“工业流水线”的鼻祖,福特 T 型汽车的电机装配,将组装过程拆成 29 道工序,将装备时间由平均二十分钟降到五分钟,效率提升四倍 ,下图图源。
 T-model-car.png
T-model-car.png
这种流水线的思想在数据处理过程中也随处可见。其核心概念是:
- 标准化的数据集合:对应待组装对象,是对数据处理中各个环节输入输出的一种一致性抽象。所谓一致,就是一个任意处理环节的输出,都可以作为任意处理环节的输入。
- 可组合的数据变换:对应单道组装工序,定义了对数据进行变换的一个原子操作。通过组合各种原子操作,可以具有强大的表达力。
则,数据处理的本质是:针对不同需求,读取并标准化数据集后,施加不同的变换组合。
作者:木鸟杂记 https://www.qtmuniao.com/2023/08/21/unify-data-processing 转载请注明出处
Unix 管道
Unix 管道是一项非常伟大的发明,体现了 Unix 的一贯哲学:
程序应该只关注一个目标,并尽可能把它做好。让程序能够互相协同工作。应该让程序处理文本数据流,因为这是一个通用的接口。
— Unix Pipe 机制发明者 Malcolm Douglas McIlroy
上述三句话哲学正体现了我们提到的两点,标准化的数据集合——来自标准输入输出的文本数据流,可组合的数据变换——能够协同工作的程序(如像 sort, head, tail 这种 Unix 自带的工具,和用户自己编写的符合管道要求的程序)。
让我们来看一个使用 Unix tools 和管道来解决实际问题的例子。假设我们有一些关于服务访问的日志文件(var/log/nginx/access.log ,例子来自 DDIA 第十章),日志的每一行格式如下:
1 | // $remote_addr - $remote_user [$time_local] "$request" |
我们的需求是,统计出日志文件中最受欢迎的五个网页。使用 Unix Shell ,我们会写出类似的命令:
1 | cat /var/log/nginx/access.log | # 读取文件,打入标准输出 |
可以看出上述 Shell 命令有以下几个特点:
- 每个命令实现的功能都很简单(高内聚)
