最近翻 DuckDB 的执行引擎相关的 PPT(Push-Based-Execution) 时,发现了这篇论文:Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age。印象中在执行引擎相关的文章中看到他好几次;且 NUMA 架构对于现代数据库架构设计非常重要,但我对此了解尚浅,因此便找来读一读。
从题目中也可以看到,论文最主要关键词有两个:
- NUMA-Aware
- Morsel-Driven
据此,大致总结下论文的中心思想:
- 多核时代,由于部分 CPU 和部分内存的绑定关系,CPU 访问内存是不均匀(NUMA)的。也即,对于某一个 CPU 核来说,本机上一部分内存访问延迟较低,另一部分内存延迟要高。
- 传统火山模型,使用 Exchange 算子来进行并发。其他算子并不感知多线程,因此也就没办法就近内存调度计算(硬件亲和性)。也即,非 NUMA-local。
- 为了解决此问题,论文在数据维度:对数据集进行水平分片,一个 NUMA-node 处理一个数据分片;对每个分片进行垂直分段(Morsel),在 Morsel 粒度上进行并发调度和抢占执行。
- 在计算维度:为每个 CPU 预分配一个线程,在调度时,每个线程只接受数据块(Morsel)分配到本 NUMA-node 上的任务;当线程间子任务的执行进度不均衡时,快线程会”窃取“本应调度到其他线程的任务,从而保证一个 Query 的多个子任务大约同时完成,而不会出现”长尾“分片。
作者:木鸟杂记 https://www.qtmuniao.com/2023/08/21/numa-aware-execution-engine 转载请注明出处
背景铺垫
论文中出现了一些名词,如果不了解其内涵,可能很对论文的一些关键设计点理解到位,因此这里对相关概念和背景做了一些铺垫。
NUMA
