在Google I/O 2022 大会上,Google Cloud 发布了兼容 PostgreSQL 标准的云原生数据库 AlloyDB(注:Alloy 意为合金),号称比 Amazon 的同类产品(Aurora?)快两倍,这个口号,对老用户来说,应该不足以让其迁移,但对于新用户来说,确有一些吸引力。
由于笔者主要做存储,下面基于谷歌这篇介绍 AlloyDB 存储层博文,剖析下 AlloyDB 存储层架构,看看其设计有何亮色。
整体架构
在整体上,AlloyDB 分为 Database 层和存储层。其中,DB 层用以兼容 PostgreSQL 协议,解析 SQL 语句,转化为读写请求,发送给存储层。对于存储层,又可以细分为三层:
- log storage 层:DB 层会将写入转换为操作日志,或者说 WAL 写入存储层。log storage 负责这些日志记录的高效写入和存储。
- LPS 层:Log Processing Service,LPS,日志处理服务层,消费 log storage 层的 WAL ,生成 Block,本质是一个物化(Materialized)的过程。
- block storage 层:对应单机 PostgreSQL 的 block 层,用于服务查询,通过分片(shard)提供并行度、通过冗余(replication)保证跨区容错性。
作者:木鸟杂记 https://www.qtmuniao.com/2022/05/15/google-alloydb-storage 转载请注明出处
 database-storage.png
database-storage.png
即,AlloyDB 将其存储层进一步拆分为两个存储层和一个计算层,以拆解复杂度:
- log storage 层,承接 DB 层过来的写入请求。但只支持追加(append only)写入,因此可以做到低延迟、高可用,并且可以用 LSN 做读写并发控制、分布式事务。
- block storage 层,承接 DB 层过来的查询请求。虽然文中没提到,但盲猜其提供的 block 仅支持单次写多次读( write once then becomes immutable),以方便做缓存和版本控制。
- LPS 层,两个子存储层间数据的搬运工,同时负责 block 的生成和读取,无状态,可伸缩。可根据负载、统计信息等各种信号,动态增删实例以追踪变化的负载。
