Introduction
In 2018, I worked on some 6.824 labs; my old notes are here. Unfortunately, I got stuck at Part 2C and could never pass the tests, so I put it aside. But in the days that followed, I often thought about this legendary course with a tinge of sadness. Putting it off until today, I can finally come back to fulfill that wish.
This time, there were three reasons I could pass all the tests: first, having done it once before, many of the principles were still fresh in my mind; second, over the past year or so I had gained a lot of hands-on experience with distributed systems at work; and third, my Go skills had improved somewhat. But during the process, I still encountered a great many vexing details. To make it easier to review them later, I’ve organized these details and recorded them here. If they happen to be of the slightest help to others working on this course, that would be another happy occasion.
6.824 and Raft
6.824 is an excellent open course on distributed systems. While doing the labs, I was constantly amazed by its exquisite design and the thoroughness of its materials. That the masters at MIT would share such an essential course with the world truly reflects the character of a great university and its scholars, and is a great fortune for us computer scientists.
Raft is a consensus protocol designed for understandability. Distributed consensus is a very, very classic problem in the distributed field, and also one of the hardest parts of distributed systems. Intuitively speaking, it’s like laying the foundation for a skyscraper on quicksand. Unreliable networks and failure-prone hosts create state changes so complex that they are truly beyond the ability of ordinary people to simulate in their heads. I am rather dull, and can only achieve some understanding through intuitive grasp plus accumulation of details. Returning to Raft, with Paxos as a predecessor in the same field, how did Raft still manage to stand out? I think it comes down to two key points:
- Easy to understand. Paxos is notoriously difficult to understand, and therefore hard to bring into common use. Raft reduces the dimensionality of algorithmic complexity by decoupling it into multiple modules, greatly lowering the difficulty of understanding for ordinary people. In addition, Raft has many elegant designs that avoid introducing complexity as much as possible, further reducing the mental burden.
- Easy to implement. Being easy to understand objectively leads to ease of implementation, but that doesn’t automatically mean you can produce an excellent system from it. If understanding remains at the intuitive level, implementation becomes a castle in the air. The brilliance of the Raft paper is that it has both an intuitive grasp and a detailed organization—it is almost a system design document, and a detailed one at that.
To do well on this lab, you need to consult a large amount of material. I’ve summarized what the lab mentioned and what I found at the end of this article. Of course, there is also the English barrier. Although I eventually passed all the test cases, there are still many points I didn’t implement well and many things I don’t fully understand.
Note: Later, in 2023, I did it again, and finally figured out most of the points.
Author: 木鸟杂记 https://www.qtmuniao.com, please indicate the source when reposting
Overall Structure
This lab (2020 version) is divided into three parts: Part 2A: leader election, Part 2B: log replication, and lab2C: state persistence.
I didn’t use too many channels in my implementation; state changes were all done through blocking locks. I noticed that some implementations online control all state changes with channels, which might be more efficient asynchronously but slightly less readable. My implementation basically follows the paper’s description. In terms of code organization, it can be summarized as three states and three loops.
Three States
Follower, Candidate, and Leader. Accordingly, I defined three functions: becomeFollower, becomeCandidate, and becomeLeader, which encapsulate some of the internal state transitions of a Raft peer.
1 | func (rf *Raft) becomeCandidate() { |
Three Loops
Three goroutines: electionLoop, pingLoop, and applyLoop. The first two loops are both driven by timers. electionLoop only executes election logic when the peer is not the Leader, while pingLoop is started each time a peer is elected Leader and exits promptly when it loses its Leader status. That is, for the same peer, these two loops are mutually exclusive.
electionLoop is the loop where a Follower becomes a Candidate after a timeout and initiates an election. It is a background resident goroutine, but skips the loop body when it detects that it is the Leader (skips the election), since no one would voluntarily initiate an election to overthrow themselves.
1 | func (rf *Raft) electionLoop() { |
pingLoop is the loop where a Candidate, after being elected Leader, sends heartbeats and completes log synchronization in the process. This loop is started as a goroutine in the becomeLeader function; once it detects that it is no longer the Leader, it exits immediately, since all peers are highly self-aware—if everyone were dishonest, consensus would never be reached.
1 | func (rf *Raft) pingLoop() { |
applyLoop is the simplest: it continuously applies committed logs to the state machine, also a background resident goroutine. The elegance of this design lies in decoupling. That is, instead of applying immediately after each commit, a separate goroutine performs the application uniformly, to avoid committing the same index multiple times (since a commit can happen once a majority of peers respond, and subsequent responses from other peers may cause multiple commits), which would in turn lead to multiple applies.
