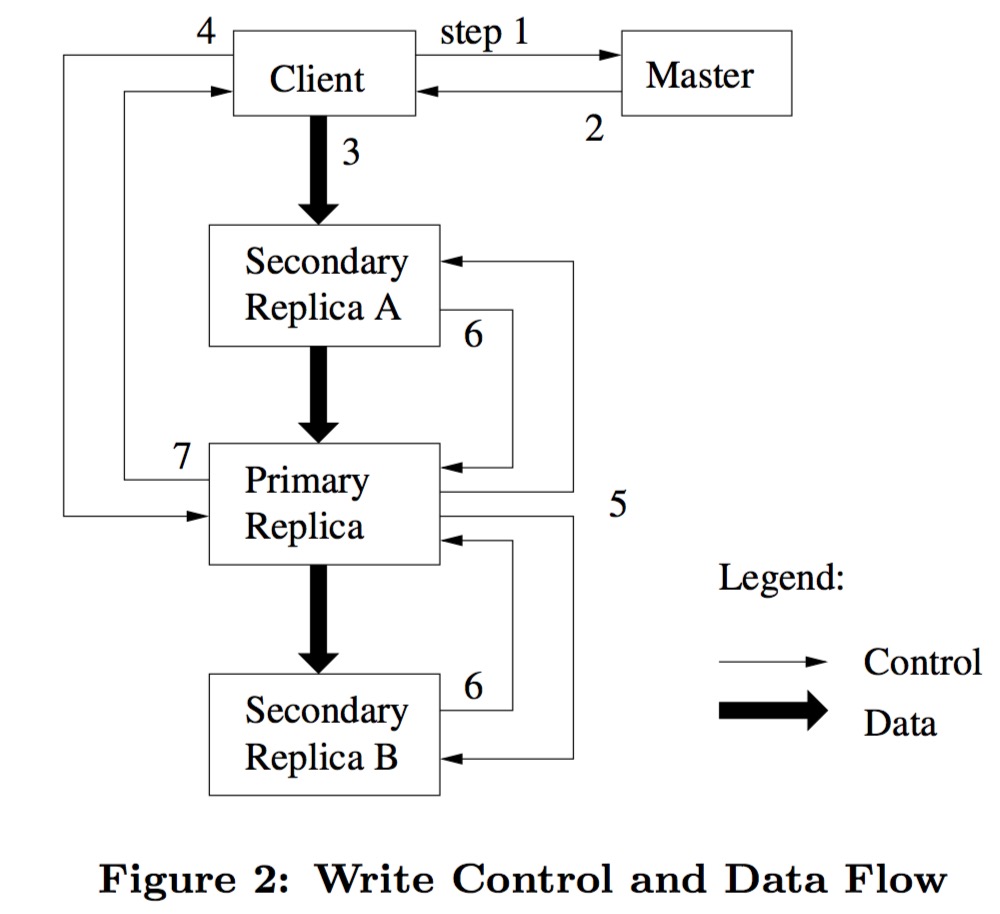
 write control and data flow
write control and data flow
Introduction
GFS is a distributed large-file storage system custom-built by Google for its business needs, supporting elastic scaling and designed for massive data. It runs on clusters of inexpensive commodity servers, features automatic fault tolerance, and supports concurrent access from a large number of clients.
GFS is designed for large files and read-heavy workloads. Although it supports file modifications, it only optimizes for appends. It does not support POSIX semantics but implements a similar file operation API. It was a groundbreaking industrial-scale storage system developed by Google around the same time as MapReduce to solve large-scale data storage problems such as indexing.
Its main design details are as follows:
- Simplified system metadata: The Master maintains two important mappings: file path to logical chunk, and the relationship between logical chunks and their multiple replicas.
- Large chunk size: It chose 64 MB, which was considered quite large at the time, as the basic unit of data storage to reduce metadata.
- Relaxed consistency: It allows content inconsistency among multiple replicas to simplify implementation and improve performance, ensuring corrupted data remains invisible to users through read verification.
- Efficient replica synchronization: When synchronizing multiple replicas, the control flow and data flow are separated to improve synchronization efficiency using network topology.
- Leases to distribute pressure: The Master delegates some authority to a Chunkserver via a lease, which is responsible for read/write control among the multiple replicas of a chunk.
- Concurrent append optimization: Multiple clients concurrently append to the same file, guaranteeing data atomicity and at-least-once semantics.
- Fast snapshot support: Uses a COW (copy-on-write) strategy to implement snapshot operations, and performs copy-on-write through chunk reference counting.
- Per-node lock control: For each operation, read locks must be acquired node by node along the file path, with a read or write lock acquired at the leaf node; of course, file paths are prefix-compressed.
- Asynchronous garbage collection: Data deletion and other master maintenance operations (corrupted chunk cleanup, expired chunk removal) are unified into a periodic process.
- Version number marking: Helps clients identify stale data.
- Chunk checksums: A 32-bit checksum is computed for every 64 KB block.
Author: 木鸟杂记 https://www.qtmuniao.com, please indicate the source when reposting
Overview
Basic Assumptions
Like any system, the scenarios it targets require some core assumptions, so that all subsequent designs can make trade-offs based on them. So what are the basic assumptions of GFS as a distributed file system? We can look at it from several aspects: error handling, file size, modification patterns, and consistency model.
Error Handling
One of the innovations of this file system is abandoning expensive industrial-grade hardware and choosing clusters of inexpensive commodity server disks as the storage medium. Therefore, it is necessary to shield the unreliability of this cheap hardware at the software layer and provide a reliable storage service for upper-layer applications—this is the same problem faced by computing frameworks like MapReduce. In addition, at the software layer, there are usually hundreds or thousands of clients accessing the cluster simultaneously, and they may be distributed across an equally large number of other machines.
In other words, when building a system of this scale on such storage media, component failures should not be treated as exceptions but as the norm. For example, user code may have bugs, the operating system may have bugs, and disks, memory, networks, and even power supplies may all fail.
Therefore, when designing the system, we must introduce continuous monitoring to monitor the health of various software and hardware components; integrate error detection, fault tolerance, and automatic recovery mechanisms to alert, handle, and automatically recover from basic errors.
Targeting Large Files
GFS is designed for single files ranging from tens of megabytes to several gigabytes. This was considered very large at the time (2003). Of course, with the further development of the Internet and communication infrastructure, and the explosive growth of non-textual data such as images and videos, this assumption now seems quite ordinary; but it also shows the foresight of Google’s system evolution.
Returning to the scenario at the time, for millions of KB-sized files, even if the file system could support their storage, it would be difficult to manage them efficiently. Therefore, GFS readjusted some basic designs of conventional file systems: including the size of file blocks and the process of I/O operations.
