概述
Bw-tree 是 2013 年微软发表的相关论文提出的数据结构。考虑到多核机器和 SSD 日趋普及,结合两大存储引擎 B±tree 和 LSM-tree 特点,提出了一种 latch-free、delta update、log structured 的 B族树 —— Bw-tree。
由于上述论文在实现细节上语焉不详,cmu 几个作者在 2015 年时实现了一版基于内存的 Bw-tree,然后又发表了一篇论文,补充了一些实现上的细节,并将代码开源在了 github 上,称为 open bwtree。
例行地总结下(太长不看版),Bw tree 的主要特点有:
- 总体分三层:bwtree 索引层,缓存控制层和 Flash 存储层。
- bwtree 在整体上是一棵 B+ 树,同时借鉴了 B-link 树的思想,每个节点存在一个指向右兄弟的 side pointer。
- bwtree 在单个树节点上表现为类似 LSM-tree 的 Log-Structure,每个逻辑节点由 a base node + a delta records chain 组成。
- bwtree 实现 latch-free 的核心数据结构叫 Mapping Table,通过 CAS 进行 installing 操作,修改一个 mapping entry 可以同时完成多个逻辑指针的修改。
- bwtree flash 层也使用 Log-Structure Store (append only)对逻辑页的物理存储(base page 和 delta record)进行管理。
作者:木鸟杂记 https://www.qtmuniao.com/2021/10/17/bwtree-index, 转载请注明出处
缘起
新数据结构的设计往往是为了适应硬件的变化。那么近些年,硬件层面有什么变化趋势呢?一方面,在单核性能压榨到极致后(摩尔定律失效),单机多核架构成为一个主要发展方向,但传统基于锁控制并发的数据结构难以充分利用多核性能。这是因为,过多的锁会导致频繁的等待和上下文切换。另一方面,闪存(Flash)的价格越来越便宜,逐渐成为主力存储类型。但闪存有其独特读写特点:顺序写比随机写快几倍,随机读并发要远强过传统磁盘。
