Overview: Why Flow Control Matters
The benefit of moving to the cloud lies in pooling resources, enabling multi-tenant sharing, and allocating on demand, thereby reducing costs. But:
- Multi-tenant isolation: Users demand that they can use the capacity they’ve purchased without being affected by other tenants.
- Resource sharing: Resources can only be logically separated, not physically separated; otherwise, dynamic allocation (overcommitment) cannot be fully achieved.
These two are a pair of contradictory requirements, and I believe they are the most critical problems that cloud-native databases must solve. If this problem is not solved well, the database will:
- Either the platform won’t make money: With static resource reservation, users may be satisfied because they can always use the resource quota sold to them, but this leads to massive resource waste—either the price is high, or users won’t pay.
- Or users will be dissatisfied: Multiple tenants share physical resources, but it is very easy for them to affect each other, preventing users from using the quota promised by the platform.
Starting from static allocation, DynamoDB gradually evolved a combined global and local admission control mechanism, thereby achieving physical resource sharing while logically providing quota isolation to users, realizing true cloud-native databases. Below, based on the details disclosed in the paper Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service, I summarize the evolution of its flow control mechanism for your reference.
Due to limited expertise, any errors are welcome to be pointed out at any time.
Author: Muniao’s Notes https://www.qtmuniao.com/2022/09/24/dynamo-db-flow-control Please indicate the source when reprinting
The Beginning: Static Reservation
What we face here is actually a common scheduling problem: how to schedule table-partition-replicas onto a cluster (a set of physical machines) while balancing the following characteristics:
- Availability: Physical machines are divided into AZs (Availability Zones), and different replicas are scheduled to different AZs.
- Data capacity: This is actually about storage resources; each physical machine has a total capacity limit, and each replica also has an expected capacity (which can automatically split as capacity grows, so initially they may all be relatively small). When creating table partition replicas, we need to find target machines whose remaining resources exceed their requirements. For example, a very simple matching strategy is to always pick the most idle machine in the cluster.
- Traffic: The paper calls this performance, which actually includes compute resources and network bandwidth. The allocation method is similar to point 2.
The focus of this article is mainly on point 3, and it introduces traffic units: Read Capacity Units (RCUs) and Write Capacity Units (WCUs).
The initial strategy was to evenly distribute the table’s total quota (provisioned capacity) across each partition. For example, if the table’s total quota is 1000 RCUs and there are ten partitions in total, each partition gets 100 RCUs. Then the traffic of each partition must not exceed 100 RCUs.
The biggest advantage of this strategy is its simple implementation, while the disadvantages are numerous. Let’s examine this strategy carefully and we will find that it actually contains an assumption: traffic across partitions is uniform. But in reality, this model is too ideal. Once partition traffic becomes uneven, some partitions may be throttled after reaching their 100 WCUs quota due to high traffic, while the quotas of other partitions with low traffic are wasted.
First Steps: Bursting and Adaptive Traffic
To patch the purely static allocation strategy above, DynamoDB began introducing traffic bursting and adaptive traffic strategies.
Bursting Strategy
To deal with short-lived spikes in certain partitions, DynamoDB introduced a workaround: if it finds that a partition has instantaneous high traffic and the node where the partition replica resides still has remaining capacity, it temporarily allocates some extra capacity to that replica. Specifically in implementation, DynamoDB uses three token buckets:
- Partition reserved token bucket. Corresponds to the 100 RCUs in the previous example; when partition traffic does not exceed this value, reads and writes are allowed and the corresponding number of tokens is deducted from this bucket.
- Node total token bucket. Corresponds to the single-machine capacity limit; all incoming requests consume tokens from this bucket.
- Partition burst token bucket. When partition traffic exceeds the reservation, it checks whether the node total token bucket still has remaining capacity; if so, it allows that partition to burst.
It should be noted that the RCU quota is sufficient with the above strategy, but for the WCU quota, DynamoDB adds one more restriction: it needs to check whether the total WCUs of all replicas of that partition exceeds the limit. The idea is that RCUs can be given a bit more, but WCUs cannot. The implementation is also simple: each partition (where multiple replicas form a replication group) Leader acts as a coordinator to collect and distribute capacity information.
Finally, this strategy is only used to address short-lived burst traffic within a 300-second window; if the time window is exceeded, the borrowed traffic must be released. Because this portion of traffic belongs to the overcommitted capacity on the machine, it needs to be ready for reallocation to other partition replicas on the same machine at any time.
Adaptive Strategy
Then how are long-lived spikes solved? The only way is to reallocate traffic across different partitions.
