Snowflake 由甲骨文的两位员工在 2012 年出来创办,一开始就瞄准云原生数仓,因此架构设计(在当时看来)非常“激进”。超前的视野带来超额的回报,Snowflake 在 2020 年正式上市,市值一度高达 700 亿美金,创造了史上规模最大的软件 IPO 记录。
本文我们综合两篇论文:The Snowflake Elastic Data Warehouse 和 Building An Elastic Query Engine on Disaggregated Storage 来大致聊聊其架构设计。
本文来自我的专栏《系统日知录》,如果你觉得文章还不错,欢迎订阅支持我。
这篇文章我早就想写了,但上次在看论文时卡住了——论文信息太多,地毯式的阅读,很快就淹没在细节中,当时也只看了三分之二,就搁置了。上周(20240707)在文章 Spark:如何在云上做缩容时提到了存算分离的 snowflake ,有读者要求写下,于是便重新捡起来。
相比上次 push 的方式,本次采用 pull 的方式:即不是被动的读论文,而是先思考,如果让我设计这么一个云原生数仓,我要怎么设计,会有哪些问题等等。带着这些问题,我再去从论文中找答案,发现效率一下高了很多,也便让这篇文章没有再次难产。
作者:木鸟杂记 https://www.qtmuniao.com/2024/08/25/snowflake-paper/ 转载请注明出处
概述
Snowflake 主要设计目标如下:
- 存算分离:因此存储和计算都能做到弹性伸缩,按实际用量计费
- 多租户:保证多租户之间的隔离性
- 高性能:在1,2 前提下尽可能的提升性能
架构
为了实现上述设计目标,让我们首先看看 snowflake 的整体架构:
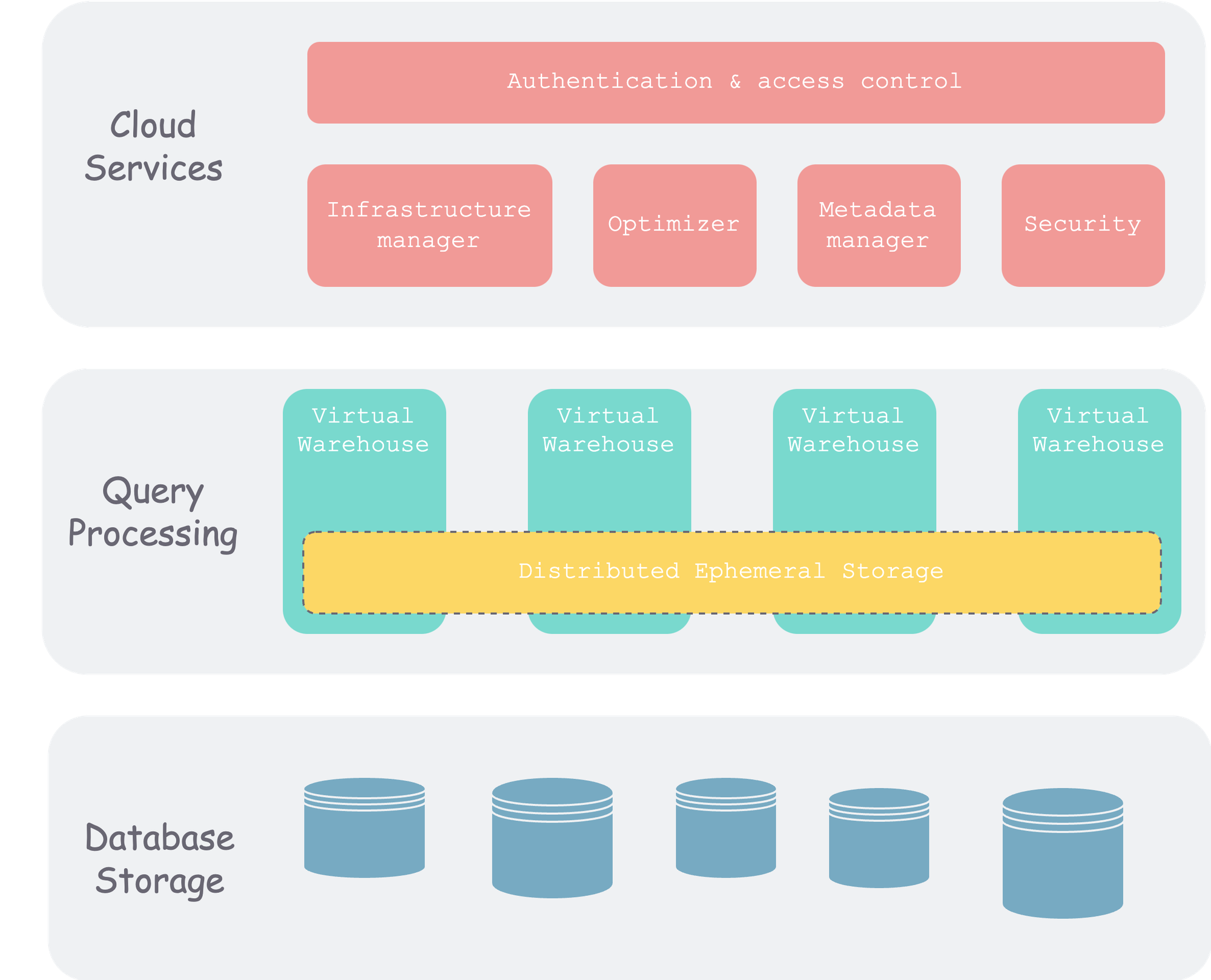
可以看出,snowflake 整体分为三层。除了我们常说的存算两层外,还有一个元信息层。
