cmu15445 is a classic open course on the design and implementation of Database Management Systems (DBMS). The course uses Database System Concepts as the textbook, providing lecture slides, notes, and videos, and carefully prepares several interconnected projects. The course places great emphasis on system design and programming implementation. In the words of the professor Andy Pavlo, this is a course that you can put on your resume and that can help you land a good offer.
Having some free time this vacation, I dug out this course and was immediately impressed by its rich content and elegant organization. Unfortunately, time is limited, so I can only follow the projects as the main thread, supplemented by lecture slides and notes, and briefly go through them. If I have more time, I will skim the textbook and videos. Starting from project one, after each project’s autograder run, I will write a note for future reference. Professor Andy Pavlo suggests not making the project code repository public, so I will try to minimize code snippets and focus more on the thought process.
This post is about project one: managing the cache of file system pages in memory — the buffer pool manager.
Overview
The target system of this project, BusTub, is a disk-oriented DBMS, but data on disk does not support byte-level access. Therefore, an intermediate layer for managing pages is needed. However, Professor Andy Pavlo insists on not using mmap to delegate page management to the operating system. Thus, the goal of Project 1 is to proactively manage the cache of pages from disk in memory, thereby minimizing the number of disk accesses (in time) and maximizing the contiguity of related data (in space).
This project can be broken down into two relatively independent sub-tasks:
- Maintaining the replacement policy: LRU replacement policy
- Managing the buffer pool: buffer pool manager
Both components are required to be thread-safe.
This article first analyzes the project content from basic concepts and core data flows, then goes through the two sub-tasks respectively.
作者:木鸟杂记 https://www.qtmuniao.com/2021/02/10/cmu15445-project1-buffer-pool/, 转载请注明出处
Project Analysis
When I first started writing the project code, I felt there were many details, and it was easy to miss something during implementation. But as I implemented and thought deeper, I gradually grasped the full picture and realized that as long as a few basic concepts and core data flows are clear, one can grasp the essentials.
