This article originated from Lu Pan’s personal blog post: https://blog.the-pans.com/cap/, a Chinese translation of Martin Kleppmann’s article “Please stop calling databases CP or AP” authorized by Martin himself. However, many sentences in that translation read rather oddly. I compared it with the English original, and re-translated it sentence by sentence according to my own understanding. This article discusses why we should not abuse the concept of the CAP theorem; it is well-documented and penetrating, well worth reading. Even more commendable is that Martin cites sources for all key viewpoints in the text, and recommends some learning materials at the end—all excellent reading. Below is the main text.
In Jeff Hodges’s excellent blog post Notes on Distributed Systems for Young Bloods, he suggests we use the CAP theorem to evaluate systems. Many people have followed this advice, calling their systems “CP” (providing consistency but unavailable during network partitions), “AP” (highly available but inconsistent during network partitions), or simply “CA” (indicating they haven’t read Coda’s article from five years ago).
I agree with all of Jeff’s other points, but I cannot endorse his advice on using the CAP theorem. The CAP theorem itself is too simplistic and widely misunderstood to serve effectively when characterizing systems. Therefore, I ask that everyone stop citing the CAP theorem, stop discussing the CAP theorem. Instead, we should use more precise terms to express our trade-offs in system design.
(Of course, it’s ironic that while I don’t want others to discuss this topic anymore, I am myself writing an article about it. But at least from now on, when someone asks me why I don’t like discussing the CAP theorem, I can send them the link to this article. Also, sorry if this article comes across as a bit of a rant, but at least these rants come with citations.)
Author: Muniao’s Notes, please credit when reposting.
CAP Uses Very Narrow Definitions
If you want to cite CAP as a theorem (rather than as a vague marketing gimmick for databases), you must be precise—mathematics demands rigor. The proof only makes sense when you use the same terms as in the theorem proof. That proof uses very specific definitions:
- Consistency in CAP means linearizability. This is a very specific (and very strong) form of consistency. It should be noted that although the C in ACID also stands for Consistency, it has nothing to do with the consistency here. I will explain what linearizability means later.
- Availability in CAP is defined as “all working [database] nodes must return a [non-error] response for every request received.” Having only some nodes able to handle requests is not enough: all working nodes must correctly handle requests. Therefore, many systems claiming to be “highly available” (e.g., the system rarely goes down overall) do not actually meet the definition of availability used here.
- Partition Tolerance (a very misleading name) essentially means you are communicating over an asynchronous network in which messages may be delayed or simply lost. The Internet and data centers both have this property, so we have no choice in this matter.
Also note that CAP does not just describe old systems; it is a specific model of a system:
- Simply put, the CAP system model is a single register that supports reads and writes. CAP says nothing about transactions across multiple objects—these issues are outside the scope of the theorem unless you can reduce them to a single-register problem.
- The CAP theorem only considers one type of failure: network partitions (e.g., the nodes are still running, but the network between them has problems). This kind of failure will certainly happen, but it is far from the only kind of failure that can occur: nodes can crash entirely or restart, may run out of disk space, may encounter software bugs, etc. When building distributed systems, you need to consider much more complex trade-offs; focusing too much on the CAP theorem can easily lead to neglecting other important issues.
- Furthermore, CAP does not mention latency. People actually care more about latency than availability. In fact, a system that satisfies CAP availability**[1]** can take arbitrarily long to respond to a request and still be considered “available.” It is safe to say that if your system takes two minutes to load a page, your users will certainly not call it “available.”
If you use properties that match the precise definitions in the CAP theorem proof, then the theorem applies to you. But if your “consistency” and “availability” mean something else, you cannot expect CAP to still apply. Of course, this doesn’t mean you can accomplish the impossible by redefining concepts! I just mean that you cannot rely on the CAP theorem to provide guidance, nor can you use the CAP theorem to justify your arguments.
If the CAP theorem does not apply to you, that means you must think through the trade-offs yourself. You can use your own concepts to explain consistency and availability in your system, and of course, it would be even better if you could further provide a theorem proof. But please don’t call it the CAP theorem, because that name is already taken (it has its specific meaning and referent).
Linearizability
In case you are not familiar with the property of linearizability**[2]** (i.e., consistency in CAP), let me briefly explain. The formal definition of linearizability is not very intuitive, but its key idea is quite simple:
If operation B begins after operation A has successfully completed, then for operation B, the entire system must appear to be in a state where operation A has already completed or updated.
