Overview
Facebook Velox is a C++ library for SQL runtime, designed to unify Facebook’s various computation flows, including Spark and Presto, using a push-based model with support for vectorized execution.
Velox takes an optimized PlanNode tree and slices it into linear Pipelines. The Task is responsible for this transformation, with each Task targeting one PlanTree segment. Most operators are translated one-to-one, but some special operators usually appear at the split points of multiple Pipelines. Typically, these split points correspond to branching points in the plan tree, such as HashJoinNode, CrossJoinNode, and MergeJoinNode, which are usually translated into XXProbe and XXBuild. However, there are also exceptions, such as LocalPartitionNode and LocalMergeNode.
Author: 木鸟杂记 https://www.qtmuniao.com/2023/03/22/velox-task-analysis Please indicate the source when reposting
 velox-join-bridge.png
velox-join-bridge.png
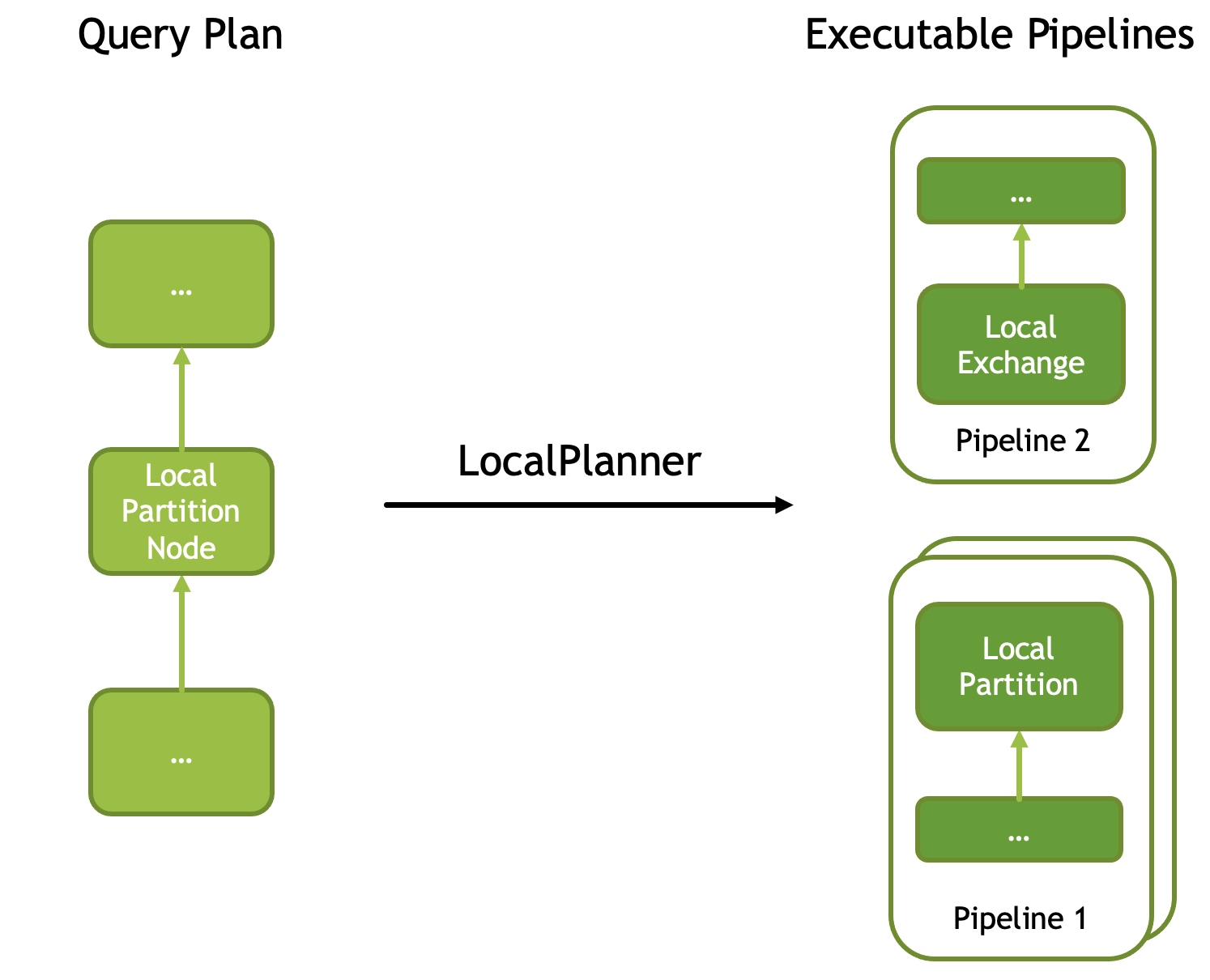
To improve execution parallelism, Velox introduces the LocalPartitionNode, which can run a Pipeline across multiple threads (one instance per thread) in parallel, consuming data in a mutually exclusive manner. Each instance is called a Driver. This operator does not branch in the input plan tree (i.e., it has no multiple sources), but when translated into physical operators, it is split at this node, changing the execution parallelism before and after the split. The corresponding physical operators are LocalPartition and LocalExchange.
