本文来自 Amazon S3 VP Andy Warfield 在 FAST 23 上的主旨演讲的文字稿,总结了他们在构架和维护如此量级的对象存储 —— S3 的一些经验。我们知道,Amazon S3 是云时代最重要的存储基础设施之一,现在各家云厂商的对象存储基本都兼容 S3 接口,所有云原生的基础设施,比如云原生数据库,其最终存储都要落到对象存储上。
作者:木鸟杂记 https://www.qtmuniao.com/2023/11/15/s3-experience 转载请注明出处
截至 2023 年,Amazon S3 自 2006 年上线以来,已经 17 岁了。在开始之前,我们首先看下Andy Warfield 给出的一组数据,来感受下星球最强的对象存储已经到了什么量级:
 S3-metrics.png
S3-metrics.png
即,
- 容量和吞吐:超过 280 万亿个对象,QPS 平均超过 1 亿 / s
- 事件:每天 S3 会向 serverless 应用发送超过 1250 亿个事件
- 冗余:每周超过 100 PB 的数据冗余
- 冷存储检索:每天都要至少从 S3 归档存储中回复 1 PB 数据
- 数据完整性校验:每秒进行 40 亿次完整性校验计算
对这个量级有了直观的感受之后,我们来看看 Andy Warfield 分享的经验。为了方便叙述,下面都用第一人称——我们,意指 S3 团队。
HDD 对 S3 设计的影响
虽然 SSD 在价格上已经越来越便宜,但对于 S3 如此量级的存储来说,仍然大量采用 HDD。其中一个重要原因仍然是成本优势(存储密度和寿命都很棒)。相对其最初诞生时期,HDD 体积缩小了 5k+ 倍、单字节成本更是便宜了 60亿倍!然而,受制于机械特性,其随机访问延迟只降低了 150+ 倍左右。
S3 刚上线时,HDD 的满载 IOPS 大概是 120,这个数值在这么多年间基本没有变过。HDD 这种存储密度越来越高,但访问延迟却一直停滞的特点,给 S3 的设计带来了很大影响—— 必须想方设法将流量均摊到不同硬盘上去,避免单块盘的 IO 过载。