DynamoDB uses a central service (the paper calls it Adaptive capacity; it is unclear whether this component is an additional service or part of some existing central service) to monitor each table’s total quota and consumed capacity.
When a table still has remaining capacity, but some of its partitions are being throttled due to traffic bursts, it can use a proportional control algorithm (probably allocating proportionally according to traffic size) to allocate some extra quota to these partitions. Moreover, if after allocation it hits the total quota limit of the storage node, the autoadmin system will migrate that partition to a relatively idle machine that can provide the required quota increment.
Reflection: Tight Coupling of Partitioning and Flow Control
The biggest characteristic of the first two approaches is that they tightly couple flow control and partitioning together—that is, flow control is performed at the partition level, making it difficult to perform cross-partition traffic scheduling for a table. But what we provide to users is a table-level quota abstraction, so it is best to hide the physical implementation of partitions, ensuring that as long as the table’s total quota still has remaining capacity, it can be allocated to data with burst traffic. Rather than having some partitions with low traffic still occupying quotas, while other partitions with high traffic get throttled after using up their allocated quotas.
Although the adaptive strategy made some improvements in the cross-partition direction, it is still in the category of patches, rather than designing dynamic flow control as a first-class concept. For this reason, DynamoDB introduced a global admission control mechanism to thoroughly solve this problem.
Improvement: Global Admission Control
Global admission control (GAC) also uses a token bucket implementation, but unlike the previous local token buckets, global admission control uses a kind of global token bucket, or distributed token bucket. Tokens are produced by the GAC service, and request router instances consume tokens, to achieve table-granularity admission control.
Components
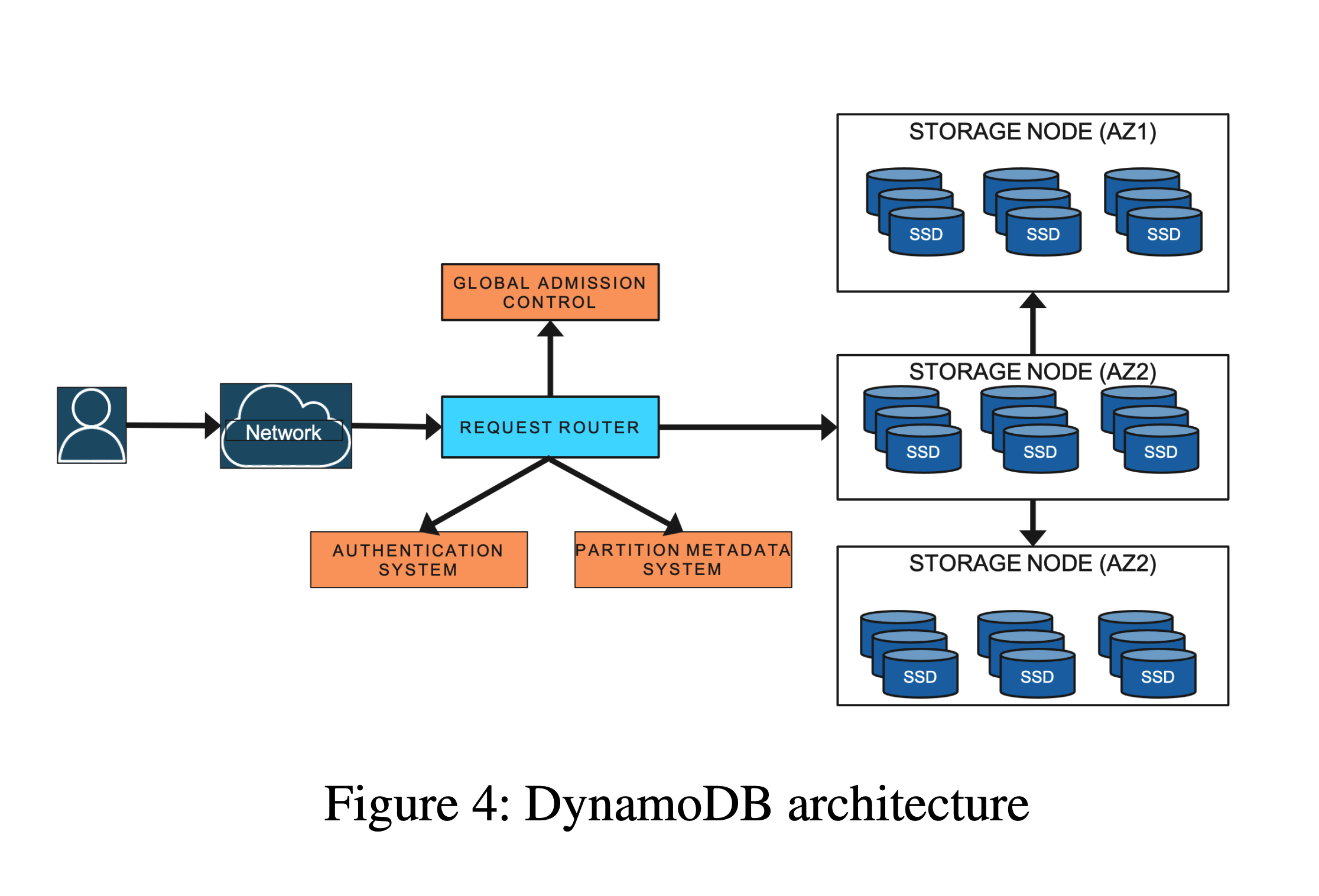 Architecture Diagram
Architecture Diagram
- GAC Service: Composed of a set of GAC instances, which distribute traffic evenly via consistent hashing.