NUMA,是 Non-Uniform Memory Access 的缩写,即非一致性内存访问架构。传统 UMA (一致性访存)架构比较好理解,它也是我们通常以为的内存访问模型——所有 CPU core 访问本机所有内存的延迟是一致的(下图源):
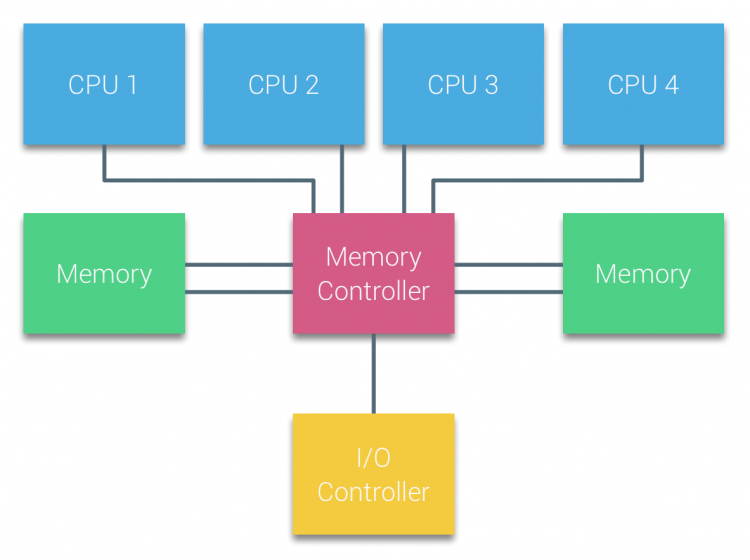 uma-architecture.png
uma-architecture.png
但在多核(现在常用的服务器动不动就是 50+ core)时代,内存访问总线会”争用“非常严重,从而造成内存延迟迅速增高。于是,便有了 NUMA 架构——将单机内存切分成几块,分别和一些 CPU 进行绑定。一组绑定的 CPU 和内存通常称为一个 NUMA-node 或者 NUMA socket。
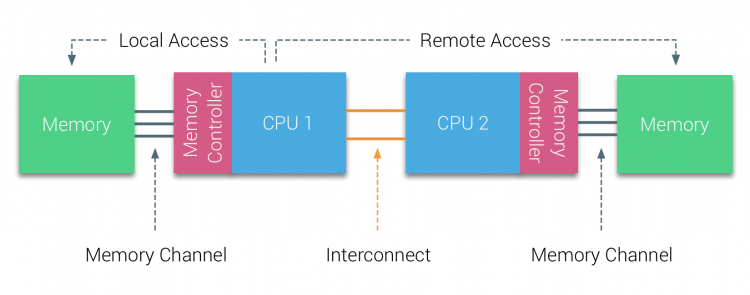 numa-architecture.png
numa-architecture.png
上图只是一个示意图,通常一个 NUMA-node 会有很多个 CPU core,而非上图中的一个。那么,本 NUMA-node 的访问就是 Local Access,对其他 NUMA-node 的内存访问就是 Remote Access,后者通常要比前者慢几倍。
1 | ~ numactl --hardware |
上面代码是通过 numactl 命令查看的一个物理机的 NUMA 情况。可以看出该物理机一共有 56 核,分为两个 NUMA-node,每个 28 核,每个 NUMA-node 有 128G 内存,local access 和 remote access 访问延迟比大概是 10: 21。
通常来说,操作系统尽量将线程和其使用的内存分配到同一个 NUMA-node 中,尤其是只需要小内存的线程。但对于数据库这种遇到大内存(buffer pool)的系统来说,内存分配很容易跨 NUMA-node,因此需要专门设计。