 velox-local-partition.png
velox-local-partition.png
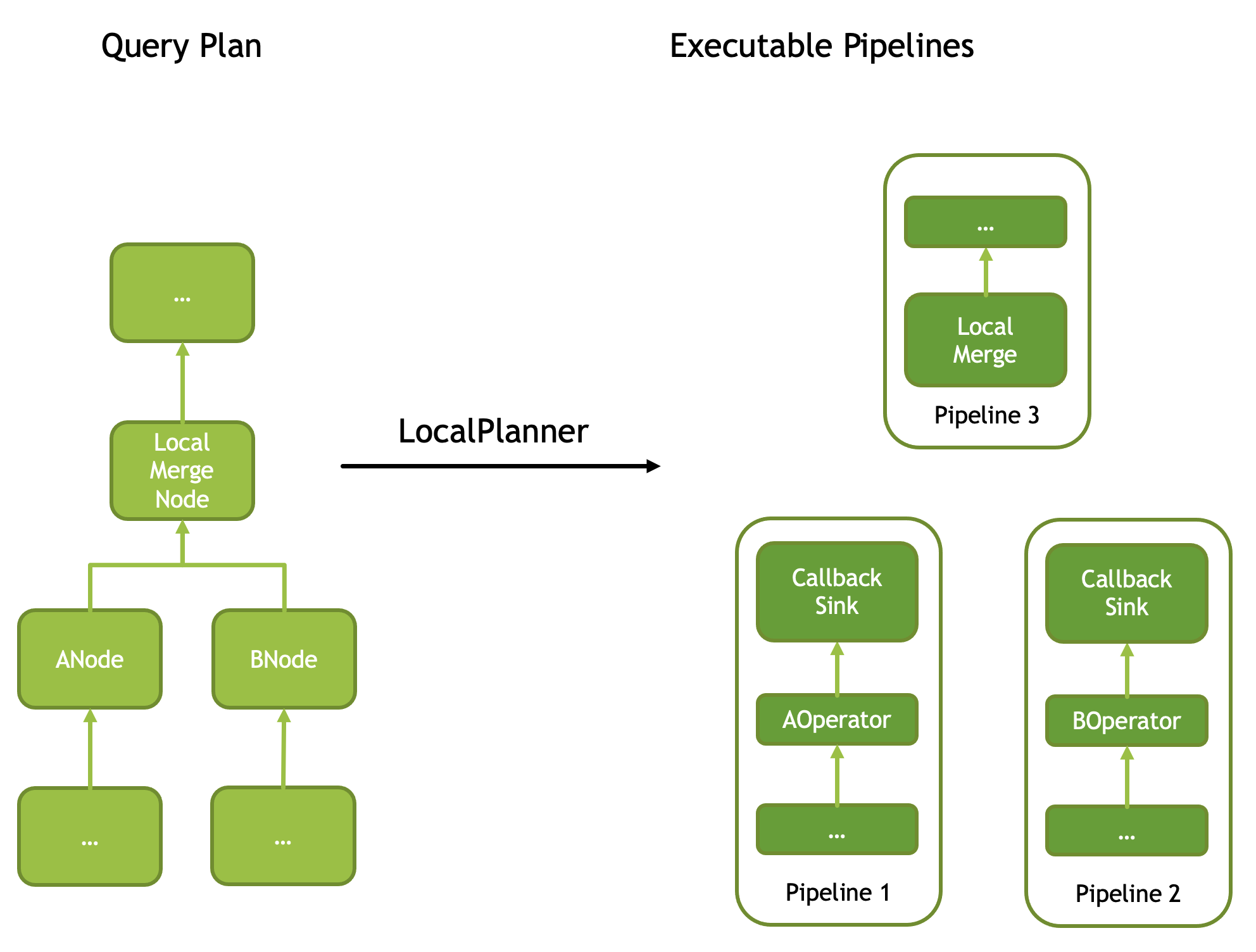
There is another special node called LocalMergeNode, which requires its input to be ordered, and then performs a single-threaded merge sort to make the output globally ordered. Therefore, the consuming Pipeline split by it must be single-Driver. When translated into operators, it corresponds to two operators: CallbackSink and LocalMerge.
