早对 LevelDB 有所耳闻,这次心血来潮结合一些资料粗略过了遍代码,果然名不虚传。如果你对存储感兴趣、如果你想优雅使用C++、如果你想学习如何架构项目,都推荐来观摩一下。更何况作者是 Sanjay Ghemawat 和 Jeff Dean 呢。
看过一遍如果不输出点什么,以我的记性,定会很快抛诸脑后。便想写点东西说说 LevelDB 之妙,但又不想走寻常路,从架构概览说起,以模块分析做合。读代码的这些天,一直在盘算从哪下笔比较好。在将将读完之时,印象最深的反而是 LevelDB 的各种精妙的数据结构:贴合场景、从头构建、剪裁得当、代码精到。不妨, LevelDB 系列就从这些边边角角的小构件开始吧。
本系列主要想分享 LevelDB 中用到的三个工程中常用的经典数据结构,分别是用以快速读写 memtable 的 Skip List、用以快速筛选 sstable 的 Bloom Filter 和用以部分缓存 sstable 的 LRUCache 。这是第一篇,Skip List。
需求
LevelDB 是一个单机的 KV 存储引擎。KV 引擎在本质上可认为只提供对数据条目(key,val) Put(key, val), Get(key) val, Delete(key) 操作的三个接口。而在实现上,LevelDB 在收到删除请求时不会真正删除数据,而是为该 Key 写一个特殊标记,以备读取时发现该 Key 不存在,从而将 Delete 转为 Put ,进而将三个接口简化为两个。砍完这一刀后,剩下的就是在 Put 和 Get 间进行性能取舍,LevelDB 的选择是:牺牲部分 Get 性能,换取强悍 Put 性能,再极力优化 Get。
我们知道,在存储层次体系(Memory hierarchy)中,内存访问远快于磁盘,因此 LevelDB 为了达到目标做了以下设计:
- 写入(Put):让所有写入都发生在内存中,然后达到一定尺寸后将其批量刷磁盘。
- 读取(Get):随着时间推移,数据不断写入,内存中会有一小部分数据,磁盘中有剩余大部分数据。读取时,如果在内存中没命中,就需要去磁盘查找。
为了保证写入性能,同时优化读取性能,需要内存中的存储结构能够同时支持高效的插入和查找。
之前听说 LevelDB 时,最自然的想法,以为该内存结构(memtable)为是平衡树,比如红黑树、AVL 树等,可以保证插入和查找的时间复杂度都是 lg(n),看源码才知道用了跳表。相比平衡树,跳表优势在于,在保证读写性能的同时,大大简化了实现。
此外,为了将数据定期 dump 到磁盘,还需要该数据结构支持高效的顺序遍历。总结一下 LevelDB 内存数据结构(memtable)需求点:
- 高效查找
- 高效插入
- 高效顺序遍历
作者:木鸟杂记 https://www.qtmuniao.com/2020/07/03/leveldb-data-structures-skip-list/, 转载请注明出处
原理
跳表由 William Pugh 在 1990 年提出,相关论文为:Skip Lists: A Probabilistic Alternative to Balanced Trees。从题目可以看出,作者旨在设计一种能够替换平衡树的数据结构,正如他在开篇提到:
Skip lists are a data structure that can be used in place of balanced trees.
Skip lists use probabilistic balancing rather than strictly enforced balancing and as a result the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
跳表是一种可以取代平衡树的数据结构。
跳表使用概率均衡而非严格均衡策略,从而相对于平衡树,大大简化和加速了元素的插入和删除。
这段话中有个关键词:概率均衡(probabilistic balancing),先卖个关子,按下不表。
接下来我们从两个角度来解读跳表:链表和跳表,跳表和平衡树。
链表到跳表
简言之,跳表就是带有额外指针的链表。为了理解这个关系,我们来思考一下优化有序链表查找性能的过程。
假设我们有个有序链表,可知其查询和插入复杂度都为 O(n)。相比数组,链表不能进行二分查找的原因在于,不能用下标索引进行常数复杂度数据访问,从而不能每次每次快速的筛掉现有规模的一半。那么如何改造一下链表使之可以进行二分?
