目标
充分利用现代存储 SSD 的性能,在提供同样 API 的情况下,显著降低 LSMTree 的读写放大,以提高其性能。
背景
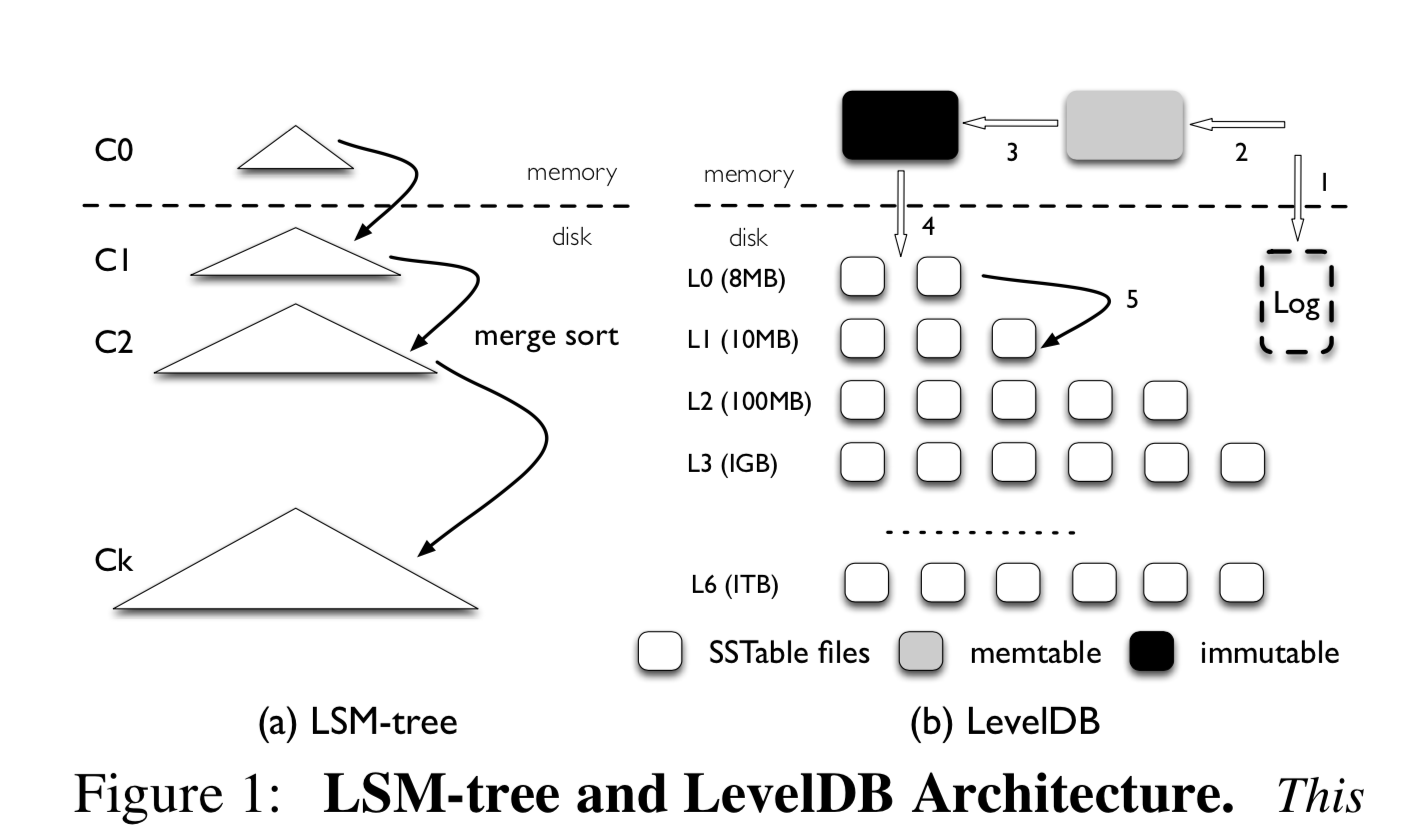
在传统磁盘上,顺序 IO 的性能大概是随机 IO 的 100 多倍,LSMTree 基于此,将海量 KV 的随机读写实现为内存随机读写+顺序刷盘+定期归并(compact),以提高读写性能,尤其适用于写多于读且时效性比较强(最近数据最常访问)的场景。
 wisckey-lsm-tree.png
wisckey-lsm-tree.png
作者:木鸟杂记https://www.qtmuniao.com/2020/03/19/wisckey/, 转载请注明出处
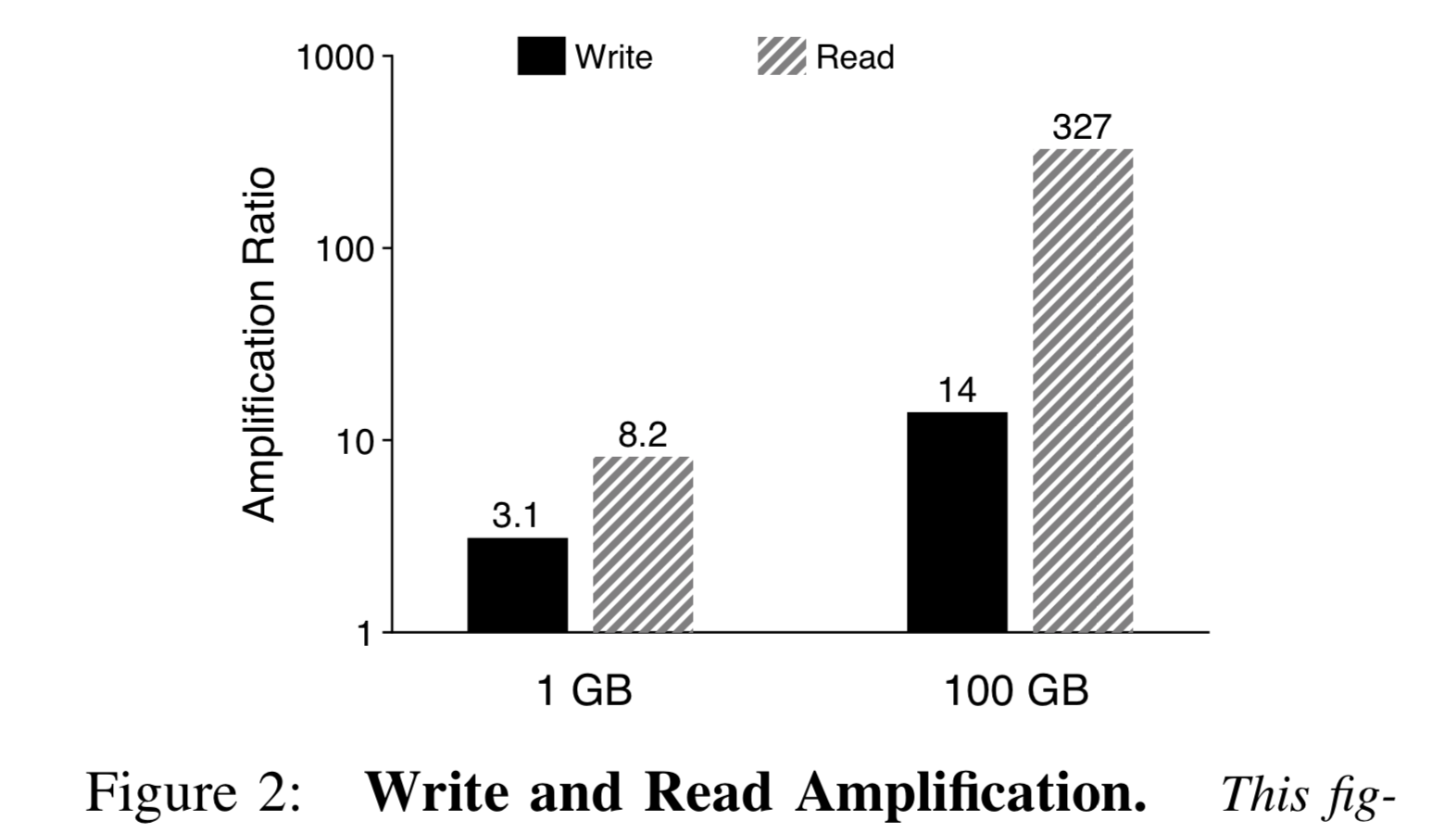
读写放大。对于写放大,由于 LSMTree 有很多层,为了加快读取速度,需要不断地进行归并排序以 compact,由此导致每一个 KV 都会被读写多次。