热度管控:数据放置和性能
基于上述原因,S3 在不断 scale 的同时,所面临的最主要和有意思的问题之一就是:如何在如此多的 HDD 上管理和均衡 IO 流量。我们称该问题为——热度管控(heat management)。
所谓热度(heat):就是任意时间点,某个磁盘承受的 IO 请求。如果管控不当,造成不同磁盘间流量的严重倾斜,就会造成数据局部访问热点(hotspot),从而造成长尾效应(“stragglers”)。这些长尾请求通过 S3 的存储软件栈(software storage stack)层层放大之后,可能大范围影响请求性能。为了解决这个问题,我们需要仔细考虑数据放置策略(data placement)。
通常来说,由于无法在数据写入时(即进行放置决策时)预知其之后的访问模式,我们很难用一个策略消除所有用户的访问热点。但由于 S3 的量级以及多租户机制,我们可以进行完全不同的设计。
我们发现一个特点:在 S3 上运行的工作负载越多,不同对象请求间的去相关性(decorrelated)就越强。对于用户的单个存储单元来说(比如一组 Object,或者一个 Bucket),其通常的访问模式是:长时间沉寂后,突然一个远高于平均值访问高峰。但是当我们聚合了百万计的请求之后,非常有趣的事情发生了:聚合请求总量的变化曲线变的非常平缓,且出现了某种内在可预测的规律。可以看这个视频直观感受下。
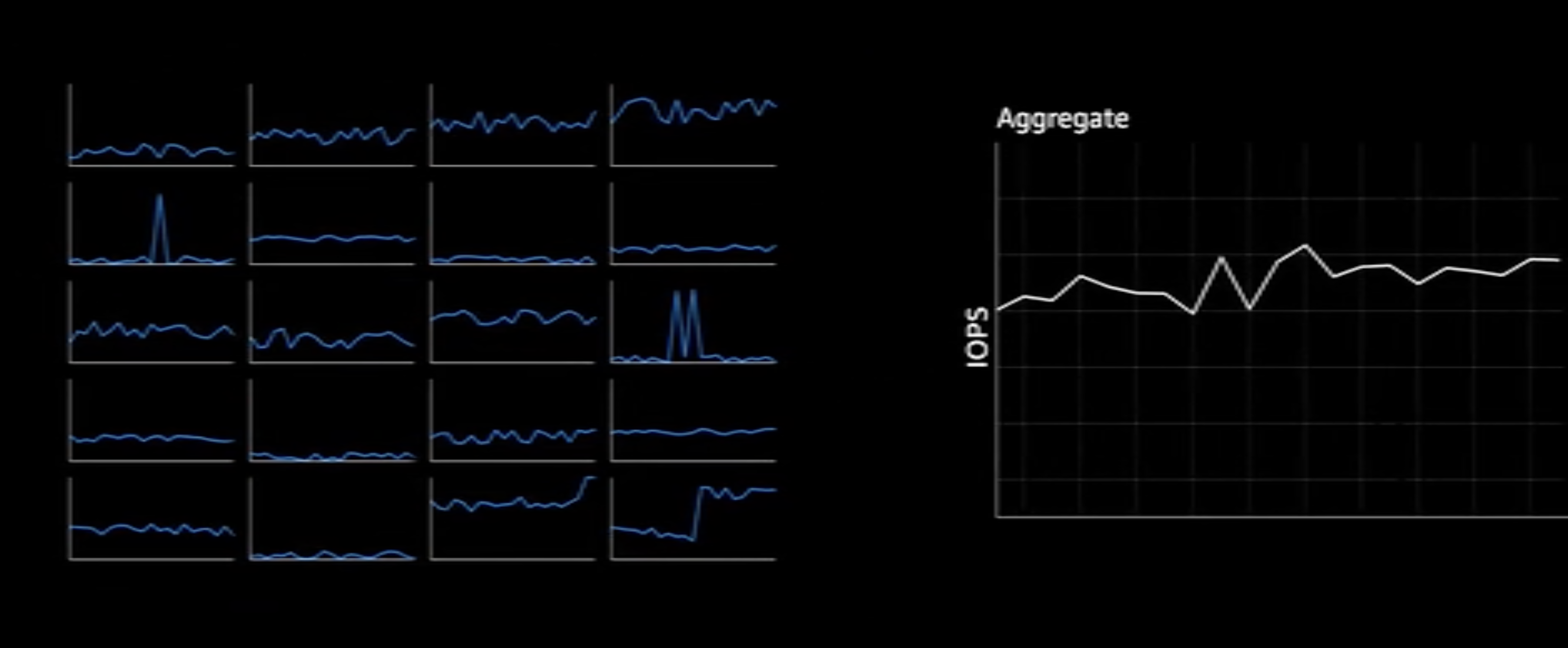 S3-aggreate.png
S3-aggreate.png
这其实也符合直觉,在成千上万的不相干访问流汇聚成海后,单个流的突发很难影响整体趋势。因此我们的问题就变成了:如何将这种聚合后总体上相对平坦的请求速率均摊到所有磁盘上,变成每个磁盘上相对平滑的 IO 访问速率。
数据复制:数据放置和持久性