Append-Only
In the scenarios targeted by GFS, all file modification types are basically dominated by appends, with rarely any overwriting of existing parts. As for random writes, although supported, they are rare. Generally speaking, once writing is complete, the file becomes read-only and is read sequentially.
There are many such scenarios, such as data streams generated by continuously running applications, archived data, and intermediate datasets produced by some machines for other machines to consume synchronously or asynchronously. Considering these access patterns are all for large data files, how to guarantee the concurrency and atomicity of append operations becomes a key point of file system design; whereas the traditional approach of caching at the client side for data locality is not so attractive here, and no additional optimization is needed for it.
Co-design
Through co-design of the system side and the application side, the flexibility of the system can be greatly improved. For example, GFS weakens the consistency model, greatly simplifying the system design without burdening user code; another example is that GFS introduces atomic append operations, allowing multiple clients to concurrently append to the same file without additional synchronization operations.
High Throughput
The design prioritizes high throughput over low latency. Therefore, to guarantee throughput, latency can be sacrificed appropriately. That is, GFS is more suitable for batch tasks than real-time tasks.
Interface
Although GFS does not implement POSIX (Portable Operating System Interface) semantics, its API is similar to that of a file system, including create, delete, open, close, read, and write. In addition, a rather special operation is record append, which is quite powerful, or rather specifically optimized by Google for its scenarios—it supports concurrent writes from multiple clients, and can greatly improve throughput during the reduce disk-write phase of MapReduce tasks.
So what does GFS cut compared to POSIX file system semantics? For example, fine-grained permission control, multi-user and group-user control, symbolic links, and so on.
Architecture Diagram
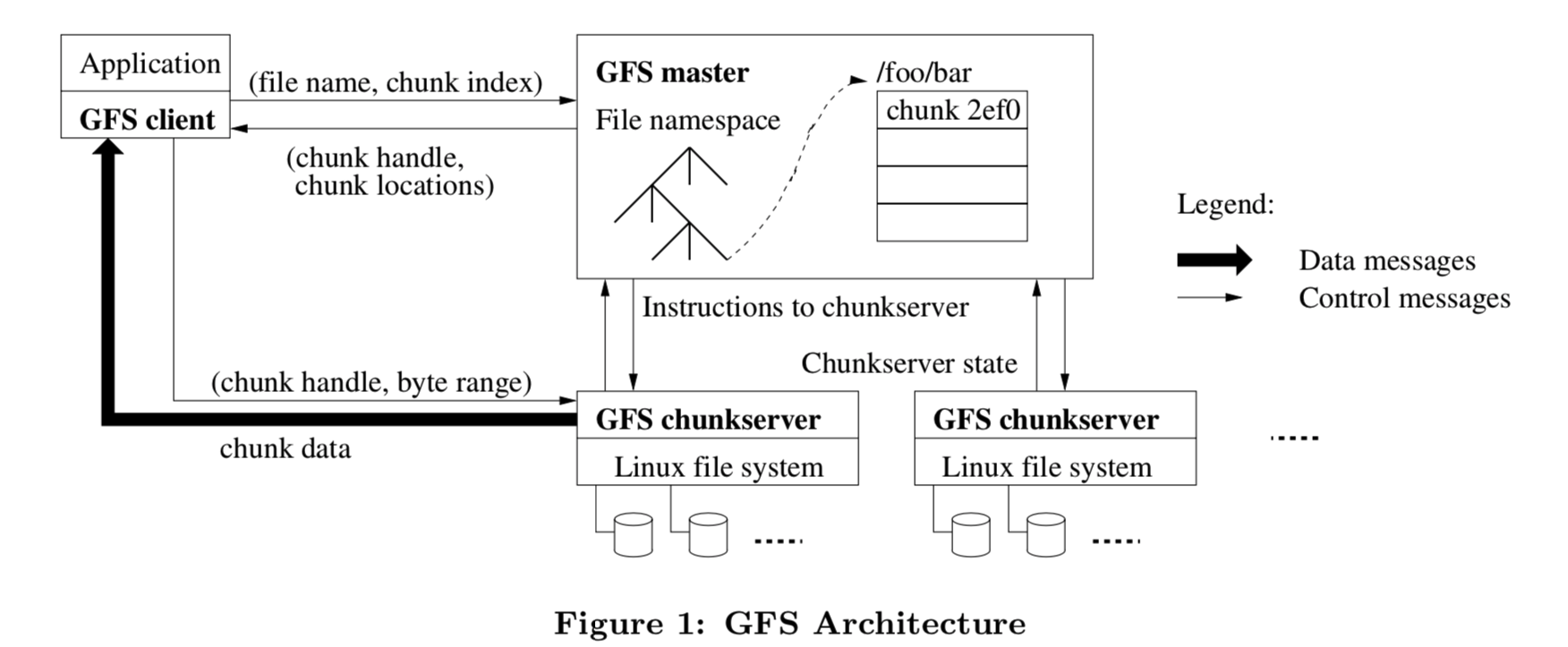 gfs-architecture.png
gfs-architecture.png
The picture tells a great deal; we can see a lot of information from it:
- Physically, the system has three roles: Client, Master node, and Chunkserver node. There is only one Master node; the others have multiple instances. Essentially, both Chunkserver and Client appear as one or a group of processes on a Linux system. Therefore, Client and Chunkserver may be on the same Linux machine.
- Logically, the system has two major parts: metadata and data. Metadata mainly includes the file system namespace, access control information, and the mapping from files to their constituent chunks. This data structure resides on the Master. Data includes the actual data of each file; each file is divided into fixed-size chunks, which are distributed across Chunkservers in some manner.
- The Client side consists of two parts: user code and the GFS Client Library. The latter is provided as a library for the former to call. For each file operation, the Client first queries the Master for file metadata, then goes to the corresponding Chunkserver to find the data based on the obtained location information.
There are also some things not detailed in the diagram but very important in implementation:
- The Master maintains some system events with Chunkservers, including lease management, orphan chunk reclamation, chunk migration, and so on. The Master and Chunkservers use heartbeats to collect metadata and issue the above control information.
- Each file chunk is replicated three times across different machine racks—this is the most direct and brute-force approach to fault tolerance. But it brings many other benefits, such as concurrent reads, which will be discussed in detail later.
- Neither the Client nor the Chunkserver caches recently accessed data at the GFS level, as in a computer’s storage hierarchy. First, this simplifies the design; second, the chunks are too large for caching to be useful; third, the Linux system’s own cache can be utilized.