对于读放大,在垂直方面需要多层查询以寻找指定key,在水平方向由于同一层有多个 key range,需要进行二分查询。当然,为了加速查找,可以为每一层配一个 bloom filter,以在该层不存在要查找的 key 时快速跳过。随着数据量的增大,读写放大会更甚。
 wisckey-rw-amplification.png
wisckey-rw-amplification.png
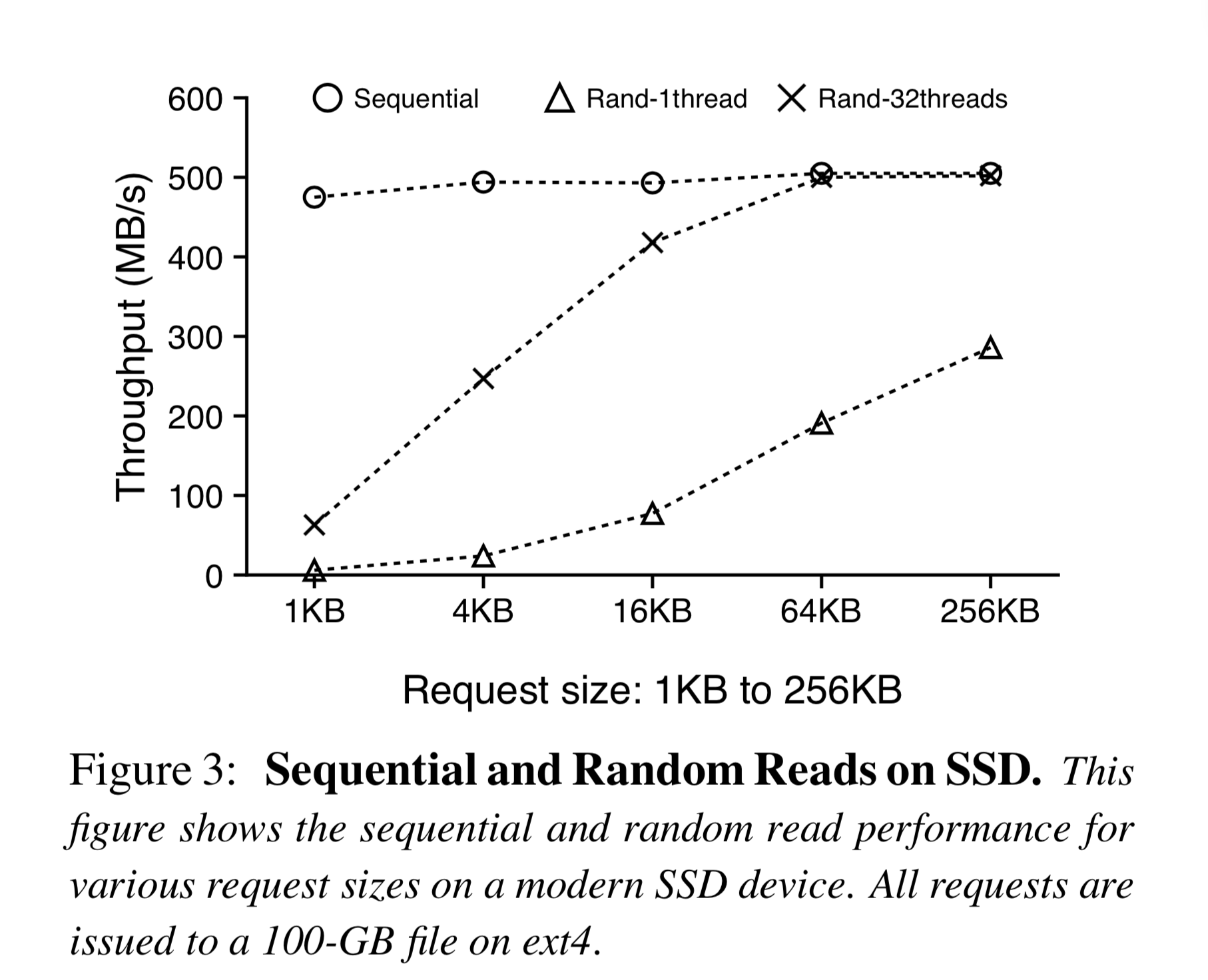
如今,SSD 价格愈发降低,使用规模愈发变大,而 SSD 的并行随机读性能是很不错的,和顺序读已经差不了那么多。当然,随机写还是尽量要避免,因为它既没随机读那么均匀的快,且会降低 SSD 寿命。
 wisckey-ssd.png
wisckey-ssd.png
核心设计
WiscKey 的核心设计主要有以下四条:
- 键值分开存储,Key 仍然存在 LSM-tree 中,Value 存在额外的日志文件(vLog)中。
- 对于无序的值数据,利用 SSD 并行随机读以加速读取速度。
- 使用独特的崩溃一致性和垃圾回收策略以高效的管理 Value 日志文件。
