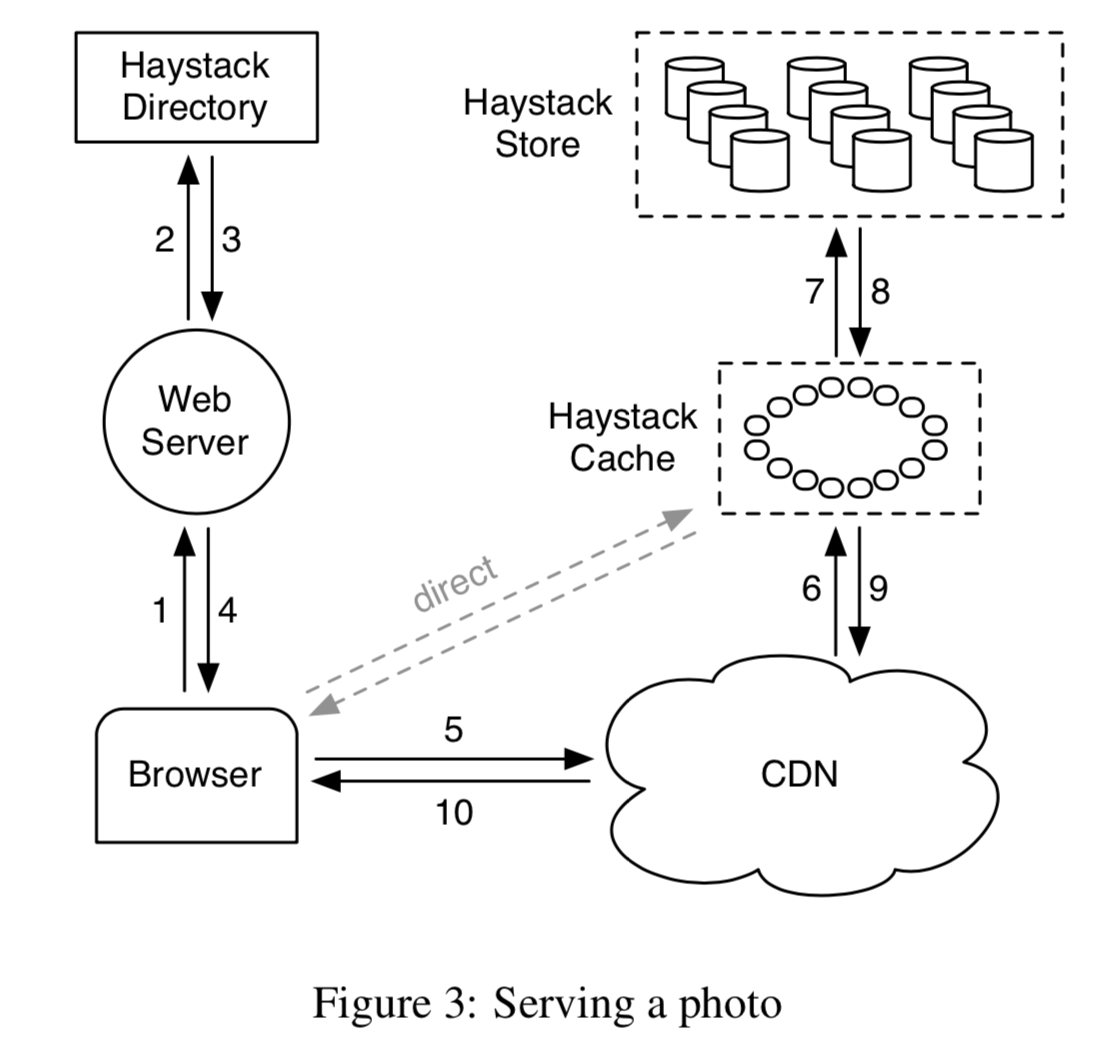
 serving a photo
serving a photo
概览
Haystack 的基本思想就是将索引信息放在内存中,避免额外的IO。为了做到这一点,主要进行了两方面的设计:
- 将小文件集合成大文件,减少文件数,从而减少了元信息的数目。
- 精简文件元信息,去掉一切在 Facebook 场景中不需要的 POSIX 语义中元信息。
这样就可以将数据元信息减小到一个内存可以放的下的量级,基本上每次每次数据访问同一个一次 IO 就可以完成,而非以前的好几次。
作者:木鸟杂记 https://www.qtmuniao.com, 转载请注明出处
Facebook业务量级
2600w, 20P
峰值每秒钟100w图片。
key observation
传统文件系统设计导致了过多的元信息查找,我们进行的减少了每个图片的元信息使得Haystack 能够在内存中进行所有的元信息查找操作。
定位
是一个对象存储,用来存分享的图片,针对的是一次写,经常读,从来不改,很少删的数据集。不得不造轮子,因为传统的分拣系统在如此高并发下,表现太差。
缘起
POSIX:目录组织,并且每个文件存了过多的我们用不到的元信息,如用户权限。而在读文件的时候,元信息必须预先读入内存,在有数十亿量级的文件时,这几乎是不可忍受的。尤其对于NAS(network attached storage)
一个图片读写需要三次访问磁盘:
- 将文件名翻译为inode
- 从磁盘读入inode
- 根据inode信息读文件本身
特点
高并发低延迟: CDN太贵,只能减少单个文件的metadata,然后将所有metadata保存在内存中,尽量做到一次访盘。
容错:异地备份
花销: 比 CND 便宜。
简单: 没有那么长时间的完善和测试,为了可用,只能做到尽量简单。
旧流程
首先访问 webserver,获取图片的的全局URL,里面包含图片的位置信息。然后用CDN做缓存,命中返回,否则去 photo storage加载到CDN再访问。
一个文件夹存数千张图片的时候,目录到block映射增大,一次不能载入内存,更加重了访问次数。
总之,我们明白了无论是内部缓存还是外部缓存(memcached),都无助于长尾形式的访问流量。