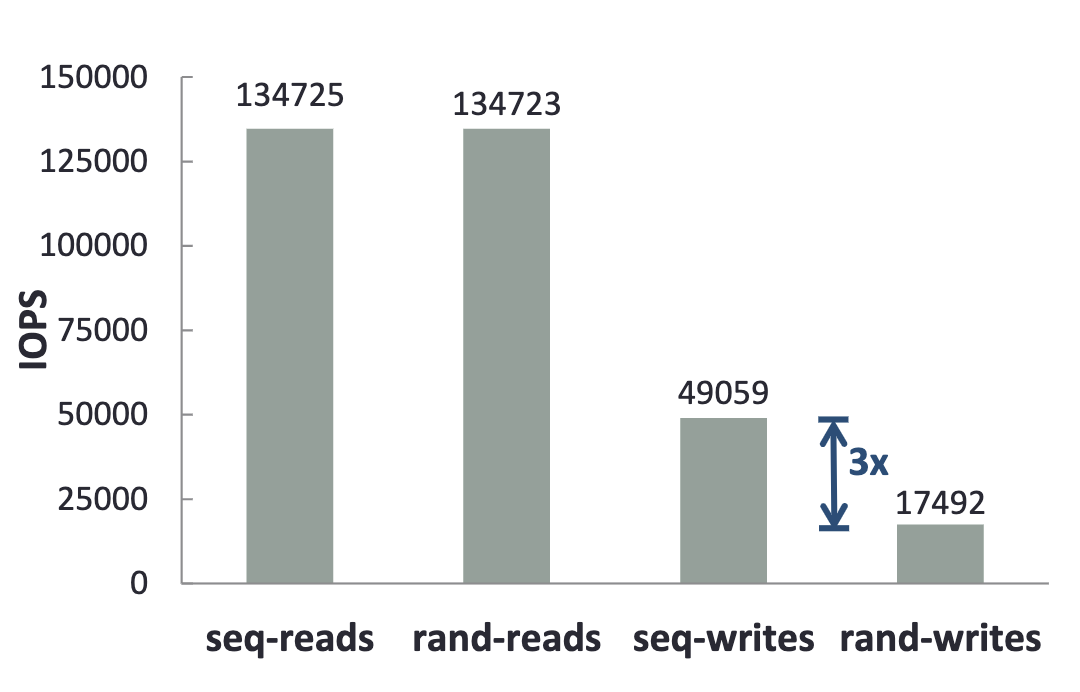 flash 读写性能对比
flash 读写性能对比
针对上述两个观察,微软设计出了 bwtree。bwtree 在内存中使用无锁结构进行增量更新:
- 无锁结构能够减少上下文切换,提高并行吞吐。
- 增量更新避免了原地更新引发的 cache miss。
在外存中使用 Log Structure Store 管理物理数据存储:
- 追加写能够充分利用闪存顺序写速度快、吞吐高的特点。
- 虽然可能带来更多随机读,但正好闪存随机读并发更高。
架构
bwtree 的架构图如下:
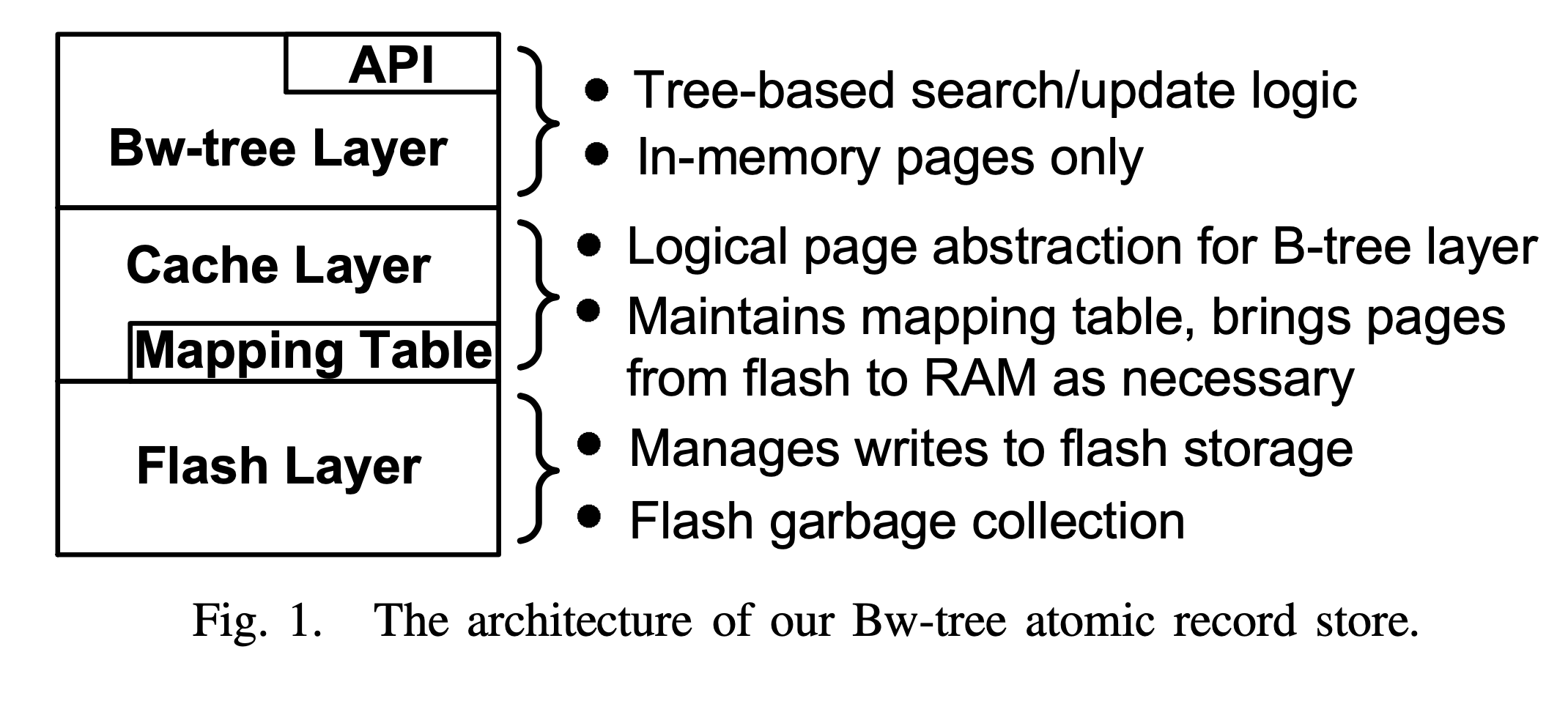 bwtree 架构图
bwtree 架构图
bwtree 总体上分三个层次,逻辑上的 Bw-tree 索引层,物理上的 Log Structured Store 存储层和沟通两者的中间缓存层。缓存层使用一个核心数据结构——映射表(Mapping Table),记录 Page ID 到物理指针的映射,并控制数据在内存和闪存间移动。
Bw-tree 索引
Bw-tree 对外提供 record(key value)级别的接口,整体结构如下图。
Bw-tree 的节点(Node)是弹性可变的,由一个基础节点(a base node) 和一个增量记录链(a delta records chain)组成。所有对节点的修改,包括插入(insert)、更改(modify)和删除(delete) ,都会以增量记录(delta record)的形式追加到链表头。
Bw-tree 中指针包括两种:节点内的物理指针(Physical link)和节点间的逻辑指针(Logical link)。逻辑指针即 page id,需要配合 Mapping Table 使用,因为后者记录了 page id 到物理指针的映射。物理指针,在内存中表现为 pointer,在闪存上表现为文件系统 or 块存储上的地址。Bw-tree 节点,如果在内存中,便通过内存指针链接到一块;如果刷到闪存上,就会通过物理地址串在一起。Bw-tree 节点间的逻辑指针,即 page id,是能够进行 CAS 方式进行并发控制的关键,后面会详细说原因。