- 去除 WAL 并且不影响一致性,提升小数据流量的写入性能。
设计细节
键值分开
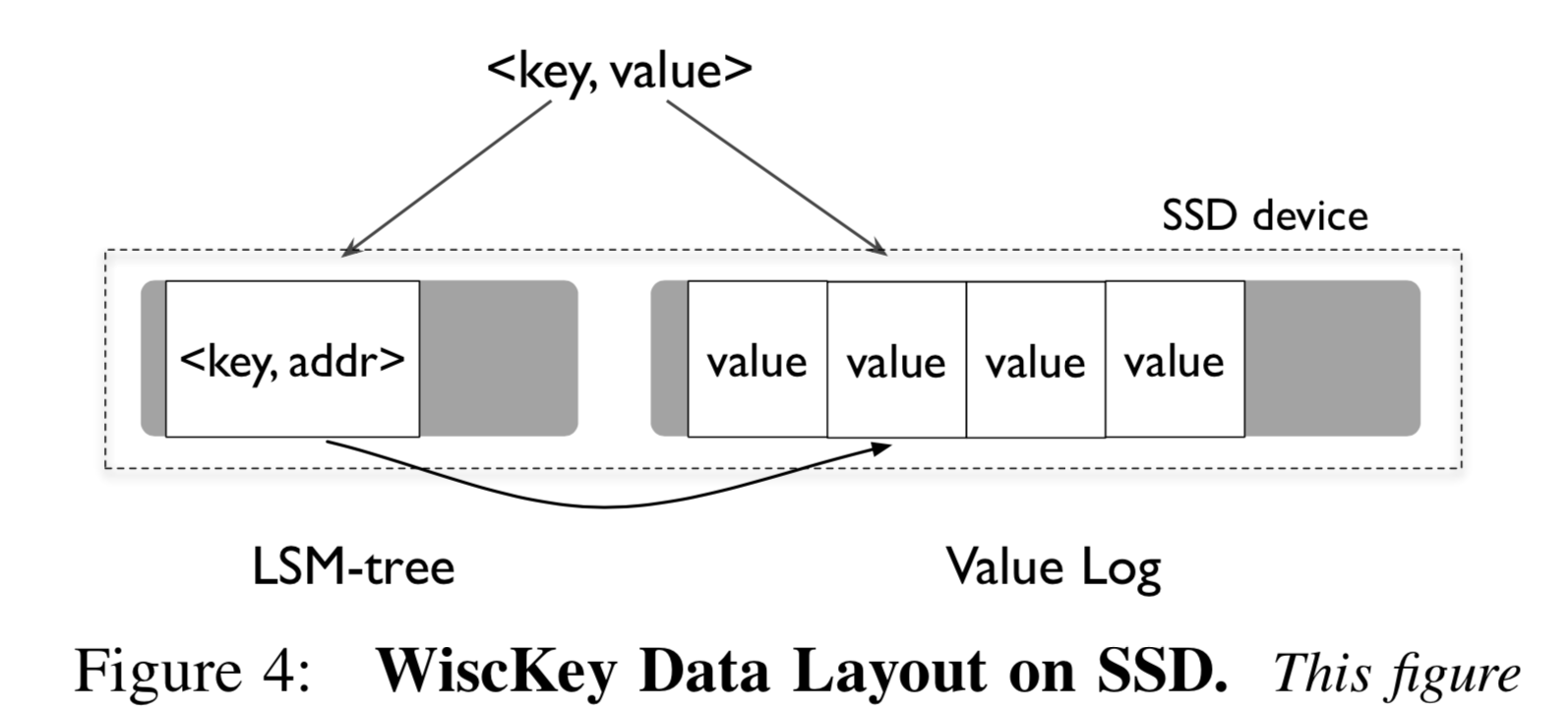
仍然将 Key 存储于 LSM-tree 结构中,由于 Key 所占空间通常远小于 Value 的空间,WiscKey 中 LSM-tree 的层数会很少,不会有太多读写放大。将 Value 存在额外的一个日志文件
中,称为 vLog。当然 Value 的一些元信息,比如 Value 在 vLog 中的位置信息,会随着 Key 一起存在 LSM-tree 中,但其占空间很小。
 wisckey-architecture.png
wisckey-architecture.png
读取。尽管 Key 和 Value 需要分开读取(即一次读取需要分解成一次 LSM-tree 中的内存(大概率)查找,一次 SSD 上的随机查找),但由于两者速度相较原来逐层查找都要块,所耗费时间并不会比 LevelDB 更多。