 velox-local-merge.png
velox-local-merge.png
In summary, the five PlanNodes mentioned above—HashJoinNode, CrossJoinNode, MergeJoinNode, LocalPartitionNode, and LocalMergeNode—cause splits during translation, i.e., they cut the logical PlanTree into multiple physical Pipelines. Therefore, at the split point, one logical operator is translated into multiple physical operators, assigned to different Pipelines. Each Pipeline has a globally unique number starting from 0: Pipeline ID.
Moreover, LocalPartitionNode can be used to change each Pipeline’s parallelism on demand, where each thread of a Pipeline is executed by a Driver. Each Driver also has a number starting from 0: Driver ID, which is Pipeline-scoped.
The translation of other PlanNodes to operators is basically one-to-one. Those interested can check this page in the official documentation: Plan Nodes and Operators.
Details are expanded below.
Splits
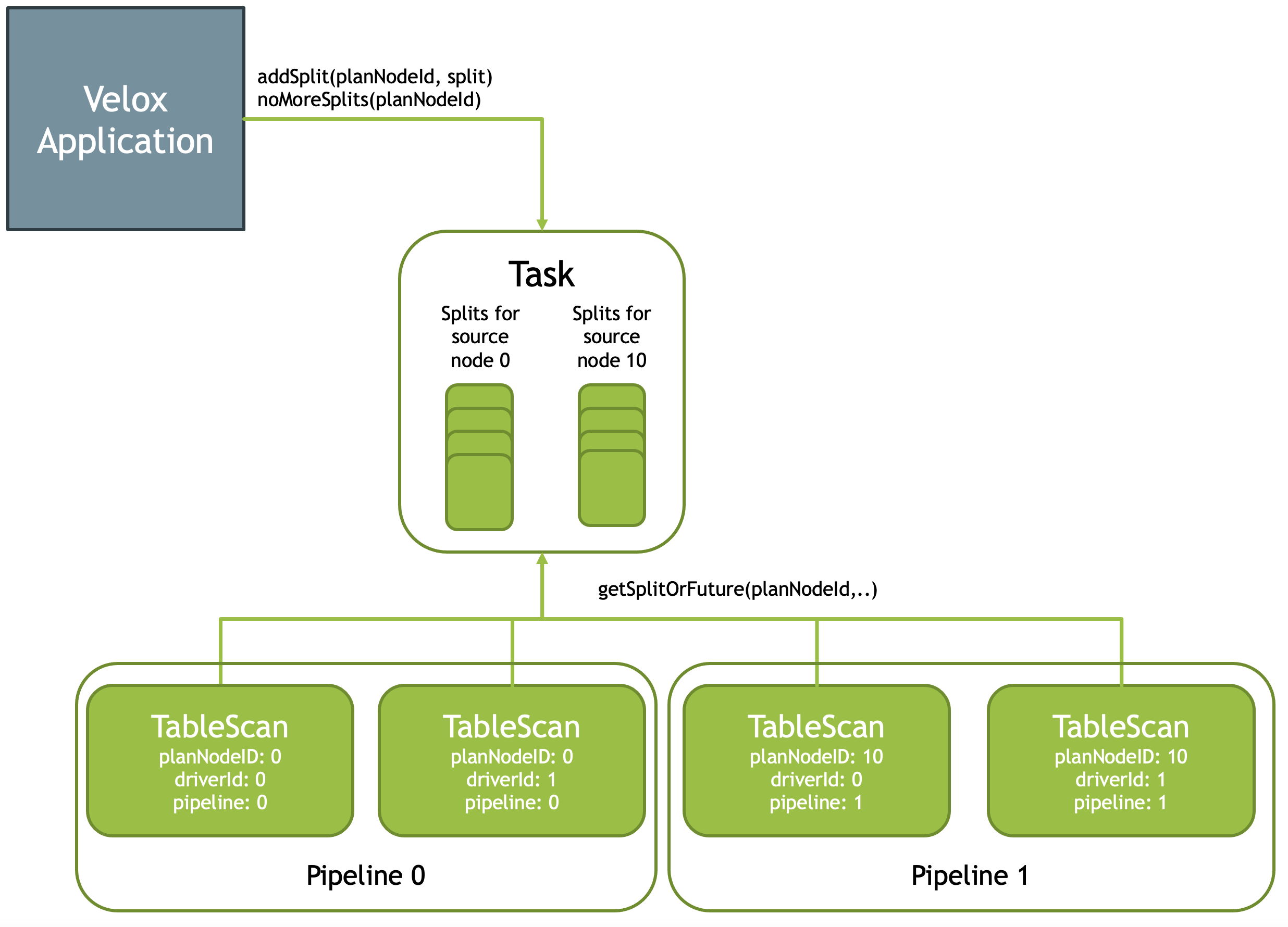