利用 map 构造一个下标到节点的映射?这样虽然可以进行二分查询了,但是每次插入都会引起后面所有元素的下标变动,从而需要在 map 中进行 O(n) 的更新。
增加指针使得从任何一个节点都能直接跳到其他节点?那得构造一个全连接图,指针耗费太多空间不说,每次插入指针的更新仍是 O(n) 的。
跳表给出了一种思路,跳步采样,构建索引,逐层递减。下面利用论文中的一张图来详细解释下。
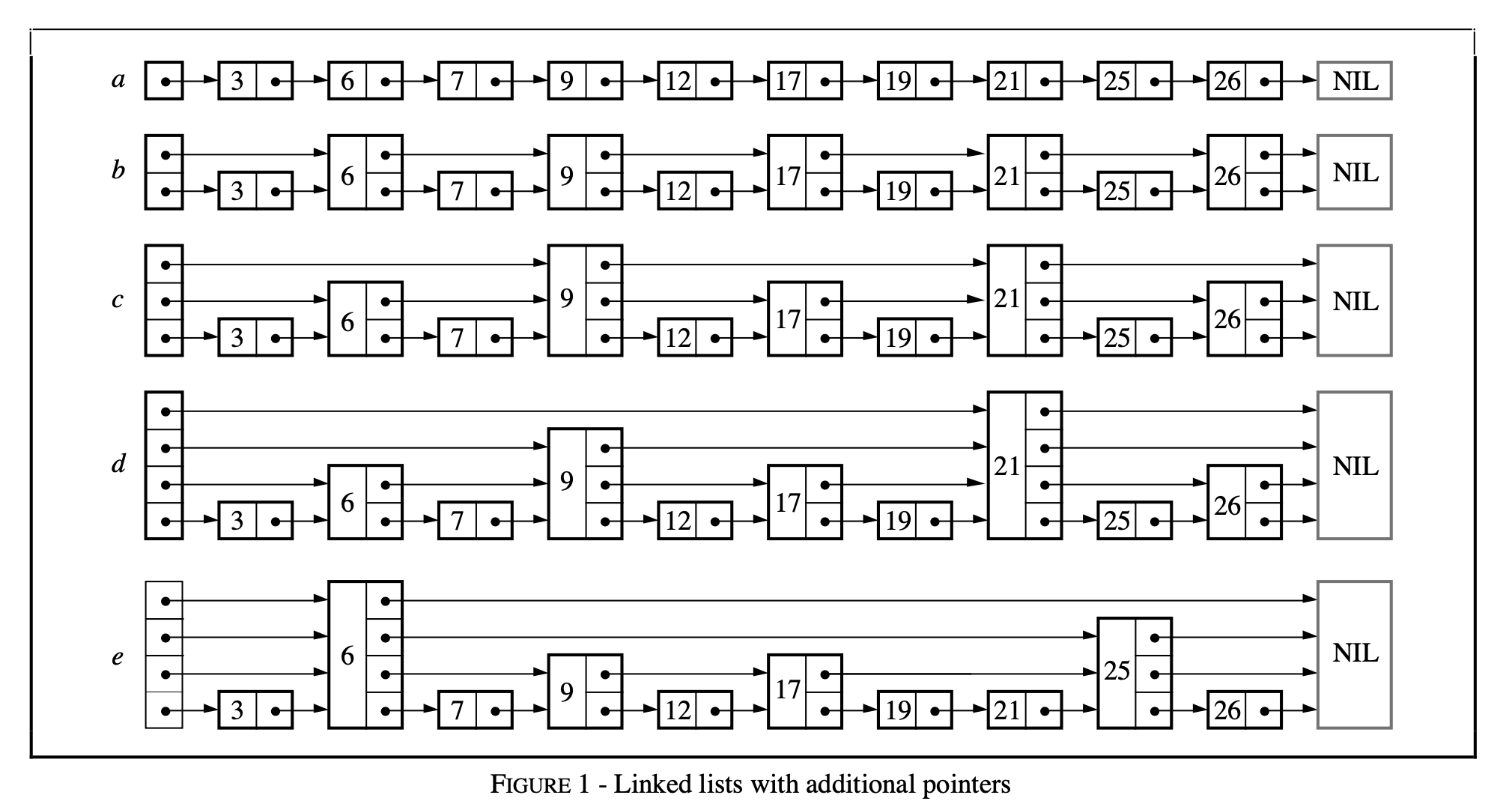 skiplist-linked-lists-with-additional-pointers.png
skiplist-linked-lists-with-additional-pointers.png
如上图,初始我们有个带头结点的有序链表 a,其查找复杂度为 O(n)。然后,我们进行跳步采样,将采样出的节点按用指针依次串联上,得到表 b,此时的查找复杂度为 O(n/2 + 1) [注1]。其后,我们在上次采样出的节点,再次进行跳步采样,并利用指针依次串联上,得到表 c,此时的查找复杂为 O(n/4 + 2)。此后,我们重复这个跳步采样、依次串联的过程,直到采样出的节点只剩一个,如图 e,此时的查找复杂度,可以看出为 O(log2n) [注2]。
代价是我们增加了一堆指针,增加了多少呢?我们来逐次考虑这个问题。从图中可以看出,每次采样出多少节点,便会增加多少个指针;我们的采样策略是,每次在上一次的节点集中间隔采样,初始节点数为 n,最后采到只剩一个节点为止。将其加和则为:(n/2 + n/4 + … + 1) = n。这和一个节点为 n 的二叉树的指针数是相同的。
这里我们回避了一个问题:该结构的插入时间复杂度是多少?这其实进一步了引出本质问题,我们该如何进行插入。
跳表和平衡树
在实践中,我们常用搜索二叉树作为字典表或者顺序表。在插入过程中,如果数据在 key 空间具有很好地随机性,那么二叉搜索树每次顺序插入就可以维持很好的查询性能。但如果我们顺序的插入数据,则会使得二叉搜索树严重失衡,从而使读写性能都大幅度退化。
为了保证性能,需要在发现不平衡时进行调整,于是有了 AVL 树和红黑树。众所周知,AVL 的旋转策略和红黑树的标色策略都稍显复杂,反正我粗看了两次都没记住,面试手撸更是不可能。
而跳表在保证同样查询效率的情况下,使用了一种很巧妙的转化,大大简化了插入的实现。我们不能保证所有的插入请求在 key 空间具有很好地随机性,或者说均衡性;但我们可以控制每个节点其他维度的均衡性。比如,跳表中每个节点的指针数分布的概率均衡。
概率均衡
为了更好地讲清楚这个问题,我们梳理一下跳表的结构和所涉及到概念。跳表每个节点都会有1 ~ MaxLevel 个指针,有 k 个指针的节点称为 k 层节点(level k node);所有节点的层次数的最大值为跳表的最大层数(MaxLevel)。跳表带有一个空的头结点,头结点有 MaxLevel 个指针。
