 ray-task-state-transfer.png
ray-task-state-transfer.png
I previously wrote a translation of the Ray paper. Later, I spent some time reading Ray’s source code. To learn and retain knowledge, I plan to publish a series of source code reading articles. To sustain continuous updates, I will try to break down the modules into smaller pieces to keep each article short. Also, due to limited experience, my understanding of the source code may contain inaccuracies—feedback and discussion are welcome.
Author: Woodpecker’s Notes https://www.qtmuniao.com, please indicate the source when reposting
Overview
One of Ray’s core designs is fine-grained, high-throughput task scheduling based on resource specifications. To achieve this, Ray stores all inputs and outputs in shared-memory-based Plasma; stores all states in Redis-based GCS, and then performs decentralized scheduling based on this. That is, every node can access global information to make local scheduling decisions, though this is also one reason why complex scheduling strategies are difficult to implement.
Ray tasks are divided into two types: stateless Tasks and stateful Actor Methods, the latter of which can be further divided into Actor Create Methods (corresponding to constructors) and ordinary Actor Methods (corresponding to member functions).
Ray allows explicit specification of task resource constraints (mainly CPU and GPU), so it needs to quantify all node resources at the framework level (ResourceSet) to perceive increases, perform allocation, achieve reclamation, etc. During scheduling, it needs to find nodes that satisfy the task resource constraints and schedule the task there.
Since all Task inputs are stored in distributed in-memory storage Plasma, after scheduling a Task to a certain node, the dependent inputs need to be transferred across nodes. Alternatively, the task could be directly scheduled to a node that satisfies the dependencies, but in fact Ray does not do this for general Tasks—the reasons will be discussed in detail later. For Actor Methods, since the corresponding Actor resides on a certain node, all related Actor Methods will definitely be scheduled to that node.
The node where the task is located, its current state, the location of dependent objects, etc., are all stored in the Global Control Store (GCS). Therefore, after each state change, it needs to interact with GCS to write the state. When a task fails due to node disconnection or crash, the task will be retried based on the state information stored in GCS. By subscribing to certain state change events in GCS, task state transitions can be driven.
There are also snapshot recovery based on lineage + snapshot, Actor lineage construction, etc. I’ll leave these as cliffhangers for now and will discuss them in detail in later articles in this series.
This article focuses on the state transitions and organization of all tasks.
State Machine
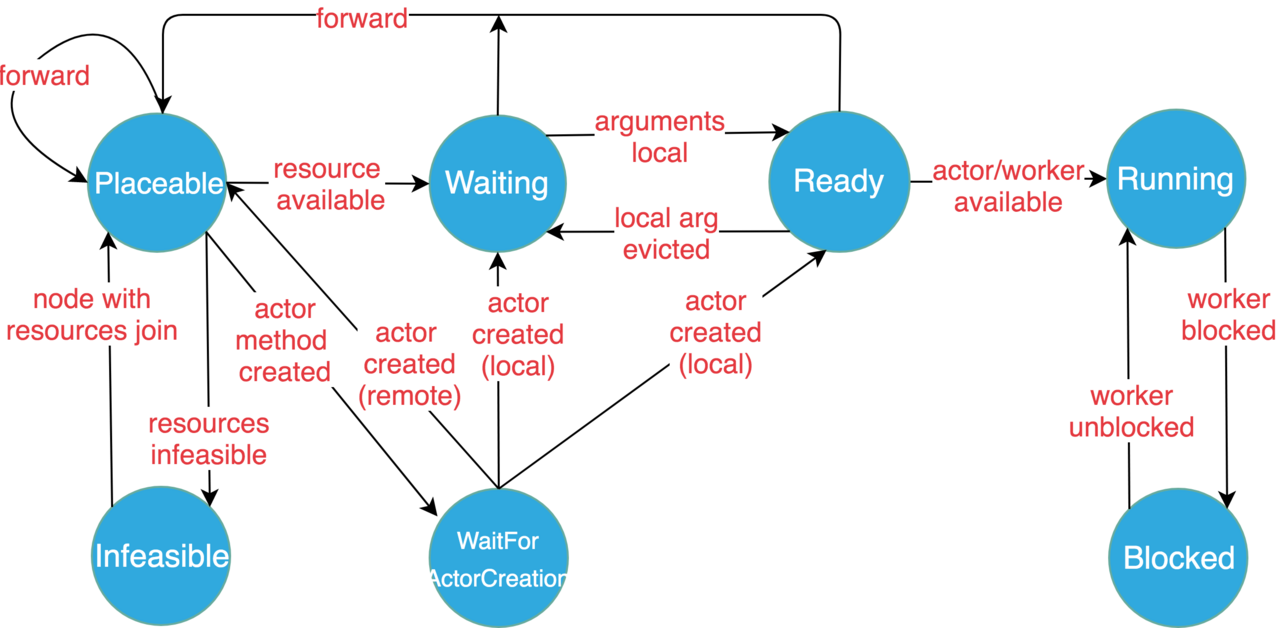
Complex task scheduling inevitably requires a reasonable state machine to describe it. The following are the task state definitions and transition diagrams given in the Ray documentation.
State Definitions
- Placeable: The task is ready to be scheduled to a node (local or remote). The scheduling decision is mainly based on the matching degree between the task’s resource constraints and the node’s remaining resources. The location of the task’s dependency objects is not currently considered. If the local node satisfies the task’s resource requirements, the task is arranged to execute locally; otherwise, it will be forwarded to another node that satisfies the resource requirements. However, this state decision is not necessarily final—the task may still be spilled over to another node later (because resources were satisfied at the scheduling moment, but at execution time, other tasks had already been executed, causing the node to no longer satisfy the resource constraints).