Velox allows the application layer (i.e., the user of Velox) to feed data to Pipelines in the form of Splits (each operator’s input fragment is called a Split), and it can be fed in a streaming manner. Therefore, there are two APIs:
Task::addSplit(planNodeId, split): feed one piece of data to VeloxTask::noMoreSplits(): notify Velox that feeding is complete.
Velox uses a queue to buffer these Splits. At any moment before the data feeding is complete, leaf operators of the Pipeline (yes, external data feeding can only happen at leaf nodes, such as TableScan, Exchange, and MergeExchange) can retrieve data from the queue. The corresponding API is Task::getSplitOrFuture(planNodeId), and the return value has two cases:
- If there is data in the queue, return a Split
- If there is no data in the queue, but the completion signal has not yet been received, return a Future (similar to an IOU; after data arrives, it will be redeemed based on this IOU).
 velox-add-split.png
velox-add-split.png
Join Bridges and Barriers
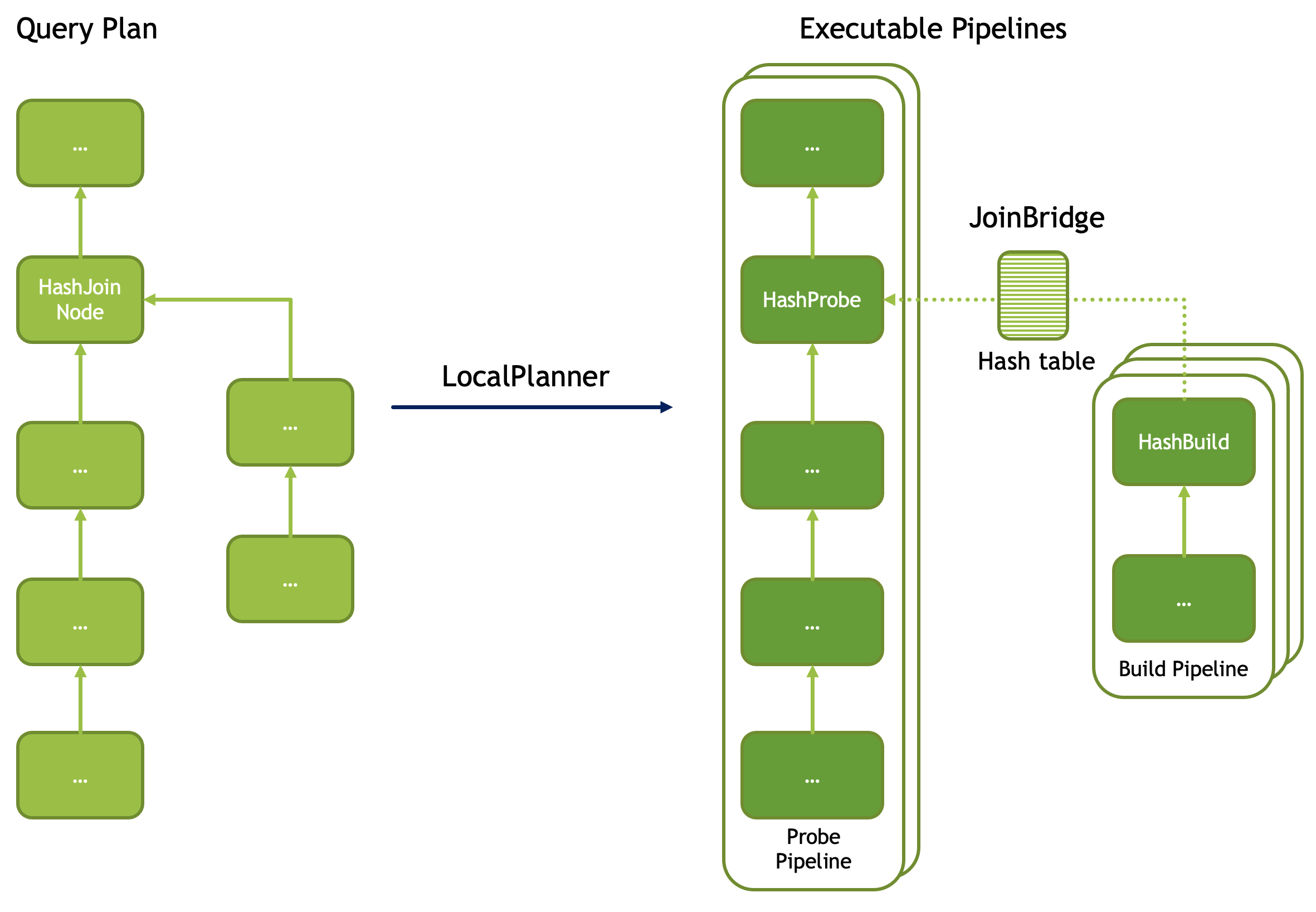