注:下图中的 Delta node 叫法不太科学,叫 Delta record 更合理些,因为其保存的信息粒度比 node 细要一些,一般就是单个 record 级别。
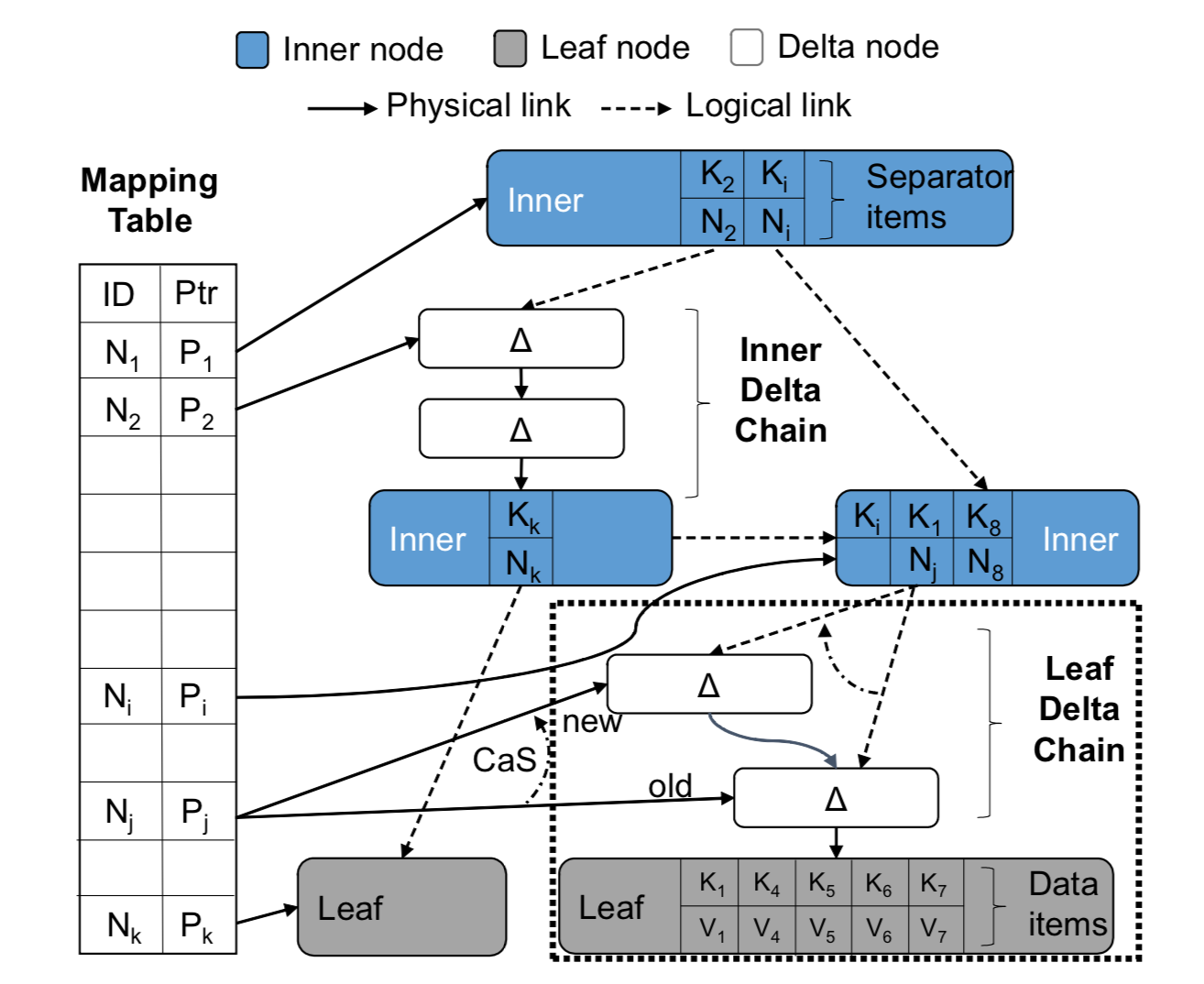 cmu 论文中 bwtree 索引示意图
cmu 论文中 bwtree 索引示意图
Delta record 是 Bw-tree 中很重要的一个数据结构。主要有两种类型,一种是针对叶子节点(Leaf Node)的 kv 增量修改;一种是针对中间节点(Inner Node)的树结构修改。Delta record 中有几个比较重要的字段:low Key,high Key 和 side pointer。
我们不妨站在设计者的角度考虑一下,delta record 应该包含哪些信息?简单罗列下:
- 包含必要的增量信息(kv 值),使之能 apply 到原节点。
- 包含一些冗余信息(low key,high key),使之对查找进行优化。
- 包含一些指向(借鉴 B-link 的 side pointer),使之能够在树结构调整时不影响并发的扫描。
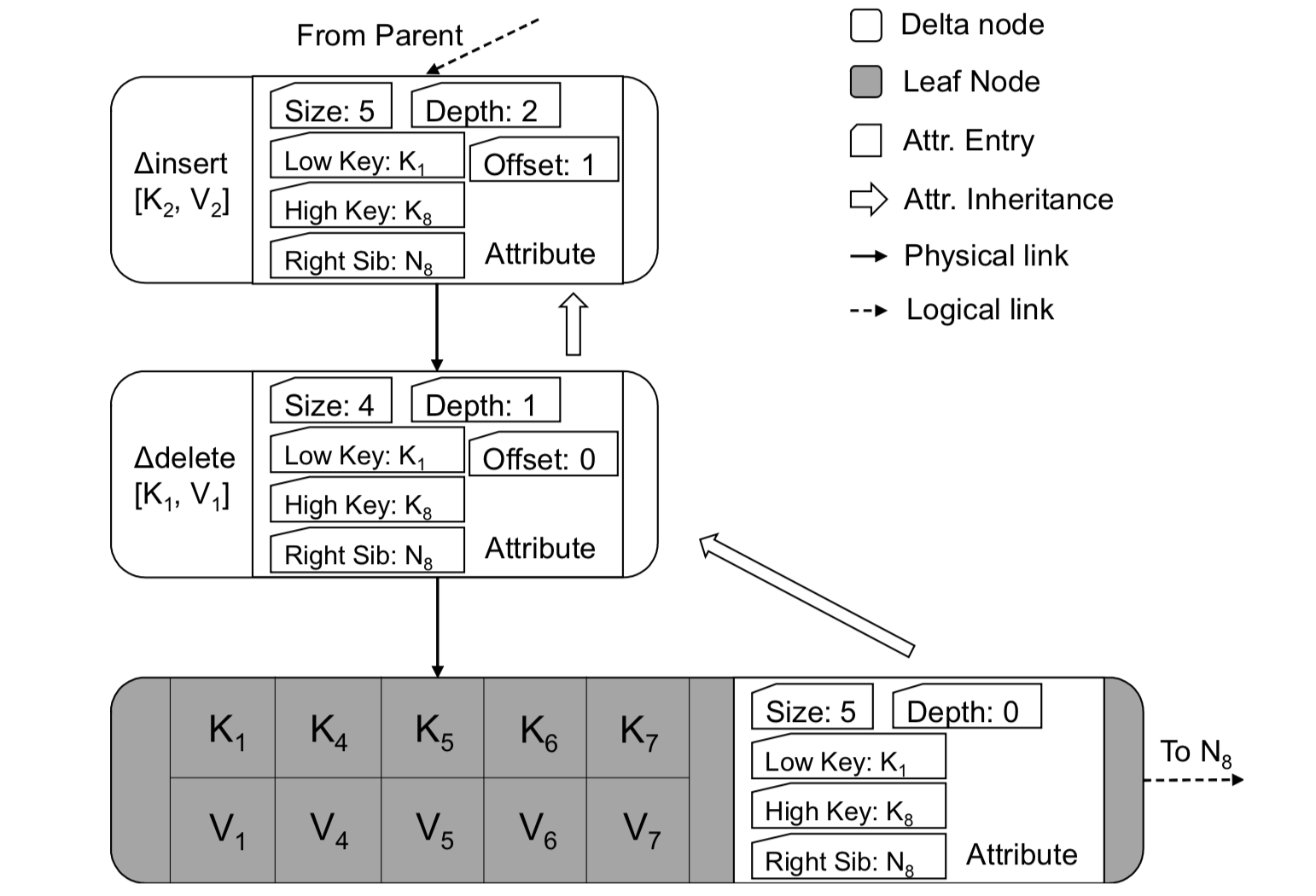 bwtree 逻辑节点
bwtree 逻辑节点
下面来通过一些典型的场景来串一下上述设计。常见的场景有两个,一是只针对单个节点的修改(追加包含 kv 的 delta record),一般是针对叶子节点;一是针对树结构的大范围修改,一般是由于新增或者删除太多引发的子树的分裂与合并,叶子节点和中间点都会涉及。
单节点操作
对于单个节点的操作主要包含更新(插入、删除、更改),查询(点查,范围查)和合并(consolidation)。其中,更新操作都是通过引入增量记录来完成,点查会从头开始遍历增量链直到基础节点,范围查会提前准备好节点对应的 kv vector,合并本质上是节点内的 compact。