Single Master
Everyone says single points are bad, so why does GFS still use a single Master? Because it greatly simplifies the design. If there is global information, complex global control policies can be easily implemented. But of course, the disadvantages are also obvious: what if the Master goes down? What if the Master’s outbound bandwidth is too small?
For the former, backups can be done in multiple ways. In the MapReduce paper analysis, several methods were analyzed: snapshot+log, primary-backup, externalized state, and heartbeat recovery. GFS probably uses 1, 3, and 4.
For the latter, the approach is to minimize the request interaction and data transfer between the Client and the Master. GFS’s main methods:
- The Client does not exchange actual file data with the Master; it only requests metadata, such as the location information of the primary chunk, and then goes to the corresponding Chunkserver.
- The Client caches metadata for a limited time, so that for a series of consecutive requests from the same client, the number of metadata requests is minimized.
Let me now detail the read flow (filename+offset):
- The Client translates the file offset into chunk id + offset within the chunk.
- The Client interacts with the Master to get the locations of all replicas of this chunk through filename + chunk id + inner chunk offset. The Client caches this information in a dictionary mapping filename+chunk id -> replica locations.
- The Client then selects the nearest replica (of course, if it fails, it will try the next one), sends it a request with the chunk handle + byte range, and reads the data.
Because of the above cache, as long as it has not expired, subsequent accesses to the same chunk do not need to go through the Master. And this can be further optimized: for example, a Client can request the locations of multiple chunks in a single request; or when the Master returns, it not only returns the replica locations of the requested chunk but also returns the replica locations of the next few chunks in the same file. These can all effectively reduce the Master’s load.
Chunk Size
Chunk size selection is a core design point. It chose 64 MB, which was considered relatively large at the time, as the fixed size of a chunk. Each chunk is physically a file under a Linux system. There are three benefits to this:
- Reduce the number of interactions between the Client and the Master: The Client requests information from the Master on a per-chunk basis. Therefore, given a fixed amount of requested data, the larger the chunk, the fewer the requests.
- Reduce cross-chunk reads for a single request: This is also easy to understand—the larger the chunk, the more likely the byte range of the same request falls within a single chunk.
- Reduce the total metadata size for chunks: To store a fixed total size of data, the larger the individual chunk, the fewer chunks are needed. The metadata for a single chunk is relatively fixed, so the total metadata size becomes smaller. With the Master’s memory unchanged, more metadata can be stored, thereby increasing the system’s capacity limit.
Any design involves trade-offs. Since choosing large chunks has the above benefits, it also brings the following drawbacks:
- Internal fragmentation. For example, if a large number of small files need to be stored, and the size of each small file is less than one chunk size, in GFS it still occupies at least one chunk, resulting in a lot of internal fragmentation. Of course, the last chunk of each file will likely also have some fragmentation.
- Small file hot spots. If there are a large number of small files in the system and they are allocated to a single Chunkserver, that Chunkserver may become a hot spot (because the number of chunks each Chunkserver can store is fixed, and if each file occupies fewer chunks, the number of files it serves will be larger). Generally, this is not a problem. If it really happens, the number of replicas for small files can be temporarily increased (so there are more alternatives to distribute requests). Other possible solutions that Google started brainstorming: solve it in a P2P-like manner, that is, a Client can read data from other Clients.
However, for GFS, small files are not the main target traffic.
Metadata
It mainly includes several collections and mappings, all stored in the Master’s memory. Therefore, Master memory and the amount of metadata per unit of data determine the system’s capacity.
1 | 1. file list and logic chunk list |
Here GFS learned from common database practice and persisted any changes to the first two data structures in an operation log, for recovery when necessary. As for the last mapping, it adopts another strategy: every time the Master recovers, this mapping is built and maintained through heartbeats from each Chunkserver. Why is there this difference? I’ll leave it as a cliffhanger; I’ll explain below.
In-Memory Data Structures
Storing all metadata in the Master’s memory has many benefits:
- The most direct one is simplicity. Often, simplicity is power: it means easy maintenance, easy extension, good performance, and so on.
- The Master can easily obtain global information, which can be used to: reclaim orphan chunks to free space, re-replicate chunks to deal with failures, and continuously migrate chunks to balance load.
- If memory becomes a bottleneck, just add more memory.
The downside is that Master memory can indeed become a bottleneck and a single point. The single point issue will not be discussed in detail here. Regarding the capacity bottleneck, first, the storage scale that GFS faced at the time was not as large as it is now; second, every 64 MB file chunk can be compressed to an average of only 64 bits of metadata. Finally, most files are assumed to occupy many chunks. Overall, the goal is to compress the metadata per unit of data as much as possible, thereby maximizing system capacity under limited Master memory. This seems to have been mentioned above—well, Google’s paper repeats things over and over. After all, for writing, echoing is beauty.
Chunk Locations
At first, GFS also intended to persist the location information of each replica of a chunk on the Master. Later, it was found that passively collecting this from each Chunkserver every time was simpler and more direct. Because each Chunkserver naturally knows the information about the chunk replicas in its own domain, having them report to the Master each time keeps the information most consistent. Suppose this information is persisted on the Master; when the Master recovers after a crash, it restores this information from local storage. But during this downtime, many Chunkservers may have gone down, and many Chunkservers may have joined the cluster, making the information inconsistent. It would still need to be synchronized to consistency through heartbeats, so why not build it through heartbeats from the start?
After some thought, I believe the core point of this persistence design for the chunk id -> chunk replica location mapping is that, unlike the filename and file -> chunk mappings, it cannot be updated while the Master is down; whereas due to the unreliability of a single Chunkserver in a large-scale cluster and the uncertainty of various operations, it is constantly changing. This is an inherent characteristic of distributed clusters, so this design can be said to be a stroke of genius.
Operation Log
The operation log is used to persist the file namespace and the file name -> chunk mapping, and serves two purposes:
- As mentioned above, it is used to persist the above metadata and reconstruct the metadata after a Master crash recovery.
- For concurrent operations, it is used to determine the operation order, equivalent to a “lock” concept.
Therefore, for files, chunks, and version numbers in GFS, they can all be uniquely determined by the order in which they are written to the operation log.
The operation log is so important that we cannot just back it up on the Master’s hard disk—what if the Master is completely destroyed? It must also be synchronized to other remote machines. As mentioned earlier, this log is somewhat similar to a WAL (Write Ahead Log): all modification operations must first be written to the operation log before they can be applied to the Master’s in-memory data structure and then exposed to the Client. Otherwise, during crash recovery, the information obtained by the Client and the Master is often inconsistent. (Of course, to avoid frequent disk flushing affecting normal request performance, some operations can be batched before flushing, but this also brings inconsistency issues, so these considerations need to be flexibly adjusted according to actual business scenarios.)