存储层本质上是要提供 block 的读写服务, AlloyDB 拆出 log storage 层负责写、block storage 层负责读。基于日志服务物化实现存储层,在分布式数据库领域,算是一个经典(甚至老旧)架构,但如何将其高效组合,还是比较考验工程能力。
基于日志服务的另一个好处是,可以对同一份数据使用不同的方式进行物化,以支持不同的工作负载(workload),比如将数据按需物化为针对 TP 和 AP 优化的数据格式,即,支持 HTAP。
读写流程
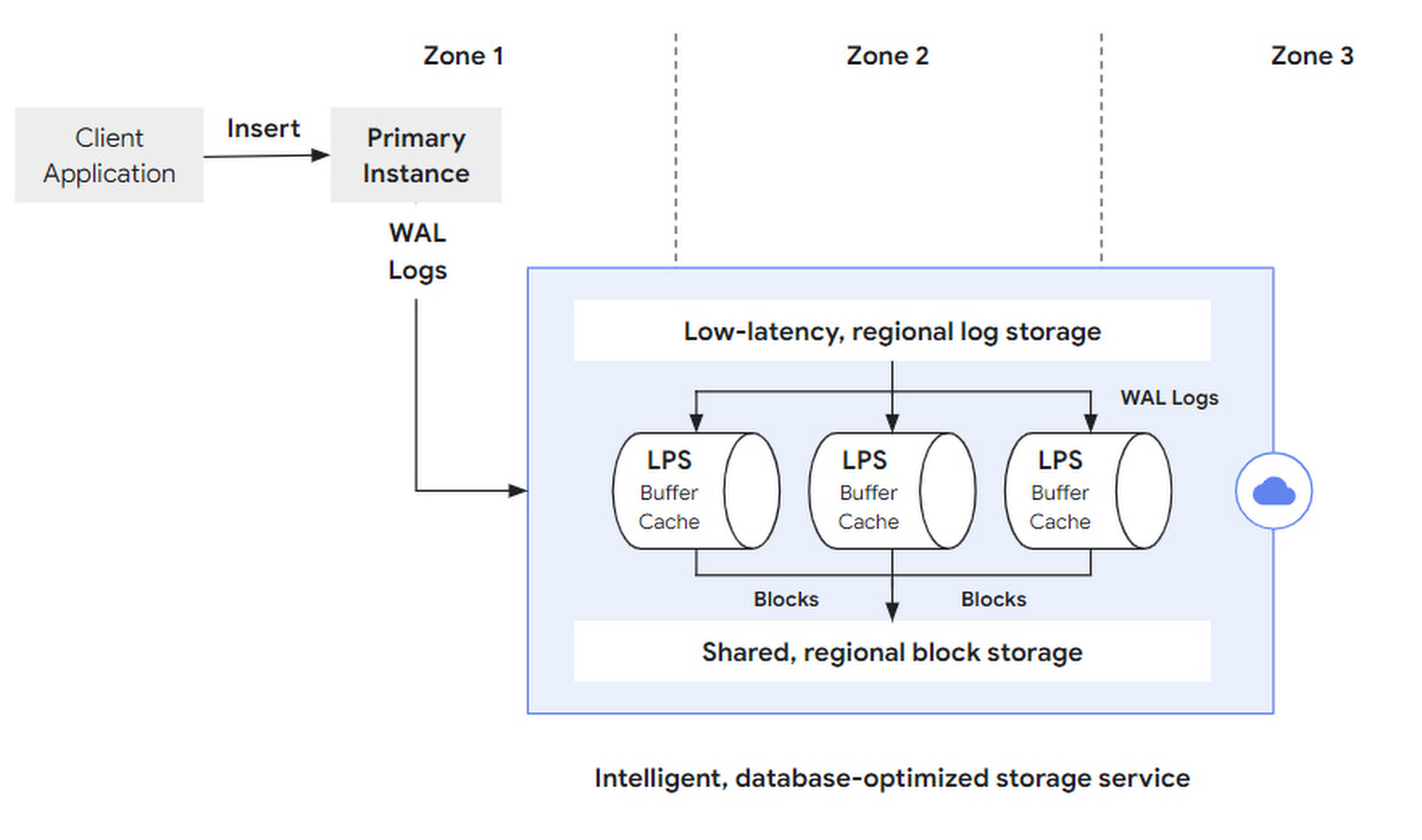
写入请求(如 SQL insert),由客户端向主实例发起,在经过 DB 层解析后,变为一组 WAL Records 发到存储层。在 WAL 同步写入成功后,事务提交成功返回。之后,LPS 会将日志异步的物化为 Block。
 write-workflow.png
write-workflow.png
原文没有展开,但如何对日志进行分段和容错、如何多地部署、如何管理日志生命周期,也是很关键的设计点。
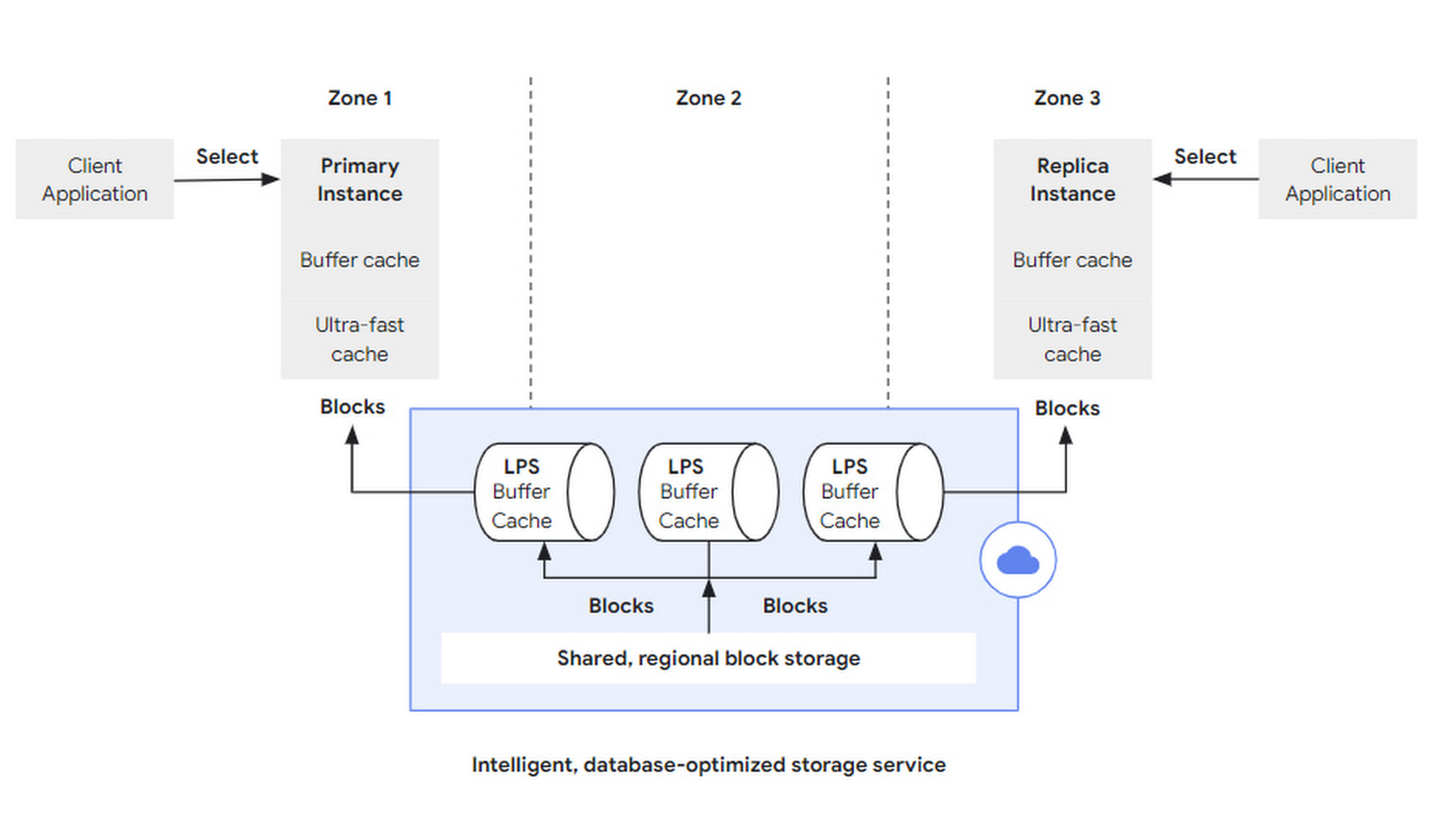
