 6.824-schedule.png
6.824-schedule.png
MIT 今年终于主动在 Youtube 上放出了随堂视频资料,之前跟过一半这门课,今年打算刷一下视频,写写随堂笔记。该课程以分布式基础理论:容错、备份、一致性为脉络,以精选的工业级系统论文为主线,再填充上翔实的阅读材料和精到的课程实验,贯通学术理论和工业实践,实在是一门不可多得的分布式系统佳课。课程视频: Youtube,B站。课程资料:6.824主页。本篇是第四节课笔记,VM-FT。
备份——容错
失败(Failue)
如何定义?在其他电脑看来,停止对外提供服务。
通过备份/副本(Replication)
可以解决:宕机(fail-stop),比如 CPU 过热而关闭、主机或者网络断电、硬盘空间耗尽等问题。
不能解决:一些相关联(correlated,主副本机器会同时存在)的问题,比如软件 Bug、人为配置问题
前提
主从备份可以工作的一个假设是,主从机器的出错概率需要时独立的。
比如说:同一批次机器、同一个机架上的机器,出错概率就存在强正相关特性。
是否值当
需要对业务场景和所需费用考量,是否真的需要进行 Replica。比如银行数据就需要多备份,而课程网站可能并不需要。
作者:木鸟杂记 https://www.qtmuniao.com/2020/04/01/6-824-video-notes-4-vm-ft/, 转载请注明出处
Primary-Backup Paper
两种进行状态备份的方式:
- 状态转移(State transfer)
持续增量同步 Primary 的状态到 Backup,包括CPU、内存、IO设备等等;但是这些状态通常所占带宽很大,尤其是内存变化。 - 冗余状态机(Replicated State Machine)
将服务器看作是一个具有确定性状态的状态机,只要给定相同初始状态和同样顺序的确定输入,就能保持同样的状态。同步的是外部的事件/操作/输入;同步的内容通常较小,但是依赖主机的一些特性:比如指令执行的确定性(deterministic)。而在物理机上保证确定性很难,但是在 VM 上就简单的多,由于 hypervisor 有对 VM 有完全的控制权,因此可以通过某些手段来额外同步某些不确定性输入(比如类似随机数、系统时钟等)。
一般来说操作会比状态小的多,因此 Replicated State Machine 被采纳。
Q&A:
- 如果主从备份由于某种原因不一致了会怎么样?
可以考虑 GFS 中,由于网络分区造成两个 chunkserver 都认为自己是 Primary 的例子。 - 如果指令中有一些类似于依赖于随机数的指令,Replicated State Machine 如何进行同步?
这正是之前强调的需要依赖指令的确定性的意义所在。当然,也可以在遇到这种命令时,让 Backup 去直接接受 Primary 的执行结果。
此外,Replicated State Machine 需要机器为单核,因为在多核机器上,指令的执行顺序本身是不确定的。那对于多核机器如何做同步?State Transfer 。
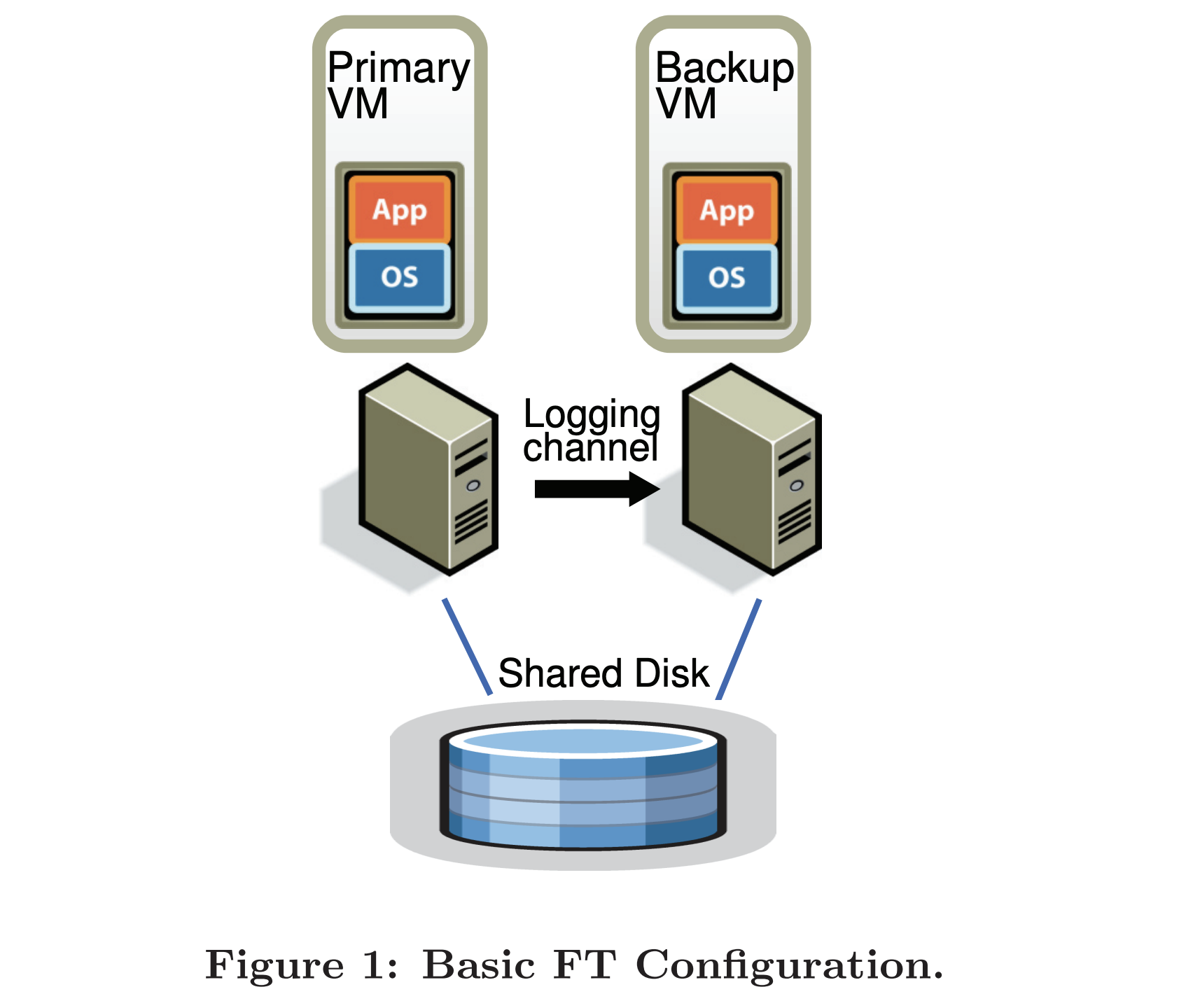 pb-ft-configuration.png