单个节点改变一般只发生在叶子节点上,其类型都是对于单条记录(一个 kv)的修改操作引起的,包括:插入、删除、更改。Bw-tree 将这些修改做成一条 delta record,追加到节点内的修改链上,之后修改映射表中的链表头指向,完成修改。
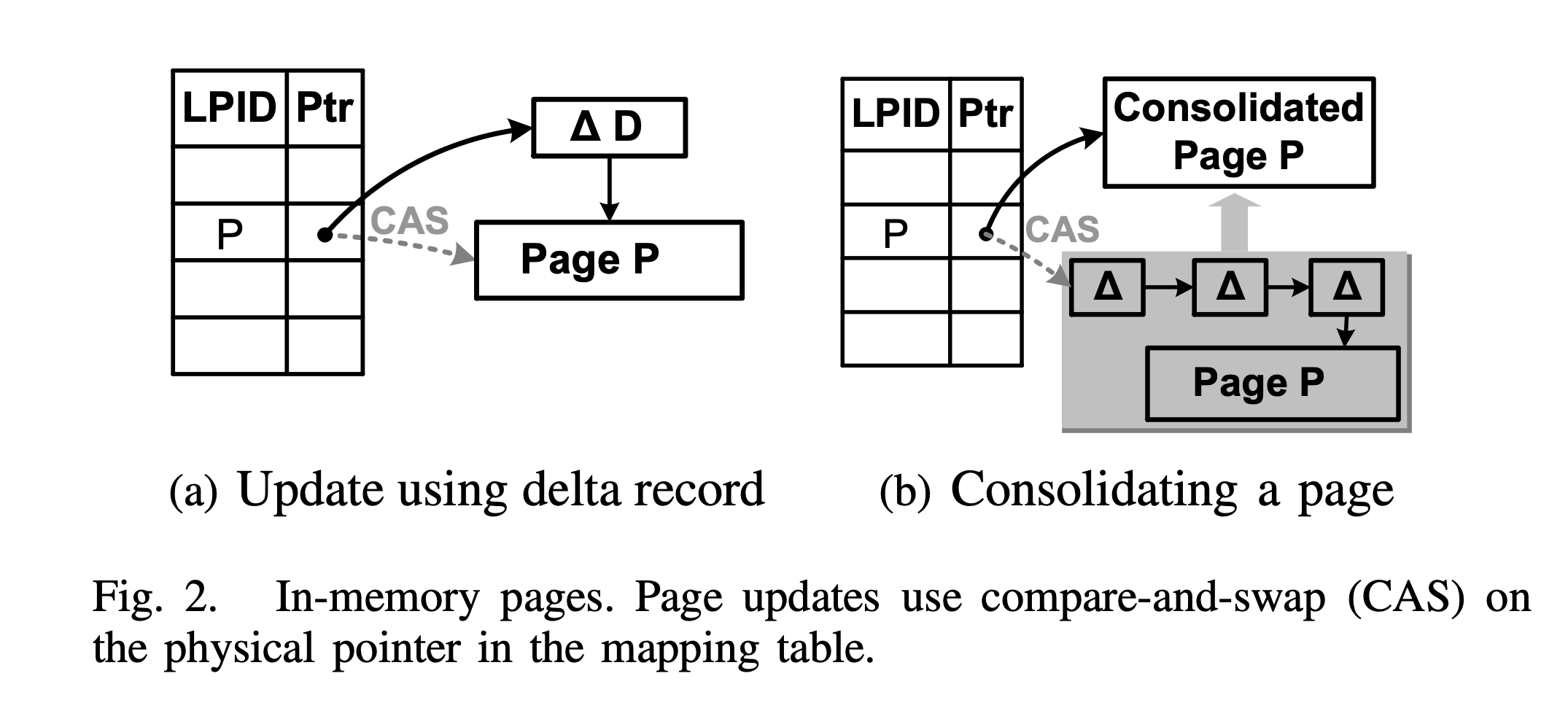 bwtree 单节点操作
bwtree 单节点操作
如上图 a,增量修改 Page P 时,其步骤如下:
- 在内存中新申请一个增量记录(图中 △D)。
- 给其赋值,包含增量信息(如修改类型、待修改 KV),查找优化信息(如 low key,high key)以及指向当前增量链的物理指针。
- 通过 CAS 操作,修改 Mapping Table 中对应项进行 installing,使之指向新的增量链的头。
对于单节点,为了释放空间,还会进行合并操作(consolidating),如上图 b,步骤如下:
- 在内存中新申请一个页。
- 将增量记录和基础页合并,拷贝到新申请的页中。
- 通过 CAS 操作,修改 Mapping Table 中对应项进行 installing。
合并操作有点类似于 LSM-tree 中的 compact,只不过粒度更小。
树结构变化
树结构变化,微软论文中称为SMO(index structure modification operation),包括分裂(split)与合并(merge)。由于一次树结构调整,难以通过单个 CAS 操作来完成,因此 Bw-tree 将其分解为多步。但为了保证调整中间状态时节点的对外可见性,Bw-tree 借鉴了 B-link tree 的思想:
- 每个节点维护了一个右指针(side pointer),指向右边兄弟节点。
- 每次分裂,只允许向右边分裂。
其作用在于,即使新分裂的节点的索引没有加入父节点,仍然可以通过前驱节点的右指针来访问到。