读取请求(如 SQL query),由客户端向任何实例发起,在 DB 层解析后,如果命中该 DB 层中的缓存(Buffer Cache),则直接返回;如果请求所需数据缓存不够,则可以去更大的、类似二级缓存的 Ultra-fast Cache 中去捞,如命中,则仍可不访问存储层。
如 Ultra-fast Cache 中仍然缺少所需 block,则会带上 block id 和 LSN,向存储层发送 block 读取请求:
- block id 用于检索 block。
- LSN 用于等待 LPS apply 进度,以保证一致性视图。
 read-workflow.png
read-workflow.png
在存储层中,LPS 负责 block 的读写,每个 LPS 都维护了 Buffer Cache,这个术语比较有意思:
- Buffer,一般用在写入时,将多个写合并到一块,以提高写吞吐。
- Cache,一般用在读取时,弥合不同介质的访问速度,以减小延迟。
在此处,两者合二为一,LPS 在日志重放(log apply)时,首先写入自己的 Buffer Cache,此时 Buffer Cache 充当 buffer,以批量刷入 block storage 中;LPS 在将 Buffer Cache 刷到 block storage 前,如收到 block 读取请求,并命中 Buffer Cache,可直接返回,此时,Buffer Cache 充当 cache。
当然,LPS 需要对 Buffer Cache 维护类似脏表之类的数据结构,以追踪每个 block 的生命周期和下刷失效时机。
弹性伸缩
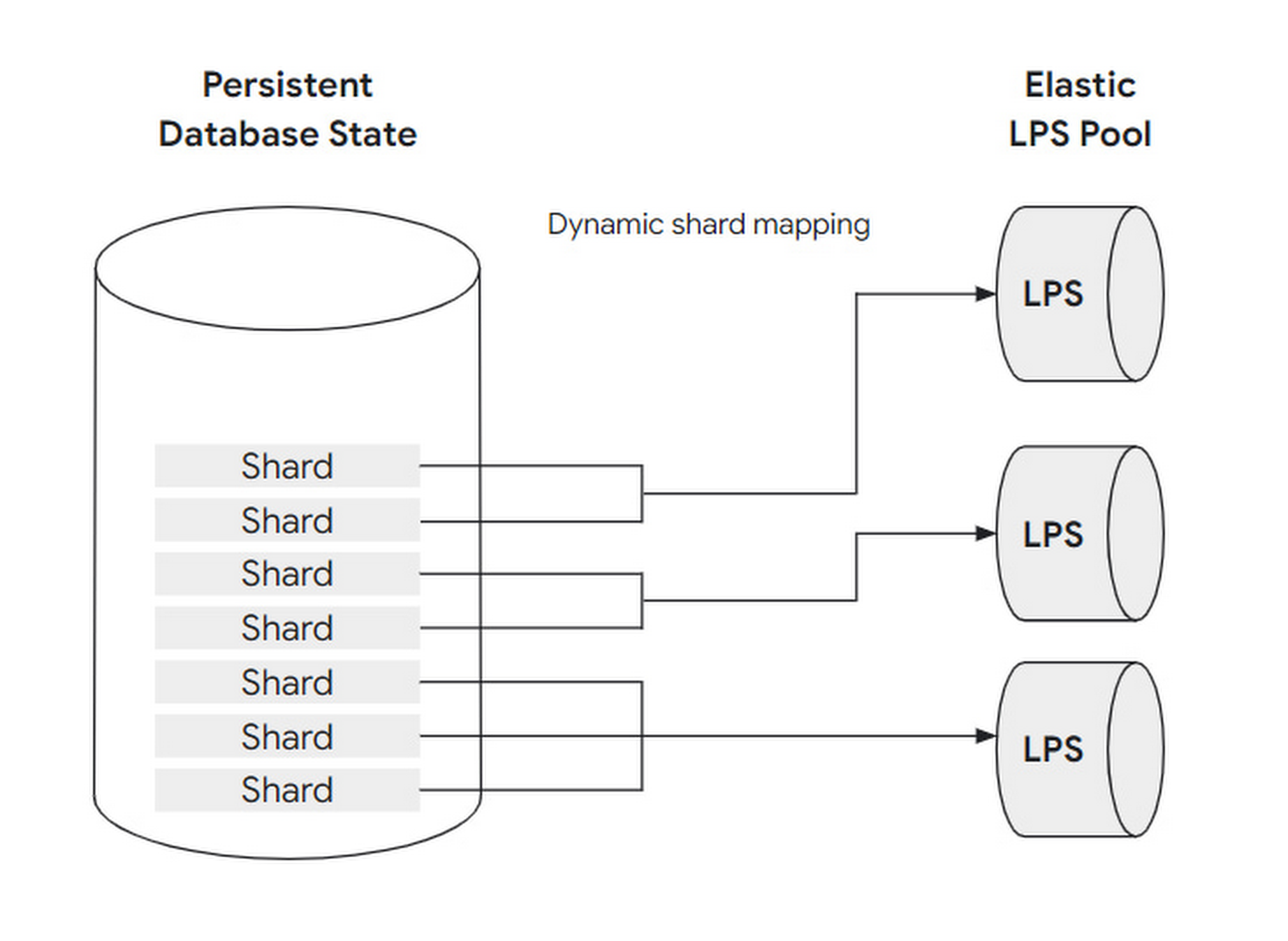
为了应对变化的负载,LPS 实例数量被设计为可伸缩的:即调整 LPS 和 block shard 的映射关系。在进一步解释如何伸缩前,先梳理下 block、shard 和 LPS实例 的概念以及联系:
一组 block 集合为一个 shard,一个 shard 最多为一个 LPS实例 所处理,但一个 LPS实例 可同时处理多个 shards。
以餐厅来类比,block 可理解为客人,shard 可理解为餐桌,LPS 实例可理解为服务员:
- 当负载很低时,只需要一个服务员就能照顾餐厅内所有餐桌上的客人。
- 当负载很高时,最多可以为每个餐桌分配一个服务员。
这种动态调节,可完全自动化,无需用户感知和干预。又因 LPS 没有状态(Buffer Cache 不算状态,想想为什么),因此可以快速伸缩。
 LPS-shard.png