pb-ft-configuration.png
挑战
- 需要同步什么状态?
- Primary 需要等 Backup吗?
- Primary 宕机时,如何进行切换?
- 在 Primary/Backup 宕机时,如何进行快速恢复。
同步状态的层级:
- 应用层(Application state)。如 GFS,更为高效,只需要发送高维操作即可,缺点是需要在应用层进行容错。
- 机器层(Machine level)。可以让运行在服务器上的应用无需改动而获取容错能力。但需要细粒度的同步机器事件(中断、DMA);并且需要修改机器底层实现以发送这些事件。
而 VM-FT 选择了后者,能力更强大,但也做出了更多牺牲。
VM-FT 系统使用一个额外的虚拟层 VMMonitor( hypervisor == monitor == VMM ),当 client 请求到达 Primary 时,VMMonitor 一方面向本机转发请求、一方面向 Backup 的 VMMonitor 同步请求。处理完请求得到结果时,Primary 的 VMMonitor 会回复 Client,而 Backup 的 VMMonitor 会丢弃 Backup 产生的回复。
使用两种方法来检测 Primary 和 Backup 的健康状况:
- 和 Primary/Backup 进行心跳。
- 监控 logging channel。
主从切换
如何实现主从间的切换?在 Primary 宕机后,Backup 声称具有 Primary 的 MAC 地址,然后让 ARP 缓存表过期,就将打向某个IP的流量从 Primary 切换到了 Backup。
切换后,原先的 Backup 成为新的 Primary,对外进行回复。然后利用 VMotion 的技术在和新 Primary 共享外存的地方启动一个副本,并且建立日志通道。
不确定性事件
都有哪些不确定性(Non-deterministic)操作(operations)和事件(events)?
- 输入的不确定性。系统中断事件。
- 奇怪指令。比如随机数、依赖时间戳的指令。
- 多核。不同机器可能以不同的方式在多核上交替运行指令。
对于不确定性操作,需要保留充足的信息到日志通道中,以使 Backup 可以进行同样的状态改变,并且产生同样输出。对于不确定性事件,如时钟信号中断和 IO 完成中断,不仅需要记录事件本身,也要记录下事件发生的指令序列的位置,由此才能在 Backup 上确定性复现。
Logging Channel
为了进行容错(FT),我们使用日志条目(log entry )来记录 Primary 上发生的事件;但我们并没有将这些日志写到硬盘中,而是将其通过日志通道(logging channel)传送到 Backup 上进行实时确定性的重建(deterministic replay)。每个 LogEntry 可能包含以下数据:
- 指令编号
- 指令类型
- 数据
DMA
DMA能够直接将数据从网口拷贝到内存,而不经过CPU。这时需要 VMM 强行中断,拷贝来到的数据,模拟一个指令,并发送给 Backup。
OutPut rule
当 Primary 宕机时,其发送给 Backup 的最后一条指令也由于网络问题丢失了。当 Backup 接手时,如何处理该条指令丢失造成的不一致?