写入。首先将 Value 追加到 vLog,得到其在 vLog 中的偏移量 vLog-offset。然后将 Key 和 <vLog-offset, value-size> 一起写入 LSM-tree 中。一个追加操作,一个内存写操作,都很快。
删除。采用异步删除策略,仅仅删除 LSM-tree 中的 key 即可,vLog 中的 Value 会被定期的垃圾回收进程回收掉。
虽然有以上优点,但 Key Value 分开也随之带来了很多挑战,比如 Range Query、垃圾回收和一致性问题。
挑战1:范围查询
范围查询(Range Query,指定起止 Key 顺序遍历 KV-Pair)是当代 KV 存储很重要的一个特性。 LevelDB 中键值对是按照 Key 的顺序存储的,因此顺序遍历相关 Memtable 和 SSTable 即可进行范围查询。但 WiscKey 的 Value 是无序的,因此需要大量随机查询。但是如图三所示,我们可以利用多线程并行随机查询以打满 SSD 带宽,大大提升查询速度。
具体来说,进行范围查询时,首先去 LSM-tree 中顺序加载出所需 Key,然后使用 SDD 的多线程随机读进行预读取放到 Buffer 中,就可以顺序的组合读出的 Key 和 buffer 中的 Value 返回给用户,以此获取很高的性能。
挑战2:垃圾回收
LevelDB 利用紧缩机制(compact)进行延迟的垃圾回收,WiscKey 中 Key 的回收也使用同样机制。但对于 Value,由于其存在 vLog 中,需要考虑额外的垃圾回收机制。
最简单粗暴的做法,可以先扫一遍 WiscKey 中 LSM-tree 结构,以获取正在使用的 Key 集合;然后扫描 vLog,回收所有不被 Key 集合引用的 Value 即可。但显然,这是一个很重(耗时很长)的操作,为了保持一致性,可能需要停止对外提供服务,类似于早期 JVM GC 时的 stop-the-world。
而我们显然需要更轻量级的做法。WiscKey 的做法很巧妙,其基本思想是将 vLog 中所有 Value 数据视为一个条带,将所有正在使用的数据维持在条带中间,使用两个指针标记中间有效数据区域头尾。头部(head)只能进行追加操作,尾部(tail)进行垃圾回收。那么我们如何维持这个有效的中间数据区域呢?
