 python-learn.png
python-learn.png
绪论
使用 Logging 前可以先捋一下我们常见的日志输出需求,俗话说,不管需求的设计就是耍流氓。
- 能够定位事件(Event)的产生位置(代码文件&行数)和生成时间,用于调试和跟踪。
- 一份日志可以同时送到多个目标输出。
- 可以通过不同级别或者更精细条件筛选日志输出。
- 可以方便的控制第三方模块的日志输出。
- 实现上面的一切的前提下,配置/设置 尽量简单。
Python 的 Logging 模块通过神奇的模块化设计,树形的方式组织完美的实现了以上五点。
作者:木鸟杂记 https://www.qtmuniao.com, 转载请注明出处
模块设计
Python 的 logger 抽象出了几个具有从属关系的元概念,Logger,Handler ,Filter和 Formattor 作为 logger 实现的基石。
- Loggers 提供了应用代码可以直接使用的接口
- Handlers 将(loggers生成的)日志记录分发到合适的输出
- Filters 提供了对哪些日志进行输出的精细控制
- Formatters 则决定了日志在最终的输出上样式
Loggers
Logger 类作为日志库的基本模块,能做三件小事:
- 它是在用户代码中进行日志输出调用的类,暴露了
debug(), info()等接口; - 根据日志级别和 filter 类决定用户调用该类(
logger.info(msg))时,是否创造一个日志记录(LogRecord)并传递该日志输出的事件; - 作为日志模块树的一个节点,将该事件往根部传递,所有处于传递路径(该logger->parent logger -> … -> root logger)上的所有 logger 节点添加的所有 Handler 都会相应该事件。当然,通过设置 logger 的 propagate = False 或者没有parent logger 可以阻止事件传播。
Handlers
Handler 负责将符合级别要求的日志消息分发到各种 handler 指定的目标输出。Logger 实例可以通过 addHandler 方法添加零到多个 Handler。常见的可以添加的 Handler 子类有 StreamHandler,FileHandler,BaseRotatingHandler 等等。
设想一个场景,某个应用想将所有级别日志信息输出到文件中,将 error 级别以上的日志在标准输出显示,而将所有severity 以上的日志通过邮件报警。那么就可以设置三个 handler,每个handler分别负责捕获不同级别的消息,并且发送到不同的目标输出。
Handler 的最常用的几个方法:
setLevel()和 logger 的同名方法一样,设置最低有效级别。只不过 logger 的行为是将该级别以上的日志消息发送给其所有handler,而 handler的行为是将该级别以上的日志消息输出到相应目标输出。setFormatter()选择该 handler 输出的布局和格式。addFilter()和removeFilter增删过滤规则,用以决定某条日志消息是要过滤掉。
应用程序不要直接使用 Handler 类,这只是一个基类,规定了一些接口和默认行为。
Formatters
与 Handler 不同的是,用户程序可以直接实例化并使用 logging.Formatter 类:
1 | logging.Formatter.__init__(fmt=None, datefmt=None, style='%') |
其中 fmt 规定消息布局和格式,datefmt 指定日期显示格式,style 指定 fmt 串中变量解析方式。
想说下的几个点是
fmt不仅可以指定格式,在 terminal 进行输出时,可以使用ColoredFormatter设定配色方案,使命令行输出变的炫酷起来。style是%, ‘{‘ or ‘$’三选一,默认是%。但 python3 推荐用str.format方式进行字符串格式化,可以改成style = '{'
Filters
精细的控制日志过滤,就先不讲啦,高阶玩家可以自己去看官方文档。
树形组织
Logging 库利用 Python 中天然存在的 Module 间的树形层次结构构建了以 Logger 为树节点的日志系统。这表现在
