早对 LevelDB 有所耳闻,这次心血来潮结合一些资料粗略过了遍代码,果然名不虚传。如果你对存储感兴趣、如果你想优雅使用C++、如果你想学习如何架构项目,都推荐来观摩一下。更何况作者是 Sanjay Ghemawat 和 Jeff Dean 呢。
看过一遍如果不输出点什么,以我的记性,定会很快抛诸脑后。便想写点东西说说 LevelDB 之妙,但又不想走寻常路:从架构概览说起,以模块分析做合。读代码的这些天,一直在盘算从哪下笔比较好。在将将读完之时,印象最深的反而是 LevelDB 的各种精妙的数据结构:贴合场景、从头构建、剪裁得当、代码精到。不妨, LevelDB 系列就从这些边边角角的小构件开始吧。
本系列主要想分享 LevelDB 中用到的三个工程中常用的经典数据结构,分别是用以快速读写 memtable 的 Skip List、用以快速筛选 sstable 的 Bloom Filter 和用以部分缓存 sstable 的 LRUCache 。这是第二篇,Bloom Filter。
引子
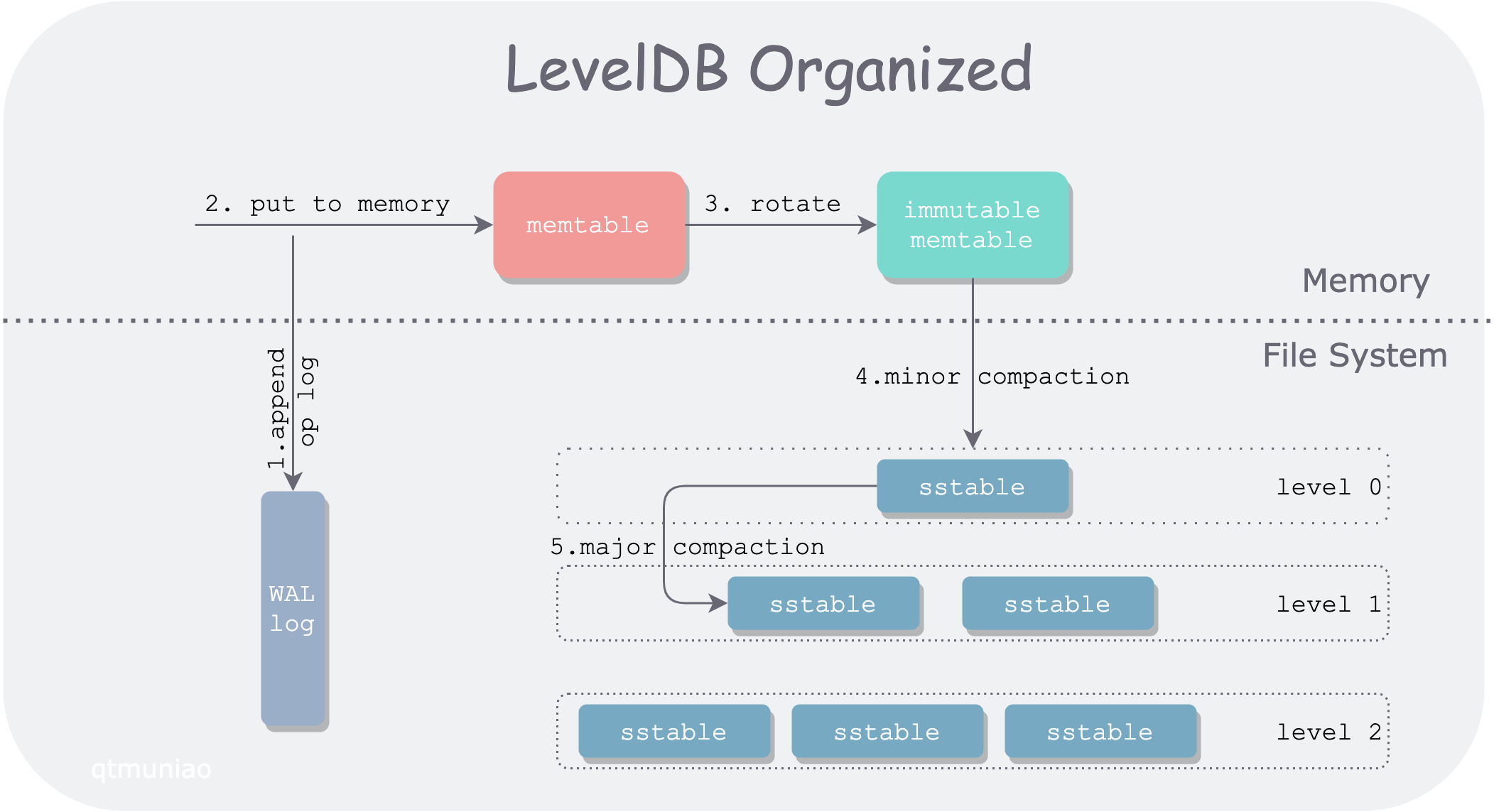
LevelDB 是一个单机的 KV 存储引擎,但没有使用传统的平衡查找树以平衡读写性能,而是使用了 LSM-tree 结构来组织数据,牺牲部分读性能来换取较高的写吞吐。下面来对照一张图来介绍 LSM-tree 在不同存储介质上的组织方式。
 leveldb.png
leveldb.png
LevelDB 将数据分为两大部分,分别存放在内存和文件系统中。主要数据模块包括 WAL log,memtable,immutable memtable,sstable。按照数据流向依次如下:
- 当 LevelDB 收到一个写入请求
put(k, v),会首先将其操作日志追加到日志文件(WAL)中,以备节点意外宕机恢复。 - 写完 WAL 后,LevelDB 将该条 kv 插入内存中的查找结构:memtable。
- 在 memtable 积累到一定程度后,会 rotate 为一个只读 memtable,即 immutable memtable;同时生成一个新的 memtable 以供写入。
- 当内存有压力后,会将 immutable memtable 顺序写入文件系统,生成一个 level0 层的 sstable(sorted strings table) 文件。该过程称为一次 minor compaction。
- 由于查询操作需要按层次遍历 memtable、immutable 和 sstable。当 sstable 文件生成的越来越多之后,查询性能必然越来越差,因此需要将不同的 sstable 进行归并,称为 major compaction。
LevelDB 层次组织
所有在文件系统中的 sstable 文件,被 LevelDB 在逻辑上组织成多个层次(一般是 7层),并且满足以下性质:
- 层次越大说明其数据写入越早,即先往上层进行“放”(minor compaction),上层“满”(达到容量限制)之后“溢”(major compaction)到下层进行合并。
- 每层文件总大小都有一定限制,并且成指数级增长。比如 level0 层文件总大小上限为10MB,level1 层为100MB,依次类推,最高层(level6层)没有限制。