Where there is an operation log, there is a checkpoint. Because a large system faces so many requests, if every time the Master recovers it has to read the operation log from the very beginning, the process would be extremely long. To compress the operation log, a natural idea is to periodically checkpoint, persisting the state machine or in-memory data structure corresponding to the log before a certain point in time in some way. GFS chose a B-tree because it can be loaded directly into memory without transformation (for example, building a dictionary from key-value pairs), thereby further speeding up recovery time.
When doing a snapshot, GFS uses a small trick to avoid conflicting with the current write to the operation log (after all, modifying the same file requires locking). When it’s time to do a checkpoint, the operation log is switched to a new file. Then a new thread is started to convert the old file into a checkpoint in the background.
Although old snapshots can be released after the latest checkpoint is done, it’s better to be safe than sorry. In practice, GFS often keeps a few extra checkpoints.
Consistency Model
This part was rather difficult for me to understand when I first read the paper, but later I realized it was very clever—by appropriately relaxing consistency constraints while meeting application requirements, the implementation can be greatly simplified.
Before detailing the GFS design, we must first clarify one question: what gives rise to the consistency problem? If this question is not clear, then all the following GFS designs may make no sense at all, which was the reason I couldn’t understand this part at first. The answer is multiple replicas; any system with multiple replicas must face the consistency problem. Because of the unreliability of the network, the unreliability of the Client, and the unreliability of the Chunkserver—in short, every node in a distributed system and the communication between nodes is unreliable. Synchronizing a piece of content to multiple replicas takes time (therefore this operation is not atomic, and may leave the system in an awkward intermediate state). During this time, if any component (Client, Chunkserver, or network) has a problem, inconsistency among different replicas will occur. When subsequent Clients read the data, they will be troubled by the inconsistent replicas—which one should be taken as the standard?
GFS’s Guarantees
GFS believes that there is no need to provide full POSIX file system semantics; only the following basic guarantees are sufficient for the targeted scenarios:
- Changes to the file namespace (such as file creation operations) are atomic.
For the first point, the simplest implementation is to add a big lock outside the file namespace data structure in the Master. All operations are mutually exclusive, so any change to it is atomic, and the operation log can determine an order for all operations. However, too coarse a lock granularity will inevitably affect performance, so in the file directory tree, each node actually has a lock; the specific locking process will be detailed later.
- The state of a modified chunk depends on the type of modification, whether the modification succeeded or failed, and whether it was a concurrent modification.
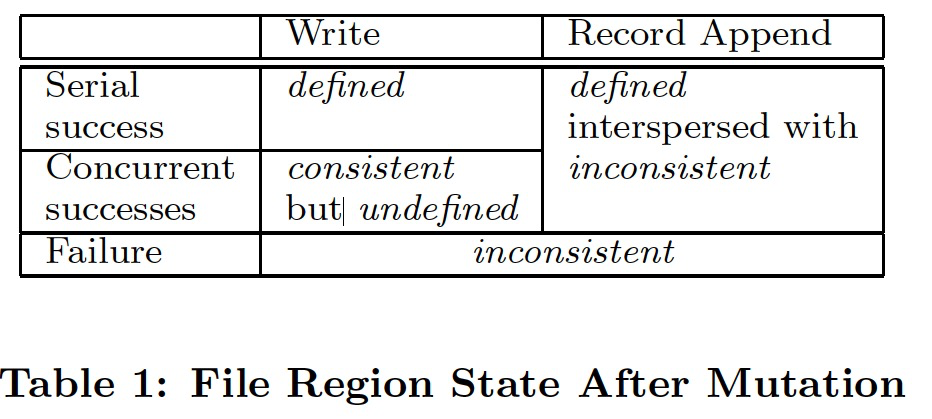 modified file state
modified file state
As shown in the figure, a chunk has three states, in descending order of consistency level: defined, undefined but consistent, and inconsistent. Understanding these levels requires some background, which is mentioned in different places in the paper; here I reorganize it:
- Modification operations. Include write operations and append operations. Write operations need to specify chunk+offset. After a successful append operation, the system will return the offset of the successful append to the client.
- Concurrent writes. If two clients simultaneously write to the same offset of the same chunk, there is an ordering issue. If they are nearly simultaneous, the system does not guarantee the concurrent order. Then when the client reads back, it may not necessarily read the data it just wrote.
- Append failure. The append operation guarantees at least one success. During an append operation, assuming three replicas are configured but only two replicas are written successfully and the last replica times out (possibly because the corresponding chunk server is down; of course, after restarting, GFS will mark it as stale using the chunk version and skip that offset), then the append operation will retry, and the failed data will not be deleted. However, GFS has an alignment operation: after the retry succeeds, the starting offset of the appended data in the three replicas is defined (i.e., consistent). Then the replica that failed last time will have a hole, which the system will fill with special characters.
With this background in mind, let me first state a conclusion: defined/undefined refers to the overwrite ordering problem when multiple clients concurrently write to the same offset; consistent/inconsistent refers to whether the content at the same offset is the same across multiple replicas. Let me explain these terms in detail:
- Defined: After a client writes to an offset and then reads the data at that offset, what is read must be what it just wrote.
- Undefined but consistent: Multiple clients concurrently write to the same offset; it is uncertain who will overwrite whom (this order is arranged by the Chunkserver where the Primary Replica resides, which will be discussed later). That is, after writing and then reading, it is uncertain whether what is read is what was written by itself or overwritten by someone else. But eventual consistency is guaranteed: after the concurrent writes are completed, the final replicas are consistent.
- Inconsistent: After a modification operation, the data at the same offset in all replicas is not exactly the same.
It is also worth mentioning that because the client caches chunk locations, it may read stale information. Of course, expiration events and reopening the file will refresh this information, but there is a window where stale information can be obtained. However, since most GFS scenarios are appends, stale data is generally not read.
Impact on User Code
By using other technical means: relying on appends rather than random writes, checkpoint techniques, and self-checking, self-locating record writes (i.e., doing checksums and IDs in the application layer or library), the above relaxed consistency model can be used with confidence. Let me explain these techniques in detail below.
-
Append writes and checkpoints
The scenario GFS actually faces is far more appends than random writes. Then in a scenario with almost only appends, the strategy for maintaining consistency can be much simpler. A typical scenario is a writer writing from beginning to end. Using two small tricks can guarantee consistency: a. rename after writing; b. checkpoint periodically. The former can guarantee the atomicity of file writing: either it is fully visible or not visible at all. For the latter, each checkpoint is actually defined and naturally consistent. Readers can safely read up to the last checkpoint. Even if the writer fails and restarts, it can incrementally write from the last checkpoint. During this process, readers will not read inconsistent data.