这也是分布式数据系统经典的分法,我在这个视频中也按照这种分类方法梳理了分布式系统的一些脉络,感兴趣的同学可以去看看。
数据库存储层(Database Storage)
这一层是数据的最终持久化层,最开始时(论文发表时)通常存在各个云厂商的对象存储上。后来也开始支持第三方存储,比如 Apache Iceberg。
当数据写入 snowflake 后,snowflake 会将数据组织成**微分区(micro partition)**的方式,写入对象存储,具体如何做优化、压缩,如何确定大小、管理元信息,我们稍后会讲。
查询处理层(Query Processing)
也就是计算层。Snowflake 使用 **虚拟数仓(virtual warehouse,VM)**来组织计算单元,每个 VM 包含一组计算节点,可以有不同尺寸。不同 VM 之间是隔离的,不会互相影响。
查询处理层里有一个非常重要的缓存层,该层通常以 VM 为单位,以一致性哈希组织(避免节点增删后的数据 shuffle),来缓存对象存储捞上来的数据和算子运算的中间结果。
云服务(Cloud Services)
该层是整个 Snowflake 集群的“大脑”,由一组运行在云上的计算实例构成。包含以下组件:
- 鉴权认证(authentication):多租户
- 基础设施管理(infra management):也就是集群内物理信息管理管理
- 元信息管理(metadata management):主要是数据库、表等 schema 信息的管理
- 查询解析和优化(query parsing and optimization):SQL 解析到执行几个阶段中,除最后执行外都在这里,毕竟这里有全局元信息,便于优化
- 准入控制( access control)
接下来我们重点说说存储层和计算层。
存储层