即,虽然子节点分裂了,但藕断丝连,仍然通过指针串在一起。
此外,不同于叶子节点的 kv 修改增量,中间节点的修改增量是一些特殊增量,下面会详细介绍。
树结构调整包括节点分裂(node split)和合并(node merge)。
节点分裂。
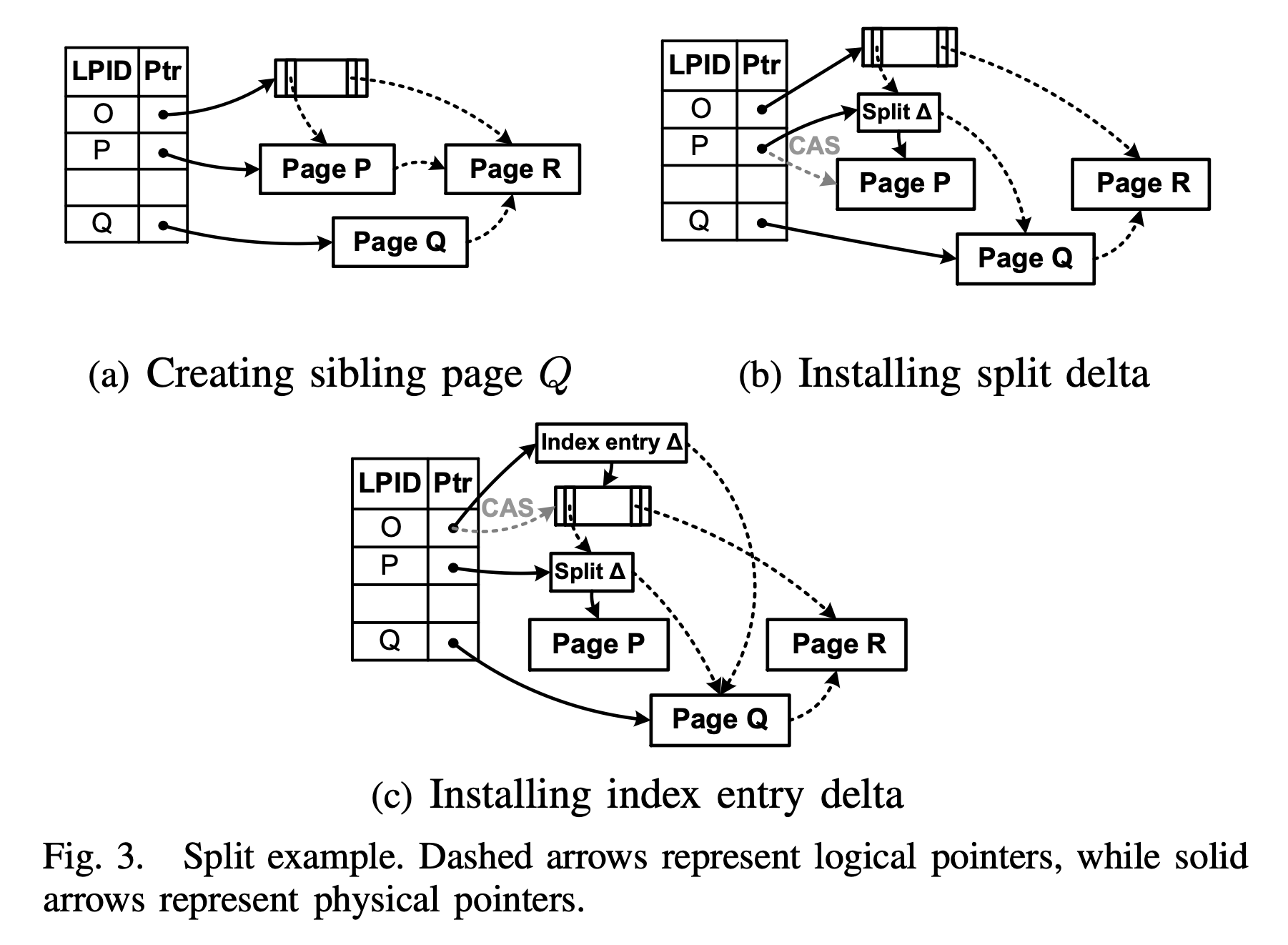 bwtree 节点分裂过程
bwtree 节点分裂过程 Untitled
Untitled
如上图,分裂 Page P,分为两个阶段:child split(对应上图 a、b),parent Update(对应上图 c),每个阶段使用一个 CAS 操作将修改对外可见:
- 创建 Page Q 。容纳 Page P 的右半部分 kv 值,并将其 side pointer 逻辑指向 Page P 右兄弟 Page R。此时,Page Q 对外不可见,即通过 Bw-tree 根节点不可达。
- 安装分裂增量(Split Delta)。为了将 Page Q 对外可见,Bw-tree 引入了一个特殊增量记录:分裂增量。该分裂增量包含原 Page P 中的 split key,用以查找时在 Page P 和 Q 间进行路由;同时记录下 Page Q 作为其 side pointer。最后通过 CAS 操作,将分裂增量安装到映射表中。
- 安装索引增量(Index Entry Delta)。Page Q 从 Page Q 分裂后,需要在父节点添加一个 index entry,指向新增的节点 page Q。Bw-tree 通过引入索引增量,来完成这个操作。索引增量中除了包含 SplitKey-PQ 和 Pointer-PQ 外,还包含一个 SplitKey-QR,这样落在
[SplitKey-PQ, SplitKey-QR]间的查询就可以直接路由到 Page Q 上。
虽然图中各种指针看起来眼花缭乱,但理清他们只需要把握几个特点:
- 实线是真实物理指针,虚线是逻辑指针,即 Page ID。
- 节点内的物理指针在增量记录创建时完成,Mapping Table 中物理指针通过 CAS 操作来更新。