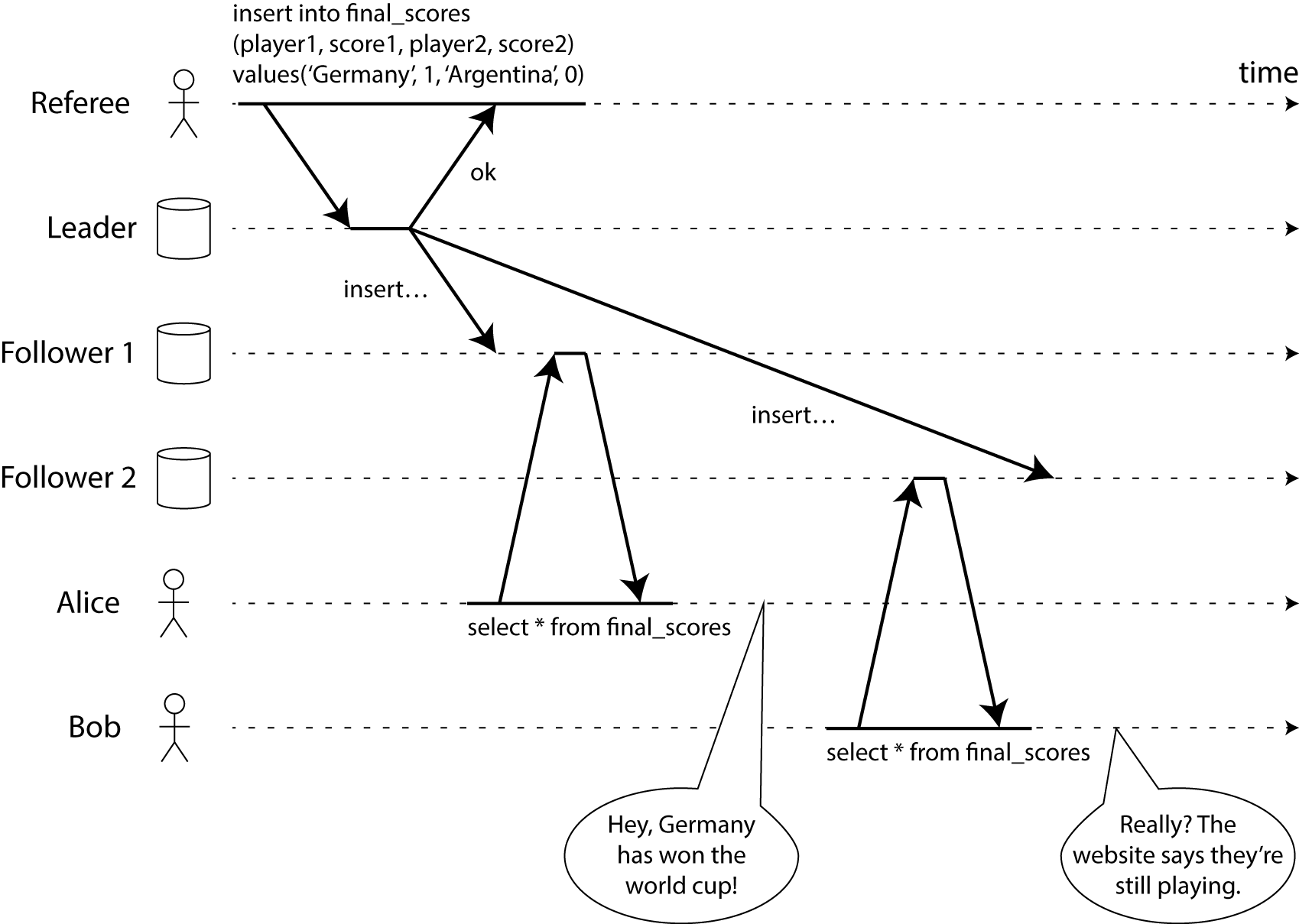
To explain more clearly, let’s look at an example of a non-linearizable system. Please see the figure below (a preview from my not-yet-published book):
 img
img
This figure shows Alice and Bob in the same room, both following the 2014 World Cup final result on their phones. Just as the final result was published, Alice refreshed the page and saw the champion, then excitedly told Bob. Bob, in disbelief, refreshed his phone page, but because his request was routed to a slower database replica, his phone showed that the final was still ongoing.