各家云上最便宜、容错性最好的,无疑就是对象存储了。云上的系统,如果有大规模的数据存储需求,一般都会用对象存储。对象存储也即 blob 存储(不管你存的是啥,人家都当做一段不理解的二进制块来存储),以桶(bucket,也就是 namespace)、对象(object)两级来进行逻辑组织。每个对象都是 path → object 的 kv 对,是拍平的,没有类似文件系统的目录树结构。
对于 Snowflake 的存储系统来说,对象存储需要考虑的特点有:
- 自容错:因此不用再上层进行 replication
- 不可变:因此不能进行原地更新
对象存储本身容错,从而使 Snowflake 无需担心可用性问题,也就不用像传统 share-nothing 的 TiDB 架构,得自己在多机搞多副本,然后还要用 raft 来维持一致性。
微分区(micro-partition)
在表和实际存储中间,数据库通常都会按 block(叫 partition 也行)对数据进行组织,传统的数仓的 block 多为静态的。而 Snowflake 管每块数据叫 micro-partition,其特点是:
- 不太大:几十兆到几百兆间,便于拆分、合并和迁移,也即动态分区。
- 列存:每个 micro-partition 包含一些行,但是内部为了压缩和应对数仓场景,是按列存储的。
- 元信息:会保存每列 min-max 等元信息,以便进行快速过滤。
大致示意图如下,左边是逻辑上的一张表,右边是物理上的数据组织,一张表“横切”为多个 micro-partition,每个 micro-partition 内“纵切”后按列存储。
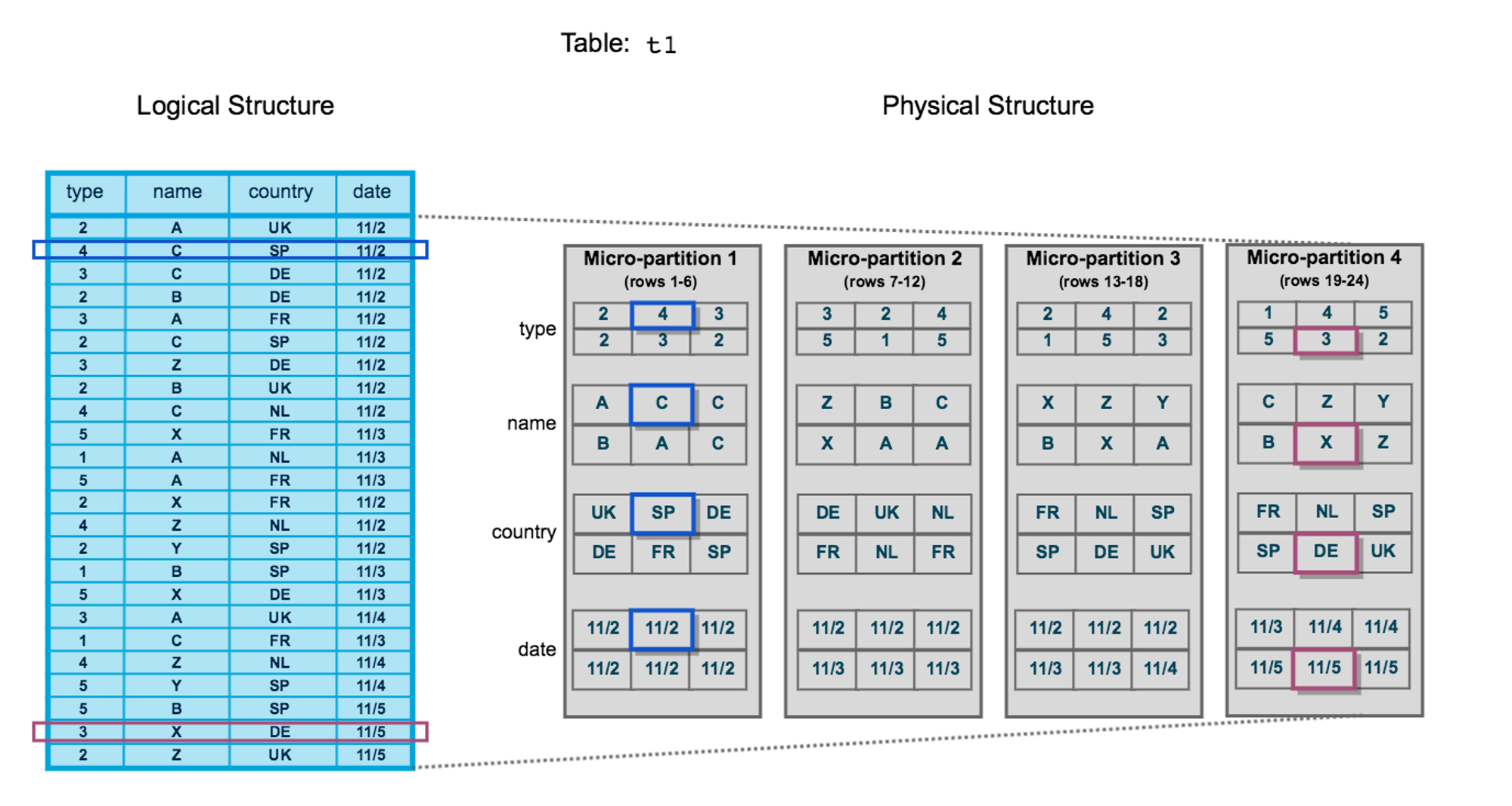
每个 micro-partition 作为一个 object 存在对象存储中。
DML 操作
由于每个 micro-partition 是不可变的,那我们往表中插入、更新和删除行数据时该怎么办呢?