LPS-shard.png
跨区多活
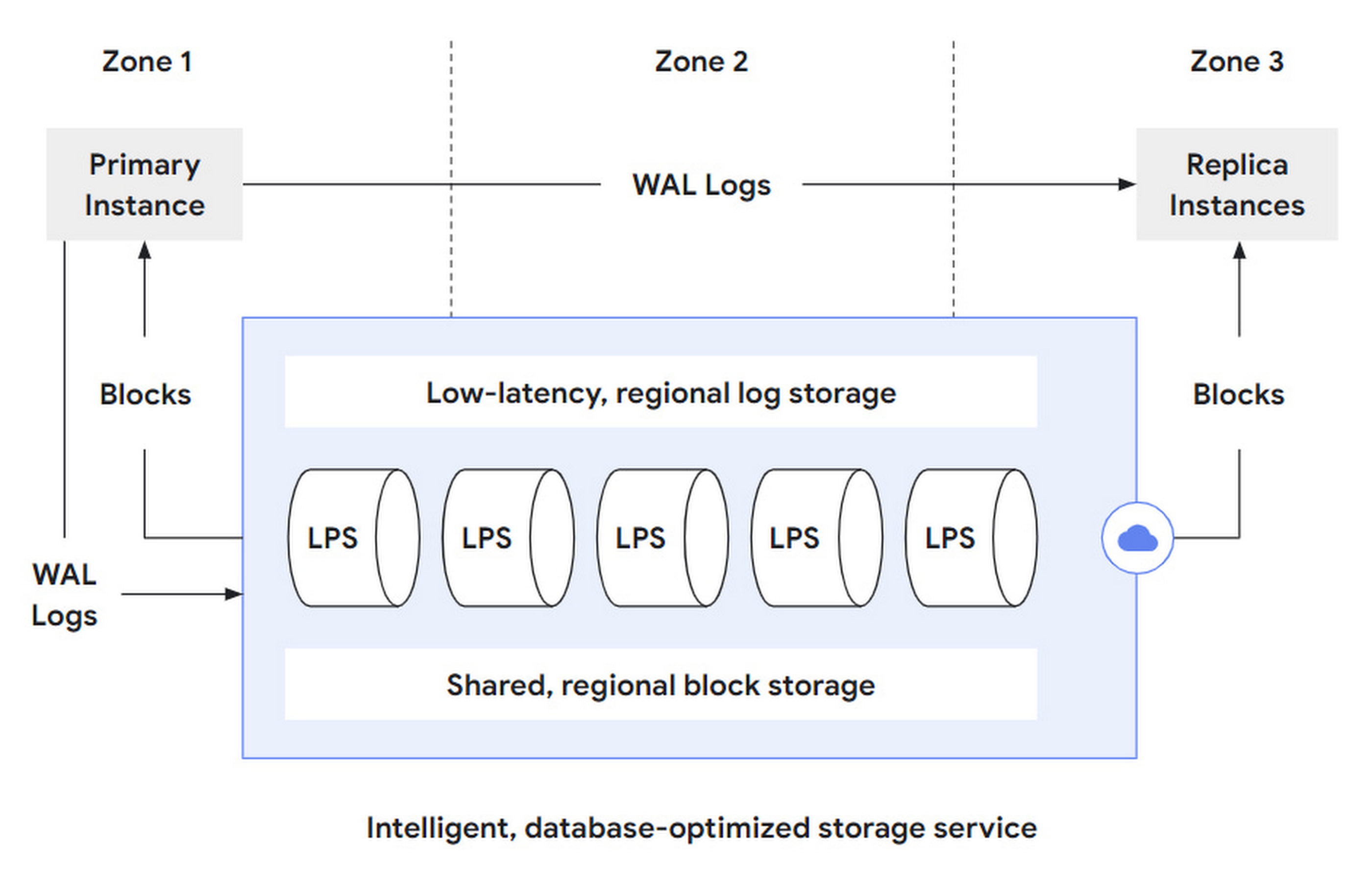
为了容忍区域性故障,AlloyDB 会将每个 block 分片的多个副本放到不同区域(zone)中。
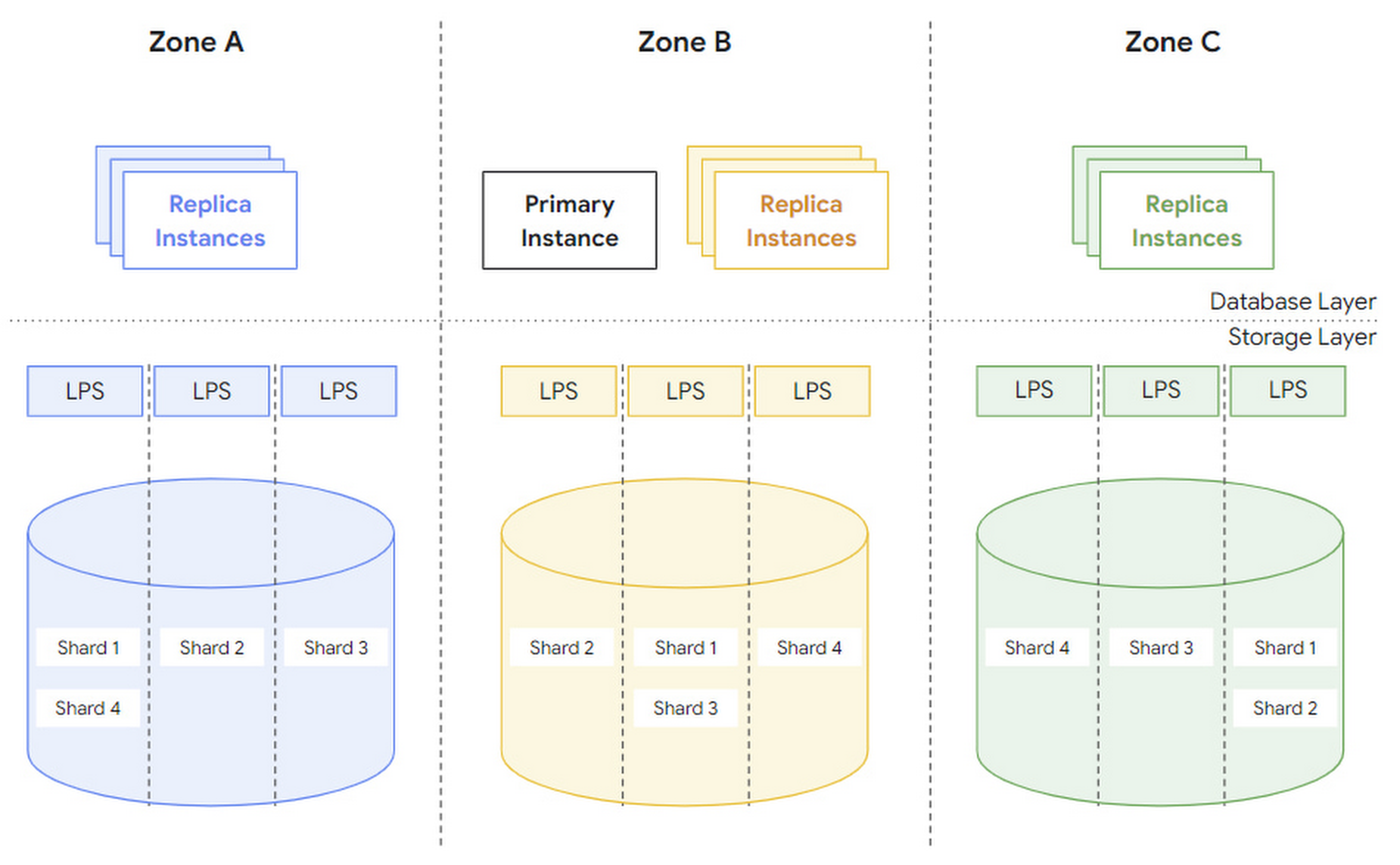 zones.png
zones.png
文中提到两个概念,region 和 zone,没有去求证,但猜测 region 指物理区域,zone 指逻辑区域。当某个 zone 发生故障时,在同一 region 新拉起一个 zone,并进行数据恢复:
- 首先使用其他副本的 snapshot 来恢复。
- 然后将该 snapshot 之后的 WAL 回放。
正常情况下,每个 zone 可以独立的进行服务,没有特别多的跨 zone 流量。
此外,AlloyDB 还支持逻辑上(比如某个 database)的手动和自动备份,以防止用户误删数据。
小结
AlloyDB 的存储层基于日志服务进行实现,分为两层存储 log storage、block storage 和一层计算 LFS。基于 LSN 来控制并发,动态伸缩 LFS 以应对负载。
你对这种设计有什么看法?欢迎留言讨论。