If Alice and Bob refreshed the page at the same time and got different results, it wouldn’t be too surprising, because we cannot know for sure which request the server processed first. But in this example, Bob clearly knows that he refreshed the page after Alice told him the final result, so he expects that the result he gets cannot be older than Alice’s. But he did get an old result, which violates the property of linearizability.
Because Bob obtained Alice’s query result through a channel outside the system (Alice told him directly by speaking), we can determine that Bob’s request definitely came after Alice’s request (i.e., the two requests were not concurrent). If Bob had not learned from Alice that the match was over, he would not have known that the result he saw was outdated.
If you are building a database system and don’t know what additional communication channels your users might have, then if you want to provide linearizable semantics (CAP consistency), you need to make the database appear as if there is only one copy, even though the system may actually have multiple backups in multiple locations.
This is a very expensive property because it requires a great deal of coordination. The cost is so high that even CPUs on a single machine do not provide linearizable access to local memory! On modern CPUs, you need to use memory barrier instructions to achieve linearizable memory access, and even detecting whether a system is linearizable is itself quite difficult.
CAP Availability
Let’s briefly discuss why, in the presence of a network partition, we must give up either availability or consistency.
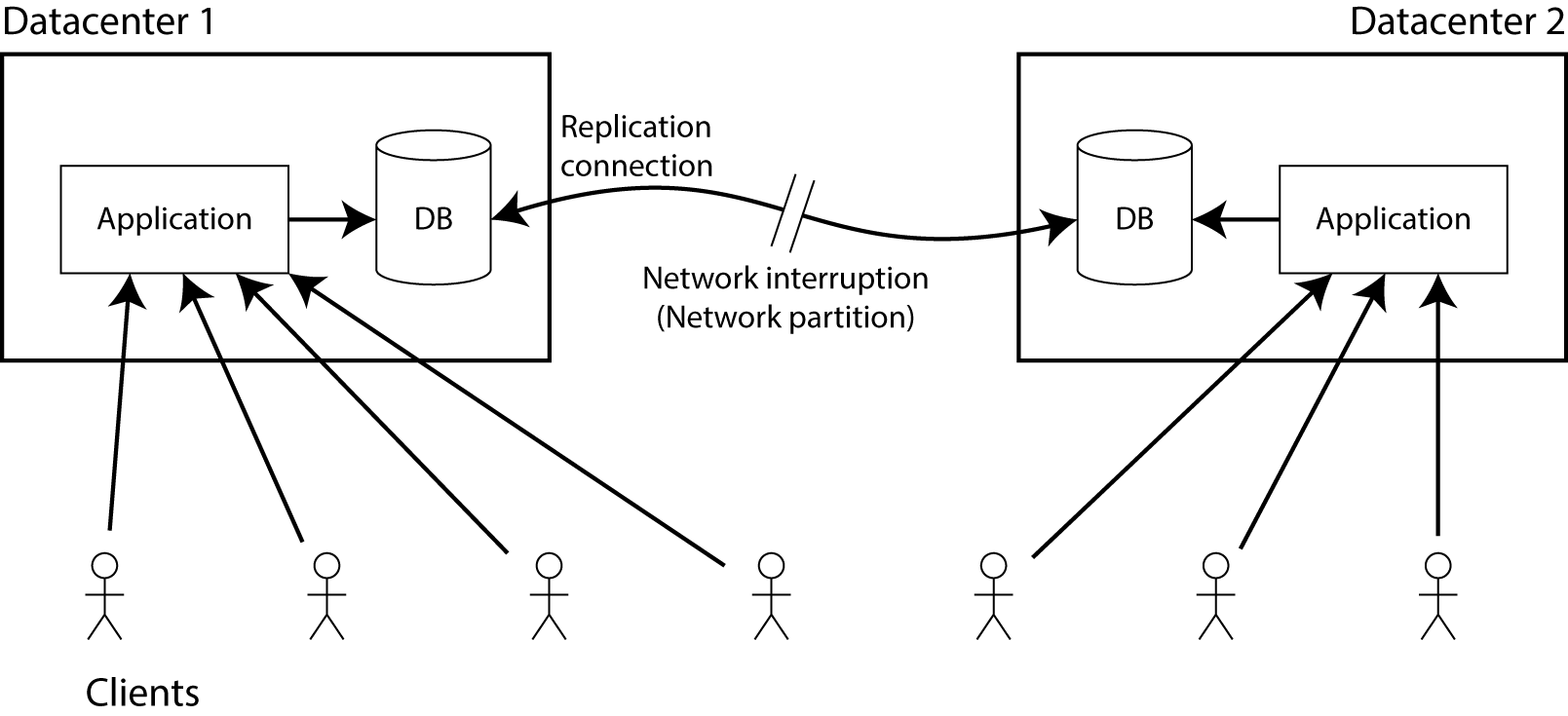
For example, your database has one replica in each of two different data centers. Here, the choice of synchronization strategy between replicas doesn’t matter—it could be single-leader (master-slave), multi-leader (multi-master), or quorum**[3]**-based replication (Dynamo-style). We only require that when data is written to one data center, it is synchronized to the other. Assume clients connect to only one of the data centers, and there exists a network path allowing the two data centers to synchronize data.