使用 Output Rule 保证。即 Primary 仅当在收到 Backup 该条指令的 ACK 时,才会将该指令结果发送给用户。当然,为缩短响应延迟,在 Backup 上,VMM 只需要将收到的指令缓存到 Buffer 中就可以回 ACK。而且,Primary 只是会延迟将回复发送给用户,以等待 Backup 的 ACK,但在这段等待时间内并不用真停止执行,毕竟网络请求回复是异步的,Primary 可以并行的做其他事情。
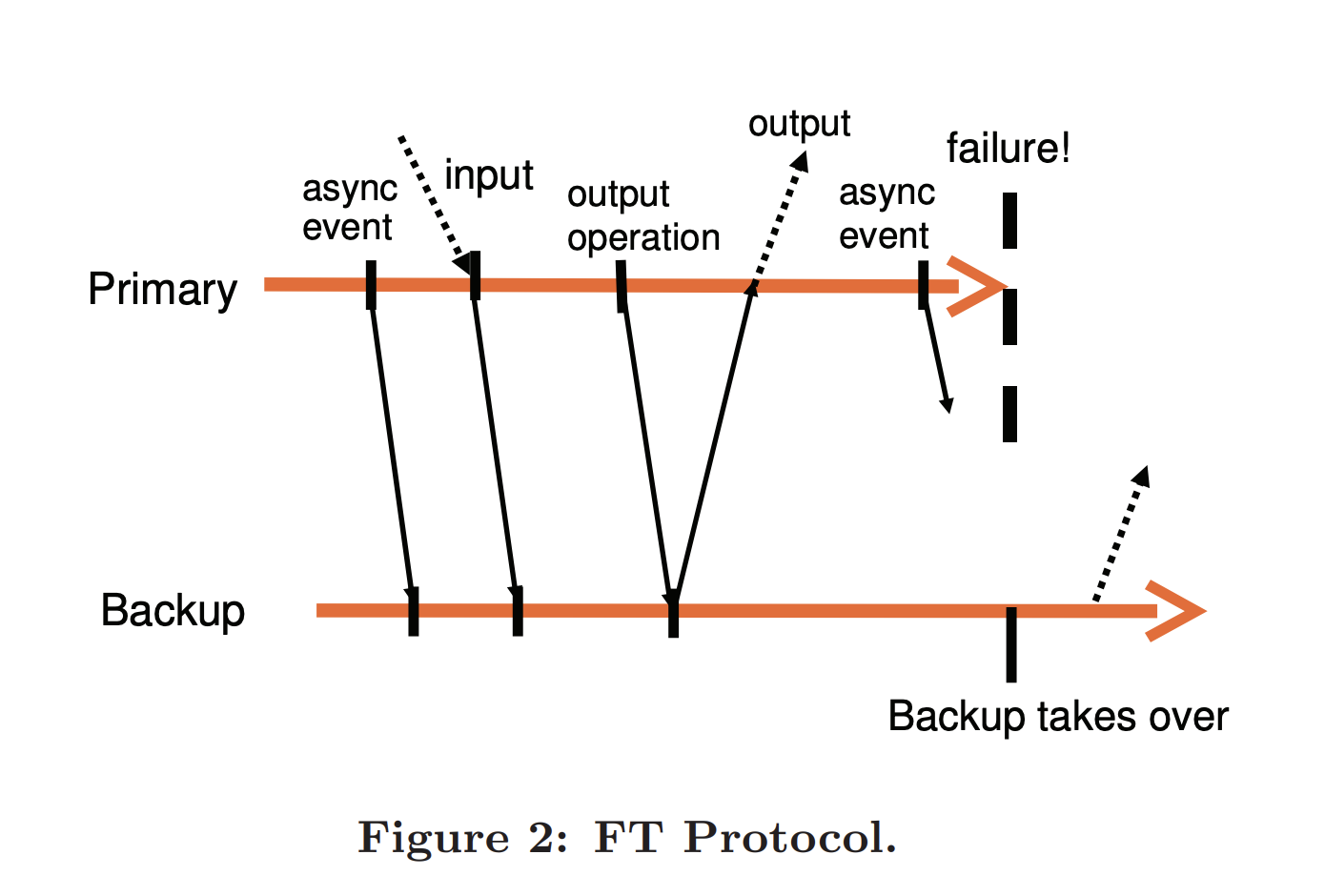 pb-ft-protocol.png
pb-ft-protocol.png
在 Primary 宕机后,Backup 接管时,可能会产生重复的结果。但是由于P/B 共用 TCP channel,SEQ 也会被重用,会在 Client 端作为重复TCP 帧被忽略,从而不会暴露到用户层面。
吞吐
如果 Primary 和 Backup 不在一个城市,每次通信都需要几ms,那么久很难构建高吞吐系统。
网络分区
如果 P/B 之前的网络断了,但是同时都可以和 client 通信,就发生了 split-brain。解决办法是引入一个第三方仲裁,来保存谁可以进行应答:比如使用一个 TAS(Test-and-Set Server) 或者一个共享外存。