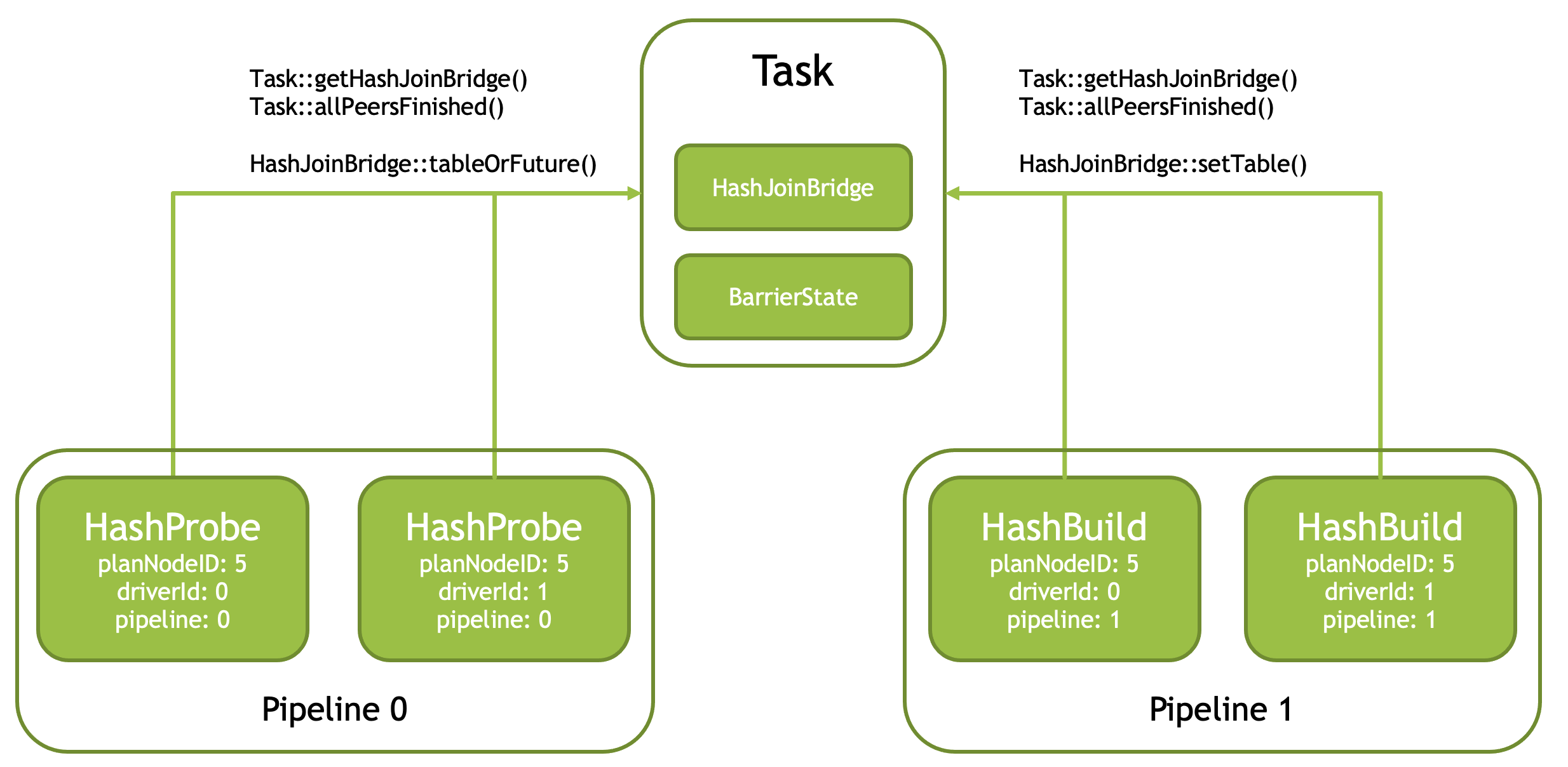
Join (HashJoinNode and CrossJoinNode) is translated into XXProbe and XXBuild operators, which communicate data through a shared Bridge. Both sides of the Pipeline can retrieve this shared Bridge via the Task::getHashJoinBridge() function based on the PlanNodeId.
To increase build speed, the build-side Pipeline usually uses multiple Drivers for concurrent execution. However, since there is only one Bridge, each Driver can call Task::allPeersFinished() (internally implemented using a BarrierState structure) when finishing to determine whether it is the last Driver. If so, it merges the output of all Drivers and sends it to the Bridge.
Of course, in the case of RIGHT and FULL OUTER join, the probe side also needs to feed unmatched data to the Bridge. At this time, it also needs to be handled by the last Driver, so the Task::allPeersFinished() function is also required.
 velox-hash-join.png
velox-hash-join.png
Let’s look at the splitting details of Join operators in detail. Taking HashJoin as an example, when Task splits the PlanTree, it converts one logical HashJoin operator into a pair of physical operators: HashProbe and HashJoin, and uses an asynchronous mechanism for notification: after HashJoin is completed, it notifies the Pipeline where HashProbe resides to continue execution; before that, the latter is blocked and waiting.
velox-join-bridge.png
As shown in the figure above, when each Pipeline is instantiated (logical PlanNode to physical Operator), it can be generated in multiple copies for parallel execution, consuming data in a mutually exclusive manner. Moreover, the parallelism granularity of each Pipeline can be different. For example, in the figure above, the Probe Pipeline is instantiated into two copies, while the Build Pipeline is instantiated into three copies. Moreover, the last Pipeline to finish running in the Build Pipeline group is responsible for sending data to the Probe Pipeline through the Bridge.
