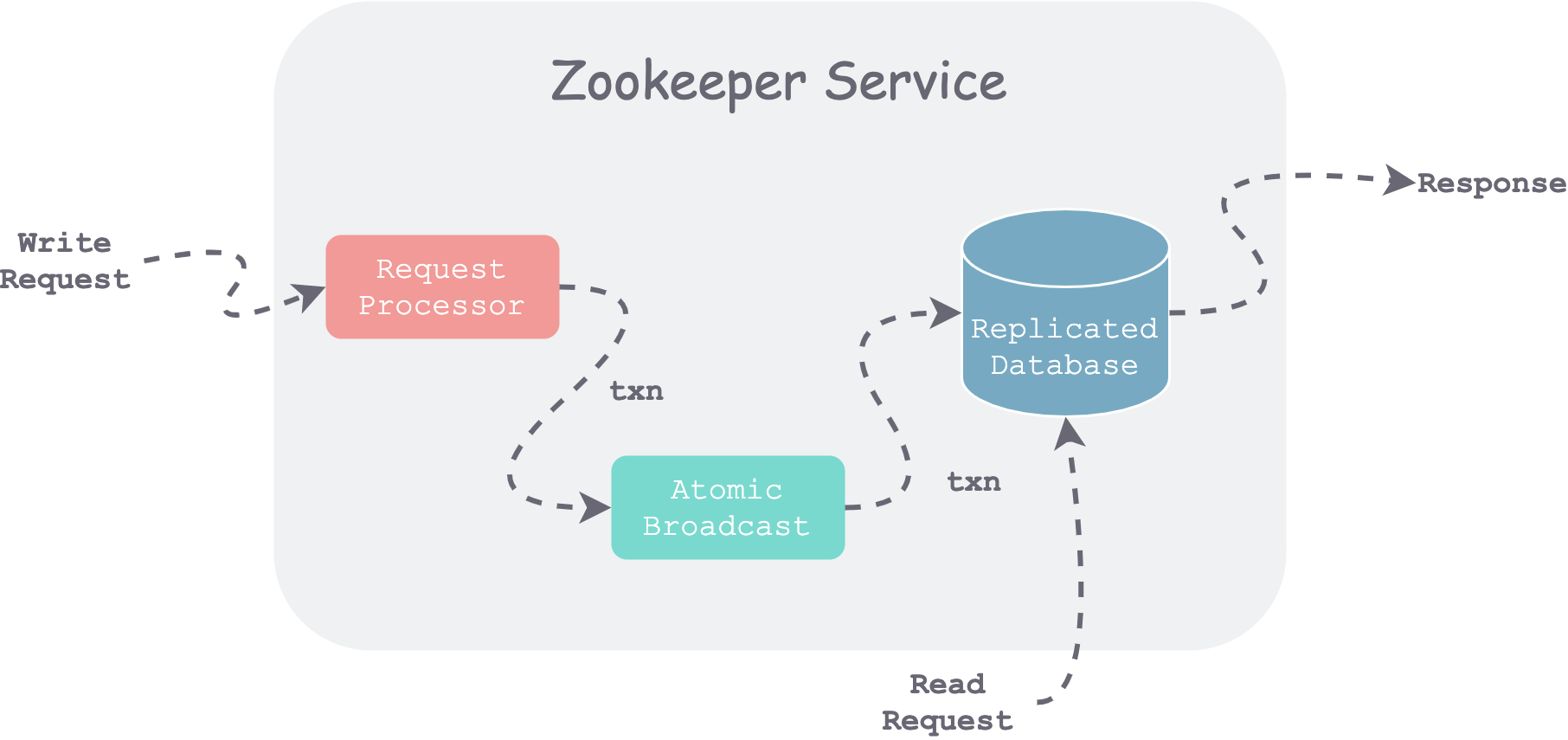 zookeeper 组件与请求流程
zookeeper 组件与请求流程
如上图所示,当 Server 收到一个请求时,首先进行预处理(Request Processor),如果是写请求,则通过 Zab 协议(Atomic Broadcast)达成一致,然后各自提交到本地数据库(Replicated Database)。对于读请求,直接读取本地数据库中状态后返回。
请求处理(Request Processor)
所有更新请求都会被转为**幂等(idempotent)**的事务(txn),具体方法为获取当前状态、计算出目标状态,封装为事务,即可使用类似 CAS 的方式处理并发请求。因此,只要保证所有事务按固定顺序执行,就能避免不同服务器上的数据副本分裂。
原子广播(Atomic Broadcast)
所有更新请求都会被转给 Zookeeper 的 Leader,Leader 首先将事务追加到本地 WAL,然后将变动使用 Zab 协议广播到各个节点,收到过半成功回复之后,Leader 将变动提交(Commit)到本地内存数据库,并广播该 Commit 给 Followers。
由于 Zab 使用多数票原则,因此 2k+1 个节点的集群最多可以容忍 k 个节点的故障(failures)。
为了提高系统吞吐,Zookeeper 使用流水线(pipelined)方式优化多个请求处理过程。
复制状态机(Replicated Database)
每个服务器都会在本机内存中维护一个 Zookeeper 中所有状态的副本(replica),为了应对宕机重启,ZooKeeper 会定期将状态做快照。不同于普通快照,Zookeeper 称其快照为 fuzzy snapshots,即在做快照时并不上锁,通过 DFS 的方式遍历文件树 Dump 到本地。之后由于异常宕机重启时,只需加最新快照,然后重新执行最新快照之后几条 WAL 即可。由于 WAL 中记录的事务的幂等性特点,即使快照和 WAL 的时间点不完全对应,也不会影响副本间的一致性。
客户端服务器交互事宜(Client-Server Interactions)
串行写。无论是在全局范围还是具体到一个 Server 本地,所有更新操作都是串行的。在执行某个 Path 数据更新时,该 Server 会触发所有与之连接的 Client 所订阅的 Watch 事件。需要注意,这些事件只保存在 Server 本地,因为他们是和会话关联的,如果 Client 与该 Server 断开连接,会话便会销毁,这些事件也随之消亡。
本地读。为了获取极致性能,Zookeeper 的 Server 直接在本地处理读请求。但这有可能造成客户端拿到陈旧数据(比如其他客户端在另外的 Server 更新了同一 Path)。于是 Zookeeper 设计出了 Sync 操作,会将调用 Sync 时刻的最新提交数据同步到与该 Client 连接的 Server 上,然后将最新数据返回给 Client。即,Zookeeper 将性能与时效性的选择权交给了用户,方法是是否调用 Sync。
一致性视图。Zookeeper 全局会维持一个事务自增标识:zxid,它本质上是个逻辑时钟,可以标识 Zookeeper 一个时刻的数据视图。Client 在故障重启后重新连接到一个新的 Server 时,如果该 Server 未执行到客户端所存 zxid,则要么 Server 执行到该 zxid 后再回复 Client,要么 Client 换一个更新的 Server 进行连接。如此,可以保证 Client 不会看到回退的视图。
会话过期。会话在 Zookeeper 中本质上标识一个 Client 到 Server 的连接。会话有超时时间,如果 Client 长时间(大于超时间隔)不发请求或者心跳,Server 便会删除该会话。
小结
Zookeeper 使用目录树组织数据、使用 Zab 协议同步数据、使用非阻塞方式提供接口,构建了一个表达能力强大的分布式协调性内核。可以用于分布式系统的控制面以进行协调、调度和控制。近年来基于 Raft 的 Etcd 也是类似地位。