RAM-to-disk 比率,提高这个比率,但是一个图片最少占一个inode,从而带来至少数百比特的额外元信息占用。
新设计
传统来说,如果网页静态内容服务如果出现瓶颈,就用CDN来解决。但是长尾文件的访问还需另谋他路,当然我们承认非热门图片的请求是可以访盘的,但是我们可以减少这个次数。
一个图片存一个文件元信息太多,那么直观的想法就是一堆图片存成一个文件。
接下来我们区分两种元信息:
- 应用元信息,用来构建浏览器可以用来检索图片的URL。
- 文件系统元信息,用以让某个主机在其磁盘上定位该图片。
概览
三个主要组件:Haystack Store, Haystack Directory, Haystack Cache,简略起见,我们将 Haystack 省略代称为存储,目录和缓存。
- Store 对图片的持久化层做了封装,是唯一管理图片文件元信息的组件。实现上来说,我们将主机的存储进行划分,称为一个个物理上的 Volume。然后不同主机上的某几个物理 volume 作为一组称为一个逻辑上的 volume。那么这几个物理上的volume就是该逻辑 volume 的 replica,以进行备份,容错和分流。
- Directory 维护了逻辑到物理的映射,以及另外一些应用信息,包括图片到逻辑volume的映射,有空闲空间的逻辑volume
- Cache 起内部CDN的作用。当对热门图片的请求过来时,上层CDN不可用或者没命中时,屏蔽了直接对store的访问。
一个典型的要访问CDN的图片请求URL长这样:http://⟨CDN⟩/⟨Cache⟩/⟨Machine id⟩/⟨Logical volume, Photo⟩
在CDN,Cache,Machine,层如果命中就返回,否则剥离该层次地址,然后将请求转发到下一层。
serving a photo
上传一个图片的时候,首先请求被打到 web server 中;然后 server 从 Directory 中选择一个可写的逻辑卷(logic volume)。最后,webserver 给该图片一个 id,并且将图片上传到选定的逻辑卷对应的几个物理卷中。
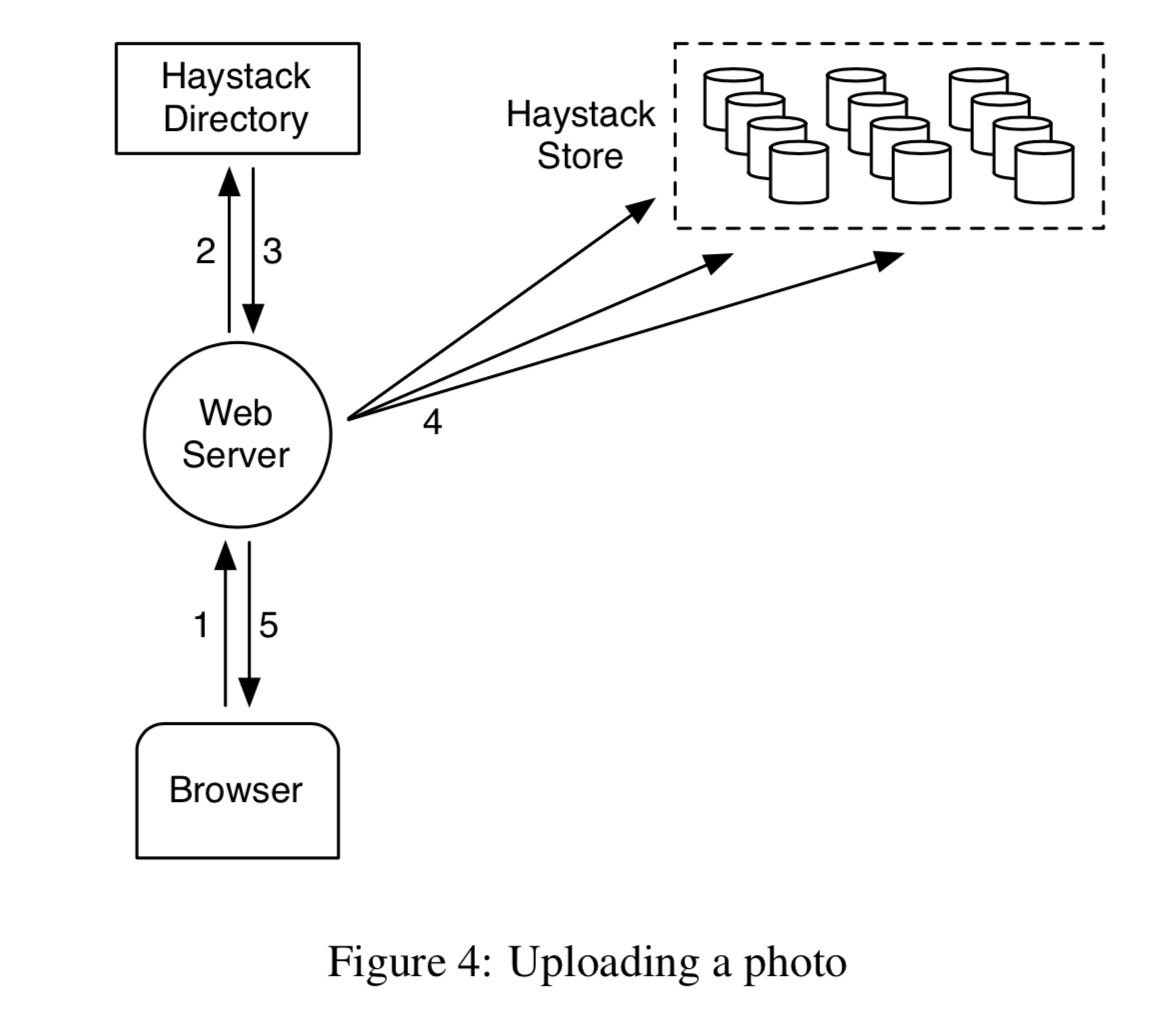 up loading a photo
up loading a photo