按前面从有序链表构建跳表的思路,每次插入新节点就变成了难题,比如插入的节点需要有多少个指针?插入后如何才能保证查找性能不下降(即维持采样的均衡)?
为了解决这个问题, Pugh 进行了一个巧妙的转化:将全局、静态的构建索引拆解为独立、动态的构建索引。其中的关键在于通过对跳表全局节点指针数概率分布的维持,达到对查询效率的保持。分析上面见索引逐层采样的过程我们可以发现,建成的跳表中有 50% 的节点为 1 层节点,25% 的节点为 2 层节点,12.5% 的节点为三层节点,依次类推。若能维持我们构造的跳表中的节点具有同样的概率分布,就能保证差不多查询性能。这在直觉上似乎没问题,这里不去深入探讨背后的数学原理,感兴趣的同学可以去读一读论文。
经过这样的转化,就解决了上面提出的两个问题:
- 插入新节点的指针数通过独立的计算一个概率值决定,使全局节点的指针数满足几何分布即可。
- 插入时不需要做额外的节点调整,只需要先找到其需要放的位置,然后修改他和前驱的指向即可。
这样插入节点的时间复杂度为查找的时间复杂度 O(log2n),与修改指针的复杂度 O(1) [注3] 之和,即也为 O(log2n),删除过程和插入类似,也可以转化为查找和修改指针值,因此复杂度也为 O(log2n)。
源码分析
千呼万唤始出来,让我们进入正题。LevelDB 中对 SkipList 的实现增加了多线程并发访问方面的优化的代码,提供以下保证:
- Write:在修改跳表时,需要在用户代码侧加锁。
- Read:在访问跳表(查找、遍历)时,只需保证跳表不被其他线程销毁即可,不必额外加锁。
也就是说,用户侧只需要处理写写冲突,LevelDB 跳表保证没有读写冲突。
这是因为在实现时,LevelDB 做了以下假设(Invariants):
- 除非跳表被销毁,跳表节点只会增加而不会被删除,因为跳表对外根本不提供删除接口。
- 被插入到跳表中的节点,除了 next 指针其他域都是不可变的,并且只有插入操作会改变跳表。
接口
LevelDB 的 Skip List 对外提供的接口主要有三个,分别是插入、查询和遍历。
1 | // 插入 key 到跳表中. |
为了灵活适配,LevelDB 的 SkipList 使用了类模板(template class),使得调用方可以自定义 Key 的类型,并且基于该 Key 定制比较类 Comparator。
在详细分析这几个接口之前,首先看下跳表的基本构成元素 SkipList::Node 的数据结构,代码里有一些多线程读写共享变量时进行同步的代码。这里主要涉及到指令重排的一些内容,下面稍微展开说一下。
我们知道,编译器/CPU 在保在达到相同效果的情况下会按需(加快速度、内存优化等)对指令进行重排,这对单线程来说的确没什么。但是对于多线程,指令重排会使得多线程间代码执行顺序变的各种反直觉。用 go 代码举个例子:
1 | var a, b int |
该代码片段可能会打印出 2 0!