- logger 和 module_name 具有一一对应关系
- logger 的“有效级别”(effective level)是通过树中向上遍历确定的
- logger 会将事件(写某条日志)沿着树结构像上传递,所有含有 handlers 的 logger 节点都会进行响应
此外,日志模块有个内置的根节点,负责给所有模块日志输出行为一个默认实现。可以通过 root_logger = Logging.getLogger() 即 module_name = None 来获取。该 root_logger 默认的有效日志级别为 WARNING,并 添加了一个默认的 handler,该 handler 绑定了一个简单的 formatter。
也就是说,用户无需任何配置,只要通过 root_logger = Logging.getLogger() 获取 root_logger 即可进行日志输出。而有额外需求的用户,则可以通过前述机制对不同模块的输出位置和布局格式进行精细化的配置。这种开箱即用 + 增量细调 的设计时程序框架常见的手法,可以同时兼顾入门菜鸟和高阶玩家的不同需求。
一一对应
每个logger 是和 python 的 module_name 一一对应的单例。也就是说,在同一进程中,不同位置通过:
1 | smap_logger = logging.getLogger() |
获取的smap_logger 是同一实例。
有效级别
logger 有一个有效级别的概念,当一个 logger 没有被显式的设置日志级别(setLevel)的时候,它就会使用其父节点 logger 的日志级别。如果其父节点的日志级别也没有被显式设置,就会继续看其祖父节点。如此往复,直到找到一个被显式设置了有效级别的 logger 节点。当然,无论如何这个搜寻过程都会在根节点结束,而根节点默认的级别为 WARNING。
当 logger 接收到一个日志输出的事件时,会根据其有效级别来确定该事件是否会分发给该 logger 所添加的所有 handlers。
事件响应
子 loggers 会将日志事件沿着树中的路径向其祖先传递。因此并不需要为所有 logger 绑定 handler,只需要在几个合适的关键顶层节点添加 handler 就可以使得其所有子分支上的日志节点,按该 handler 的行为进行日志输出。
当然,你还可以通过设置某 logger 的 propagrate 属性为 False 来阻止该节点向上传递日志事件。
输出日志流程,可以用下面一张图来说明:
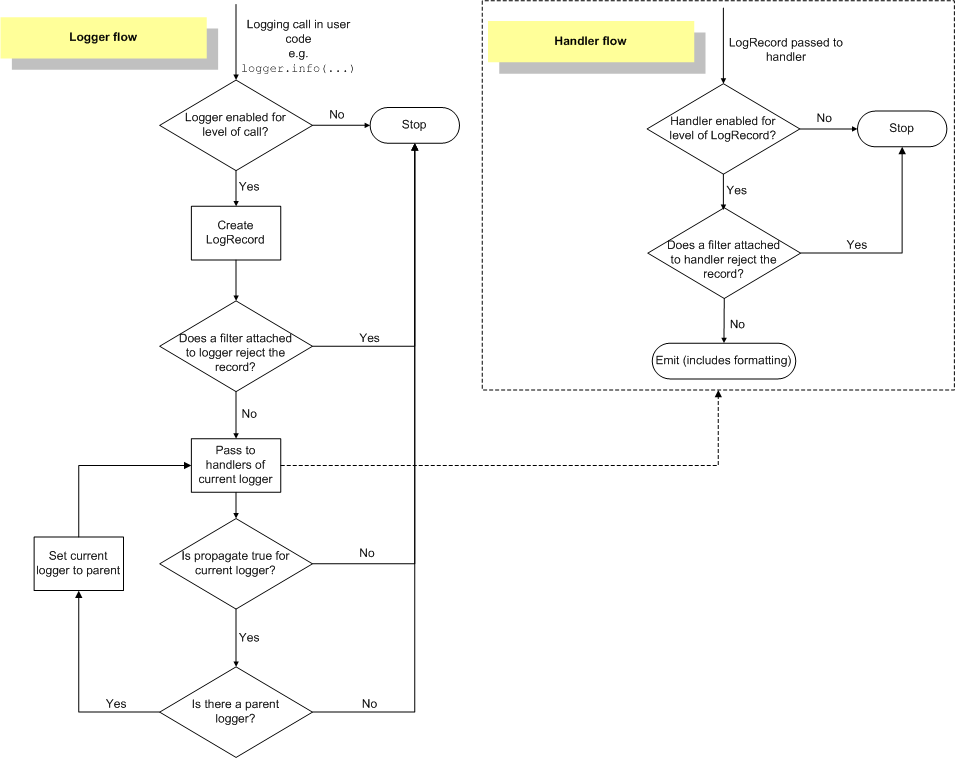 Logging Flow
Logging Flow
实践
一个 example
官方文档提供的一个最基本示例,
1 | import logging |
此外,像 log4j 等 Java 的日志框架一样,这些配置能通过配置文件来完成。包括基本格式和YAML格式。官方文档都有讲。
自己的例子
我在写 smap(slice-map,对数据集分片,分发到多机执行map的一个计算框架)的 Python 库时,想实现功能:可以让用户侧在使用该库时,动态设置该库的日志级别。当时还费劲心机的将日志级别作为一个参数,传递到框架中,然后每次用之前先将该模块的 logger 设置为该有效级别。
如果能早就知道 logging 库模块级别的单例以及树形组织设计,那么基本上实现这个功能就啥也不用做,只需要告诉用户我使用的是 logging 日志库就可以了。用户就可以通过
1 | import logging |
就行了。
注解
「树」:是计算机中一种常用的数据结构,用来模拟具有树种结构性质的数据集合,看起来像一棵根朝上,叶朝下的倒挂树。详细参见维基百科。
「父节点,祖先节点」:都是树这种数据结构范畴内的概念。
「日志事件」: 由 logger.info() 等 API 调用产生,发送给日志系统,让系统决定如何响应该事件在合适位置进行以合适布局和格式进行输出。其他所谓消息(Message),日志记录(LogRecord)其实都是类似的意思。
「目标输出」:各种输出目的地,比如说标准输出(stdout),文件(File),数据库(db),邮件(email),中心化日志服务(log service)等等。
参考
- Logging facility for Python, 该篇大部分来源于此,只是做了个翻译和重新组织。