在存储系统里,总是会用数据冗余来保护数据免于硬件故障。但冗余,同样可以用来管控热度。在多机上有多个副本,给了我们在流量过来时选择机器的自由度。从存储容量(capacity)的视角来看,数据冗余推高了成本;但从 IO (至少是读取)的角度来看,数据冗余提升了性能。
除了多副本冗余外,S3 自然也是用了 EC (erasure coding)方式来降低冗余。其具体原理我们在 Facebook F4 中介绍过,这里不再赘述。
数据尺度对放置策略的影响
除了使用数据冗余来均摊流量外,我们下一步可做的是:将新写入的对象数据尽可能大范围地摊到硬盘池中。将同一个桶的对象摊到不同的硬盘后,同一个用户的访问流量便也随之打到了不同硬盘集合。这样做有两个好处:
- 负载隔离:如果每个用户的数据在单块磁盘上都只会占一小块地方,因此很难靠单个用户的访问来“掀起波浪”,造成该盘的访问热点。
- 热点摊平:对于任意的突发流量,我们可以利用超常规尺度的磁盘池来将其摊平。这对于小存储集群来说是非常昂贵且难以想象的。
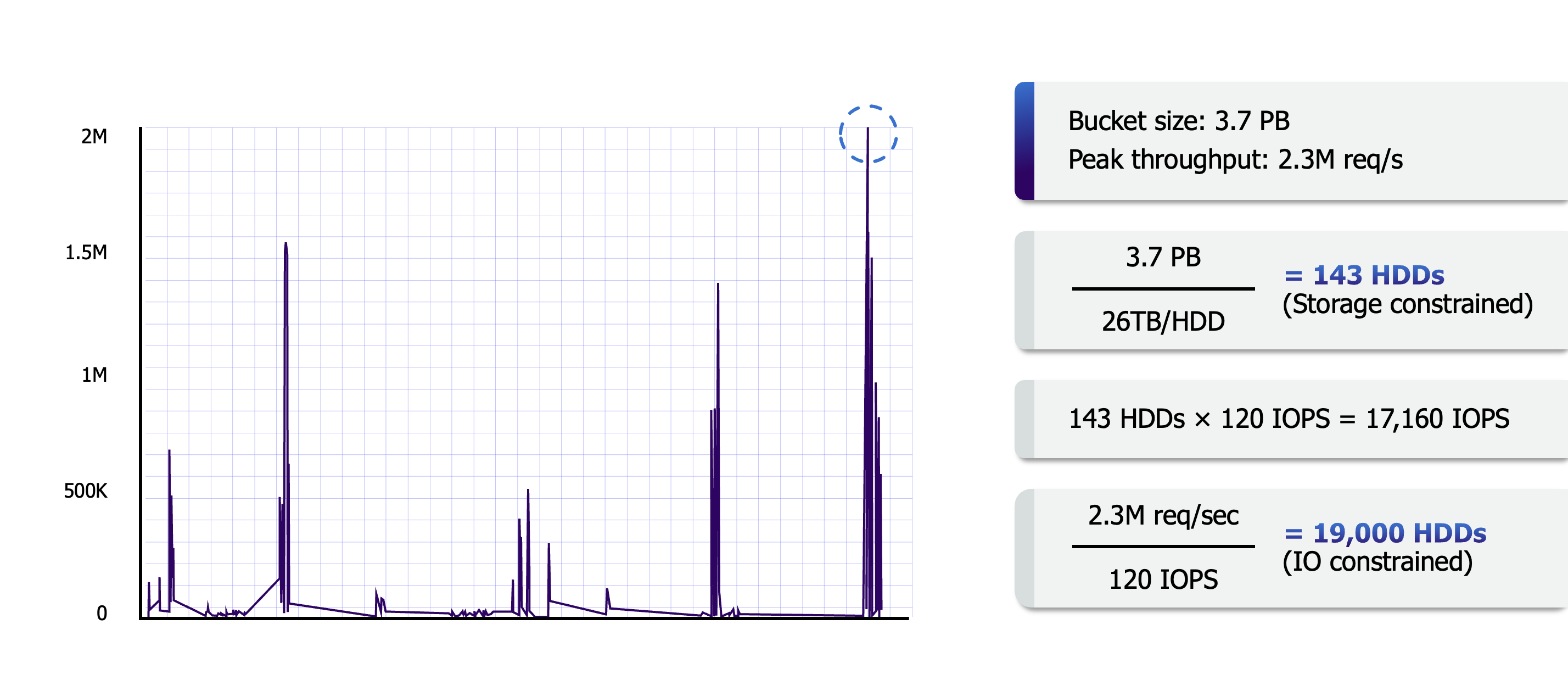 S3-flow-avg.png
S3-flow-avg.png
如上图,可能是基因研究用户在使用 lambda 函数计算进行大规模的并行数据分析,IOPS 一度达到 2.3M IOPS,但我们使用数百万张磁盘可以轻松满足这种需求(上面计算可以看出 2w 张盘满载可以满足,那么有百万张盘,每个只用百分之一就可以满足)。
这种尺度的请求处理在 S3 中并不算夸张,当下 S3 集群至少有上万用户的存储桶的数据横跨超过百万张盘。正是 S3 如此体量的用户和用户数据,让这种构建方式成为可能。
人的因素对 S3 的影响
本文来自我的专栏《系统日知录 2023》,还有一部分在专栏文章中。你的订阅是我持续创作优质文章的最大动力,目前专栏有 82 篇文章,涵盖数据库、存储、系统等主题,如果你对大规模数据系统内容感兴趣,目前处于完结前的打折期,不容错过。