1 | func (rf *Raft) applyLoop() { |
Locking Principles
I followed the rather coarse-grained approach recommended in the lab materials, mostly at the function level. I only release the lock before long-running operations (network I/O): that is, before each RPC (sendRequestVote and sendAppendEntries). Therefore, the efficiency won’t be very high, but it is easy to implement and understand. At the same time, to ensure that each send process is atomic (not interrupted), I used a channel for synchronization to guarantee that before sending an RPC to the next peer, the previous RPC has finished preparing its Args; of course, you could also move the process of preparing Args outside the goroutine.
1 | func (rf *Raft) pingLoop() { |
Logging
I implemented the String() function for the main structs to conveniently return the current peer’s key states, as well as the parameters and return values before and after RPCs, making it easy to trace and debug. Taking the Raft struct as an example:
1 | func (rf *Raft) String() string { |
Leader Election (Part 2A: leader election)
Any peer (or server) in Raft is in one of three states: Follower, Candidate, or Leader. The state transition diagram is as follows:
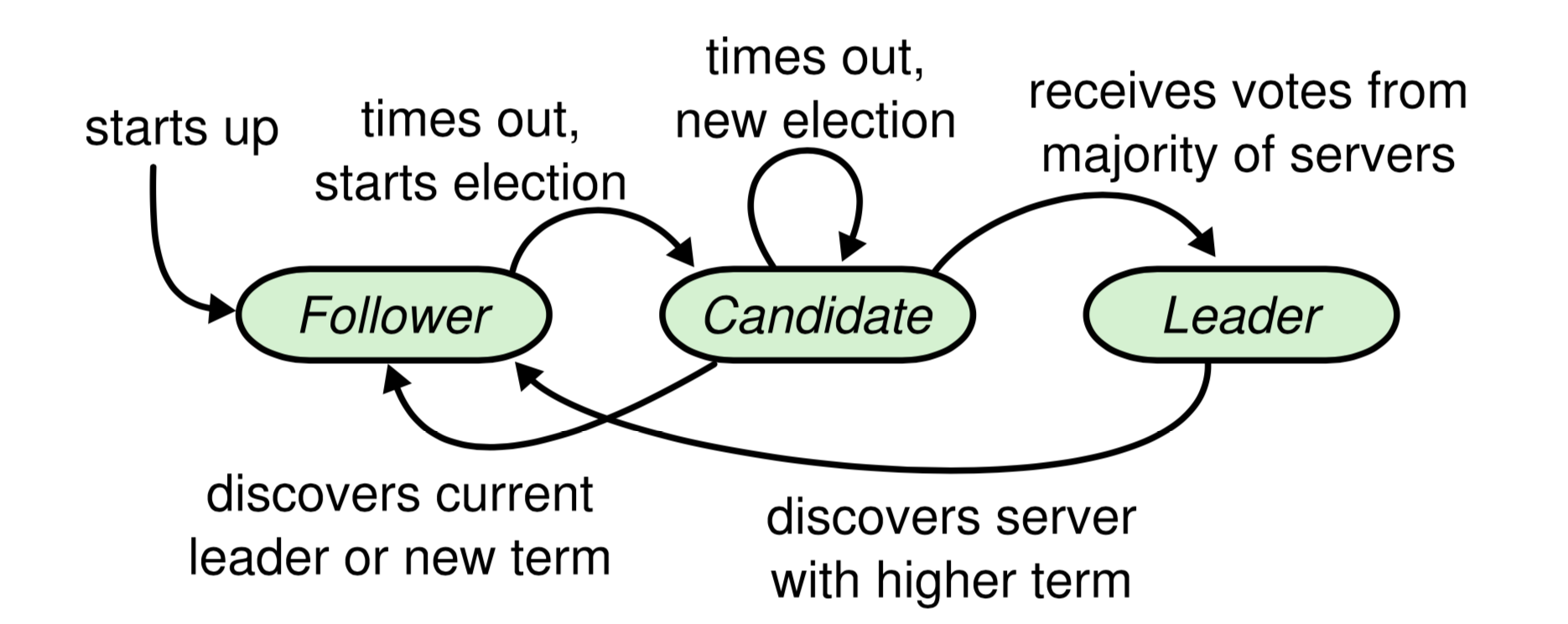 raft-server-state.png
raft-server-state.png
All peers start as Followers. After a random timeout, they successively become Candidates. Candidate is an intermediate transitional state designed for campaigning to become Leader. All terms begin with a Candidate (i.e., term+1 when becoming a Candidate); if elected, the term lasts until the Leader’s term ends.