在分布式环境下,一个机器节点本质上就是一组CPU + 一块内存的资源容器;而在单机上,一个 NUMA-node 也是如此。因此,以看待分布式调度算法的思想(将计算调度到存储旁)看待本论文,很多地方或可更易理解。
火山模型
火山模型是最传统、经典的一种数据库执行引擎模型。在火山模型中,SQL 语句会转化成一棵算子树,其中每个算子都实现了 open-next-close 接口;通过自上而下的(对 next)树形递归调用,完成数据的处理。
火山模型中的算子有个特点,就是不感知其所处理的数据在哪块内存、也不感知自己运行在哪个 CPU 上,甚至不感知是否为并行执行。当然,为了利用多核性能,可以扩展火山模型,通过 Exchange 算子来实现类似 partition→parallel processing→merge 的 shuffle 操作,从而将算子树进行并发执行。Exchange 算子可以插入算子树的任何一个位置,从而改变局部并发。除此之外,其他算子都不会感知并行运行细节。这种模型的优点在于,简洁优雅、表达能力强。但在多核时代,这种模型显然没有照顾到 NUMA 架构特点。
对于上述火山模型,我们通常将其执行模式称为基于拉(”pull-based“)的。因为我们都问从算子树的根节点要数据,而根节点会递归的向孩子节点要数据,直到叶子节点(通常是各种 scan 节点)。整体,就像从根节点往外”拉“数据一样。
与基于拉的模式相对,我们还有基于推(”push-based“)的执行模式。就像在代码中将递归转化为迭代一样,push-base 就是直接从叶子节点开始执行,在算子执行完生成新的数据后,会往数据下游算子(算子树中的父节点)推数据。
这两者最大的不同在于,pull-based 是不需要进行算子级别的调度的,所有数据都是”需求倒逼生产“,下游一步步问上游要;而 push-based 则需要一个全局调度器来协调上下游的数据生产消费关系——在下游能够接受数据时,将上游吐出来的数据推给下游。