Exchange Clients
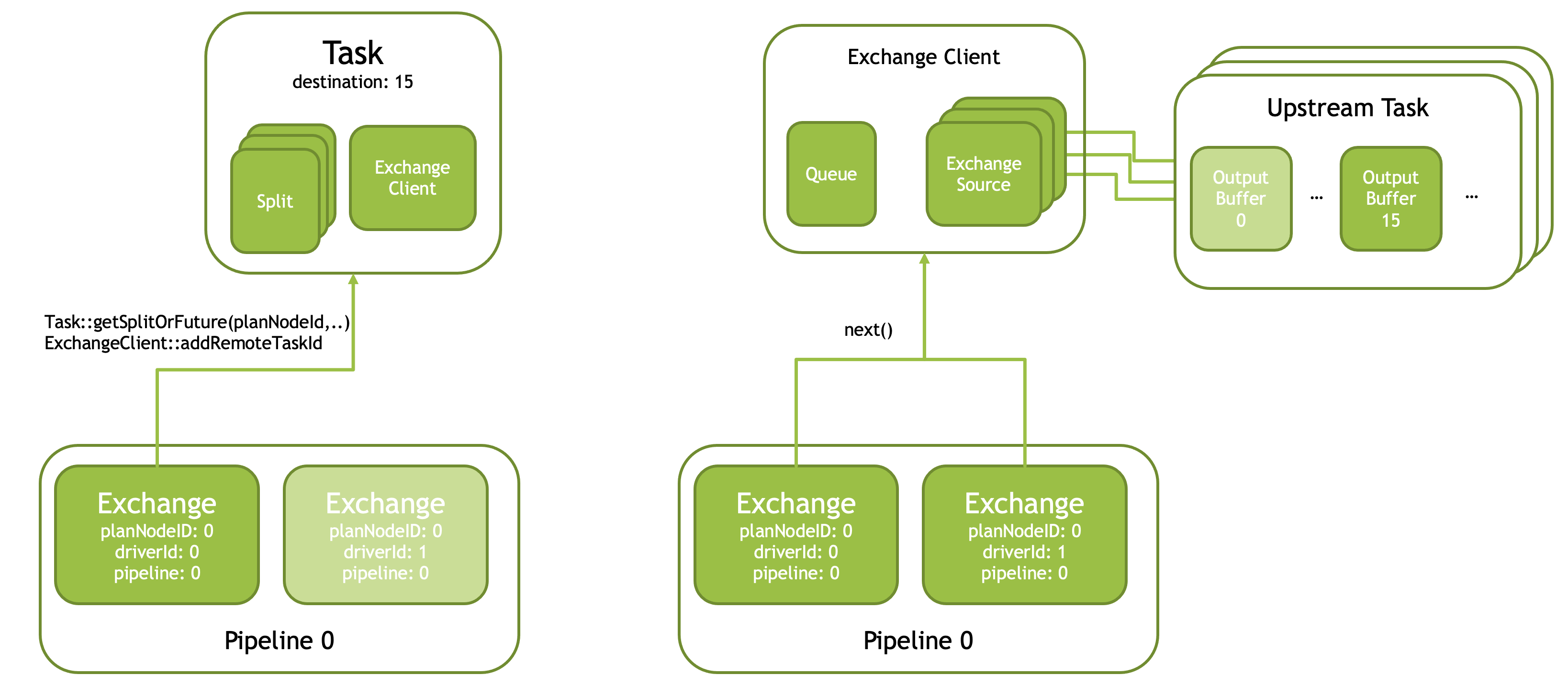
Velox uses Exchange Clients to fetch data from remote workers. It is divided into two steps:
First, the Exchange operator of the first Driver (driverId == 0) in the Pipeline obtains a Split from the Task and initializes a shared Exchange Client.
Second, the Exchange Client will construct an Exchange Source for each upstream Task, pulling data from each upstream Task’s same Partition (Partition-15 in the figure) in parallel, and placing it in the Client’s Queue. Each Driver of Exchange will pull this data from the queue.
The logic of how to pull data from the upstream Task needs to be custom implemented by the user with ExchangeSource and ExchangeSource::Factory. Each ExchangeSource accepts a string ID of an upstream Task, a Partition number, and a queue as parameters. Then it pulls data of that Partition from the upstream Task and puts it into the queue.
 velox-exchange-source.png
velox-exchange-source.png
The rest of the article is available by subscribing to my column:
Xiaobot - Facebook Velox Task Analysis
This is a paid subscription column on Xiaobot. Here is the column link: https://xiaobot.net/p/system-thinking
Xiaobot is a paid subscription platform inspired by foreign newsletters, focused on writing, except it replaces email with WeChat. I currently plan to launch several series around “systems”: Graph Database 101 series, Daily Database Learning series, System Good Reads series, Reading Notes series, Data-Intensive Paper Reading series. “Systems” refers to database systems, distributed systems, human organizational systems, and any system with traceable patterns and discoverable laws. By studying system architectures and borrowing from system organizations, we can make our own cognition systematic. I guarantee at least two updates per week. The current price is 32 RMB per quarter, as a benefit for early subscribers. If someone subscribes to this column through your referral, you can get 30% of their subscription fee. See the column introduction for sharing details. If you have any suggestions or system articles you’d like to see, feel free to leave a comment~
References
https://facebookincubator.github.io/velox/develop/task.html