- 由于 level0 每个 sstable 文件都是直接由 memtable 落盘而来, 因此多个 sstable 文件的 key 范围可能会有交叠。而其他层的多个 sstable 文件则通过一些规则保证没有交叠。
对于 LevelDB 的一次读取操作,需要首先去 memtable、immutable memtable 查找,然后依次去文件系统中各层查找。可以看出,相比写入操作,读取操作实在有点效率低下。我们这种客户端进行一次读请求,进入系统后被变成多次读请求的现象为读放大。
为了减小读放大,LevelDB 采取了几方面措施:
- 通过 major compaction 尽量减少 sstable 文件
- 使用快速筛选的办法,快速判断 key 是否在某个 sstable 文件中
而快速判断某个 key 是否在某个 key 集合中,LevelDB 用的正是布隆过滤器。当然,布隆过滤器只能快速判断 key 一定不在某个 sstable 中,从而在层层查找时跳过某些 sstable 。之后会详述原因,此处按下不表。
作者:木鸟杂记 https://www.qtmuniao.com/2020/11/18/leveldb-data-structures-bloom-filter, 转载请注明出处
原理
Bloom Filter 是 Burton Howard Bloom于1970年 提出,相关论文为: [Space/time trade-offs in hash coding with allowable errors](Space/time trade-offs in hash coding with allowable errors)。仅让渡些许准确性,就换取了时空上的高效性,实在是很巧妙的设计。
数据结构
Bloom Filter 底层使用一个位数组(bit array),初始,所表示集合为空时,所有位都为 0:
 empty-bloom-filter.png
empty-bloom-filter.png
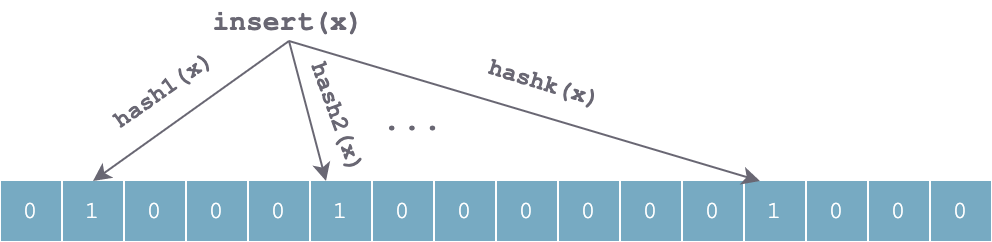
当往集合中插入一个元素 x 时,利用 k 个独立的哈希函数分别对 x 进行散列,然后将 k 个散列值按数组长度取余后分别将数组中对应位置置为 1:
 set-x-bloom-filter.png
set-x-bloom-filter.png
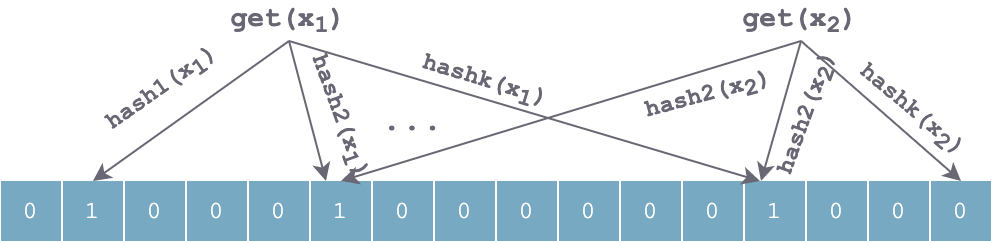
查找过程和插入过程类似,也是利用同样的 k 个哈希函数对待查找元素按顺序进行哈希,得到 k 个位置。如果位数组中 k 个位置上的位均为 1,则该元素有可能存在;否则,若任意一位置上值为 0,则该值一定不存在。对于下图来说,x1 有可能存在,x2 一定不存在。
 get-x-bloom-filter.png
get-x-bloom-filter.png
当持续插入一些元素后,数组中会有大量位置被置 1,可以想象,肯定会有一些位置冲突,造成误判。使用 k 个独立哈希函数可以部分解决这个问题。但如果对于某个值 y,k 个 hash(y) 计算出来的位置,都恰好被其他时候插入的几个元素值设置为 1,则会误判 y 在集合中。
时空优势