There is an ironclad rule in Raft: regardless of its current state, whenever a peer discovers that its term lags behind another’s, it immediately updates its term and becomes a Follower. The term is the de facto logical clock; all voting actions (Candidate and Voter[1]) and log synchronization actions (Leader and Follower) require both parties involved to be in the same term.
Raft uses a strong Leader: only the Leader can synchronize logs to Followers, not the reverse. Moreover, the Leader’s own log can only be appended by the Client and cannot be altered or deleted. Since the Leader holds great power, the election must have stringent requirements to guarantee that the elected Candidate’s log is more up-to-date than that of a majority of peers. Therefore, during the election phase, the Candidate’s log must be compared one by one with that of every other peer. According to the description in the paper:
Raft determines which of two logs is more up-to-date by comparing the index and term of the last entries in the logs. If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date.
We only need to consider the index and term of the last log entry of the two logs:
1 | func notLessUpToDate(currTerm, currIndex int, dstTerm, dstIndex int) bool { |
The detailed description of the implementation can be found in Figure 2 of the paper. This description should be treated as a programming language rather than natural language, because it is extremely precise. Pay special attention to not omitting the trigger conditions for state transitions. I won’t repeat it here, but will only list some points that I found potentially confusing during implementation:
-
All fields in the
RequestVoteArgsstruct must be capitalized, as required by the test program. -
The request and reply structs for
AppendEntries, as well as the implementation for sending RPCs, need to be modeled afterRequestVote. -
logEntryalso needs to be defined by yourself; my implementation only contains two fields: Term and Command. -
A peer can vote at most once per term. This can be guaranteed by checking whether
rf.votedForis null [5] before casting a vote. But it also means that a peer must be able to vote at least once per term, which requires timely updatingvotedForwhen the term changes. There are two cases: first, when a Follower/Candidate times out and becomes a Candidate, the term increases by 1; at this point, vote for yourself first (rf.votedFor = rf.me), then initiate the election. Second, when receiving an RPC from another peer (including Request and Reply), if you find that the other peer’s term is higher and you become a Follower, you also need to promptly clear your previous vote (rf.votedFor = -1) so that you can continue to vote in this new term. However, when a Candidate in the same term falls back to a Follower, remember not to resetrf.votedFor. -
When implementing AppendEntries, a peer should promptly become a Follower as long as its own term is not higher than that of the Leader initiating the heartbeat. This includes the following situations: a. If the peer’s term is smaller, it needs to catch up its term and then become a Follower; b. If it was originally a Candidate with the same term, it should stop the election and become a Follower; c. If it was already a Follower with the same term, just reset the electionTimer.
1
2
3
4
5
6if args.Term < rf.currentTerm {
DPrintf("%v reject append entry rpc from %v for (term)", rf, args)
return
}
rf.becomeFollower(args.Term) // become follower with term args.Term and reset timer -
Regarding the reset of
electionTimer: each time a peer becomes a Follower, the timer can be reset. In addition, for Followers/Candidates, there are two other situations that require a reset: one is when receiving an AppendEntries RPC; the other is when granting a vote to a Candidate. This inference comes from this sentence under Followers in Figure 2:If election timeout elapses without receiving AppendEntries RPC from current leader or granting vote to candidate: convert to candidate
-
Every time an RPC reply is received, (Candidate and Leader) must check whether the current state is consistent with that before sending the RPC. If it is inconsistent, the goroutine should exit promptly: “Not in that position, don’t do that work.” The combination of term + role can uniquely determine a peer’s state.
1
2
3
4
5
6
7
8
9// in pingLoop()
if rf.role != LEADER || rf.currentTerm != args.Term {
return
}
// in electionLoop()
if rf.role != CANDIDATE || rf.currentTerm != args.Term {
return
}
While working on it, I also thought of an extreme scenario and worked through it. Suppose a certain Peer A becomes network-partitioned from the other peers, and thus keeps timing out, electing, timing out, electing, thereby continuously updating its term to a very large value T. At some point, A restores communication with the other peers and initiates an election, asking every peer for a vote. Then all the remaining peers, including the Leader, discover the larger term T and immediately become Followers. However, thanks to the up-to-date guarantee, A still cannot become Leader. So the only consequence of this scenario is that A abruptly drags everyone into a higher term, and helps someone else (possibly electing a peer other than A or the original Leader). Of course, in practice, prevVote is usually used to prevent a Leader from being constantly interrupted by a peer that has been partitioned for a long time.