这里我有两个问题:1. 如何选择逻辑卷?和图片请求的大区相关吗? 2. 明显有可能造成不一致。即从 Directory 选择逻辑卷后,写的时候发现全满了或者网络问题写失败怎么办?试看paper接下来怎么说。
Haystack Directory
Directory 负责四方面的功能:
- 维护逻辑卷到物理卷的映射
webserver 使用该映射关系进行上传图片和构建图片请求URL
-
负责逻辑卷间写的负载均衡和跨物理卷间的读
-
决定一个请求是由CDN处理还是Cache处理
-
检查是否由于逻辑卷达到容量或者操作原因导致逻辑卷变为只读
Haystack Cache
Cache 会从CDN或者直接从用户浏览器收到图片的HTTP请求。Cache被组织成了分布式的Hash Table,并且用图片的 id 去定位 cache。命不中,则从根据 URL 从指定 Store 拉去图片。
只有当满足
- 请求直接从浏览器而非 CDN 过来。
- 图片被从可写服务器拉去
才会在 Cache 中缓存该请求的图片。
理由二是因为a. 图片被写后往往会很快被读取 b. 读写分开速度会更快
Hyastack Store
Haystack 的主要设计就在于 Store 的组织上。
每个物理卷在物理上是一个大文件,每个 Store 机器和通过一个逻辑卷id + offset 来迅速定位一个图片。Heystack 一个关键设计就在于此:不用硬盘访问就可以获取某个图片的文件名,偏移量和大小。因为Store 的每个物理节点一直在内存中维护着每个物理卷对应文件的描述符和图片 id 到其元信息的映射。
具体组织上来说,每个物理卷就是一个包含一个超级块(superblock)和一系列 needles。每个needle保存图片元信息和图片本身。其中 flag 是为了标记该图片是否被删除,cookie 是在上传图片时随机生成,为了防止猜 url ,而 alternate key 是为了保存同一个图片的不同分辨率的文件而增加的。Data Checksum 进行数据校验,而 padding 可能是为了硬盘块对齐。
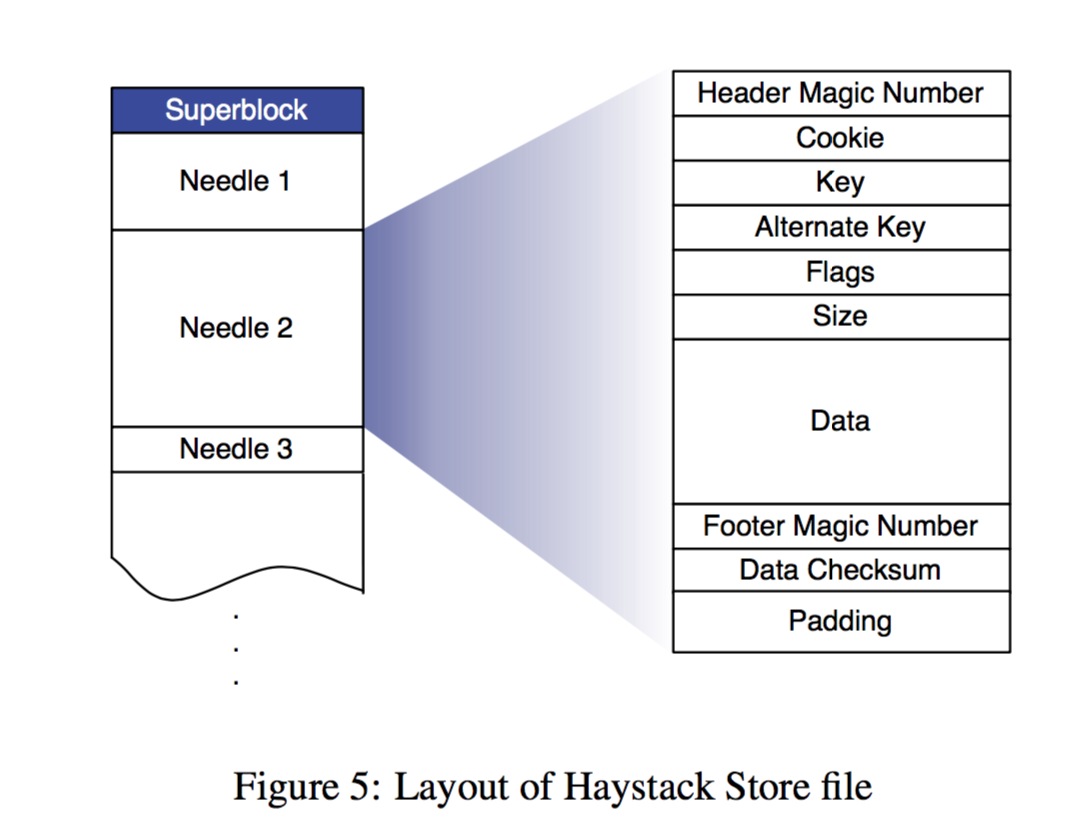 layout of haystack store file
layout of haystack store file