-
Self-checking and self-locating
Another classic scenario is multiple writers concurrently appending to merge sharded results or act as a producer-consumer queue. As mentioned earlier, for append writes, GFS provides an at-least-once semantic guarantee. Since record writes are retried on failure but not deleted, there must be some failed records (manifested as failed records on some replicas and padding on others).
GFS’s strategy is to leave the handling of these erroneous records to the reader. The specific handling method is: for corrupted records, the checksum written by the writer can be used to verify and skip them; for duplicate records, the writer provides a record id, which the reader can use to filter during reading.
Of course, the code for the above logic is built into the library functions, and application-layer code can call it conveniently.
System Interactions
All read and write flow designs have a basic principle—minimize the participation of the Master node. Because the Master node easily becomes a single-point bottleneck. Next, I will describe in detail how the client, master node, and chunk servers interact to complete data changes, atomic record appends, and snapshot operations.
Leases and Mutation Order
File modifications on a distributed system include metadata modifications and chunk writes and appends. Chunk modification operations act on all its replicas, and an order needs to be determined when writing to different replicas. As mentioned earlier, we need to reduce the Master’s involvement as much as possible, so this decision cannot be made directly by the Master. GFS uses the mechanism of leases: the Master periodically authorizes a chunk’s replica on a certain server (with a timeout, hence called a lease). The replica that receives the authorization is called the primary replica, which arranges the write order. In this way, the Master delegates some authority to the server where a certain replica resides for a period of time. That is, there are two restrictions:
- Scope of authority. Only for all read and write operations of this chunk.
- Lease duration. There is a timeout (initially 60s) and needs to be renewed periodically. Generally, as long as it is alive, the Master will agree to its renewal request. However, occasionally the Master will actively revoke a lease to prevent a specific chunk from being modified, for example, before taking a snapshot.
Using leases does reduce the interaction between the client and the Master node, but it heavily relies on clock synchronization among multiple nodes. For example, suppose each lease carries a timestamp of its expiration. This timestamp is generated on the Master and checked on the primary replica. If the primary replica’s clock is slow, the Master may consider the lease expired before it renews, and thus authorize the lease to another replica. At this point, there are two primary replicas simultaneously, which can cause some problems. In addition, if the network between the Master and the primary replica is disconnected, the Master authorizes the lease to another node, while the client still caches the address of the original primary replica and can communicate with that node, which will also cause problems.
Let me now explain the write flow step by step with reference to the flowchart:
write control and data flow
- The client asks the Master for the locations of the primary replica and other replicas of the chunk to be written. If there is no primary replica yet, the Master authorizes one through a lease.
- After the Master sends this information to the client, the client caches it. And unless the primary replica is unreachable or its lease expires, the client will not send further requests to the Master.
- The client pushes the data to be written to the chunk servers where each replica resides. A noteworthy design is that GFS decouples the data flow from the control flow, that is, the client can push data in any order without having to go through the primary replica first and then the secondary replicas, as with the control flow. This allows us to optimize the data flow independently and even push in parallel; this is very beneficial for large chunk writes and will be discussed in detail in the following chapters. Each Chunkserver does not immediately write to disk upon receiving data, but places it in a cache using an LRU strategy. This is also an operation to decouple network I/O from disk I/O—one is to improve efficiency, and the other is to wait for the primary replica to arrange the write order.
- When the client is informed that all replicas have received the data push, it sends a write (flush to disk) request to the primary replica server. The primary replica server arranges a write order for the write requests from multiple concurrent clients (if any) (assigning a serial number to each write request) and writes it to the operation log mentioned earlier.
- The primary replica server forwards the client’s write request and serial number to the other replica servers. With this uniquely corresponding serial number, the flush order of all replicas can be kept consistent.
- All secondary replica servers report back to the primary replica server after flushing to disk.
- The primary replica server replies to the client. If any replica write has a problem, it will be reported to the client. If a problem is encountered, there are two possibilities: a. none of the replica data has been flushed to disk. b. some replica data has been flushed successfully. For the latter, an inconsistent state will appear. The client’s library code (meaning no application code handling is needed) detects the error and retries. Therefore, before truly successful writing, steps 3~7 may be repeated multiple times.
It should be noted that there is a special case: if the data to be written is too large and exceeds the designed chunk size, it is split into multiple writes. The flow of each write is the same as above, so the data order of all replicas will definitely be consistent. But if other clients are also writing at the same time, then the data of this write request may be interleaved, resulting in the consistent but undefined state mentioned earlier.
Data Flow
GFS decouples control flow and data flow to fully utilize network bandwidth. Control flow always goes from the primary replica to the secondary replicas, but data flow can be dynamically adjusted according to the actual situation. The main goal is to maximize the use of network bandwidth, avoid network bottlenecks, and minimize data transfer latency.
GFS’s main means are:
- Use network topology to organize the transfer order.
- Transfer data in a linear, pipelined manner.
For the first point, GFS uses IP organization to reflect network topology—that is, the relationship between IPs can determine the network proximity of nodes.
For the second point, tree-shaped transmission may cause the root node’s load to be too heavy and fail to distribute load and network bandwidth evenly. But if it is simply linear synchronization without pipeline parallelism, the efficiency will be very low.
Record Append
GFS provides an atomic append operation called Record Append. Unlike a write operation that needs to specify an offset and data, a record append operation only needs to specify the data. After a successful write, the offset of the successfully written record will be returned to the client. If multiple clients concurrently write to the same area, it is highly likely to cause data overlap: that is, the data in the overlapping area partly comes from client A and partly from client B, resulting in inconsistency. But for the record append operation, the system guarantees the atomicity of the written data (i.e., the content of a single record comes from only one client) and reliability through the following means:
- If multiple clients are encountered concurrently, the system uniformly arranges the append order, and a single record append will not be interrupted.
- If an append fails due to node or network failure, the record will be retried, that is, guaranteed to be written successfully at least once.
This setting is a bit like in the Linux file system, where multiple threads use the O_APPEND flag for file append operations. After setting this flag, the Linux system call guarantees that moving to the end of the file and appending data is an atomic call. For the record append operation, GFS also provides a similar atomicity guarantee. It’s just that Linux is for multiple processes, while GFS is for multiple clients that may be across nodes.