 wisckey-gc.png
wisckey-gc.png
当需要进行垃圾回收时,从尾部读取一块数据(Block,含有一批数据条目,每个数据条目包含<ksize, vsize, key, value> 四个字段,每次读取一块是为了减少 IO)到内存中;对于每个数据条目,如其正在使用,则将其追加到 vLog 条带头部;否则将其丢弃;然后移动尾指针(tail)跳过此数据。
尾指针是一个关键变量,需要进行持久化以应对宕机。WiscKey 做法是复用存储 Key 的 LSM-tree 结构,利用一个特殊的 Key (<‘‘tail’’, tail-vLog-offset>)将其和 Keys 存在一块。头指针就是 vLog 文件的结尾,不需要保存。此外,WiscKey 的垃圾回收时机可以根据情况进行灵活配置,比如定期回收、达到某个阈值进行回收、系统闲时回收等等。
挑战3:崩溃一致性
当系统宕机崩溃时,LSM-tree 通常提供 KV 插入的原子性以及恢复时的顺序性等保证。WiscKey 也可以提供同样的一致性,但由于键值分开存储,实现机制稍微复杂一些(起码原子性会难一些)。
对于数据插入的原子性,我们考虑如下情况。宕机恢复后,当用户查询某 Key 时,
- 如果不能在 LSM-tree 中找到,则系统当其不存在。即使 Value 可能已经被追加到了 vLog 中,之后也会被回收掉。
- 如果可以在 LSM-tree 中找到,则去查看其对应的 vLog 中的数据条目
<ksize, vsize, key, value>,并依次检查该条目是否存在、位置是否在于中间合法段中、 Key 是否能匹配的上。如果不能,则删除该 Key,然后告诉用户不存在。为了防止数据只写一半后挂了,导致存在残缺的数据条目,也可以在数据条目中加入校验和。
通过上述流程,我们可以保证 KV 写入的原子性:对用户来说,KV 要么都存在,要么都不存在。
对于数据插入的顺序性,由于当代文件系统(如 ext4,btrfs,xfs)等都保证追加的顺序性,即如果在 vLog 中顺序追加了数据条目 D1, D2, D3 … Dx, Dx+1, … 如果 Dx 在系统宕机时没有追加到 vLog 中,则其之后的数据条目都不会追加到系统中。由此可以保证数据插入的顺序性。