- GAC Instance: Uses token buckets to produce tokens; each instance maintains one or more table-level token buckets.
- Request Router: request router, the client of GAC, communicates with the GAC service to obtain tokens for flow control. Tokens have a time limit; if not consumed before expiration, they are automatically destroyed.
One key question is: how many tokens does GAC allocate to a request router instance each time?
DynamoDB tracks the consumption rate of each request router instance based on historical information, and allocates proportionally according to the rate. Then how is tracking performed? The paper doesn’t mention it; presumably it uses something like a sliding time window, but such signals are also not easy to work with, as there will always be cases of inaccurate characterization or excessive delay. It is unclear how DynamoDB specifically implements this.
Dynamic Rebalancing
Unlike static partitions and traffic quotas, partition traffic from the GAC perspective changes at any time. To avoid hotspot aggregation causing certain storage nodes to be overwhelmed, DynamoDB implements a mechanism that can proactively rebalance partitions across nodes based on throughput consumption and storage volume:
- Each storage node independently performs resource usage accounting; if the total resource usage of the node exceeds a certain percentage threshold, the storage node will proactively report to the autoadmin service and provide a list of candidate replicas to be migrated.
- After receiving the request, the autoadmin service will find a suitable storage node for each candidate replica based on global resource distribution, while satisfying the availability and resource usage constraints mentioned at the beginning.
Traffic Splitting
If there is a large hotspot on a certain partition, it may still be throttled due to the load of the node it resides on. DynamoDB will track these hotspots and collect statistics on the traffic distribution of data on that partition, splitting the partition according to traffic. Compared to simply splitting by midpoint (to balance storage resources), splitting by traffic distribution (compute and bandwidth) may be more fundamental for eliminating hotspots. After partition splitting, migration can be performed as needed.
The time required for partition splitting is usually on the order of minutes.
But there are some access hotspots that cannot be eliminated through partition splitting:
- Single data item hotspot
- Range access hotspot
DynamoDB can identify these access patterns, thereby avoiding splitting on such partitions.
Auto Provisioning
Setting a fixed quota when creating a table is a very difficult thing—just like trying to predict the future. If set too high, it causes resource waste; if set too low, it easily triggers throttling. This is a drawback of static quotas, so DynamoDB provides a kind of dynamic quota table (on-demand provisioning table, billing according to actual usage, which is also a major characteristic of cloud computing).
To precisely describe quotas, DynamoDB introduces the concept of throughput measurement: read and write capacity units. If we simply use QPS to characterize traffic, it is obviously inappropriate, because the amount of data involved in each request is unequal. Therefore, DynamoDB introduces per-unit-time traffic quotas—RCU and WCU—to characterize read and write traffic.
When performing auto provisioning, we must first accurately track read and write traffic. When a traffic burst is detected and throttling is about to be triggered, the quota is expanded exponentially (doubled). If the application’s sustained traffic is greater than twice the previous peak, the overall quota will be further increased through methods such as splitting partitions by traffic.
Summary
An important characteristic of the cloud is resource pooling, on-demand allocation, and precise billing, thereby achieving full resource utilization overall, offsetting the cost brought by generality through economies of scale.
Specifically in cloud-native databases, this manifests as automatic provisioning of multi-tenant traffic. Through its paper, DynamoDB disclosed an evolution process from static quota partitioning, applying patches, to global dynamic partitioning. For various domestic vendors claiming to want to build cloud-native databases, if they want to truly make money (resource sharing) while ensuring user experience (resource isolation), DynamoDB’s experience surely has many lessons to learn from.

