Distributed systems have many classic patterns, also known as design patterns. Each pattern solves a classic category of problems; with enough accumulated knowledge, one can make variations and trade-offs to design architectures that fit specific requirements. However, there don’t seem to be many shared experiences in this area, so I plan to summarize some lessons from work and study—partly as notes, and partly hoping they may be helpful to others. Given space constraints and my own limitations, it is difficult to be exhaustive or precise. Corrections are welcome for any inaccuracies.
Each post will analyze a topic through background overview, architecture modules, and summary/extensions. This is the first post: the Master-Workers architecture.
Overview
The Master-Workers architecture (loosely translated as primary-secondary architecture) is a common organizational pattern in distributed systems, such as the Master and ChunkServers in GFS, and the Master and Workers in MapReduce. Faced with a cluster of separate machine resources in a distributed system, the primary-secondary architecture is the most natural and straightforward way to organize them—like a group of people with a leader who makes decisions and coordinates, thereby maximizing the group’s collective output.
This is also a manifestation of the common divide-and-conquer philosophy in computer systems. A complex system is broken down into several relatively high-cohesion, low-coupling sub-modules, with clearly defined functional boundaries and interaction interfaces, making the system easier to understand, maintain, and extend. In the primary-secondary architecture, the primary (Master) typically maintains cluster metadata and uses it for scheduling, while the secondaries (Workers) are usually responsible for reading and writing specific data shards (in storage systems) or serving as execution units for sub-tasks (in compute systems).
Author: 木鸟杂记 https://www.qtmuniao.com/2021/07/03/distributed/system/1/master/worekrs, please cite the source when reposting
Architecture Modules
A primary-secondary architecture system typically consists of a single Master and multiple Workers. As a side note, the reason I use secondary instead of the English word Slave is that I feel Worker is more neutral. Of course, a single Master introduces performance bottlenecks and availability issues; there are usually multiple solutions to this, which will be discussed later. But the benefits of a single Master are obvious: the Master acts as a control node without having to deal with consistency issues brought by multiple replicas, greatly reducing implementation complexity.
Taking the storage system architecture that I’m more familiar with as an example, the architecture diagram usually looks like this.
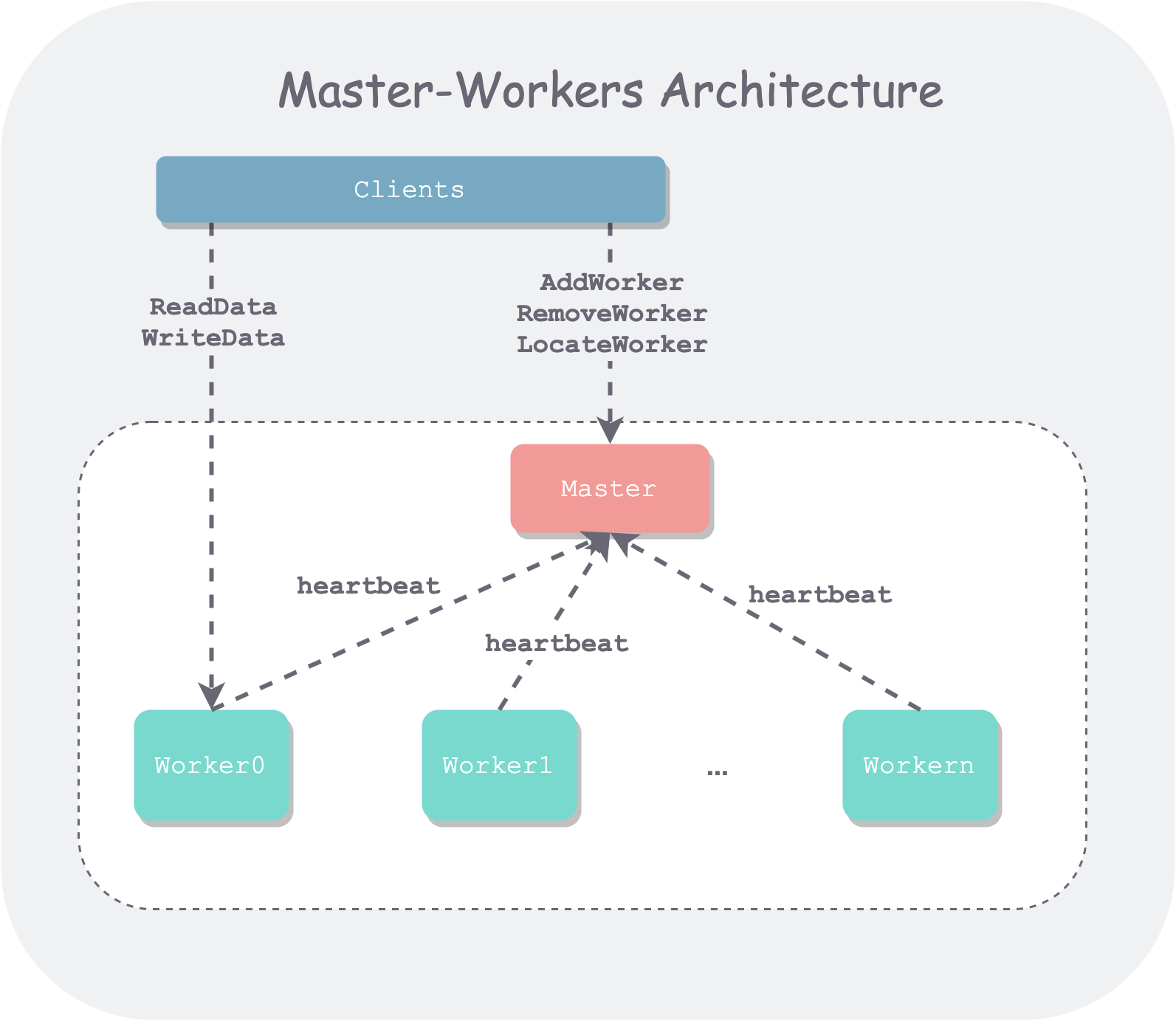 master-workers-architecture.png
master-workers-architecture.png
In addition to the internal Master and Workers of the system, there are also external users who use the system. We usually call them the client. The client interacts with the system through the interfaces exposed by the system (such as RPC or HTTP).
Master
The Master typically stores the system’s metadata. What is metadata? It can be understood as a reflection, or a view, of the cluster’s organizational information in the Master’s mind: for example, how many Workers are in the cluster, how much remaining capacity each Worker has, what the load looks like, which data is stored on which Workers, and so on.
How is this metadata collected? There are mainly two cases:
- Configuration. This can be understood as the cluster’s static information, such as how many Workers the system initially has, the physical topology of the Workers, the capacity of each Worker, etc. The Master loads this configuration information at startup.