- 更新完 Mapping Table 中的记录后,图中的虚线指针就随之改变了指向。
节点合并。
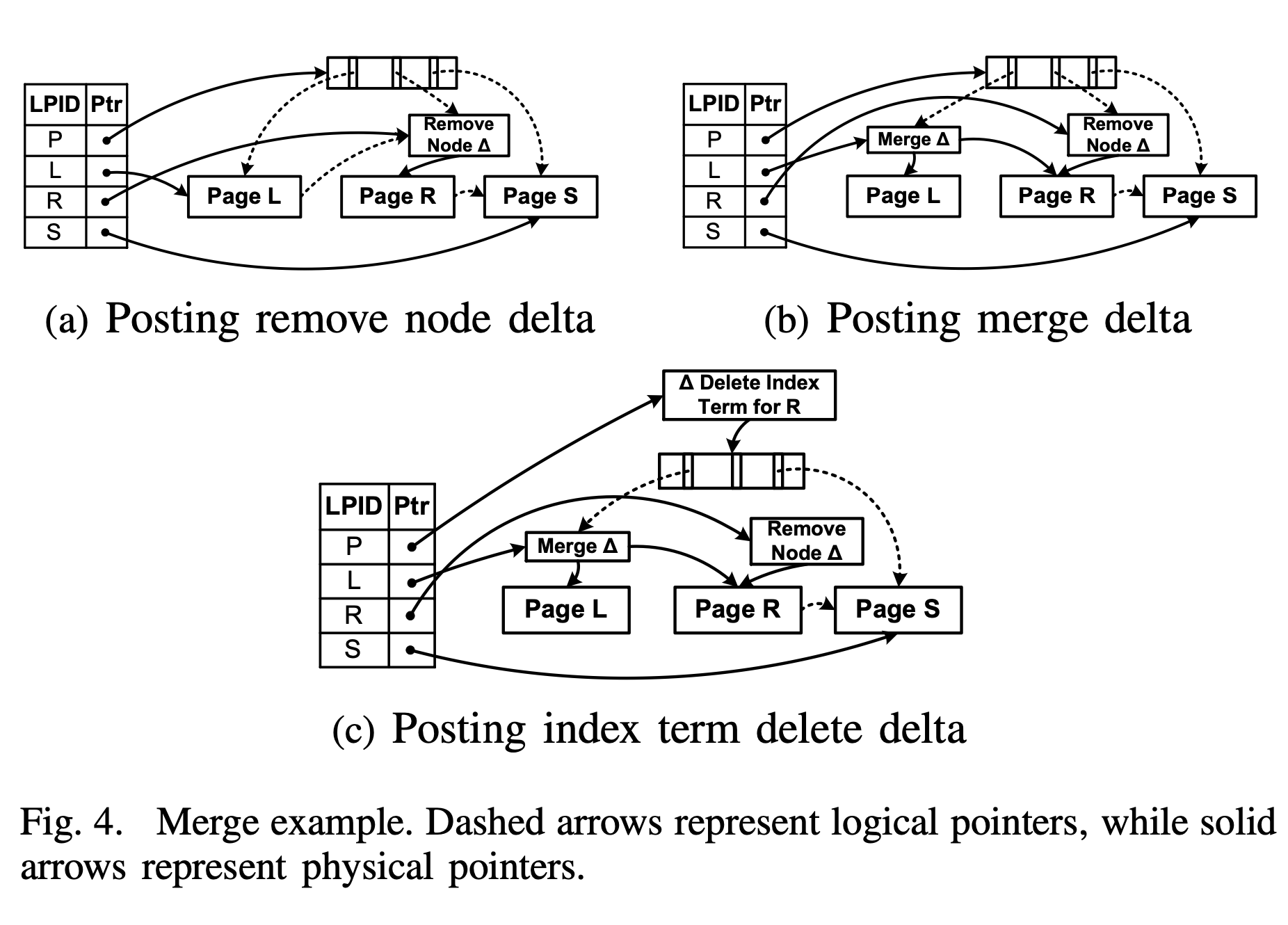 bwtree 节点合并过程
bwtree 节点合并过程
如上图,将 Page R 合并到 Page L ,分为三个阶段,每个阶段包含一个 CAS 操作:
- 标记删除(Marking for Delete):引入移除节点增量(Remove Node Delta),追加到 Page R ,然后通过 CAS 操作更新映射表中的 Page R 对应值,将 Page R 标记删除。但此时,Page R 仍然可以通过 Page L 的 side pointer 访问到,即移除节点增量只屏蔽了来自父节点的访问。
- 合并孩子节点(Merging Children):引入节点合并增量(Node Merge Delta,遵从论文中名字,但是和 Remove Node Delta 命名不对称啊,不知道有什么特殊考虑没)。该增量记录了到 Page L 和 Page R 的物理指针,然后通过 CAS 操作,更新映射表中 Page L 的值,即该增量是逻辑页 L 的一部分。
- 父节点更新(Parent Update)。引入索引删除增量(Index Term Delete Delta),追加到父节点,逻辑删除其中原先指向 Page R 的 key 和指针,然后通过 CAS 操作,更新映射表中父节点 P 的值。
从图 a 中可以看出,更新映射表中 Page R 的值安装 Remove Node Delta 时,同时修改了两条逻辑指向:
- Page L 指向 Page R 的 side pointer。
- 父节点 Page P 指向 Page R 的 child pointer。
这也是映射表与逻辑指针的意义所在:通过 CAS 修改一个映射表项,达到同时修改多个逻辑指向的目的。
处理冲突
如果有一个节点进行 SMO 操作的同时,另一个线程要进行单节点更新,但与 SMO 操作产生了冲突(比如操作同一个 Page),该如何解决冲突?