- 所有命令通过管道进行组合(低耦合),当然这也要求可组合的程序只面向标准输入、标准输出进行编程,无其他副作用(比如输出到文件)
- 输入输出面向文本而非二进制
此外,Unix 的管道的另一大优点是——流式的处理数据。也即所有程序中间结果并非都计算完成之后,才送入下一个命令,而是边算边送,从而达到多个程序并行执行的效果,这就是流水线的精髓了。
当然,管道也有缺点——只能进行线性的流水线排布,这也限制了他的表达能力。
GFS 和 MapReduce
MapReduce 是谷歌 2004 年的论文 MapReduce: Simplified Data Processing on Large Clusters 提出的,用以解决大规模集群、并行数据处理的一种算法。GFS 是与 MapReduce 配套使用的基于磁盘的分布式文件系统。
MapReduce 算法主要分为三个阶段:
- Map:在不同机器上并行的对每个数据分区执行用户定义的
map() → List<Key, Value>函数。 - Shuffle:将 map 的输出结果(KV 对)按 key 进行重新分区,按 key 聚集送到不同机器上,
Key→ List<Value>。 - Reduce:在不同机器上并行地对 map 输出的每个 key 对应的
List<Value>调用 reduce 函数。
(下图源 DDIA 第十章)
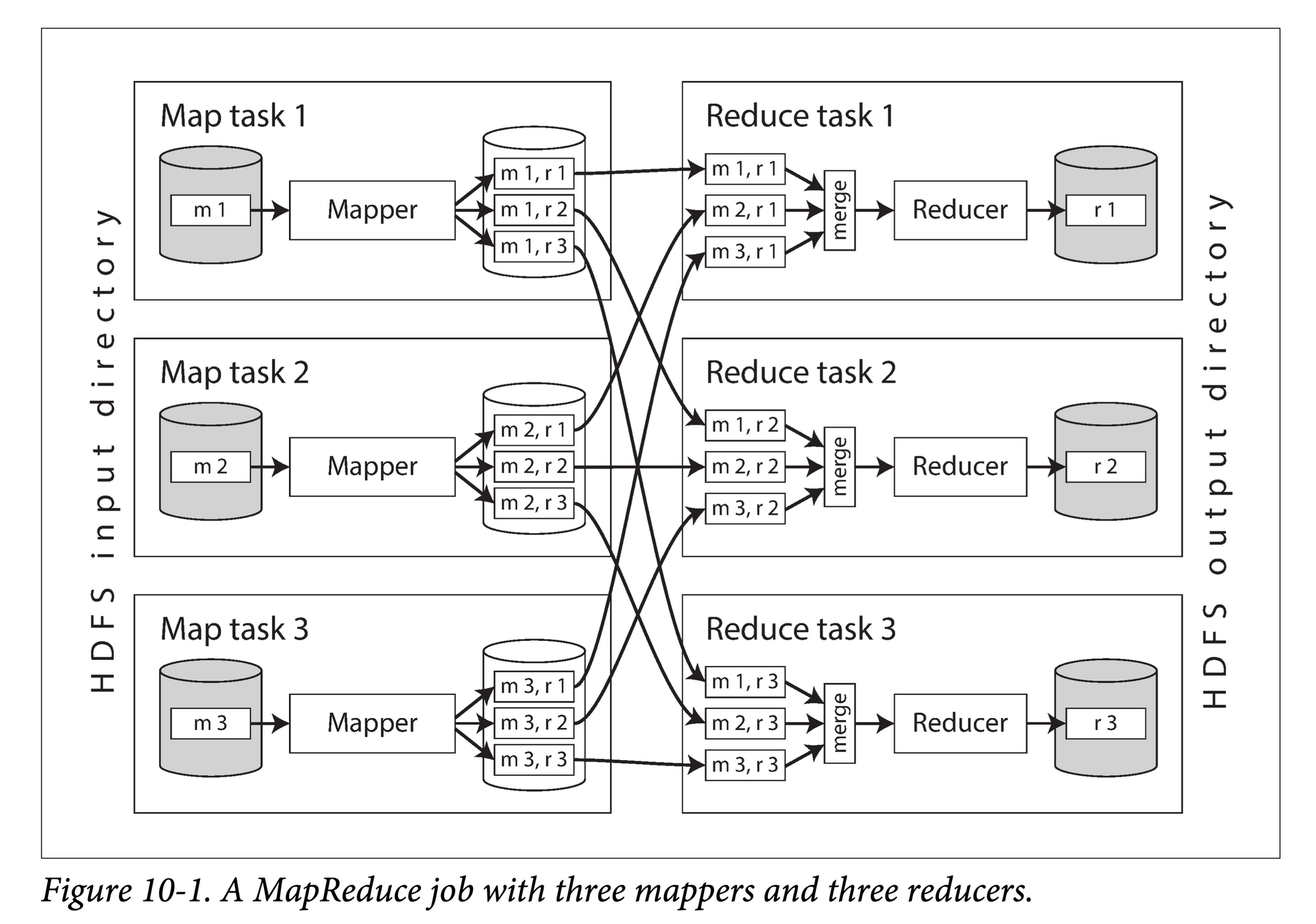 mapreduce.png
mapreduce.png
每个 MapReduce 程序就是对存储在 GFS 上的数据集(标准化的数据集)的一次变换。理论上,我们可以通过组合多个 MapReduce 程序(可组合的变换),来满足任意复杂的数据处理需求。
但与管道不同的是,每次 MapReduce 的输出都要进行“物化”,即完全落到分布式文件系统 GFS 上,才会执行下一个 MapReduce 程序。好处是可以进行任意的、非线性的 MapReduce 程序排布。坏处是代价非常高,尤其考虑到 GFS 上的文件是多机多副本的数据集,这意味着大量的跨机器数据传输、额外的数据拷贝开销。