Log Replication (Part 2B: log replication)
From the time the Leader receives a client request to the time it applies the contained command to the state machine, the process roughly consists of the following steps:
- Receive the client request, which contains a command parameter (
Start(command interface{})). - The Leader appends this request to its local log (
rf.log = append(rf.log, &logEntry{rf.currentTerm, command})). - Notify all Followers in parallel to write this log via heartbeat (AppendEntries RPC).
- After a majority of Followers have successfully written it, commit the log.
- Broadcast the LeaderCommit to all Followers via the next heartbeat.
- Each Follower applies it independently.
Heartbeats are periodic, and log synchronization is accomplished during these periodic heartbeats. If the RPC parameters do not carry log entries, it is a simple heartbeat; if the RPC parameters do carry log entries, it means the Leader is telling that Follower that it thinks these logs need to be synchronized.
So how does the Leader know which logs each Follower needs to synchronize?
Trial and error.
By probing for a match point, the Leader’s logs after the match point are the part that needs to be synchronized to the Follower. Probing for a match point means that the Leader will start from its own log entries and ask backwards, one by one: do you have this log entry? As soon as it finds a log entry that the Follower has stored, that is a match point, and the logs before it must be the same [2]. To implement this logic, the Raft paper mainly uses these variables: matchIndex[], nextIndex[], prevLogIndex, and prevLogTerm.
matchIndex and nextIndex
These two arrays are only useful for the Leader. matchIndex[] tracks the log entries that the Leader has matched with each Follower, and nextIndex[] stores the next log entry to send to each Follower.
When a Candidate is elected Leader, it initializes all matchIndex to 0 [3], indicating that it currently doesn’t know the progress of each peer; at the same time, it initializes all nextIndex to len(rf.log), indicating that probing will start from before it, i.e., from the last log entry.
1 | func (rf *Raft) becomeLeader() { |
There is an implicit situation here: during the first probe, args.Entries is empty, corresponding to the initial empty heartbeat mentioned in Figure 2 of the paper:
Upon election: send initial empty AppendEntries RPCs (heartbeat) to each server; repeat during idle periods to prevent election timeouts (§5.2)
Later, as the probing continues backwards, more and more log entries will be carried in the heartbeats, which may cause performance issues in actual engineering.
prevLogIndex and prevLogTerm
Each heartbeat carries probing information: prevLogIndex and prevLogTerm. When a Follower receives this RPC, it checks whether it has this log entry. If not, then its prevLogIndex and subsequent logs must not match and can be deleted. If it does, then the log entries carried in the RPC parameters are useful: append them after the match point, and update the commit information according to the Leader’s request.
1 | if args.PrevLogIndex >= len(rf.log) || rf.log[args.PrevLogIndex].Term != args.PrevLogTerm { |
Leader Handling Replies
When the Leader receives a reply from a Follower, if it finds a match, it updates matchIndex and nextIndex; otherwise, it continues to probe the previous entry. Of course, to speed up matching, we adopt a large-step forward strategy, skipping an entire term rather than a single index each time [4]. Without this optimization, one test won’t pass.
Of course, even this might not be enough; you may also need to add some fields to the Follower’s reply to hint the Leader to jump forward quickly.
1 | if reply.Success { |
Some Points
As usual, here are some issues or bugs I encountered during implementation:
-
How to determine which logs can be committed, i.e., how to get the match point of a majority of peers from the matchIndex array (
getMajoritySameIndex)? My implementation is rather crude: make a copy, sort it in descending order, and take the value atlen/2.1
2
3
4
5
6
7
8
9func getMajoritySameIndex(matchIndex []int) int {
tmp := make([]int, len(matchIndex))
copy(tmp, matchIndex)
sort.Sort(sort.Reverse(sort.IntSlice(tmp)))
idx := len(tmp) / 2
return tmp[idx]
} -
Don’t forget to assign the
applyChparameter passed to theMakefunction torf.applyCh. -
When a Leader/Candidate/Follower receives a RequestVote RPC with a larger term, it needs to immediately convert to a Follower and reset the electionTimer.
-
When a Leader receives an AppendEntries reply, it needs to check the term first, and then check whether its state has changed. That is, the order of the following two if statements cannot be swapped. Otherwise, for some reason, this peer’s state might have changed (i.e., it is no longer the Leader or its term has changed), and it would return directly. But it is possible that its term after the change is still smaller than reply.Term, thus failing to promptly become a Follower.