一般来说, Bw-tree 会作为一个存储引擎嵌入到 DBMS 中,DBMS 中的事务管理模块会尽量处理外部冲突,将多个 SMO 操作进行序列化(个人猜测)。然后 Bw-tree 来处理 SMO 操作与单节点更新的冲突。
Bw-tree 采用了一种叫 “the help-along protocol” 的方案,即任何线程如果发现有 SMO 操作正在进行,就先去执行 SMO 操作,再去执行自己的操作(增删改查)。即:
- 将 SMO 的优先级提高以确定两类更新(SMO 与单节点更新)顺序。
- 所有线程遇到冲突的 SMO 时,不管是否属于本线程操作,都先去完成 SMO,这样总有一个线程完成 SMO 并得以继续,其他线程则直接放弃。
缓存管理(Cache Management)
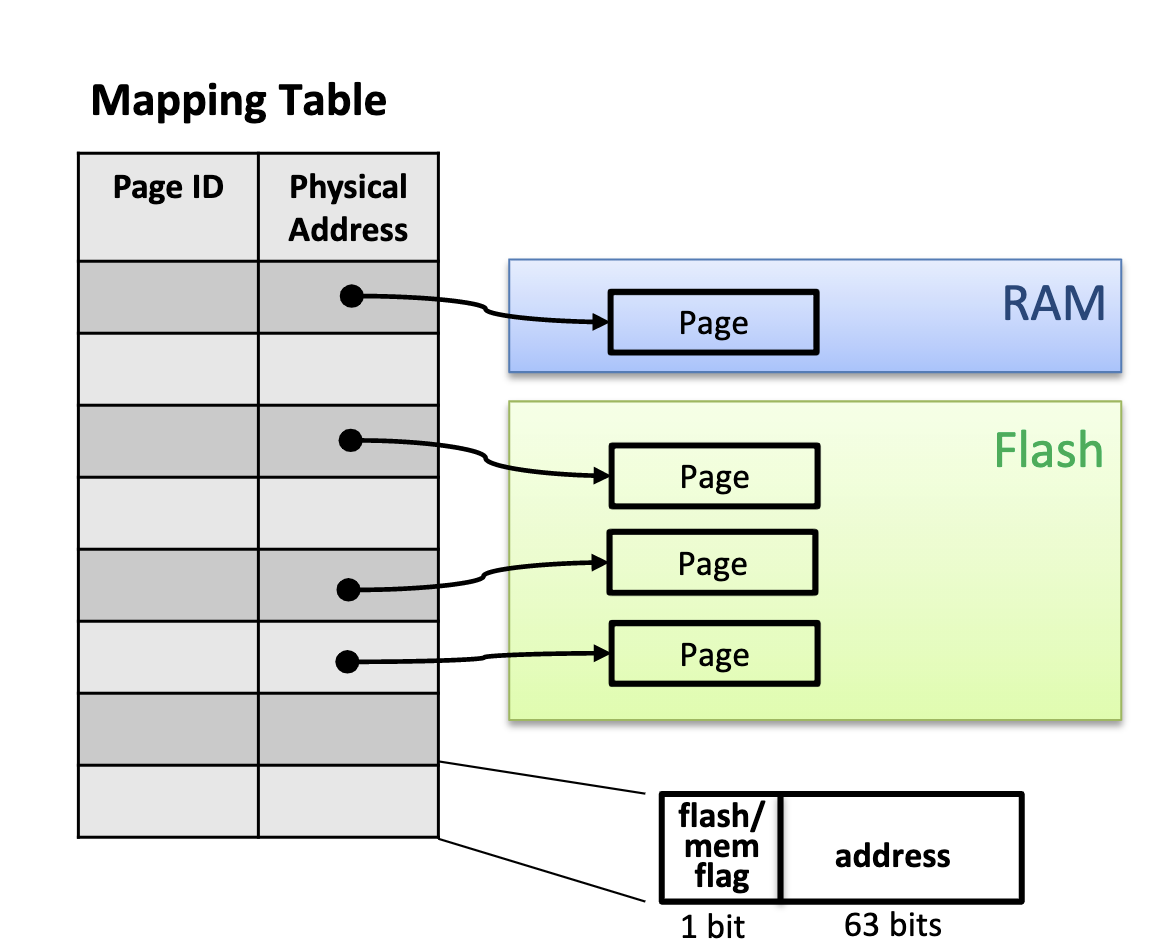 bwtree 映射表
bwtree 映射表
主要功能
缓存层主要功能有:
- 维护映射表(Mapping Table),保存逻辑 PID 到物理地址间的映射。物理地址可能是内存中的指针,也可能是闪存文件系统中的地址。
- 负责页面在内存和闪存之间移动,包括读取(reading)、交换(swapping)、下刷(flushing)。
映射表更新
所有对映射表更新都通过 latch-free 的 CAS 来完成,包括:
- 叶子节点和中间节点的追加增量记录造成的物理指针的变化。
- 页在闪存和内存间交换造成的内存指针和文件地址的替换。
增量下刷
引起缓存中的页下刷的原因有很多种,比如上层事务要求做检查点,比如内存使用达到阈值需要换出。之前提到,一个逻辑页包含一个基础页和一个增量链,并且增量链在阈值范围内还会不断延长,因此对一个逻辑页的下刷不是一次性完成的,也是增量进行的。为此 Bw-tree 又引入了一种特殊的下刷增量(flush delta),记录下刷点,并添加到逻辑页中。这样如果有修改,在下次下刷时,只需要下刷增连链之后的增量记录即可。