Pipeline
在 push-based 的模式下,我们通常会将算子树切分成多个线性的流水线( Pipeline),并以 Pipeline (下图中虚线部分)的粒度进行执行调度。每个 pipeline 也可称为 pipeline segment,即整个算子树的一部分。
 pipeline-split.png
pipeline-split.png
Pipeline 的切口处,我们通常称之为 Pipeline Breaker——即 Pipeline 进行不下去,要进行切分了。如果你恰好对 Spark 的执行 Stage 划分有所了解,就会发现他们原理是一样的——在 Shuffle 处进行切分。而 Join 处通常会发生 shuffle。
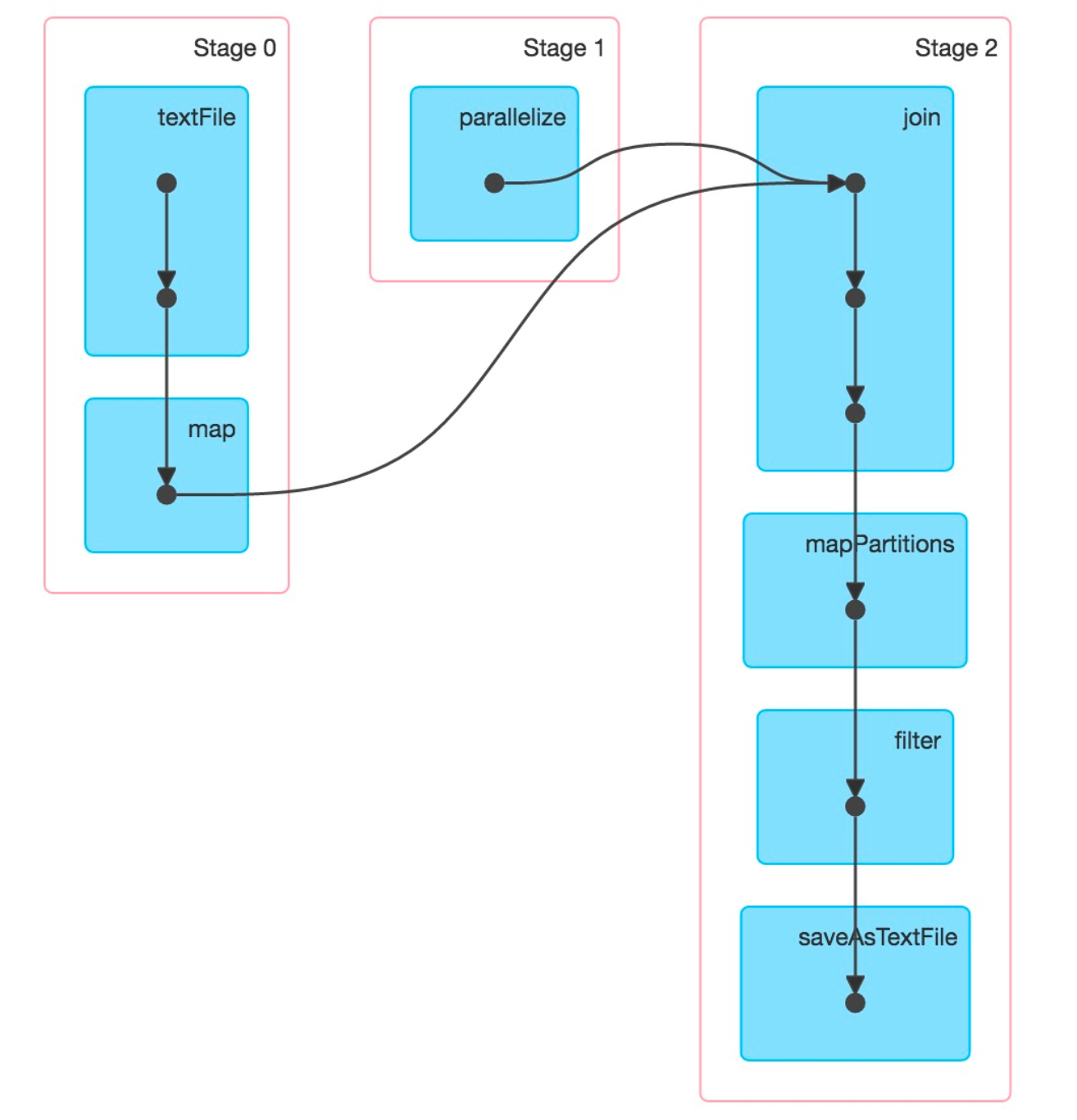 stage-split.png
stage-split.png
morsel
morsel 是本论文提出的一个类似”数据块“的概念,可以理解为关系数据库中的多个行(row)或者多个元组(tuple),这是本论文的最小调度和单元,对应下文中相同颜色标出的部分。
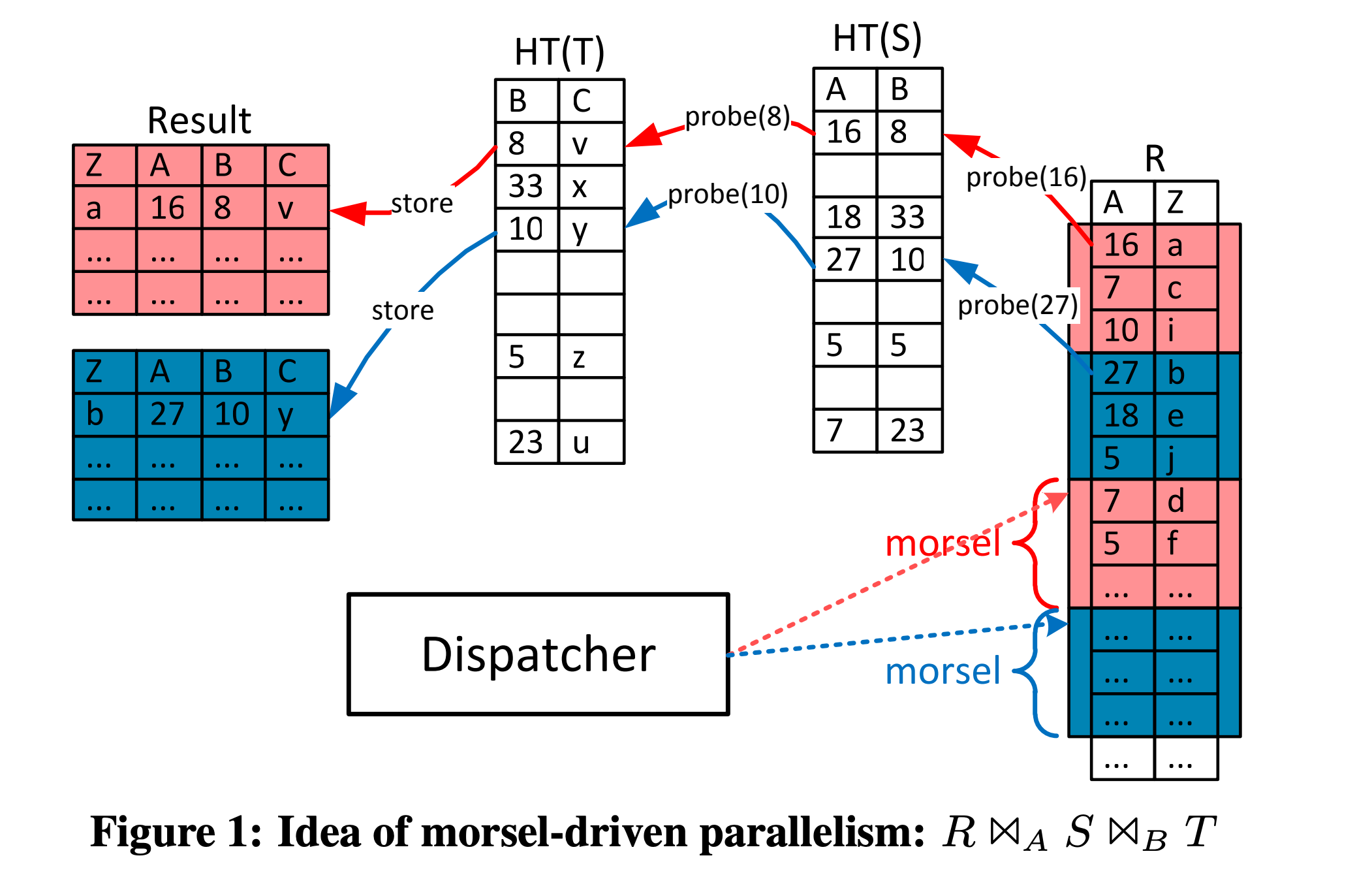 data-parallelism-morsel.png
data-parallelism-morsel.png
若想理解 morsel,可以对比 CPU 的时间片。只有将 CPU 切换成一块块大小合适的时间片段,我们才能更加方便的设计利用率高(更容易做均衡调度)、可抢占(单块时间片完成后而不必等待整个任务完成,便可调入其他任务占用时间片)、带优先级(执行新的时间片时,按优先级选择任务)的各种调度算法。
内容概要
morsel 驱动执行
