计算下推其实是常见的思想:将计算推到数据旁。由于在数据库中,逻辑上,计算常在存储层之上,因此将一部分算子推到存储层去做,称为计算下推。其在分布式数据库中尤为重要。
下面是 CockroachDB 和 TiDB 的解决方案,内容来自于文档和博客,因此可能和最新代码的逻辑并不一致。
CockroachDB
基本概念
CockroachDB 中相应的模块叫 DistSQL,其思想来源于Sawzall,有点类似 MapReduce。支持的算子叫做 aggregator,本质上是对 SQL 聚合算子的一种泛化。
作者:木鸟杂记 https://www.qtmuniao.com/2022/04/05/crdb-tidb-dist-sql 转载请注明出处
在逻辑上,每个 aggregator 接受一个输入行流(Join 会有多个),产出一个输出行流(output stream of rows)。一行(row)是由多个列值(column values)构成的元组。输入输出流中会包含每个列值的类型信息,即模式(Schema)。
CockroachDB 还引入了组( group )的概念,每个组是一个并行的单元。划分组的依据是组键(group key),可以看出思想有点类似于 MapReduce 中的 Reduce 阶段的 Key。组键其实是 SQL 中 group by 的泛化。两个极端情况:
- 所有行同属一个组。则所有的行只能在单节点执行,而不能并发。
- 每一行各属一个组。则可以随意切分行的集合,进行并发。
aggregators
有些 aggregator 的输入、输出或逻辑有一些特殊之处:
- table reader 没有输入流,会直接从本机 KV 层拿数据。
- final 没有输出流,提供最终结果给 query\statement。
- final 和 limit 对输入流有顺序要求(ordering requirement)。
- evaluator 可以通过代码自定义其行为逻辑。
逻辑到物理
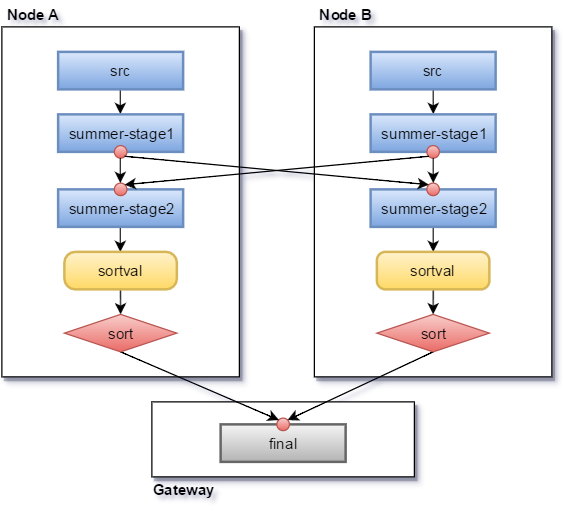
执行过程有点类似于 Spark 中对 DAG 的拓扑调度和执行。
- 读取会被下发到每个 range ,由 range 的 raft leader 负责。
- 遇到非 shuffle aggregator,则在各个节点并发执行。
- 遇到 shuffle 的 aggregator(比如 group by),就使用某种哈希策略,将输出数据送到对应机器。
- 最后在 gateway 机器上执行 final aggregator。
 multi-aggregator.png
multi-aggregator.png
单个 Processor
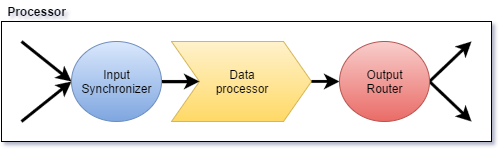
每个逻辑 aggregator 在物理上对应一个 Processor,都可以分为三个步骤:
- 接受多个输入流,进行合并。
- 数据处理。
- 对输出按 group 分发到不同机器上。
 single-aggregator.png