相对于其他表示数据集的数据结构,如平衡二叉搜索树、Trie 树、哈希表,甚至更简单的数组或者链表,Bloom Filter 有着巨大的时空优势。上述提到的表示数据集的数据结构,大都需要对数据项本身存储,可能有的做了压缩,比如 Trie 树。但是 Bloom Filter 走了另一条路,并不存储数据项本身,而是存储数据项的几个哈希值,并且用高效紧凑的位数组来存,避免了指针的额外开销。
如此设计,使得 Bloom Filter 的大小与数据项本身大小(如字符串的长短)无关。如,具有 1% 的误差和最佳 k(哈希函数个数)的 Bloom Filter 来说,平均每个元素只需 9.6 bit。
这种优势的获得,可以理解为在哈希表基础上,忽略了冲突处理,从而省下了额外开销。
参数取舍
从上面对 Bloom Filter 可以粗略的感受到,其误判率应该和以下参数有关:
- 哈希函数的个数 k
- 底层位数组的长度 m
- 数据集大小 n
这几个参数与误判率的关系的推导这里不详细展开,可以参考维基百科,或者这篇 CSDN 文章。这里直接给出结论:
当 k = ln2 * (m/n) 时,Bloom Filter 获取最优的准确率。m/n 即 bits per key(集合中每个 key 平均分到的 bit 数)。
源码
铺垫了 Bloom Filter 背景和基本原理后,让我们来看看 LevelDB 源码是如何将其嵌入系统的。
通用接口
为了减小读放大,尤其是对磁盘访问的读放大,LevelDB 抽象出了一个 FilterPolicy 接口,用以在查找 key 时快速筛掉不符合条件的 SStable,这些 Filter 信息会和数据在 SSTable 文件中一起存储,并且在需要时加载到内存,这要求 Filter 占空间不能太大。
1 | class LEVELDB_EXPORT FilterPolicy { |
抽象出该接口可以让用户根据自己需求实现一些其他的过滤策略。自然的,LevelDB 提供了实现了该接口的一个内置的过滤策略:BloomFilterPolicy:
1 | class BloomFilterPolicy : public FilterPolicy { |
根据上述源代码,LevelDB 在实现时,有以下几个点需要注意:
- 之前提到的 bit 数组在 C++ 语言中,LevelDB 使用 char 数组来表示。因此计算 bit 数组长度时需要对齐到 8 的倍数,计算下标时需要进行适当转换。
- LevelDB 实现时并未真正使用 k 个哈希函数,而是用了 double-hashing 方法进行了一个优化,号称可以达到相似的正确率。
小结
Bloom Filter 通常用于快速判断某个元素是否在集合中。其本质上是通过容忍一定的错误率,来换取时空的高效性。从实现角度来理解,是在哈希表的基础上省下了冲突处理部分,并通过 k 个独立哈希函数来减少误判,LevelDB 在实现时使用了某种优化:利用一个哈希函数来达到近似 k 个哈希函数的效果。
下一篇中,将继续剖析 LevelDB 中用到的另一个经典的数据结构:LRU 缓存(LRU cache)。
参考
- LevelDB handbook:https://leveldb-handbook.readthedocs.io/zh/latest/bloomfilter.html
- Wikipedia:https://en.wikipedia.org/wiki/Bloom_filter