1
2
3
4
5
6
7
8if reply.Term > rf.currentTerm {
rf.becomeFollower(reply.Term)
}
if rf.role != LEADER || rf.currentTerm != args.Term {
DPrintf("%v is not leader or changes from previous term: %v", rf, args.Term)
return
} -
Does a Leader need to roll back its
commitIndexafter losing leadership? And does a Candidate need to setcommitIndex = 0when it becomes Leader? The answer to both is no, because according to the Leader Completeness property in the paper, all committed logs will definitely appear in the logs of subsequent Leaders. -
When updating
rf.matchIndexandrf.nextIndexupon receiving an AppendEntries reply, be careful not to rely onlen(rf.log), because it may have been changed, for example, by a new log entry appended due to a client request. It is better to use the values from the fields in the parameters at the time the RPC request was sent:args.PrevIndex + len(arg.Entnries), as noted in the code above. -
I couldn’t pass the TestRPCBytes2B test case at first. Later, I found out that my heartbeat interval was too small; it turned out to be a unit mistake, writing microseconds instead of milliseconds. This caused too many AppendEntries packets to be sent to the same Follower (the test program can tolerate slightly sending one or two extra packets).
-
For the random seed,
rand.Seed(time.Now().UnixNano())is better. -
When sending AppendEntries RPC, when peerID is the Leader itself, remember to update nextIndex and matchIndex as well:
1
2
3
4
5if peerID == rf.me {
rf.nextIndex[peerID] = len(rf.log)
rf.matchIndex[peerID] = len(rf.log) - 1
continue
}
State Persistence (Part 2C: state persist)
In terms of implementation alone, 2C is relatively simple: just implement the serialization (rf.persist()) and deserialization (rf.readPersist()) functions to save or load the states that need to be persisted. And call rf.persist() promptly whenever these states change.
But it is easy to fail the tests. When I did it two years ago, I was stuck here for a long time. Because the test cases in this part are more complex, they can easily expose points that were not well implemented in the first two parts.
Serialization and Deserialization
The states that need to be persisted are clearly stated in Figure 2 of the paper. The usage of labgob is also very detailed in the comments. The main thing to note is that the rf.log slice doesn’t need special treatment; just handle it like an ordinary variable. Taking serialization as an example:
1 | func (rf *Raft) persist() { |
State Changes
There are four main places in the code where state changes occur:
- When initiating an election and updating term and votedFor.
- When calling Start to append a log and
rf.logchanges. - When the RequestVote and AppendEntries RPC handlers change related states.
- When a Candidate/Leader updates its own state upon receiving an RPC reply.
But the test case TestFigure8Unreliable2C just wouldn’t pass. After some Googling, I found that others had this problem too. Making the pingInterval smaller and widening the gap between it and electionTimeout solved it. In the end, I changed the parameters to the following values, and the test case passed.
1 | const ( |
But I initially set the heartbeat interval relatively large because I saw this sentence in the materials:
The paper’s Section 5.2 mentions election timeouts in the range of 150 to 300 milliseconds. Such a range only makes sense if the leader sends heartbeats considerably more often than once per 150 milliseconds. Because the tester limits you to 10 heartbeats per second, you will have to use an election timeout larger than the paper’s 150 to 300 milliseconds, but not too large, because then you may fail to elect a leader within five seconds.
But when I changed it to heartbeatInterval = 50 * time.Millisecond, the tester also let it pass. I’m still somewhat puzzled by this.
References
-
Raft paper: https://pdos.csail.mit.edu/6.824/papers/raft-extended.pdf
-
Lab2 Raft course materials page: https://pdos.csail.mit.edu/6.824/labs/lab-raft.html
-
TA’s summary of past experiences: https://thesquareplanet.com/blog/students-guide-to-raft/. By the way, this TA’s blog is also quite good.
-
TA Q&A: https://thesquareplanet.com/blog/raft-qa/
-
Raft locking advice: https://pdos.csail.mit.edu/6.824/labs/raft-locking.txt
-
Raft implementation structure advice: https://pdos.csail.mit.edu/6.824/labs/raft-structure.txt
-
Raft homepage, which has a visualization animation that can help you intuitively feel how Raft works, and it has some interactivity. There are also more Raft-related materials you can refer to: https://raft.github.io/
-
An online classmate’s implementation: https://wiesen.github.io/post/mit-6.824-lab2-raft-consensus-algorithm-implementation/
Notes
[0] Each server in Raft is uniformly referred to as a Peer in this article.
[1] A voter may be a Follower or a Candidate.
[2] Refer to the Log Matching property in Figure 3 of the paper.
[3] 0 actually represents nil, because rf.log[0] is a meaningless empty log entry that serves as a sentinel, reducing some checks, similar to a dummy head node in a linked list.
[4] The Raft paper mentions this strategy in the footnote on pages 7–8.
[5] In my implementation, votedFor is of type int, and I use -1 to represent null.