- Reporting. This is mainly the cluster’s dynamic information. While running, Workers actively report their own status to the Master, such as whether the Worker is alive, the Worker’s load information, what data the Worker stores, etc. During system operation, Workers periodically report to the Master through heartbeats and other means.
With this metadata, the Master can have a grasp of the entire cluster situation and make a series of decisions. Here are a few examples:
- Scheduling. A new write data request comes in—which Worker should be assigned to handle it? Usually, one with a lighter load is chosen.
- Balancing. As Workers change and data is added or deleted, the distribution of data across different machines may no longer be uniform, forming read/write hotspots on some machines while wasting resources on others, thereby affecting the overall system performance. Therefore, real-time monitoring and timely migration are needed.
- Routing/Locating. A read or write request comes in, but you don’t know which Worker to go to? The Master will query the metadata and return the Worker information corresponding to the data.
Master Availability
As can be seen, the availability of the entire system depends entirely on the Master. The industry has many solutions for this, such as:
- Using primary-backup. That is, creating a replica of the Master. The backup Master must keep all metadata in sync with the primary Master at all times; once the primary Master fails, the backup immediately takes over. Hadoop later adopted this approach.
- Using consensus algorithms (consensus algorithm). Simply put, a group of Master machines form a committee, and every state change must reach consensus through some algorithm. Google’s Spanner does this.
- Masterless. The system no longer has a Master; everyone is equal. Then, through some strategy, such as consistent hashing (consistent hash), work is distributed. Amazon’s Dynamo does this.
Each strategy is a large topic in itself and could be the subject of a separate post in the future. Due to space constraints, this post will not elaborate further.
Workers
In a storage system, Workers store the actual data and provide data IO services to the outside.
From a single-machine perspective, a Worker needs to design a single-machine engine that fits the business requirements to store data efficiently. Single-machine engine design is also a large topic; here is a brief mention:
- Index design: such as B+ trees, LSM-trees, hash indexes, etc.
- Underlying system: whether to use raw disks or a file system.
- Storage media: whether to use persistent memory, solid-state drives, or mechanical hard drives.
From a multi-machine perspective, as the number of machines increases, the probability of a single machine failing in the system rises significantly. To cope with this normalized failure, the following are needed:
- Operational automation. When a machine becomes unavailable, it should be automatically removed; when repaired, it should be easily brought back online.
- Data redundancy. When a machine fails, data must not be lost. Therefore, each piece of data should be stored in multiple replicas or use EC algorithms for redundancy.
Summary
The Master-Workers architecture is the most commonly used organizational pattern in distributed systems. This architecture is similar to the organization of human communities, breaking down the responsibilities of the system: the Master collects metadata and uses it for task scheduling; the Workers are responsible for the actual workload, requiring an efficient single-machine engine design and global redundancy coordination. This architecture is simple and direct, yet powerful.