下面会讲到,为了提高小尺寸 Value 的追加效率,WiscKey 使用了写 Buffer。因此宕机时可能会丢失部分数据条目,为此 WiscKey 提供了同步写开关,以让 WiscKey 放弃 Buffer,强制刷 Value 到 vLog 文件后,再写对应的 Key 入 LSM-tree。
优化1:vLog 缓存
对于密集型、小尺寸写入流量,如果用户每次调用 put(K, V),就调用 write 源语,往 vLog 中追加一条数据条目,如此频繁 IO 会导致性能会很差,不能充分利用 SSD 带宽,如下图所示:
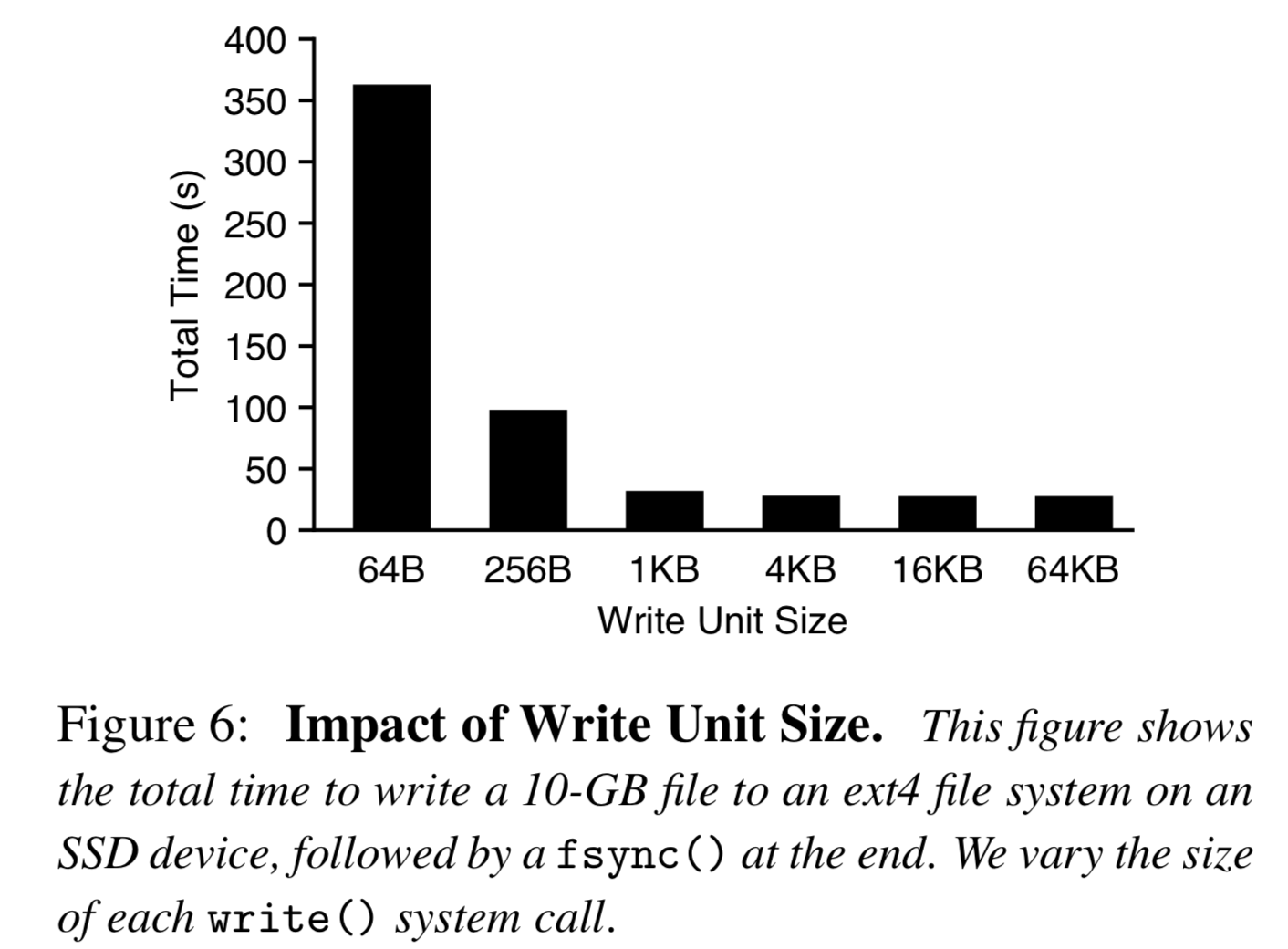 wisckey-buffer-write.png
wisckey-buffer-write.png
因此,WiscKey 使用一个 Buffer 来缓存写入的 Value,仅在用户要求或者达到设定尺寸阈值时才真正的追加到 vLog 中。在查询时也需要相应做一些修改,每次查询首先要到 buffer 中查找,然后再去 vLog 中查找。但这么做的代价是,如前所述,在系统崩溃时会丢失 buffer 中的这部分未刷盘的数据。
优化2:省去 WAL
WAL,Write Ahead Log,预写日志,是数据库系统中常用的数据恢复机制。在传统 LSM-tree 中,由于数据直接写入内存中,为了进行宕机恢复,会在每次操作前记一条日志;在宕机恢复时,逐条读取日志,恢复内存中数据结构。但这样一来,每次写请求都增加了磁盘 IO,从而降低了系统写入性能。
由于 vLog 中的数据条目按顺序记录了所有插入的 Key,因此可以复用 vLog 作为 WiscKey 中 LSM-tree 的 WAL。作为一个优化,可以将每次未持久化的 Key 的点 <‘‘head’’, head-vLog-offset> 也保存在 LSM-tree 中,每次宕机恢复时,先获取该点,然后从该点之后逐条读取 vLog 中的 Key,恢复 LSM-tree。