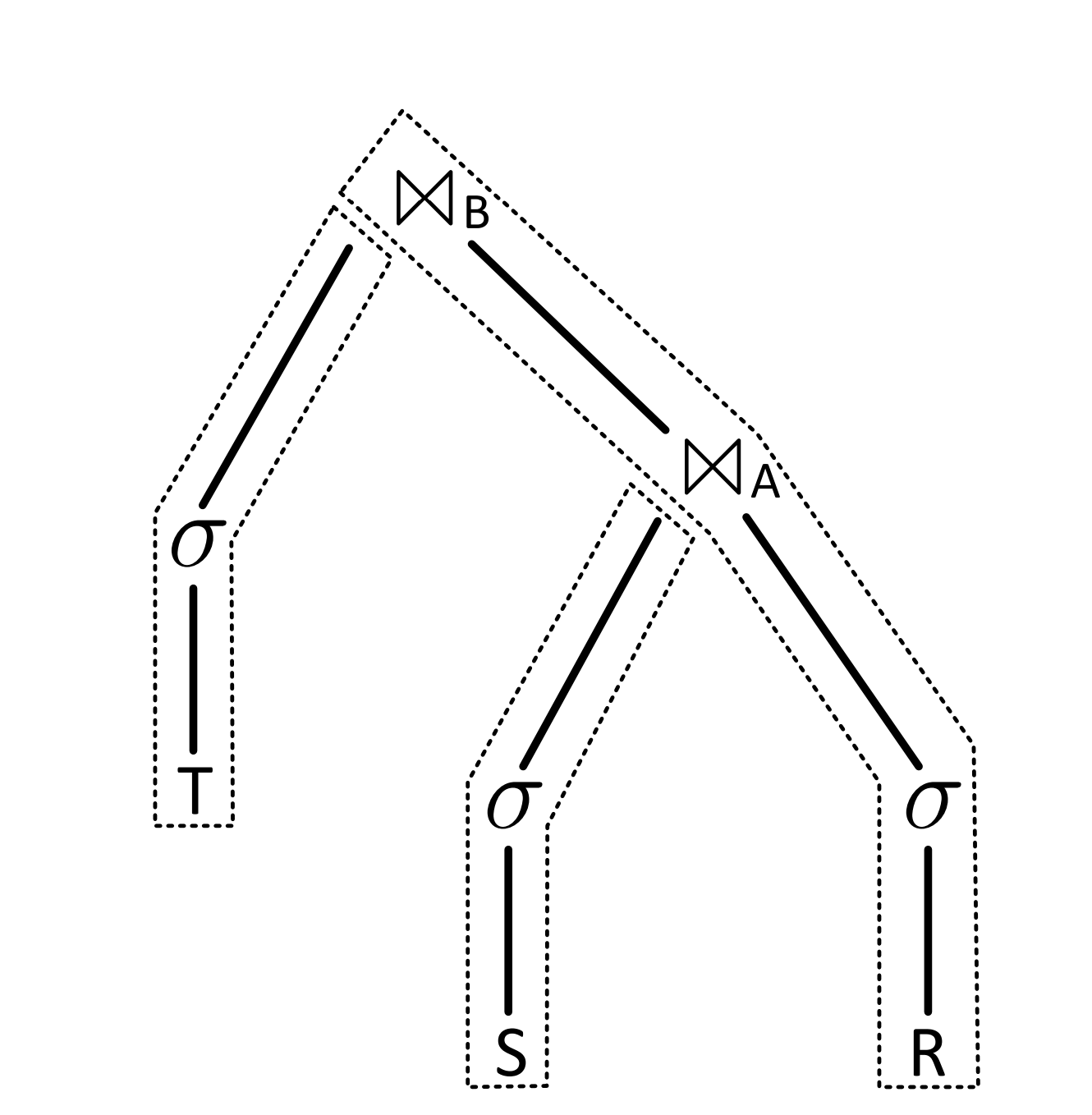
论文首先举了 σ...(R) >< A σ...(S) >< B σ...(T) 的三张表进行 inner join 的例子,其中 S 和 T 是小表。则在 Join 时对其 scan 后进行 Build 构建 HashTable;R 是大表,则在 S 和 T 的 HashTable 构建完成后,扫描以 Probe。将 HashJoin 切成 HashBuild(构建 HashTable)和 HashProbe(利用 HashTable 进行匹配),是经典的 HashJoin 的执行过程。
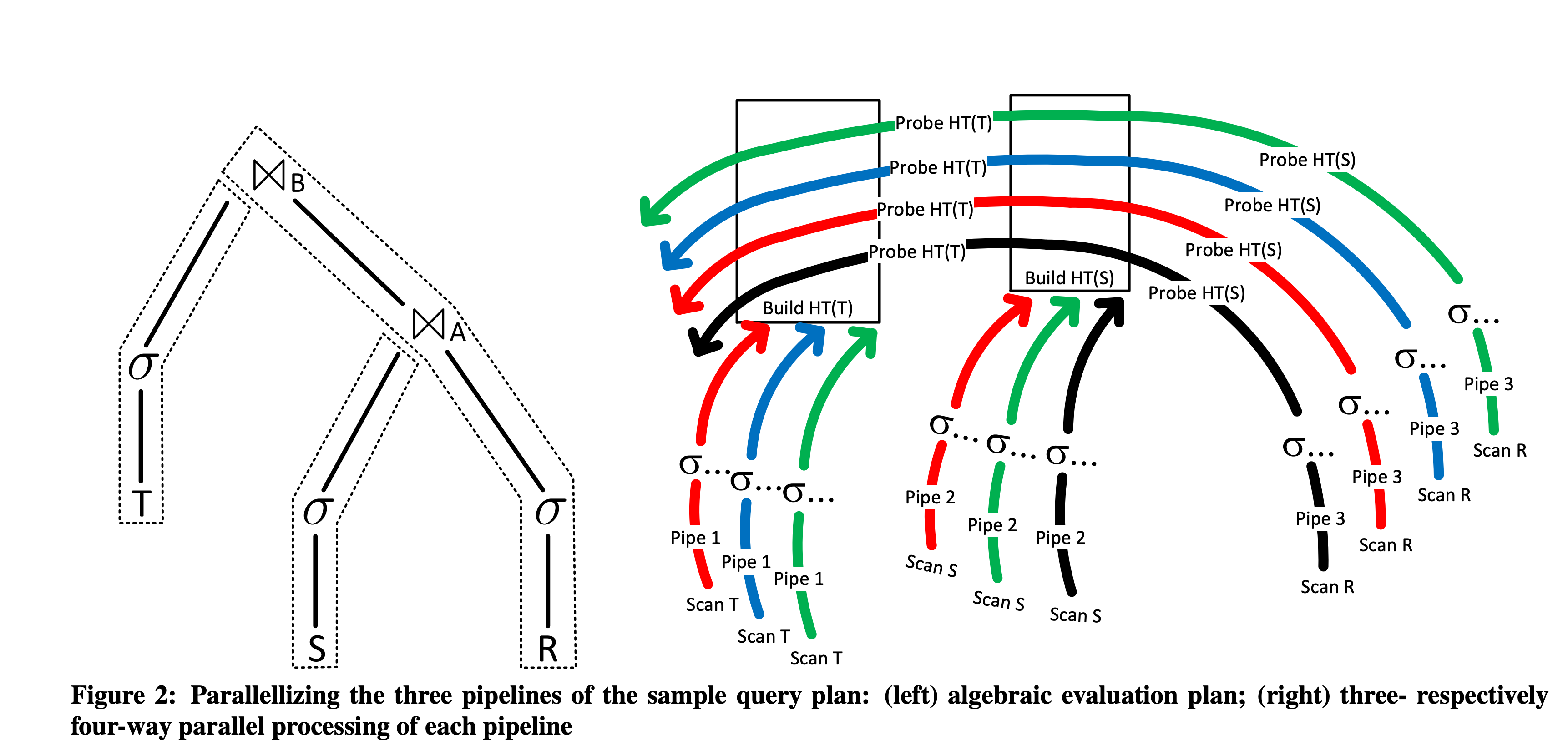 3-pipelines-parallelism.png
3-pipelines-parallelism.png
结合之前 Pipeline 的背景知识,可以推断出该执行计划会被划分为三个 Pipeline,分别是 HashTable(T) 的构建 、HashTable(S) 的构建 Pipeline 和 R 的探测。下面分别来说:
HashTable 的构建。两个 HashTable 的构建过程是类似的,以 HashTable(T) 为例,构建过程又会分为两个阶段:
- 阶段一(Phase 1):将 T 的 scan 输出按 morsel 粒度均匀分发给几个 CPU core 的 storage area,本质上是 Partition 的过程。
- 阶段二(Phase 2):每个 CPU core 对应的线程去扫描被分派的数据分片(包含很多 morsel),构建一个全局(跨线程)HashTable,本质上是 Merge 的过程。
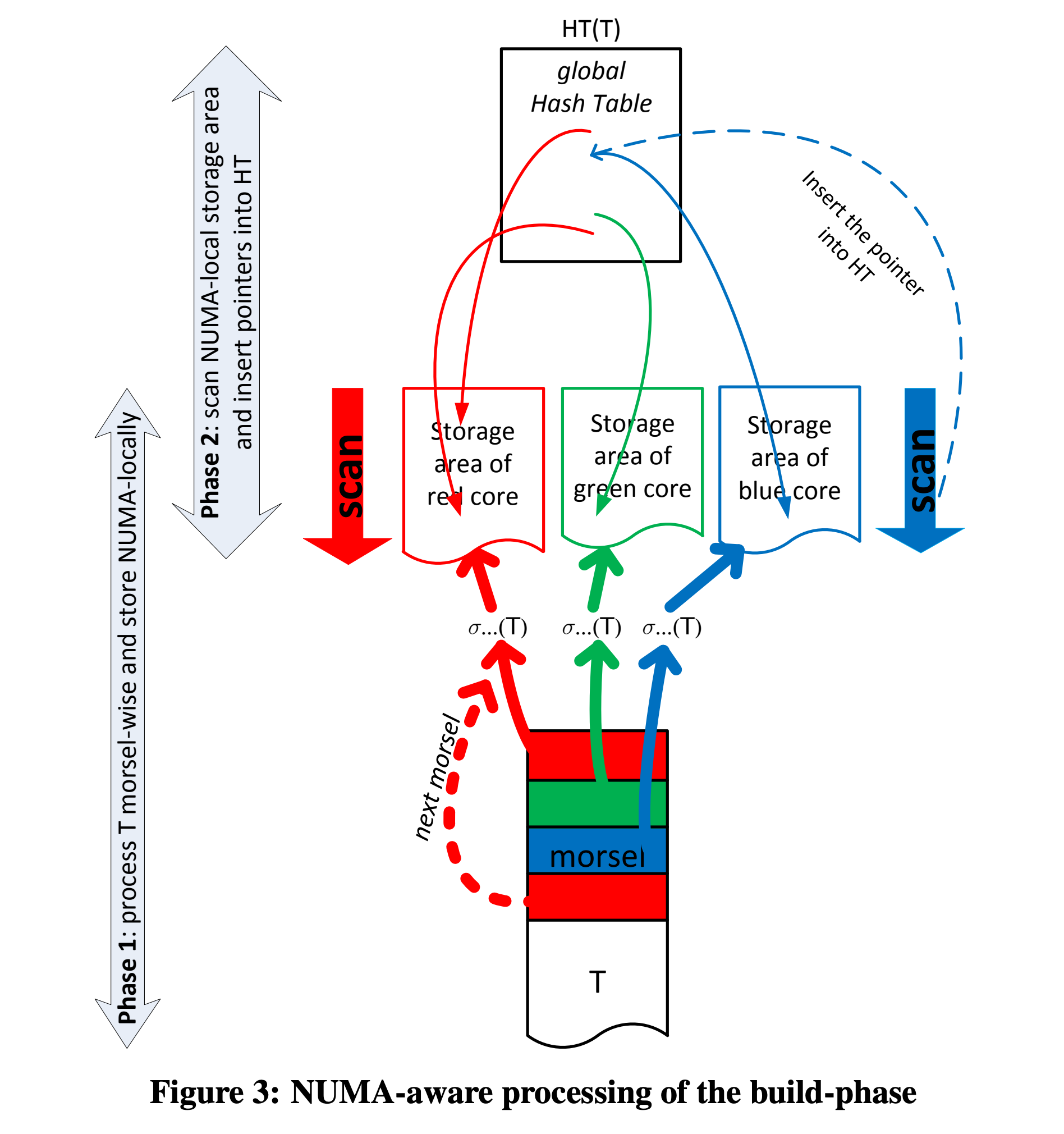 numa-aware-build-phase.png