GFS’s applications with multiple clients distributed across multiple machines concurrently writing to a file heavily rely on this operation. If GFS only supported traditional write operations, such applications would have to perform mutually exclusive writes themselves to ensure data does not overlap—for example, distributed locks, but the code complexity would go up, and performance would likely go down. In the scenarios faced by GFS, the characteristic of atomic record append is often used to treat files on GFS as a multi-producer, single-consumer queue, or as a medium for multiple clients to merge results (for example, the merge of results after multiple Partition Reduces in MR).
Specifically, in implementation, only slight modifications to the data flow mentioned in Figure 2 above are needed. After data is pushed to each backup node, the client sends a flush request to the primary backup node. The primary backup node first checks whether the current chunk will exceed the specified chunk size (64 MB) after the data is written. If it exceeds, it does not flush to disk but fills the remaining space of the current chunk with padding (for example, filling in special characters), and then prompts the client to retry. Therefore, append writes have a requirement on the maximum size of a record: it cannot exceed one quarter of the chunk size, so that each append write wastes at most one quarter of each chunk.
If the record fails to write on any backup node, the client will retry the append operation. This may result in more than one copy of the record data existing in a certain backup. As mentioned in the consistency section earlier, GFS does not strictly guarantee byte-by-byte consistency among all backups; it only guarantees that the record is atomically written successfully once as a whole, and the offsets of this successful data in each backup are consistent. Only in this way can a single offset be returned to the client, and the next operation can perform the next write from the same offset.
According to the consistency model defined earlier, for the record append operation, successfully written requests are defined and therefore consistent. Unsuccessfully written requests are inconsistent, that is, undefined. As for how applications handle these failed write parts when reading, this has been discussed earlier and will not be detailed here.
Snapshot
The snapshot operation can quickly make a copy of a single file or a file directory tree. Note that this interface is exposed to users, rather than being used only by the system for its own backups as in some systems. Users usually use this operation to copy large datasets and to back up before experimental operations.
In implementation, like AFS, it uses copy-on-write (COW) technology. When a snapshot operation is to be performed, the Master recalls the leases of all chunks contained in the files to be copied, temporarily freezing writes to these files to perform the copy. During copying, only the metadata of these files is copied; the copied metadata logically becomes a new file, but its data still points to the original file.
After the snapshot operation, when a client wants to write to a file that has been snapshotted, it first asks the Master for the lease holder. The Master notices that the reference count of this chunk exceeds 1, so instead of authorizing the lease immediately, it instructs the chunk C and its replica servers to make a local copy of the chunk on each of their replicas, producing a new chunk C’. The Master then modifies the file reference to the new chunk and authorizes a lease to one of the replicas, then returns the authorized replica to the client.
In this way, the Client can write a new file without awareness. And all copy-on-write occurs locally to speed up copying and reduce network overhead.
Master Operations
The Master is responsible for all file namespace operations. In addition, it is responsible for managing system-wide operations related to chunk replicas, including:
- Replica placement decisions
- Chunk creation
- Re-replication of replicas
- Load balancing among chunk servers
- Reclaiming useless resources
The above will be discussed one by one below.
Namespace Management and Locking
Some operations on the Master, such as snapshot operations, are very time-consuming because they need to recall the leases of all related chunks. But GFS does not want these time-consuming operations to interrupt other operations, while at the same time ensuring that operations do not interfere with each other. So there can only be one solution—region-based locking. When multiple operations act on different file regions, they can proceed in parallel; when they act on the same file region, they need to be mutually exclusive through locks.
Unlike traditional file systems, GFS does not have a dedicated data structure for each directory (such as an inode) to list all files in that directory. GFS also does not have operations for aliases of files or directories (corresponding to hard links and symbolic links in Unix-like file systems). GFS uses a lookup table to store the mapping from file paths to their metadata, and uses prefix compression to optimize storage (so it seems likely to use a compressed trie as the data structure?).
Valid nodes in the namespace tree are either a file path or a directory path. GFS assigns a read-write lock to each node as the data structure foundation for namespace mutually exclusive operations. Specifically, whenever a namespace change operation (rename, file creation/deletion, etc.) is involved, locks must be acquired node by node along the file path from front to back. For example, for the path /d1/d2/…/dn/leaf, the Master will acquire read locks for /d1, /d1/d2, …, /d1/d2/../dn in turn, and then acquire a read or write lock for /d1/d2/…/dn/leaf based on the operation type. Of course, the leaf may be a file or a directory.
Using this lock acquisition strategy can guarantee that when /home/user is snapshotted to /save/user, /home/user/foo cannot be created at the same time. According to the strategy described above, GFS will acquire read locks for /home and /save and write locks for /home/user and /save/user when doing a snapshot. When creating /home/user/foo, it will need to acquire read locks for /home and /home/user and a write lock for /home/user/foo. Therefore, these two operations must be mutually exclusive, because they can only have one operation acquire the lock for /home/user at the same time.
One question is, for “parent” nodes on the path, only a read lock is needed. Because GFS does not have a true file system hierarchical organization or inode-like concept. Therefore, it is only necessary to acquire a read lock for the parent node to prevent it from being deleted, rather than acquiring a write lock for the inode as in traditional file systems to exclusively change its metadata. Another benefit of this is that multiple clients can concurrently write multiple files to a directory, because each client only needs to acquire the directory’s read lock, thereby preventing the directory from being deleted, renamed, or snapshotted, which is sufficient. For the same file, a write lock needs to be acquired, thereby serializing multiple clients’ modification requests to the same file (meaning arranging a specific order, not serialization in the sense of data structure serialization/deserialization).
Another natural question is, will acquiring so many locks for each operation cause deadlocks? The answer is no, because for the same file region (for example, the same file path), the order of lock acquisition is the same for each operation (according to the file path, different layers are from top to bottom, and the same layer is in alphabetical order). Therefore, for the same resource, the hold-and-wait situation will not occur, and the conditions for deadlock are not met. Since each operation needs to acquire many locks, and GFS wants to ensure as high throughput and concurrency as possible, it is necessary to release unused locks in a timely manner to avoid unnecessary waiting.
Replica Placement
The physical environment faced by GFS is multi-level: a single GFS cluster may span thousands of machines on multiple racks in multiple data centers, so there are three levels: data center -> rack -> physical machine. But generally, a GFS cluster is limited to a single data center, so there are also two levels. Thus, communication between different chunk servers may cross racks through switches. And the intra-rack network bandwidth is generally greater than the inter-rack network bandwidth. This multi-level network topology poses great challenges for GFS to maintain scalability, reliability, and availability—of course, this is also a problem faced by any distributed system design.
Based on this, GFS’s replica placement strategy has two major goals:
- Maximize the reliability and availability of large data.
- Maximize the utilization of network bandwidth.