Suppose now this network path is broken—that is, a network partition occurs. What will happen?
 cap-availability
cap-availability
Obviously, you can only choose one of two options:
- The database still allows the application to perform writes, so both replicas remain individually available. However, because the synchronization link between the two replicas is broken, writes made in one data center will not be reflected in the other, which violates linearizability (in terms of the previous example, the possible scenario is that Alice is connected to DC1 and Bob is connected to DC2).
- If you don’t want to lose linearizability, you must ensure that all reads and writes happen in the same data center, namely the leader. The other data center (which cannot guarantee up-to-dateness because the network sync link is broken) must stop responding to read and write requests until the network recovers and data can be synchronized. Although the non-leader database replica server is running normally, it cannot process requests, so this does not satisfy CAP availability.
(By the way, this is essentially the entire proof of the CAP theorem—nothing more. The example here uses two data centers, but it also applies to network failures within a single data center; however, I think using two data centers makes the problem easier to understand.)
Notice that in the second case above, even though the system violates CAP availability, we are still successfully processing requests in one of the data centers. So when a system chooses linearizability (that is, gives up CAP availability), it does not necessarily mean that a network partition will definitely cause an application outage. If the system can temporarily migrate all user traffic to the leader database replica, clients won’t notice any system downtime at all.
Availability in practical applications and CAP availability are not entirely equivalent. Your application’s availability is most likely measured by some SLA (for example, 99.9% of well-formed requests must be successfully responded to within one second), but a system can meet the required SLA regardless of whether it satisfies CAP availability.
In practice, systems spanning multiple data centers usually use asynchronous replication and are therefore not linearizable. But this choice is usually due to excessive wide-area network latency, not just for fault tolerance against data center and network failures.
Many Systems Are Neither Linearizable nor CAP-Available
How do systems operate under the strict definitions of availability and consistency (linearizability) in the CAP theorem?
For example, using a single leader to manage a multi-replica database is the typical approach for relational database backups. In this configuration, if a network partition occurs between the client and the leader, data cannot be written to the database. Even if the client can still read data from some follower, it cannot write any data, which shows that the multi-replica database in this configuration is not CAP-available. Ironically, this configuration often claims to be “high availability.”
If this single-leader configuration is not CAP-available, is it a CP system? Don’t jump to conclusions. If you allow applications to read from followers, and data replication is asynchronous (the default for most databases), then when you read data from a follower, you may read data that is slightly behind the leader. In this case, your system’s read operations are not linearizable, that is, they do not satisfy CAP consistency.
Moreover, databases that support snapshot isolation/MVCC are deliberately designed to be non-linearizable, otherwise they would reduce the concurrency they can inherently provide. For example, PostgreSQL’s SSI provides serializability rather than linearizability, and Oracle provides neither. A database labeling itself ACID does not mean it necessarily satisfies the CAP theorem’s definition of consistency.
So these systems satisfy neither CAP consistency nor CAP availability. They are neither CP systems nor AP systems; they only satisfy P, whatever that means. (Yes, the CAP theorem’s “pick two out of three” allows you to pick only one of the three, or even none at all.)
What about NoSQL? Take MongoDB: (if no split-brain occurs) each shard has only one leader. Based on the discussion above, it does not satisfy CAP availability. Moreover, Kyle recently found that even under the highest consistency configuration, MongoDB still allows non-linearizable reads, so it also does not satisfy CAP consistency.
As for Dynamo and its derivatives Riak, Cassandra, and Voldemort—systems optimized specifically for high availability and called AP—do they really conform to the AP properties in CAP? The answer depends on your configuration. If you allow read and write requests to hit just one replica (R=W=1), then they do satisfy CAP availability. But if you require quorum reads and writes (R+W>N), and a network partition exists, replicas in the minority partition cannot reach consensus, so quorum reads and writes do not satisfy CAP availability (they are at least occasionally unavailable until enough nodes are added to the minority partition).