numa-aware-build-phase.png
为了并行的对数据进行处理,通常都会有个数据分片阶段——按某种方式将一个输入流变成多个输入流。正如在 MapReduce 之前有个 split 的过程。
第二个阶段会涉及跨线程的数据写入,因此需要对 HashTable 这个跨线程的全局数据结构的实现做一些优化:
- 在阶段一确定 HashTable 的大小,一次性预分配 HashTable,避免 HashTable 动态增长造成的
- 只将数据的指针插入 HashTable,避免跨线程的数据拷贝。
- HashTable 使用无锁结构,降低多线程插入时争用造成的性能下降。
HashTable 的探测。在 HashTable(T) 和 HashTable(S) 构建完成后,就会开始对 R 表的探测。R 表在扫描后,其数据也会被分派到多个 NUMA-node 上去,进行并行的探测,探测完成后也会输出到线程所在的 NUMA-local。
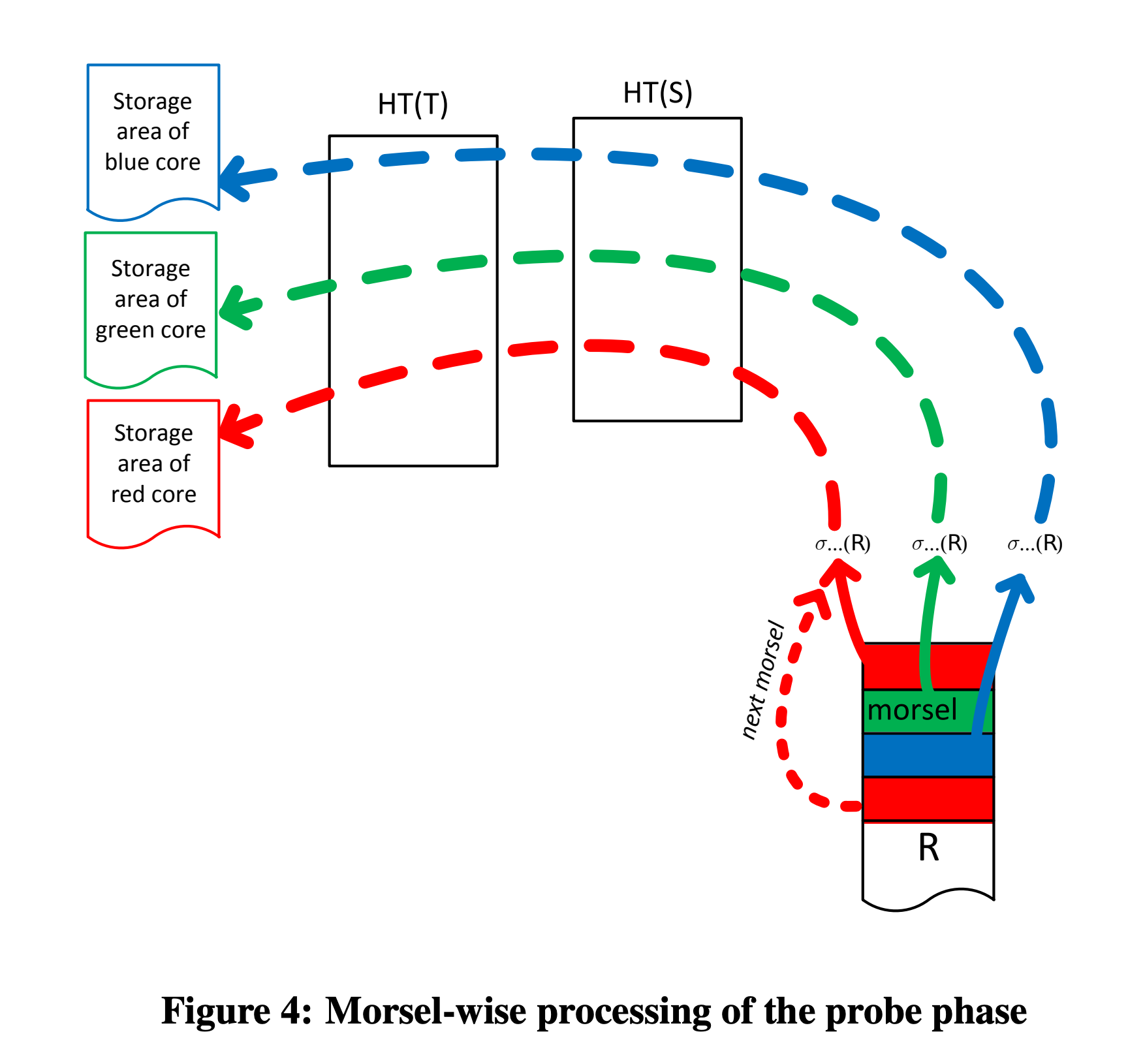 numa-aware-proble-phase.png
numa-aware-proble-phase.png
如果探测之后还有其他的算子,比如 Top、Filter、Limit 等等,也会被调度到 Probe 输出所在 NUMA-node 上进行执行。
不同于火山模型,这些算子(比如上图中的 HashJoin)要感知并行,并需要进行同步。
关于 Dispatcher 的实现和一些具体算子的实现,可以去我的系统专栏里看。
参考
- Viktor Leis等人论文,https://15721.courses.cs.cmu.edu/spring2016/papers/p743-leis.pdf
- draveness,NUMA 架构设计:https://draveness.me/whys-the-design-numa-performance/