Basic Concepts
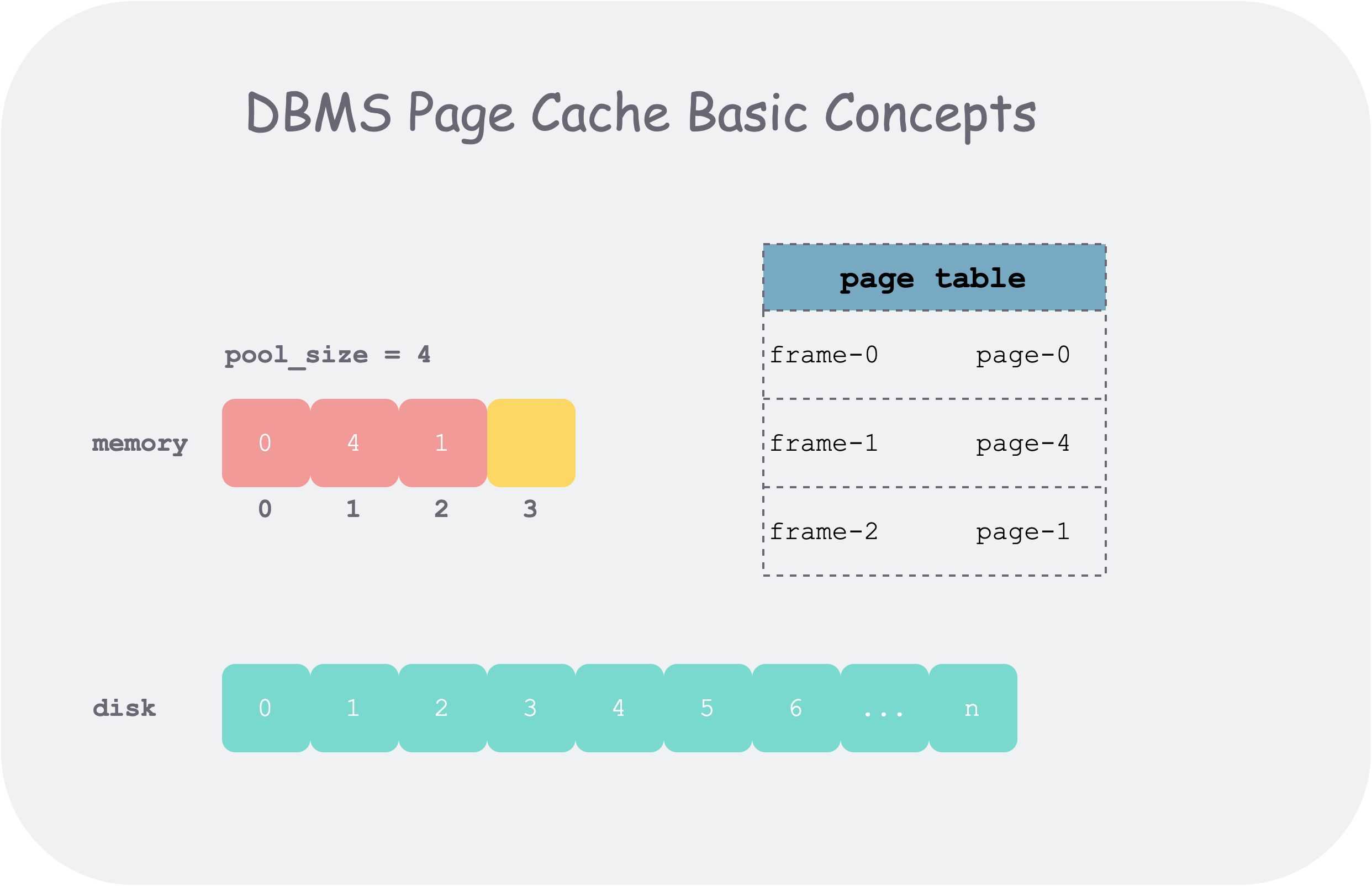
The basic unit of operation for the buffer pool is a logically contiguous byte array. On disk, it is represented as a page, with a unique identifier page_id; in memory, it is represented as a frame, with a unique identifier frame_id. To keep track of which frame stores which page, a page table is needed.
In the following text, I may use page and frame interchangeably, because both concepts are the basic units of data managed by the buffer pool, generally 4k. The differences are as follows:
- The page id is the global identifier for this unit of data, while the frame id is just the index of a page in the memory pool (frame array).
- A page in the file system is a logically contiguous byte array; in memory, we attach some metadata to it:
pin_count_,is_dirty_
 基本概念
基本概念
Generally speaking, the memory pool for managing frames is much smaller than the disk. Therefore, after the memory pool is full, when loading a new page from disk into the memory pool, some replacement policy (replacer) is needed to evict some no-longer-used pages from the memory pool to make room.
Core Data Flow
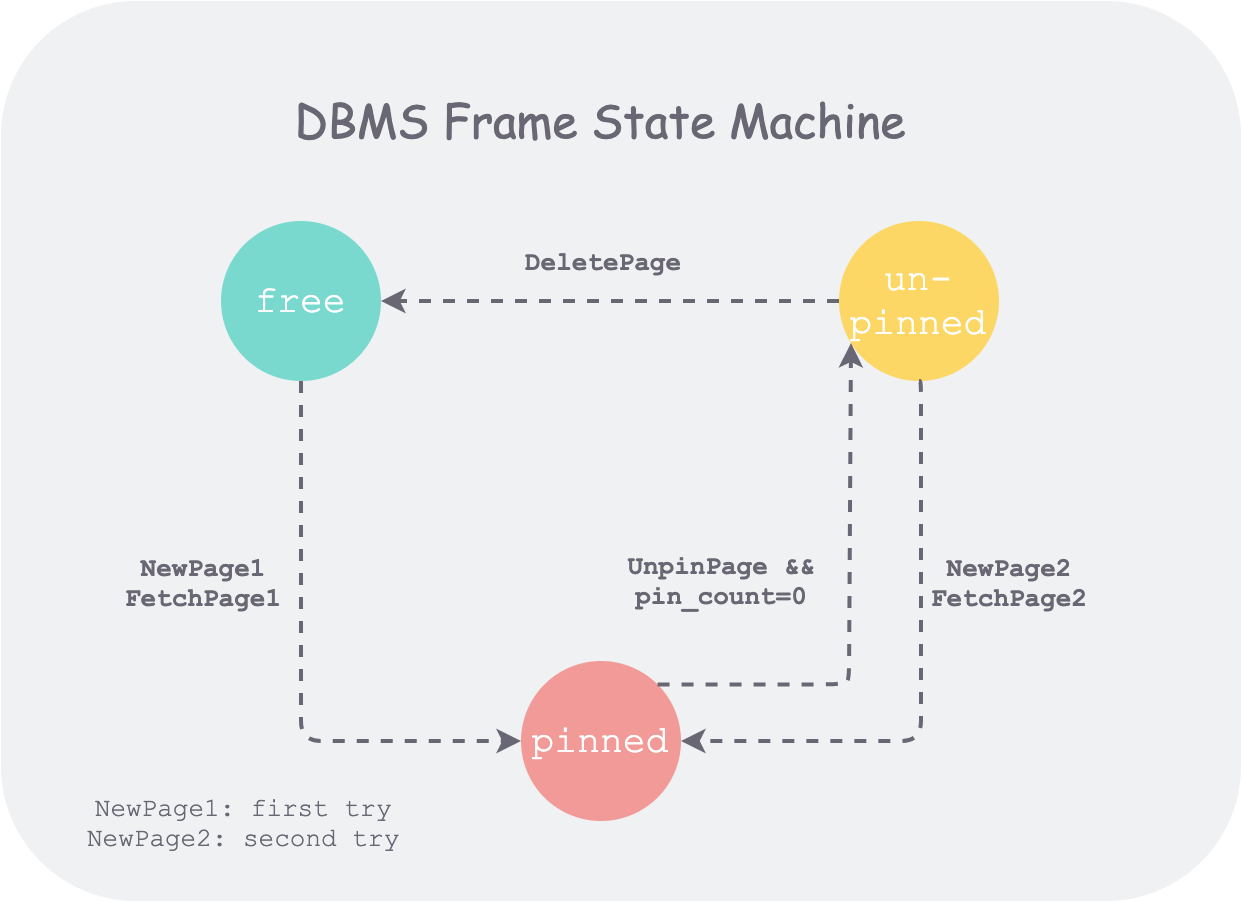
To state the conclusion first, the implementation core of the buffer pool manager lies in managing the state of all frames in the memory pool. Therefore, if we can sort out the state machine of frames, we can grasp the core data flow.
The buffer pool maintains a frame array. Each frame has three states:
- free: initial state, not holding any page
- pinned: holding a page that is being used by a thread
- unpinned: holding a page, but the page is no longer being used by any thread
And the functions to be implemented:
1 | FetchPageImpl(page_id) |
are the actions that drive the above state changes in the state machine. The state machine is as follows:
 frame 状态机
frame 状态机
Corresponding to the data structures in the implementation:
- The frame array that stores page data is
pages_ - The indexes (frame_id) of all free frames are stored in
free_list_ - The indexes of all unpinned frames are stored in
replacer_ - The indexes of all pinned frames and unpinned frames are stored in