- WaitForActorCreation: An Actor Method waits for its Actor instance to be created (mostly occurs during Actor error recovery; otherwise, generally the Actor Create Method is executed first). Once the Actor instance is created and perceived by the Actor Method through GCS, it will be scheduled to the node where the Actor instance is located.
- Waiting: The task waits for its input objects to be satisfied, e.g., waiting for task function argument objects to be transferred from other nodes to the local object store.
- Ready: All objects that the task depends on are in the local object store, so the task is ready to run locally (referring to the node where the task is currently located, same below).
- Running: The task has been scheduled to execute locally, running in the local Actor or Worker process.
- Blocked: Some dependency objects of the task are unavailable (i.e., not local). How could it run before if they weren’t local? Let me explain: Ray tasks support nested calls (corresponding to nested remote function calls). If task A generates task B during execution and waits for its result to return (
ray.get), task A will be blocked, waiting for B’s execution to complete. - Infeasible: The task’s resource requirements cannot be satisfied by all resources of any machine in the current cluster (note: not remaining resources). But if a new machine joins the cluster, it can be tested whether these tasks’ resource requirements can be satisfied.
State Transition Diagram
Task State Transition Diagram
State Enum Class
The state enum class is defined in scheduling_queue.h:
1 | enum class TaskState { |
Compared to the states in the state machine, there are a few extra enum values here, including SWAP and DRIVER. There is also the magical kNumTaskQueues; I’ll set this aside for now and talk about the first two.
- SWAP: Task dispatch is asynchronous. That is, after Ray assigns a Ready task to a Worker, only in the callback function can we finally know whether the assignment succeeded or failed, and thus transfer the task state to Running or Ready. But during this gap, what state should the task be in? This is the role of Swap (though I don’t know why it’s not explicitly included as a state in the state machine).
- DRIVER: This simply identifies a task as a user code process, thus unifying all tasks under one management scheme.
Task Queue (TaskQueue)
Ray organizes all tasks into queues by state (TaskState), and these queues are the task queues (TaskQueue). Each queue defines basic operations such as adding, removing, and searching for tasks. In addition, there is an important interface: getting the sum of resources required by all tasks in that queue. For example, when scheduling a task, to know a node’s remaining available resources, you need to subtract the resources required by running tasks and ready tasks (which need to be scheduled locally first) from the node’s total resources.
It is worth mentioning that when deleting tasks, if the removed_tasks parameter is not a null pointer, the deleted tasks are placed inside. This way, if multiple deletions occur, tasks can be collected into an array.
Another somewhat redundant point: through task.GetTaskSpecification.TaskId() you can get the task_id, so I don’t know why task_id is also added as a parameter in AppendTask—for consistency?
As for the specific implementation, it uses the classic linked list + hash organization. This allows O(1) time for add, delete, modify, and query operations, and O(n) time to get all tasks—just traverse the linked list.
1 | class TaskQueue { |
On this basis, a ReadyQueue is built specifically for the Ready state. It mainly adds a mapping from ResourceSet -> Task Ids: that is, an additional index that groups all ready tasks with the same resource requirements together. This way, during scheduling (DispatchTasks), if a task’s resource requirements cannot be satisfied by the local node, all tasks with the same resource requirements are skipped, which is a scheduling optimization (corresponding logic is in NodeManager::DispatchTasks).
Scheduling Queue (SchedulingQueue)
Collecting the above task queues by state, plus the operations of moving tasks in and out of different queues, forms the scheduling queue (SchedulingQueue). When different events occur in Ray, they drive the state transitions within the task state machine, i.e., calling the interfaces exposed by SchedulingQueue to move tasks from one state queue to another and do some context conversion work, thereby implementing task scheduling.
Note that each node maintains a scheduling queue, storing all tasks held by that node.
1 | class SchedulingQueue { |
From the code above, we can see the following:
- All functions basically revolve around adding, deleting, modifying, and querying single or groups of tasks.
- All tasks are actually organized by a two-level index: task state -> (task id -> task). Therefore, to locate a task, you need to go through the task state layer first, so helper functions are created for this layer operation:
GetTaskQueue. In addition, there are many helper functions for moving tasks between different task queues. - The kNumTaskQueues mentioned above is a pseudo-state; it is essentially a boundary marker. After converting it to an integer, all states smaller than it organize tasks by task queue, while all states larger than it only use sets to store task IDs (blocked tasks and driver tasks).
- The ready queue receives some special treatment, because actually scheduling ready tasks to a worker for execution is a large part of scheduling. This extra treatment includes: a. maintaining a separate pointer for the ready queue; b. providing an interface to get the sum of ready queue resource requirements; c. providing an interface to group all ready tasks by the same resource requirements.
- There are also two interfaces for getting a group of resources by other dimensions:
GetTaskIdsForJobandGetTaskIdsForActor, which can respectively get a group of tasks based on a given JobId and ActorId.
Glossary
Task Required Resources: Task resource requirements or task resource constraints, specified by adding annotations on functions: ray.remote(num_cpus=xx, num_gpus=xx). Among them, GPUs can also be specified as fractional, to allow multiple tasks to share one GPU.
Task argument: Task input or task parameters. If translated as input, it is relative to the task; if translated as parameters, it is relative to the function parameters executed by the task.
Object: Here translated as data object.
Object Store: Immutable object storage based on memory, which is intra-node, inter-process shared storage distributed across various nodes.
Node, Machine: Refers to each machine that makes up the cluster. If we must distinguish, Node may be more logical, while Machine is more physical. But in Ray they correspond one-to-one, i.e., one machine has only one node.
That’s all for this article. The next article plans to cover scheduling strategies or resource definitions.