但要考虑到历史上开创式的创新,纵然一开始缺点多多,但会随着时间迭代而慢慢克服。GFS + MapReduce 正是这样一种在工业界开创了在大规模集群尺度上处理海量数据的先河。
Spark
Spark 便是为了解决 MapReduce 中每次数据集都要落盘的一种演进。
首先,Spark 提出了标准的数据集抽象——RDD,这是一种通过分片的形式分散在多机上、基于内存的数据集。基于内存可以使得每次处理结果不用落盘,从而处理延迟更低。基于分片可以使得在机器宕机时,只用恢复少量分片,而非整个数据集。逻辑上,我们可以将其当做一个整体来进行变换,物理上,我们使用多机内存承载其每个分片。
其次,基于 RDD,Spark 提供了多种可灵活组合的算子集,这相当于对一些常用的变换逻辑进行“构件化”,可以让用户开箱即用。(下面图源 RDD 论文)
 rdd-operators.png
rdd-operators.png
基于此,用户可以进行任意复杂数据处理,在物理上多个数据集(点)和算子(边)会构成一个复杂的 DAG (有向无环图)执行拓扑:
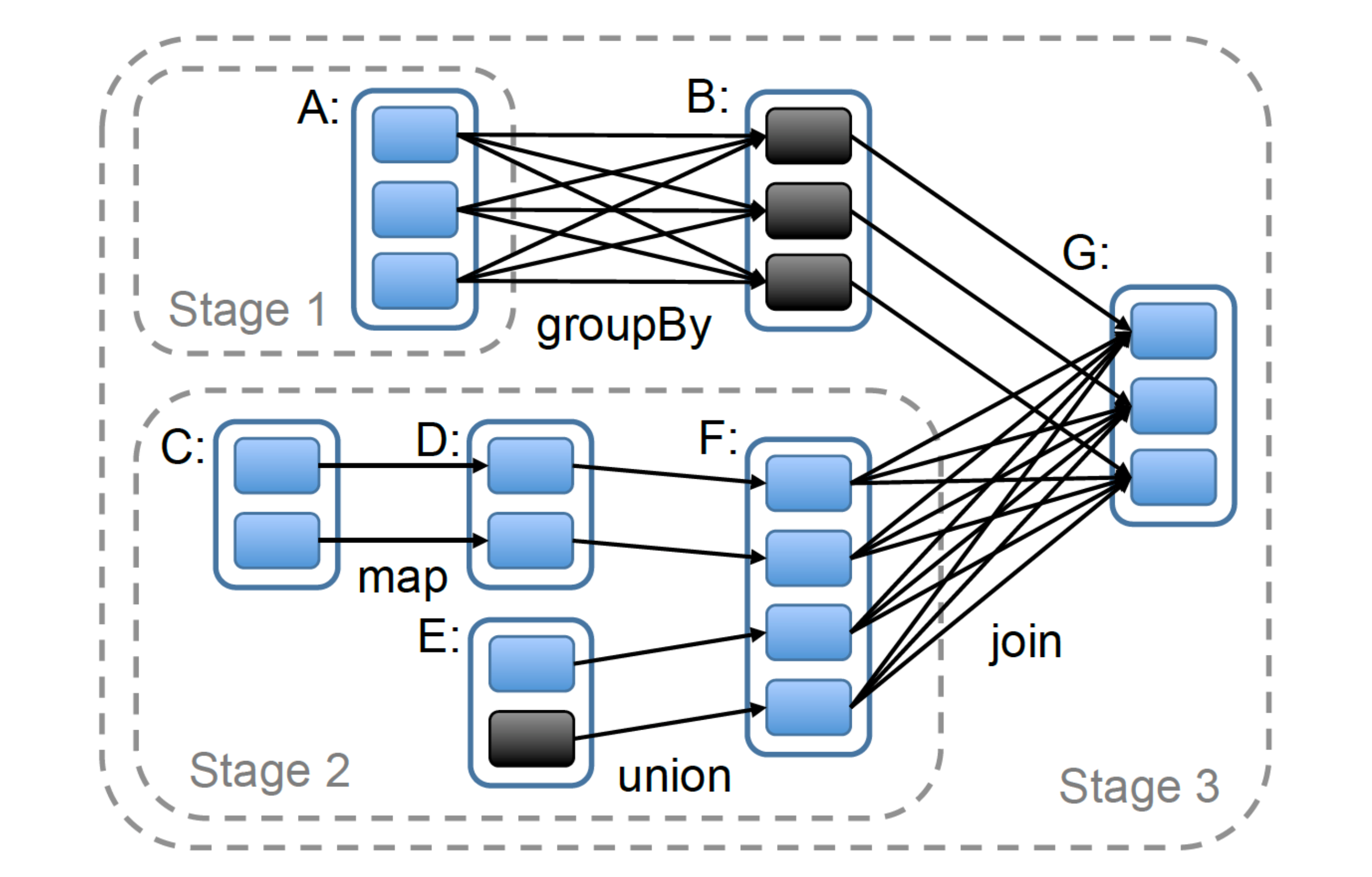 rdd-dag.png
rdd-dag.png
关系型数据库
关系型数据库是数据处理系统的集大成者。一方面,它对外提供强大的声明式查询语言——SQL,兼顾了灵活性和易用性。另一方面,他对内使用紧凑、索引友好的存储方式,可以支撑高效的数据查询需求。关系型数据库系统同时集计算和存储于一身,又会充分利用硬盘,甚至网络(分布式数据库)特点,是对计算机各种资源全方位使用的一个典范。本文不去过分展开关系型数据库实现的各个环节,而是聚焦本文重点——标准的数据集和可组合的算子。
关系型数据库对用户提供的数据基本组织单位是——关系,或者说表。在 SQL 模型中,这是一种由行列组成的、强模式的二维表。所谓强模式,可以在逻辑上理解为表格中每个单元所存储的数据必须要符合该列“表头”的类型定义。针对这种标准的二维表,用户可以施加各种关系代数算子(选择、投影、笛卡尔乘积)。
一条 SQL 语句,在进入 RDBMS 之后,经过解析、校验、优化,最后转化成算子树进行执行。对应的 RDBMS 中的逻辑单元,我们通常称之为——执行引擎,Facebook Velox 就是专门针对该生态位的一个 C++ 库。