原因在于编译器/CPU 将 f() 赋值顺序重排了或者将 g() 中打印顺序重排了。这就意味着你跟随直觉写出的多线程代码,可能会出问题。因为你无形中默认了单个线程中执行顺序是代码序,多线程中虽然代码执行会产生交错,但仍然保持各自线程内的代码序。实则不然,由于编译器/CPU 的指令重排,如果不做显式同步,你不能对多线程间代码执行顺序有任何假设。
回到 LevelDB 跳表代码上,主要涉及 C++11 中 atomic 标准库中新支持的几种 memory order,规定了一些指令重排方面的限制,仅说明下用到的三种:
std::memory_order_relaxed:不对重排做限制,只保证相关共享内存访问的原子性。std::memory_order_acquire: 用在 load 时,保证同线程中该 load 之后的对相关内存读写语句不会被重排到 load 之前,并且其他线程中对同样内存用了 store release 都对其可见。std::memory_order_release:用在 store 时,保证同线程中该 store 之后的对相关内存的读写语句不会被重排到 store 之前,并且该线程的所有修改对用了 load acquire 的其他线程都可见。
1 | template <typename Key, class Comparator> |
查找
查找是插入的基础,每个节点要先找到合适位置,才能进行插入。因此 LevelDB 抽象出了一个公用函数: FindGreaterOrEqual :
1 | template <typename Key, class Comparator> |
该函数的含义为:在跳表中查找不小于给 Key 的第一个值,如果没有找到,则返回 nullptr。如果参数 prev 不为空,在查找过程中,记下待查找节点在各层中的前驱节点。显然,如果查找操作,则指定 prev = nullptr 即可;若要插入数据,则需传入一个合适尺寸的 prev 参数。
1 | template <typename Key, class Comparator> |
该过程借用论文中图示如下:
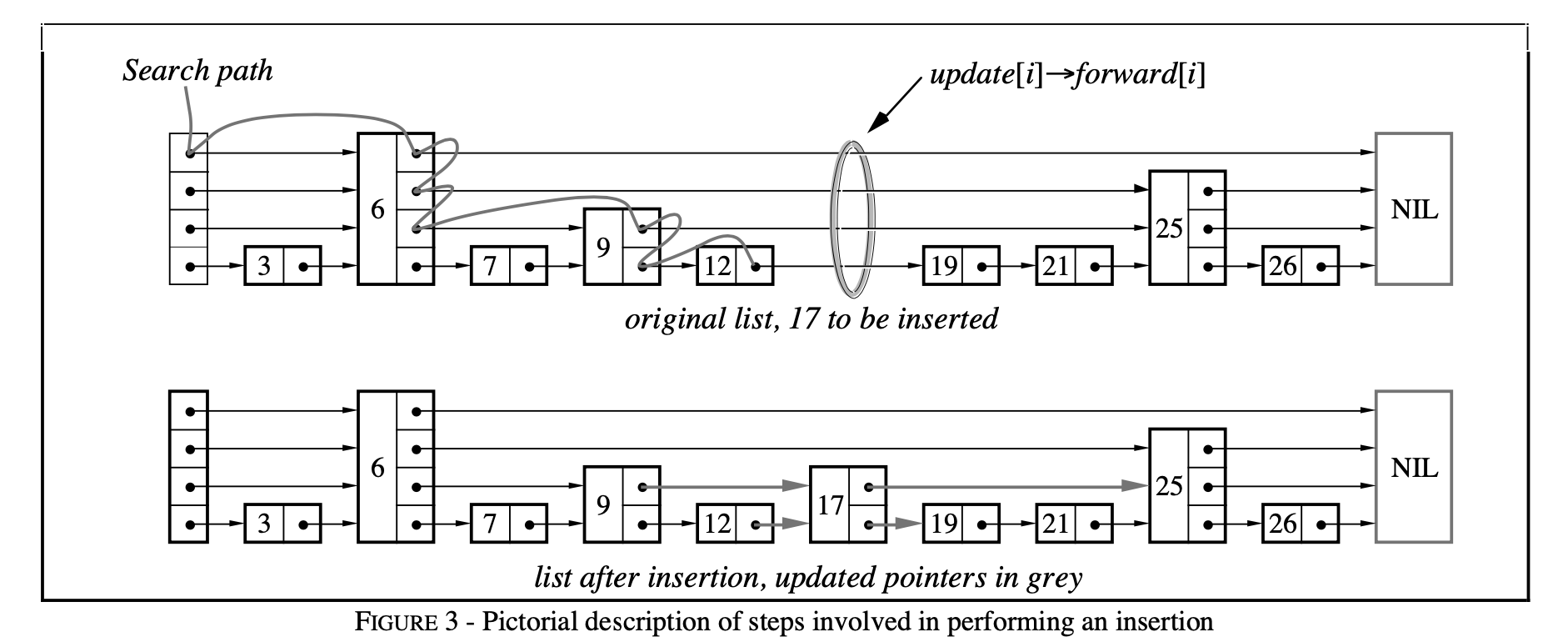 skiplist-search-insert.png
skiplist-search-insert.png
插入
在 FindGreaterOrEqual 基础上,记下待插入节点的各层次前驱节点,比如上图中,调用 FindGreaterOrEqual(17, prev) 后 prev = [12, 9, 6, 6]。插入代码如下:
1 | template <typename Key, class Comparator> |
LevelDB 跳表实现的复杂点在于提供不加锁的并发读的正确性保证。但算法的关键点在于每个节点插入时,如何确定新插入节点的层数,以使跳表满足概率均衡,进而提供高效的查询性能。即 RandomHeight 的实现:
1 | template <typename Key, class Comparator> |
LevelDB 的采样较为稀疏,每四个采一个,且层数上限为 kMaxHeight = 12。具体实现过程即为构造 P = 3/4 的几何分布的过程。结果为所有节点中:3/4 的节点为 1 层节点,3/16 的节点为 2 层节点,3/64 的节点为 3 层节点,依次类推。这样平均每个节点含指针数 1/P = 4/3 = 1.33 个。当然,在论文中的 p 的含义为相邻两层间采样的比例,和我提到的 P 的关系为:p = 1-P。