- dirtysalt,Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age: https://dirtysalt.github.io/html/morsel-driven-parallelism-framework.html
- 张茄子,OLAP 任务的并发执行与调度: https://io-meter.com/2020/01/04/olap-distributed/
本文来自我的小报童付费专栏《系统日知录》,专注分布式系统、存储和数据库,有图数据库、代码解读、优质英文播客翻译、数据库学习、论文解读等等系列,欢迎喜欢我文章的朋友订阅 专栏支持,你的支持对我持续创作优质文章非常重要。下面是当前文章列表:
图数据库系列
- 图数据库资料汇总
- 译: Factorization & Great Ideas from Database Theory
- Memgraph 系列(二):可串行化实现
- Memgraph 系列(一):数据多版本管理
- 【图数据库系列四】与关系模型的“缘”与“争”
- 【图数据库系列三】图的表示与存储
- 【图数据库系列二】 Cypher 初探
- 【图数据库系列一】属性图模型是啥、有啥不足 🔥
数据库
- 译:数据库五十年来研究趋势
- 译:数据库中的代码生成(Codegen in Databas…
- Facebook Velox 运行机制解析
- 分布式系统架构(二)—— Replica Placement
- 【好文荐读】DuckDB 中的流水线构建
- 译:时下大火的向量数据库,你了解多少?
- 数据处理的大一统——从 Shell 脚本到 SQL 引擎
- Firebolt:如何在十八个月内组装一个商业数据库
- 论文:NUMA-Aware Query Evaluation Framework 赏析