传统的执行引擎多使用火山模型,一种属于拉( pull-based )流派的执行方式。其基本概念就是以树形的方式组织算子,并从根节点开始,自上而下的进行递归调用,算子间自下而上的以行(row)或者批(batch)的粒度返回数据。

近些年来,基于推(push-based)的流派渐渐火起来了,DuckDB、Velox 都属于此流派。类似于将递归转化为迭代,自下而上,从叶子节点进行计算,然后推给父亲节点,直到根节点。每个算子树都可以拆解为多个可以并行执行的算子流水线(下图源,Facebook Velox 文档)
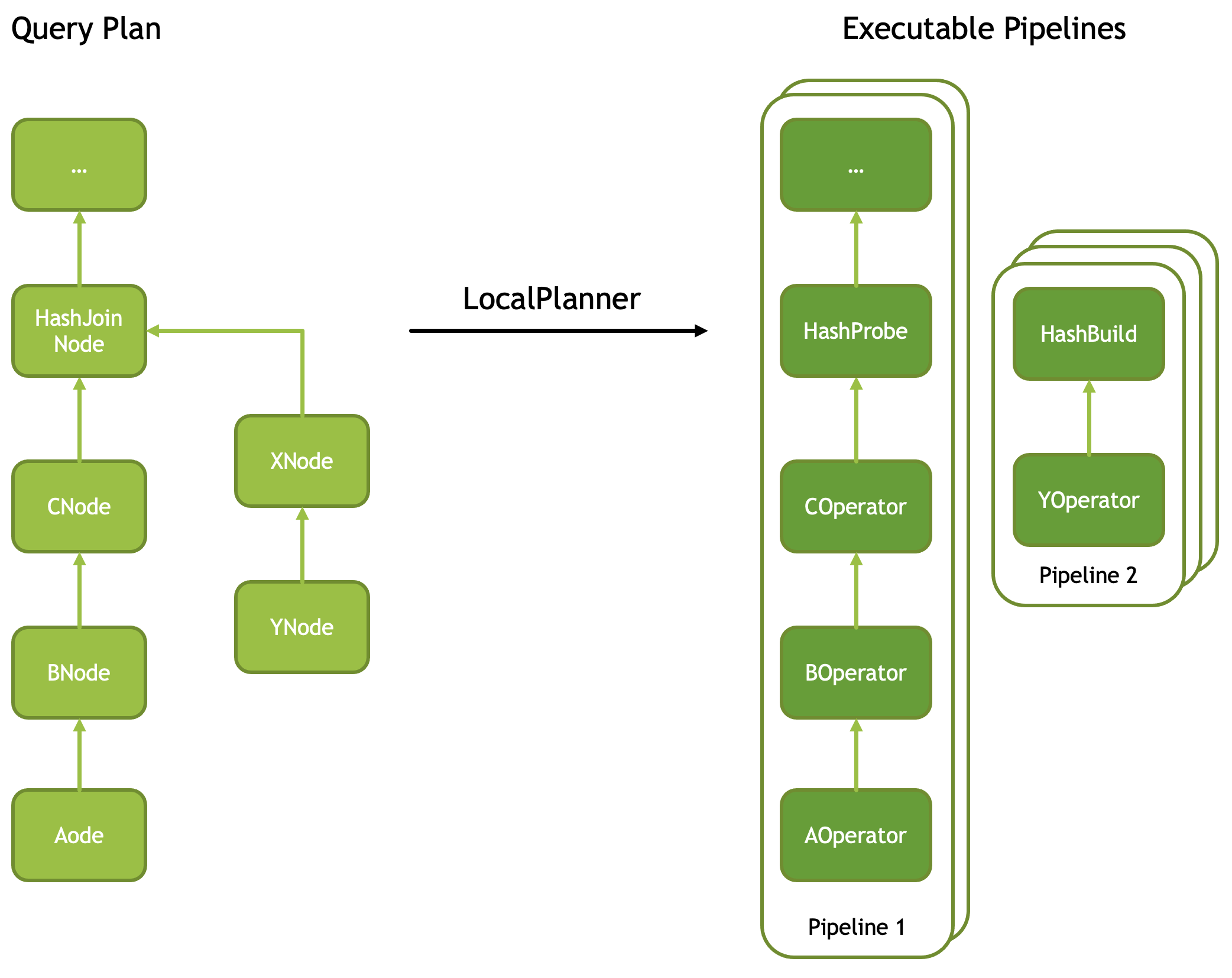 pipeline-break.png
pipeline-break.png
我们把上图顺时针旋转九十度,可以发现他和 Spark 的执行方式如出一辙,更多关于 velox 机制的解析,可以参考我写的这篇文章。
但无论推还是拉,其对数据集和算子的抽象都符合本文一开始提出的理论。
小结
考察完上述四种系统之后,可以看出,数据处理在某种角度上是大一统的——首先抽象出归一化的数据集,然后提供施加于该数据集之上的运算集,最终通过组合的形式表达用户的各种数据处理需求。
本文来自我的小报童付费专栏《系统日知录》,专注分布式系统、存储和数据库,有图数据库、代码解读、优质英文播客翻译、数据库学习、论文解读等等系列,欢迎喜欢我文章的朋友订阅👉专栏支持,你的支持对我持续创作优质文章非常重要。下面是当前文章列表:
图数据库系列
- 图数据库资料汇总
- 译: Factorization & Great Ideas from Database Theory
- Memgraph 系列(二):可串行化实现
- Memgraph 系列(一):数据多版本管理
- 【图数据库系列四】与关系模型的“缘”与“争”
- 【图数据库系列三】图的表示与存储
- 【图数据库系列二】 Cypher 初探
- 【图数据库系列一】属性图模型是啥、有啥不足 🔥
数据库
- 译:数据库五十年来研究趋势
- 译:数据库中的代码生成(Codegen in Databas…
- Facebook Velox 运行机制解析
- 分布式系统架构(二)—— Replica Placement