Sometimes people claim that quorum reads and writes can guarantee linearizability, but relying on this condition would be unwise. Because in some complex situations, when read repair and sloppy quorum occur simultaneously, data that has already been deleted may reappear; or the number of replicas has fallen below the original W value (violating the quorum condition), or the number of replicas has increased above the original N value (also violating the quorum condition)—all of which can lead to non-linearizable accesses.
These are not failed systems; people have been using them successfully in production. But so far, we cannot strictly classify them as AP or CP, either because it depends on specific configurations and operations, or because the system satisfies neither CAP availability nor CAP consistency.
Case Study: ZooKeeper
What about ZooKeeper? It uses a consensus algorithm, so people naturally assume it has chosen consistency over availability (i.e., it is a CP system).
But if you have read ZooKeeper’s documentation, it clearly states that ZooKeeper does not support linearizable read operations by default. Each client connects to only one server node; when the client reads, even if other nodes have newer data, it can only see the data on the server node it is directly connected to. This allows its read performance to be much higher than collecting a quorum or accessing the leader on every read, but it also shows that ZooKeeper does not satisfy CAP consistency under its default configuration.
Of course, you can also send a sync command before each read operation to make ZooKeeper support linearizable reads. But this is not the default setting, because it sacrifices some performance. People only use the sync command when necessary, not before every read operation.
What about ZooKeeper’s availability? ZK requires a majority of cluster nodes to reach consensus on data; for example, a write operation can only succeed when a majority of nodes agree. If a network partition occurs, one side has the majority of nodes and the other side has only a minority. At this point, the partition with the majority of nodes can continue to serve; but for the minority partition, even though the nodes are alive, it cannot normally process read or write requests. Therefore, when a network partition occurs, ZK’s write operations do not satisfy CAP availability (even though the partition with the majority of nodes can still process writes).
More interestingly, ZooKeeper 3.4.0 also added a read-only mode. In this mode, the minority partition can still process read operations without needing a quorum! This read-only mode satisfies CAP availability. Therefore, ZooKeeper’s default settings satisfy neither CAP consistency (CP) nor CAP availability (AP); the only thing it truly satisfies is partition tolerance (P). But you can call the sync command when needed to make read requests satisfy CP; or in read-only mode, make its read operations (excluding writes) satisfy AP.
This is quite annoying. If we call ZooKeeper “inconsistent” simply because its default configuration is not linearizable, we would seriously misrepresent ZK’s capabilities. It can actually provide very strong consistency! It supports atomic broadcast (which can be simply understood as the consensus problem) and provides causal consistency[4] for every session—which is stronger than read your writes, monotonic reads and consistent prefix reads combined. The ZK documentation says it provides serializable consistency, but this is actually overly modest, because it can provide much stronger consistency guarantees than that.
From the ZooKeeper example, we can see that even if a system satisfies neither CAP consistency (CP) nor CAP availability during a network partition, and even if its default configuration does not provide linearizability when there is no network partition, it can still be a good system (I guess ZK is PC/EL under Abadi’s PACELC framework, but I don’t find this more enlightening than CAP).
CP/AP: A False Dichotomy
The fact that a database cannot be unambiguously classified as CP/AP indicates that CP/AP is fundamentally unsuitable as a label for describing systems.
Based on the following points, I believe we should stop forcibly categorizing data storage systems as AP or CP:
- Within the same piece of software, you may have multiple choices of consistency properties.
- Under the strict definitions of the CAP theorem, most systems satisfy neither consistency nor availability. Yet I have never heard anyone call these systems “P”—perhaps it doesn’t sound very good. But such systems are not that bad; they may in fact be very reasonable designs, just not falling into either of the CP/AP categories.
- Although most software cannot be neatly classified into CP or AP, people still forcibly divide them accordingly. This inevitably leads to changing the definitions of “consistency” or “availability” in the CAP theorem to fit the specific scenarios of their applications. Unfortunately, when the definitions of these key concepts change, the CAP theorem no longer holds, and the CP/AP distinction becomes completely meaningless.
- Forcibly classifying a system into one of two categories easily causes people to overlook a great deal of nuance. When designing distributed systems, there are many factors to consider: service latency, model simplicity, operational complexity, etc. It is obviously impossible to compress so many details into a single bit of information. For example, ZooKeeper has an AP-compliant read-only mode, but that mode simultaneously provides global ordering of all write operations—a property much stronger than the guarantees provided by so-called AP systems like Riak or Cassandra. Crudely classifying it as AP is plainly laughable.