page_table_, and the two states are distinguished by thepin_count_field in the page.
In the figure above, NewPage1 and NewPage2 indicate that in the NewPage function, each time a free frame is obtained, it first tries to take a free frame from the free list (freelist_), and only if that fails will it evict an unpinned frame from the replacer_ and then use it. This reflects one goal of the buffer pool manager implementation: minimizing disk accesses, the reason for which is analyzed later.
Project Components
Having grasped the basic concepts and core data flow of this project, let’s analyze the two sub-tasks.
TASK #1 - LRU REPLACEMENT POLICY
I had written a similar implementation on LeetCode before, so I naturally drew on that experience. But I soon found that these two interfaces are somewhat different.
What LeetCode provides is a kv store interface, which maintains recency order during get/set, and automatically replaces the oldest KV when the memory pool is full.
But what this project provides is a replacer interface, which maintains a list of unpinned frame_ids, adds the frame_id to the list and maintains recency order when Unpin is called, removes the frame_id from the list when Pin is called, and returns the oldest frame_id when Victim is called.
Of course, the essence is the same, so for this project I also used unordered_map and doubly linked list as the data structure. Implementation details will not be elaborated on. One thing to note is that if Unpin finds that the frame_id is already in the replacer, it returns directly without changing the recency order of the list. Because logically, the same frame_id cannot be Unpinned multiple times, so we only need to consider the first Unpin of a frame_id.
In a broader context, essentially, the replacer is a recycle bin that maintains an eviction order; that is, we don’t directly delete pages with pin_count_ = 0 from memory, but put them into the recycle bin. According to the temporal locality of reference, a page that was just accessed is likely to be accessed again. Therefore, when we have to truly delete (Victim) a frame from the recycle bin, we delete the oldest one. When later we want to access a piece of data that was just put into the recycle bin, we only need to fish the page out of the recycle bin, thus saving a disk access. This achieves the goal of minimizing disk accesses.