选 p = 1/4 相比 p = 1/2 是用时间换空间,即只牺牲了一些常数的查询效率,换取平均指针数的减少,从而减小内存使用。论文中也推荐 p = 1/4 ,除非读速度要求特别严格。在此情况下,可以最多支持 n = (1/p)^kMaxHeight 个节点的情况,查询时间复杂度不退化。如果选 kMaxHeight = 12,则跳表最多可以支持 n = 4 ^ 12 = 16M 个值。
遍历
LevelDB 为跳表构造了一个内部类 Iterator,以 SkipList 作为构造函数参数,实现了 LevelDB 导出的 Iterator 接口的大部分函数,如 Next,Prev,Seek,SeekToFirst,SeekToLast 等等。
1 | template <typename Key, class Comparator> |
可以看出该迭代器没有为每个节点增加一个额外的 prev 指针以进行反向迭代,而是用了选择从 head 开始查找。这也是一种用时间换空间的取舍。当然,其假设是前向遍历情况相对较少。
其中 FindLessThan 和 FindLast 的实现与 FindGreaterOrEqual 思路较为相似,不再赘述。
1 | // Return the latest node with a key < key. |
小结
跳表本质上是对链表的一种优化,通过逐层跳步采样的方式构建索引,以加快查找速度。使用概率均衡的思路,确定新插入节点的层数,使其满足集合分布,在保证相似的查找效率简化了插入实现。
LevelDB 的跳表实现还专门对多线程读做了优化,但写仍需外部加锁。在实现思路上,整体采用时间换空间的策略,优化内存使用。
下一篇中,将继续剖析 LevelDB 中用到的另一个经典的数据结构:布隆过滤器(Bloom Filter)。
注解
[1] 先在上层查找,然后缩小到某个范围后去下层查找。
[2] 可以证明,也可以简单的找规律: O(n/2 + 1) -> O(n/4 + 2) -> … -> O(1 + log2n),即 O(log2n) 。
[3] 通过采样过程可知所有节点的概率满足 p = 0.5 的几何分布,则每个节点的期望指针个数为 1/p = 2,则每次插入平均需要修改 2 * 2 个指针,即为常数级别。
参考
- LevelDB handbook:https://leveldb-handbook.readthedocs.io/zh/latest/index.html
- 庖丁解 LevelDB 之数据存储:https://catkang.github.io/2017/01/17/leveldb-data.html
- C++ atomic memory order:https://en.cppreference.com/w/cpp/atomic/memory_order
The last thing
Leetcode 上有跳表简化版的题目,看完了本文可以趁热打铁去实现一下:https://leetcode.com/problems/design-skiplist/
这是我的实现版本:https://leetcode.com/problems/design-skiplist/discuss/740881/C%2B%2B-clean-and-simple-solution-from-leveldb