- Even CAP’s author Eric Brewer admits that the CAP theorem is a misleading and overly simplified model. In 2000, the significance of proposing the CAP theorem was to guide industry discussions on trade-offs in distributed data systems, and the CAP theorem did achieve that effect. But the theorem’s purpose was not to propose a groundbreaking formal conclusion, nor to become a rigorous classification method for data systems. Fifteen years later, we now have many more consistency and fault-tolerance models for reference. CAP has completed its mission; it is time to move on.
Learn to Think for Yourself
If CP/AP is not suitable for describing and evaluating a system, what should we use? I think there is no single correct answer. Many predecessors have spent considerable effort thinking about these issues and proposed many terms and models to help us understand them. To learn this knowledge, you need to read the relevant literature more deeply.
- Doug Terry’s paper is a great starting point: he explains various forms of eventual consistency using baseball as an example. Even if you are not American and know nothing about baseball, you will find the paper clear and highly readable.
- If you are interested in transaction isolation models (isolation, different from consistency in distributed systems but closely related), my small project Hermitage is worth a look.
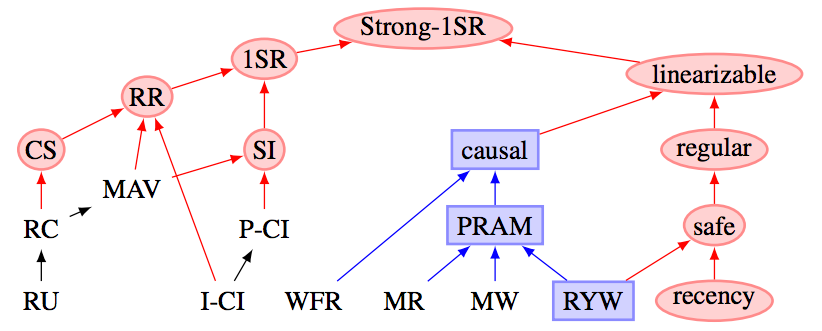
- Peter Bailis’s paper explores the relationship between consistency, transaction isolation, and availability (this paper describes the hierarchical structure among various forms of consistency—Kyle Kingsbury loves telling people about this).
![isolation-levels]() isolation-levels
isolation-levels - Once you have read these, you should be ready to dive into the literature. I have included many paper citations throughout this article; take a look—experts have already solved many of these problems for you.
- As a last resort, if you don’t want to read these original papers one by one, you can take a look at my book, which summarizes most of the important ideas in a very accessible way (see, I’ve tried as hard as possible to make this article not look like it’s promoting my book).
- If you want to learn more about the proper way to use ZooKeeper, Flavio Junqueira and Benjamin Reed’s book is a good choice.
No matter which learning path you choose, I hope you remain curious and patient—this is not an easy subject. But all the effort is worthwhile; you will learn how to make reasonable trade-offs and thereby find the architecture best suited to your application. Finally, whatever you do, please stop saying CP and AP, because they are meaningless.
Translator’s Notes
[1] CAP Availability. The author uses the term CAP-Available to specifically refer to the narrow, specialized availability in the CAP theorem; therefore, CAP availability in the text is a noun as a whole, indicated by italics. The same applies to CAP-Consistency; to avoid ambiguity, the author simply uses linearizability instead.
[2] Linearizability. It can be understood from another perspective: a series of events with partial order relationships in the system can be globally topologically sorted, that is, there are no cycles.
[3] Quorum mechanism. This is a commonly used voting algorithm in distributed systems for data replication and ensuring eventual consistency. Its main mathematical idea comes from the pigeonhole principle. This algorithm can ensure that multiple replicas of the same data object are not read and written by more than two accessors simultaneously. Each system using this algorithm has two key parameters: minimum read votes R and minimum write votes W. Their relationship must satisfy: 1. R + W > N 2. W > N/2, where N is the number of cluster replicas. When understanding it, you can analogize it to a read-write lock: the system cannot have multiple write-write or read-write operations simultaneously, but if R is set smaller, multiple reads can occur at the same time.
[4] Causal consistency. Causal consistency is a major memory consistency model that guarantees the order of operations with causal relationships, while making no guarantees about the execution order of events without obvious causal relationships.
[5] replicate. Can be translated as replica, redundancy, backup, etc.