为了加快图片的访问,物理机在内存中维护所有图片的基本元信息,如下图,只剩下了最简单的几项信息。为了加快机器重启后内存中元信息的构建,物理机会将内存中的这些元信息定期做 snapshot 即 index file;其顺序和 store file 保持一致。
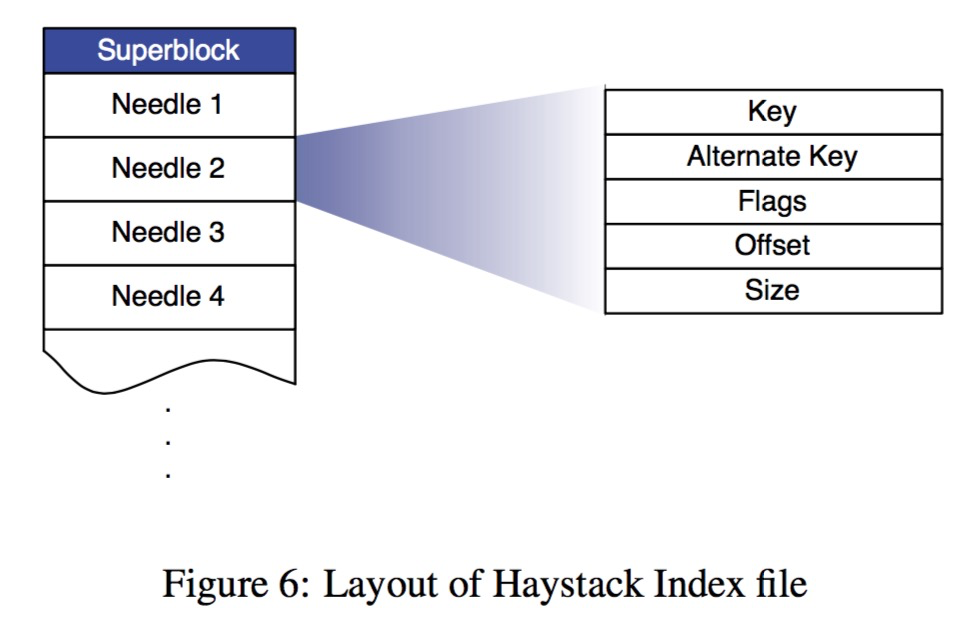 layout of haystack index file
layout of haystack index file
根据上述物理结构,我们来过一遍 Haystack 每个 API 对应的实际流程:
Photo Read
一个来自 Cache 的读请求会携带 volume id, key, alternate key 和 cookie,Store 物理机会在内存中查找图片相关的元信息,找到(文件描述符,offset 和 size), 从而读出该图片文件及其元信息;然后进行 cookie 比对和 checksum 校验,通过后返回图片数据。
Photo Write
来自 web server 的写请求会携带逻辑 volume id,key,alternate key,cookie 和 图片数据,每个物理机会同步的将这些信息追加到对应的 Store file 中。对于图片的 update 请求(比如图片旋转),我们也是进行简单的追加。但这样会造成重复的 key + alternate key;如果其和原图片落在不同逻辑卷中,Directory 只需要更新图片到逻辑卷的映射就行;如果落在同一个逻辑卷,那么通过 offset 就能获取版本的新旧(看起来除了index file 这种顺序组织,还有是利用 id 作为索引的 dict,新旧的元信息会落到一个桶内,每次取offset大的那个)
Photo Delete
删除文件很直观,就是同步的依次设置下内存和 store file 中对应图片元信息的 flag。如果请求到某个被删的 Photo,在内存中发现其 flag 被设置了,就报一个异常。暂时的,被置为已删除的图片所占的空间会暂时不可用;在定期的紧缩(compact)时,会回收这部分空间。
The Index File