To satisfy the first point, we can’t put all our eggs in one basket—that is, Chunkservers in the same cluster cannot be placed in only one rack, to tolerate entire rack failures. At the same time, this means there will be a large number of cross-rack read and write requests, which can fully utilize network bandwidth on the one hand, but cross-rack read and write requests will have some performance issues on the other hand. In short, it’s all about trade-offs.
Creation, Re-replication, and Rebalancing
Chunks are created in three situations: initial chunk creation, re-replication, and cross-node rebalancing.
First, when the Master is choosing locations for a newly created chunk replica, it considers the following factors:
- Node disk utilization. To make data distribution balanced.
- The number of recent replicas on the node. Most scenarios faced by GFS are multiple reads after a single write. To balance the load, recent writes should be distributed across as many nodes as possible.
- Multi-rack distribution of multiple replicas.
Second, when the actual number of surviving replicas of a chunk is less than the system-set value, the re-replication process is started. There are many reasons for re-replication, such as certain machines going down, certain disks failing, or the set value for certain chunks increasing, and so on. There are generally many chunks in GFS, so there may be many chunks needing re-replication at the same time. Therefore, we must arrange a priority for all re-replication requests. When arranging the order, there are several points to consider:
- The difference between the surviving number and the set value. The more replicas are missing, the higher the priority. This is not hard to understand: after all, the more missing, the greater the danger that the chunk cannot be recovered.
- The activity status of the file. Take two extreme examples: if a file has been very active recently, such as being created, then re-replication of the chunks contained in that file is prioritized. If a file has just been deleted, then obviously we no longer need to operate on it.
- Whether it blocks the current client operation. If a client is waiting because the number of replicas of a certain chunk is insufficient, then the re-replication request for this chunk is prioritized.
After sorting all re-replication requests according to the above three factors, the Master gradually selects the highest-weight request and instructs a certain chunk server to perform replica copying. The placement strategy after copying is generally the same as the initial creation placement strategy. In order not to affect normal client requests, GFS limits the number of replica copying processes both cluster-wide and within a single chunk server. At the same time, it also limits the total bandwidth for re-replication at the bandwidth level.
Finally, the Master periodically performs system-wide chunk migration to fully utilize disk space and balance the load. At the same time, this periodic operation also slowly fills a newly joined node in the cluster, rather than directly directing all write requests there to quickly fill the node. The latter can easily cause request oscillation and increased system complexity. When deleting replicas, it tends to target nodes with less remaining disk space than the average; when adding replicas, the strategy is roughly the same as at creation time.
Garbage Collection
When a file on GFS is deleted, GFS does not immediately reclaim the corresponding physical storage. Instead, unused storage is reclaimed at both the file level and the chunk level through a periodic garbage collection program. Decoupling deletion and reclamation makes the system simpler and more robust. As for why, let me explain one by one.
Basic Mechanism
Like other operations, when a GFS user deletes a file, the Master immediately records it in the operation log. The difference is that GFS does not actually delete the file and reclaim the corresponding resources immediately, but renames the file to a hidden file and tags it with the deletion operation timestamp. GFS’s file system namespace has periodic checks. When a hidden file has existed for more than three days (this is a configurable item for operators), its metadata is deleted. Note that at this point, the data corresponding to the file is still on the chunk servers; we just can’t find them anymore.
Like the periodic checks of the namespace on the Master (file path to logical chunk), the Master also checks all chunks (logical chunk to physical replica). When it finds that certain logical chunks cannot be accessed through any file (combined with the Snapshot operation mentioned earlier, we can guess that logical chunks maintain a file reference count, so as long as the reference count drops to 0, it means the logical chunk is no longer referenced by any file and becomes an orphan chunk), it deletes the information of that logical chunk. Note that at this point, it still does not synchronously delete the data on the chunk servers.
Each chunk server periodically reports the information of the physical chunk replicas it holds to the Master. After receiving this information, the Master looks up the corresponding information in the chunk-to-physical-replica set mentioned above one by one, and brings this information back in the heartbeat RPC response. After the chunk server gets the information of all orphan physical replicas on its machine, it truly deletes these replicas (I’m not sure if this step is synchronous; most likely not).
Additional Discussion
Although garbage collection is a complex topic for programming languages, under GFS’s assumptions, locating garbage chunks is quite simple. Its tracking mainly relies on the two data structures mentioned earlier. One is the mapping from file path to logical chunk; all chunks not referenced in this mapping are useless chunks. The other is the mapping from logical chunk to physical replica (stored in the form of Linux files), which is built from heartbeat reports from each chunk server. All chunks existing on chunk servers but unknown to the Master (i.e., their corresponding logical chunks are no longer in the first mapping) can be considered garbage.
Compared to synchronous deletion responses, asynchronous garbage collection has many benefits:
- In large clusters with various errors, garbage collection is simpler and more reliable. In an unreliable environment, creation may fail, deletion may fail, and modifications may also fail, so these operations may all leave garbage. For synchronous deletion, if an error occurs, the erroneous data must be recorded and retried continuously. Garbage collection can provide a unified way to recover the garbage left by the above errors. If synchronous deletion were used to handle garbage left by other errors, a lot of redundant and similar code would be generated.
- Garbage collection turns scattered deletion operations into regular centralized cleanup. Batch reclamation may be more efficient. And because all garbage collection operations are centralized in the Master’s periodic checks, the specific timing of operations can be chosen to avoid peak periods of normal user requests.
- Asynchronous, lazy garbage collection can also handle accidental deletion operations.
Everything has its pros and cons. The asynchronous, lazy garbage collection strategy is quite frustrating when we really want to delete certain data immediately. In addition, if a large number of temporary small files are generated, it will greatly affect cluster utilization. To solve these problems, the following optimizations can be made:
- After a deleted file becomes a hidden file, if it is explicitly deleted again, we will speed up its deletion pace.
- Divide and conquer by file namespace. For example, users can specify that files under certain directories are not multi-replicated; or they can stipulate that files under other directories will be truly deleted immediately after deletion.
Of course, this will bring additional logic and implementation complexity. How to implement it elegantly in an unreliable environment and how to make it compatible with existing code logic are other, less pleasant things to do.
Stale Replica Detection
When a chunk server goes down and recovers, some chunks it stores may have been modified during this period, causing the replicas of the corresponding chunks on that server to become stale. To solve this problem, GFS introduces versions for logical chunks to identify whether different replicas of the same chunk are stale.