- 【好文荐读】DuckDB 中的流水线构建
- 译:时下大火的向量数据库,你了解多少?
- 数据处理的大一统——从 Shell 脚本到 SQL 引擎
- Firebolt:如何在十八个月内组装一个商业数据库
- 论文:NUMA-Aware Query Evaluation Framework 赏析
- 优质信息源:分布式系统、存储、数据库 🔥
- 向量数据库 Milvus 架构解析(一)
- ER 模型背后的建模哲学
- 什么是云原生数据库?
存储
- 存储引擎概述和资料汇总 🔥
- 译:RocksDB 是如何工作的
- RocksDB 优化小解(二):Prefix Seek 优化
- RocksDB 优化小解(三):Async IO
- 大规模系统中使用 RocksDB 的一些经验
代码&编程
- 影响我写代码的三个 “Code” 🔥
- Folly 异步编程之 futures
- 关于接口和实现
- C++ 私有函数的 override
- ErrorCode 还是 Exception ?
- Infra 面试之数据结构(一):阻塞队列
- 数据结构与算法(四):递归和迭代
每天学点数据库系列
- 【每天学点数据库】Lecture #06:内存管理
- 【每天学点数据库】Lecture #05:数据压缩
- 【每天学点数据库】Lecture #05:负载类型和存储模型
- 【每天学点数据库】Lecture #04:数据编码
- 【每天学点数据库】Lecture #04:日志构型存储
- 【每天学点数据库】Lecture #03:Data Layout
- 【每天学点数据库】Lecture #03: Database and OS
- 【每天学点数据库】Lecture #03:存储层次体系
- 【每天学点数据库】Lecture #01:关系代数
- 【每天学点数据库】Lecture #01:关系模型
- 【每天学点数据库】Lecture #01:数据模型
杂谈
- 数据库面试的几个常见误区 🔥
- 生活工程学(一):多轮次拆解🔥
- 系统中一些有趣的概念对
- 系统设计时的简洁和完备
- 工程经验的周期
- 关于“名字”拿来
- Cache 和 Buffer 都是缓存有什么区别?