然后说回 index file。既然是定期做 snapshot 得到的 index file ,那么就会有宕机一致性问题。包括,新增文件写入 volume 和内存后没有及时写到 index file 就宕机;设置某图片 Store file 和内存删除 flag 时候没有及时同步到 index file 就宕机。应对这两个问题也简单,对于前者在重启时,读index file 时候,可以对比对应 offset 的 volume id,看是否是最新的,否则将最新的补到 index 和内存中就行;对于后者,每次读取图片时,除了内存中做检查,额外检查下 Store file 中图片的删除 flag 是否被设置,并将其同步到内存和 index file 中。
Filesystem
此外,为了减少不必要的读盘,没有采用传统的 POSIX 文件系统,而是用了对大文件友好的 XFS。
错误恢复
跑在大规模廉价硬件上的系统总避免不了出现一些错误,比如说硬件驱动错误,RAID 控制器问题,主板故障等等。我们的应对方法也简单,做了两件小事,一个是定期检测,一个是适时恢复。
我们用一个叫 Pitchfork(草叉) 的后台任务,定期检测每台存储节点(Store machine)的健康状况。比如查看与每个节点的连通情况,每个 volume 的可用性,并尝试从物理节点读一些数据以进行测试。一旦健康检查失败,Pitchfork 程序就回标记该物理机上的所有 volume id 为只读。
稍后一旦确诊,就会立即修复这些问题。偶尔修复不了的,就只能先重置该节点数据,然后从备份节点利用一个比较重的 bulk sync 的操作去同步数据过来。
优化
一些常用的优化有:
定期紧缩(Compaction):这是个在线操作,旨在收回被删除文件和重复(key 和 alternate key都一样)文件所占的空间;具体做法是新生成一个文件,逐个拷贝有效的文件,跳过被删除和重复的文件。一旦完成,就暂时阻止所有落到该 volume 的修改请求,然后交换 Store file 和内存映射。
精简内存,由于现在用 flag 只做是否删除的标志,太浪费了。可以改成将内存中所有删除了的文件对应的元信息的 offset 设置为0。并且不再内存中保存图片的 cookie,改为从硬盘读取,如此一来,省了百分之二十左右的内存。
批量上传,硬盘在进行大批量写的时相对随机写平均性能会好一些,因此我们尽可能的追求批量上传。幸运的是,用户更倾向于同时上传一批图片而非一张图片。
下面还有一些进行性能评估的段落,就先不翻了。