插入:插入最简单,将新插入的数据生成新的 micro-partition 即可。
更新:首先找到被更新的行对应的 micro-partition ,读到 VM 中,修改,然后整体写回对象存储中。这里为了区分新旧 micro-partition,会给每个 micro-partition 文件关联一个版本号。
删除:和更新类似,读取→删除→ 写回,此间也要更新版本号。
基于每个文件版本号,Snowflake 可以做 MVCC 的并发控制,进一步提供 SI 级别的隔离性和时间回溯(time travel)的功能。
整体来看,就是每次一个写事务,就会将系统的版本号推高,并且圈出一个文件集合,构成当前版本号下的一个 snapshot。基于这些 snapshot,我们可以访问任意时间的快照,即时间回溯。
计算层
计算层也就是查询执行层(之前的解析、优化都在云服务层完成了),Snowflake 引入了 VM(Virtual Warehouse)的概念。下面我们梳理下几个概念间的关系:
- 用户:每个用户可以起多个 VM,比如有的 VM 用来做 ETL,有的 VM 用来做查询。
- VM:每个 VM 可以有 XS → XXL 不同的尺寸,表示其包含不同数量、尺寸的计算资源。VM 和 VM 之间是完全隔离的。
- 节点:云上的计算节点,会包含一定的内存和外存(HDD 或者 SSD)
在设计执行层时,一个很重要的点是,是否支持 MPP ?可以粗略的理解为,一个查询语句是否能在多个节点上进行类似 spark 的分布式执行;还是只能局限在一个节点中进行单机执行。后者实现简单,但是吞吐上不去。而数仓通常是大数据量场景,因此多采用前者,当然实现会更负载,因为会在执行时,会涉及多机的的通信,以进行数据的 shuffle(可以参考 spark 中的 shuffle)。
回到 Snowflake 中,也就是一个查询语句是否可以在 VM 中的多个节点执行,从论文中的蛛丝马迹来看,应该是可以的。
除此之外,Snowflake 的计算引擎主要有以下几个特点:
- 列式(columnar):由于数仓场景通常都是“宽表窄查”,因此采用列式执行引擎效率会更高,而且可以充分利用单机缓存和 SIMD 指令加速计算。
- 向量化执行(Vectorized):这里感觉和列式稍微有点混淆,主要是想表达算子间是“流水线”地执行,而非每个算子的输出都物化。
- 推模型(push-based):也即不是用的经典的基于拉的火山模型,将控制和数据解耦,能够充分利用缓存,效率也更高。当然,实现会更复杂一些。
伸缩
每个 VM 的大小可以按用户的需求进行动态的伸缩。比如一个任务比较着急,就可以多加计算节点,用较短时间跑出来。由于 Snowflake 是按照 机器*时间 计费的,因此对于同一个 query 来说:多机器快速跑和少量机器慢慢跑,费用是差不多的,但前者无疑更快,利好用户。
缓存
执行引擎用到的数据主要包括两块:
- 输入数据:即执行计划各个叶子节点需要加载的数据,需要从远端(对象存储)中拉取。
- 中间数据:执行计划就是由算子组成的 DAG,每个算子会读入数据,进行“变换”后,产生输出,为下一个算子所用。
上述两种数据都有被复用的可能,尤其是输入数据,即某个 table 的微分区被访问后,后续一段时间内很有可能被再次访问(局部性原理)。因此,可以将其缓存在 VM 节点中的内存或者外存(HDD,SDD)中。单机容量有限,因此 Snowflake 会将 VM 内所有节点的内外存组成一个缓存池,并以一致性哈希算法(可以参考这篇文章)来维护缓存,并且是 lazy 的一致性哈希,可以避免在 VM 中有节点变更时,数据频繁的迁移的。
参考
- The Snowflake Elastic Data Warehouse
- Building An Elastic Query Engine on Disaggregated Storage
- snowflake 官方文档
- The Impact of DML Operations with micro-partitions in Snowflake