- 优质信息源:分布式系统、存储、数据库 🔥
- 向量数据库 Milvus 架构解析(一)
- ER 模型背后的建模哲学
- 什么是云原生数据库?
存储
- 存储引擎概述和资料汇总 🔥
- 译:RocksDB 是如何工作的
- RocksDB 优化小解(二):Prefix Seek 优化
- RocksDB 优化小解(三):Async IO
- 大规模系统中使用 RocksDB 的一些经验
代码&编程
- 影响我写代码的三个 “Code” 🔥
- Folly 异步编程之 futures
- 关于接口和实现
- C++ 私有函数的 override
- ErrorCode 还是 Exception ?
- Infra 面试之数据结构(一):阻塞队列
- 数据结构与算法(四):递归和迭代
每天学点数据库系列
- 【每天学点数据库】Lecture #06:内存管理
- 【每天学点数据库】Lecture #05:数据压缩
- 【每天学点数据库】Lecture #05:负载类型和存储模型
- 【每天学点数据库】Lecture #04:数据编码
- 【每天学点数据库】Lecture #04:日志构型存储
- 【每天学点数据库】Lecture #03:Data Layout
- 【每天学点数据库】Lecture #03: Database and OS
- 【每天学点数据库】Lecture #03:存储层次体系
- 【每天学点数据库】Lecture #01:关系代数
- 【每天学点数据库】Lecture #01:关系模型
- 【每天学点数据库】Lecture #01:数据模型
杂谈
- 数据库面试的几个常见误区 🔥
- 生活工程学(一):多轮次拆解🔥
- 系统中一些有趣的概念对
- 系统设计时的简洁和完备
- 工程经验的周期
- 关于“名字”拿来
- Cache 和 Buffer 都是缓存有什么区别?