TASK #2 - BUFFER POOL MANAGER
The core logic was mostly covered in the project analysis section. Here, I simply list some issues I encountered during my implementation.
The scope of page_table_. In the initial implementation, after drawing the frame state machine, I felt it was perfect to only put pinned frame ids in page_table_: it would allow frame ids to be distributed mutually exclusively according to state among free_list_, replacer_, and page_table_. But later I realized that if unpinned frame ids were not saved in page_table_, it would be impossible to reuse pages with pin_count_ = 0, and the replacer would lose its meaning.
Dirty page flush timing. There are two strategies: one is to flush every time Unpin is called, which flushes more frequently but can ensure that content is not lost after an unexpected power failure and restart; the other is to lazily flush when the replacer victimizes a frame, which ensures the minimum number of flushes. This is a trade-off between performance and reliability. Considering only this project, either approach should pass.
NewPage should not read from disk. This was a bug I wrote. After all, when NewPage is called, there is no corresponding page content on disk at all, so the following error is reported:
1 | 2021-02-18 16:53:47 [autograder/bustub/src/storage/disk/disk_manager.cpp:121:ReadPage] DEBUG - Read less than a page |
Clear metadata when reusing a frame. When reusing a frame evicted from the replacer, special care must be taken to clear fields like pin_count_\is_dirty_ before use. Of course, when DeletePage is called, care must also be taken to set page_id_ to INVALID_PAGE_ID and clear the above fields. Otherwise, when used again, if pin_count_ is not 0 after Unpin, it will cause the page to fail to be deleted during DeletePage.
Lock granularity. The most brute-force approach is to add a lock at the function scope level. If optimization is needed later, the lock granularity can be refined.
Project Code
Taking FetchPageImpl as an example to emphasize some implementation details, note that the project has already provided an implementation framework through comments.
I have added comments to mark some points I think need attention.
1 | Page *BufferPoolManager::FetchPageImpl(page_id_t page_id) { |
The autograder related to the project can be found in FAQ for the registration address and invitation code. When submitting code, it is best not to submit a GitHub repository address, as there will be many formatting issues. You can follow the instructions on the project page each time, and package the relevant files into a zip archive according to the directory structure for submission.
 提交事项
提交事项
Read the project description carefully. Things to note before submission:
- Run
make formatin the build directory for automatic formatting. - Run
make check-lintin the build directory to check for some syntax issues. - Design some tests for each function locally, write them into the relevant file (for this project,
buffer_pool_manager_test.cpp), turn on the test switch, compilemake buffer_pool_manager_testin the build folder, and run./test/buffer_pool_manager_test
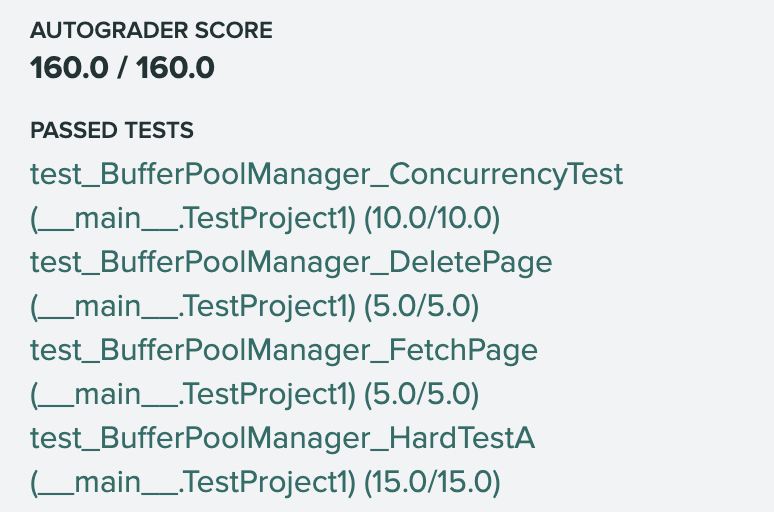
Here’s a project1 autograder result:
 autograder-result
autograder-result
Summary
This is the first project of cmu15445, implementing a buffer pool manager that moves pages between disk and memory on demand. The key to this project is to grasp the basic concepts, sort out the core data flow, and on this basis pay attention to some implementation details.