single-aggregator.png
引用
- cockroachdb SQL layer query execution: https://www.cockroachlabs.com/docs/stable/architecture/sql-layer.html#query-execution
- https://github.com/cockroachdb/cockroach/blob/master/docs/tech-notes/life_of_a_query.md
- cockroach db rfc 20160421_distributed_sql****:**** https://github.com/cockroachdb/cockroach/blob/master/docs/RFCS/20160421_distributed_sql.md
TiDB
基本概念
TiDB 中的 SQL 执行过程中主要流程为:
- 进行词法分析生成 AST(Parsing)
- 利用 AST 进行各种验证、变化,生成逻辑计划(Planing)
- 对逻辑计划进行基于规则的优化,生成物理计划(Optimizing)
- 对物理计划进行基于代价的优化,生成执行器(Executor)
- 运行执行器(Executing)
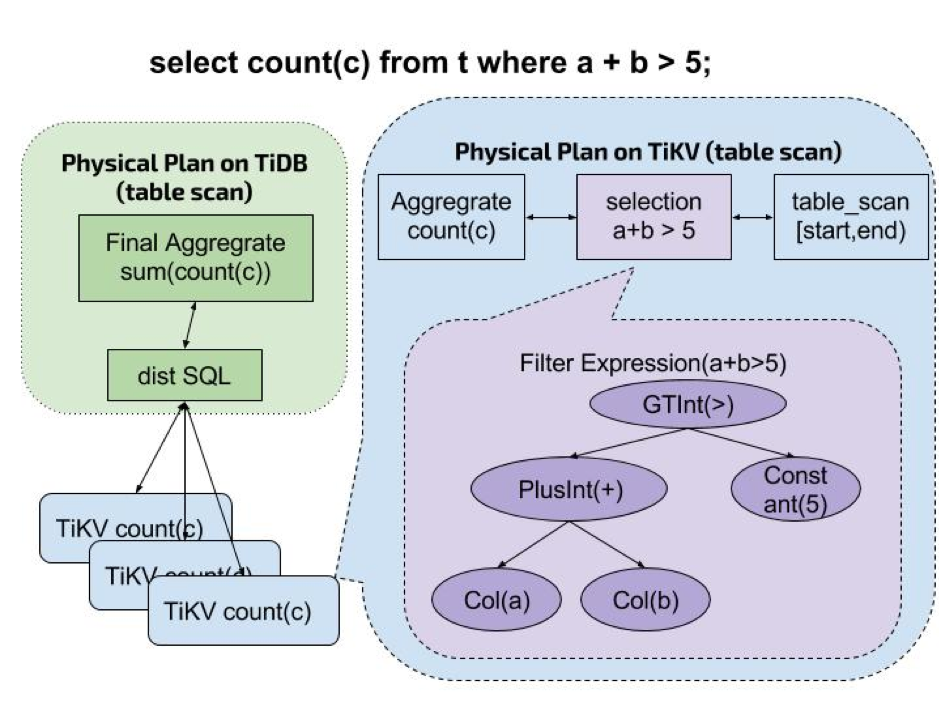
由于 TiDB 的数据在存储层 TiKV 中,在步骤 5 ,如果将所涉及到的所有 TiKV 数据全部放到 TiDB 层进行执行,会有以下问题:
- 存储层(TiKV)到计算层(TiDB)过大的网络开销。
- 计算层过多的数据计算对 CPU 的耗费。
为了解决这个问题,并充分利用 TiKV 层的分布式特性,PingCAP 在 TiKV 层增加了 Coprocessor ,即在 TiKV 层读取数据后进行计算的模块。在执行 SQL (主要是读取)时,将部分物理计划(即部分算子组成的 DAG)整个下推到 TiKV 层,由 Coprocessor 执行。
 coprocessor.png
coprocessor.png
Executors
从 TiKV 的 protobuf 接口定义中可以看出,当期 TiKV 支持的 Coprocessor 算子(TiKV 中又称 Executor)类型有:
1 | enum ExecType { |
单个 Coprocessor
Coprocessor 接受一个由 Executor 作为节点组成的 DAGRequest,利用向量化模型:
- 扫描指定数据
- 以 Chunk 为单位依次执行所有算子
- 将结果返回到 TiDB 层
小结
CRDB 和 TiDB 在执行 SQL 时最大的区别在于:
- CRDB 使用类似 MapReduce 的 MPP 模型,因此多台存储节点间需要通信互相传输数据。
- TiDB 中是存储计算分离,将能下推的计算以 DAG 的形式尽可能的下推,而需要多个节点合并计算只能在计算层做,因此多台存储节点间不需要通信以传输数据。
粗浅理解,有写的不对或需要补充之处,欢迎留言。