The specific approach is that every time the Master authorizes a lease for a chunk, it increments the version number and notifies all replicas to update it. Both the Master and all replicas persist the latest version number. Then the Master sends the lease-holding replica and the updated version number to the client. When the client reads or writes data, it checks all replicas one by one against the latest version number to see if they are the latest replicas. All stale replicas are treated as non-existent, and the garbage collection program mentioned above periodically clears them.
Fault Tolerance and Diagnosis
A major challenge in the design and construction of GFS is that individual components are unreliable while the number of components is particularly large. We can neither fully trust machines nor fully trust disks. Component failures can lead to system failures and even data corruption. Next, let’s talk about the problems GFS encountered in this regard and its solutions.
High Availability
For clusters composed of hundreds of machines, component failures may occur at any given moment. To deal with these problems, GFS uses two strategies that seem simple but are effective: data replication and fast recovery.
Fast Recovery
There are three roles in the GFS system: Master, Chunkserver, and Client. The first two are designed to quickly recover their state no matter how they die; the last one will do some retry strategies through the provided system library when encountering problems. In fact, GFS does not distinguish between manual shutdown, accidental exit, or occasional timeout; all failed components will be quickly restarted, retried, and reconnected (for the client).
Chunk Replication
As mentioned earlier, chunks are replicated three times by default, but the application side can adjust the number of chunk replicas by namespace (for example, under a certain directory). In the GFS system, the Master controls keeping the number of chunk replicas meeting the requirements. That is, when the number of chunk replicas falls below the set value due to Chunkserver downtime, checksum errors, user settings, and so on, the Master will instruct a Chunkserver to add replicas. Sometimes, even if the number of replicas meets fault tolerance requirements, GFS will increase the number of replicas for high concurrency and other needs. In addition, EC and other cross-machine redundancy methods have also been explored. Of course, GFS hopes to implement these additional designs in a loosely coupled manner, after all, GFS traffic faces appends and sequential reads rather than random writes.
Master Redundancy
The Master’s state is persisted locally in the form of an operation log and synchronized to multiple other physical machines. An operation in GFS is only considered applied to the file system after being committed to the operation log; however, to avoid affecting normal file operations and background work, these are done by additional processes. If a process dies, it will be quickly restarted. If the Master disk or system fails and cannot provide service, GFS’s external infrastructure will detect it in time, restart a Master on another machine, and recover its state through operation log replicas. So how does the client discover the new Master? GFS uses a host name rather than a specific IP for the client to connect to the Master, so only the internal DNS needs to be modified to point the Master host name to the new machine IP.
In addition, shadow Masters can be used to offload read pressure. Shadow Masters will sacrifice some latency, usually around one second. Therefore, they are suitable for dealing with traffic for files that don’t change much or are not very sensitive to slightly stale data. All decisions (mainly the location decisions of each replica) depend on the real Master. Shadow Masters only do passive information synchronization, that is, either by loading operation logs or by handshaking with chunk servers to obtain information.
Data Integrity
Chunk data servers use checksums to discover corrupted chunks. Considering that a GFS cluster usually consists of thousands of hard disks spanning hundreds of machines, encountering corrupted data blocks during reads and writes is normal. GFS will recover corrupted replicas through other replicas, but byte-by-byte verification of different replicas to ensure data correctness is not feasible. First, the performance cannot tolerate it; second, GFS does not guarantee byte-by-byte consistency of multiple replicas (for example, incomplete data blocks left by parallel append retries). Therefore, each chunk server verifies the chunks under its jurisdiction separately through checksums.
Each chunk is divided into small blocks of 64 KB, and a corresponding 32-bit checksum is constructed as metadata stored in memory and persisted through the operation log. That is, the checksum and the actual user data are stored separately.
Before reading, mainly including client reads or other chunk server reads, the chunk server verifies the checksums of all small blocks corresponding to the read data range. If the verification is inconsistent, the chunk server returns an error and reports it to the Master, so data corruption does not propagate among chunk servers. After receiving the error report, the requester will read other replicas, and the Master will instruct a selected chunk server to copy it to maintain the effective number of replicas. After the new replica is in place, the corrupted replica will be treated as garbage and reclaimed. The impact of checksums on read performance is not significant. First, the additional storage and computation overhead is not large. Second, the checksums are all stored in memory, and their calculation and verification do not consume additional I/O and can be performed in parallel with data flow I/O.
Write requests include conventional writes and parallel append writes. The latter is the main traffic of GFS, and GFS has highly optimized checksum handling for it. Each time, only the checksum of the last small block needs to be continuously updated. But for overwrite writes at a specified offset, before writing, the first and last small blocks corresponding to the write range must be verified first, because they may be partial writes. If directly partially overwritten without verification, the fact that the original data block was already corrupted may be hidden.
Finally, chunk servers periodically verify inactive chunks. If any inconsistency is detected, it will report to the Master as described in the previous process, re-backup the chunk, and then delete the corrupted chunk.
Diagnostic Tools
GFS saves additional system logs for problem diagnosis, bug debugging, and performance analysis. This brings very little extra space overhead. But without saving these logs, it may be difficult to understand some system behaviors between machines afterwards. Due to the complexity of the network and the instability of ordinary commercial machines, the scenarios at the time may be difficult to reproduce. Of course, how to record appropriate log events also requires some experience and skill. GFS records some machine-critical events (chunk server up/down), all RPC requests and responses, and so on. As long as space permits, GFS saves as many system logs as possible.
By collecting all RPC requests, the history of system interactions between GFS components can be reconstructed to assist in problem diagnosis. We can also mine logs to track their load distribution. Once again, recording these logs does not have much impact on normal client requests, because all logs are recorded asynchronously and sequentially. All real-time state information is stored in memory and presented to users in the form of monitoring pages.
Glossary
Master: The master node, the central node in a GFS cluster used to maintain file system metadata and central control, actually manifested as a group of processes on the Master node.
Client: The client, specifically referring in this article to the application connecting to the GFS cluster to perform file operations.
Chunkserver: The chunk server, a data node that stores chunks in ordinary Linux files (actually a process running on the node).
consistent but undefined: Sometimes refers to a certain replica of a chunk; sometimes refers to the server where a certain replica of a chunk resides.
Operation Log: The operation log, used for error recovery and determining the order of concurrent writes.
consistent but undefined: Consistent but undefined, referring to when multiple clients write concurrently. Although the final data order of the replicas is consistent, if a client reads the data again, it does not know whether it can read the data it wrote or the data overwritten by other clients.
Primary Replica: The primary replica/backup, or the node where the primary replica/backup resides.
Re-replication: Translated as replica/backup replenishment.
References
- GFS paper: https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/gfs-sosp2003.pdf
- 铁头乔 GFS consistency summary: https://blog.csdn.net/qiaojialin/article/details/71574203