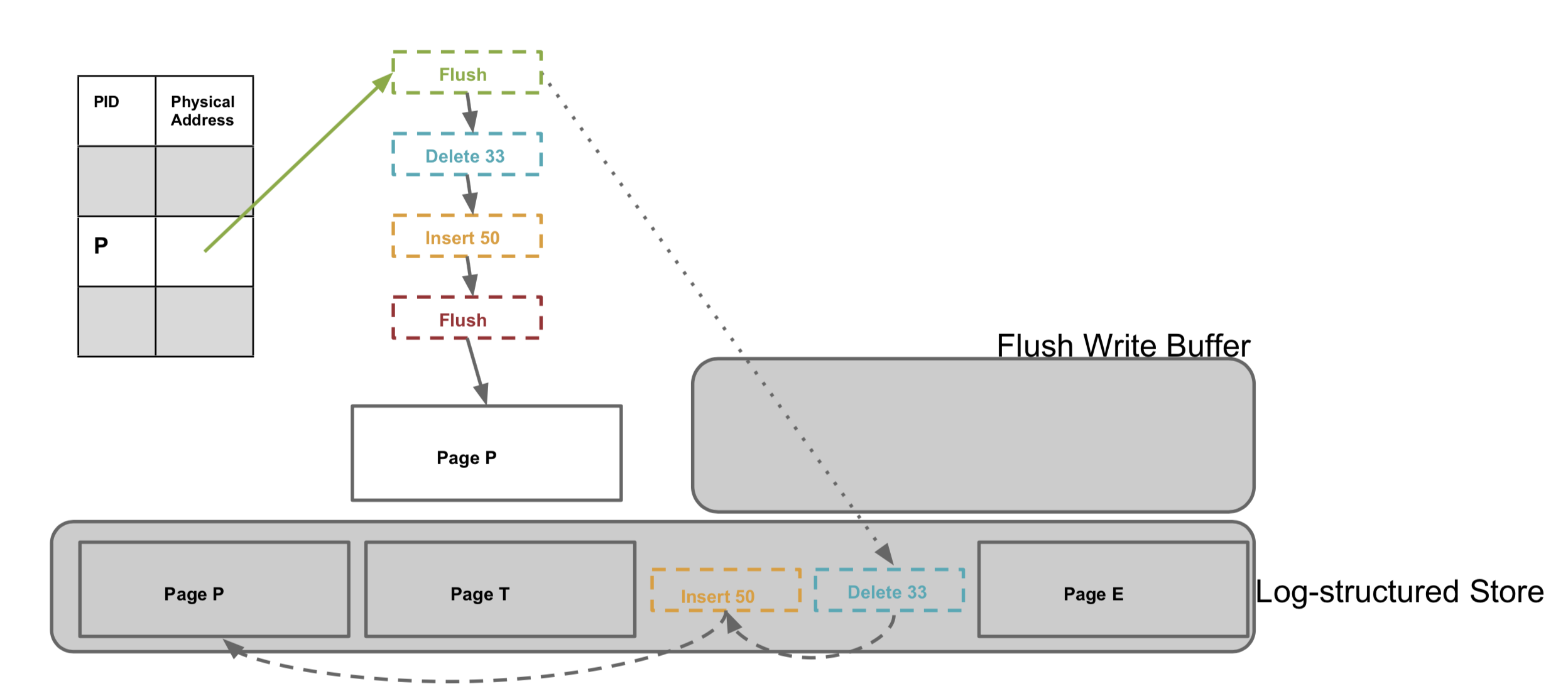 bwtree 存储结构和增量下刷
bwtree 存储结构和增量下刷
闪存层(Log-Structured Store,LSS)
闪存层和内存对应,都是增量刷盘,单个逻辑 page 的数据并不相连,page 内通过文件系统地址串起来。
会使用重写的方式进行垃圾回收,回收时可以将逻辑页的多个部分挪到一块,以减小之后的读放大。
待读
单独读微软的 bwtree 论文,存储和事务部分不太好读懂,是因为本论文只详细了描述了 bwtree 索引部分细节。至于存储和事务部分,得看微软套娃般的另外两篇论文,之后有机会我会再出两篇相关文章:
- 缓存层和闪存层:LLAMA: A Cache/Storage Subsystem for Modern Hardware,http://www.vldb.org/pvldb/vol6/p877-levandoski.pdf
- 事务相关:Deuteronomy: Transaction Support for Cloud Data,https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/Deut-TC.pdf
参考
- 微软 2013 bwtree 论文: https://15721.courses.cs.cmu.edu/spring2017/papers/08-oltpindexes2/bwtree-icde2013.pdf
- 淘宝数据库内核月报 2018/11 期:http://mysql.taobao.org/monthly/2018/11/01

