boltdb is one of the few pure-Go, single-node KV stores out there. It is based on Howard Chu’s LMDB project, with a refreshingly clean implementation: stripping away unit tests and adapter code, the core is only about four thousand lines. Simple APIs and a minimalist implementation are exactly what the author intended. Due to limited maintainer bandwidth, the original boltdb has been archived and is no longer updated. If you want to contribute improvements or open new PRs, the etcd-maintained fork bbolt is the recommended place.
For convenience, this series of guided-reading articles still uses the original, now-frozen repo as its foundation. Though small, the project is fully featured: in just over four thousand lines of code it implements a single-node KV engine with a B±tree index and single-writer/multi-reader transactions. The code itself is plain and well-commented. If you are a Go enthusiast or interested in KV stores, boltdb is absolutely a repo you shouldn’t miss.
This series is planned as three articles, analyzing the boltdb source code around data organization, index design, and transaction implementation. Because these three aspects are not fully orthogonal, the narrative will inevitably intertwine; when you don’t understand something, just skip it for now and come back to sort it out once you have the full picture. This is the first article: boltdb data organization.
Overview
There are two commonly used index designs in databases: the B±tree and the LSM-tree. The B±tree is a classic—for example, traditional single-node databases like MySQL use B±tree indexes, which are friendly to fast reads and range queries. The LSM-tree has become popular in recent years; Bigtable, LevelDB, and RocksDB all bear its imprint; as mentioned in a previous article, LSM-trees use WAL and multi-level data organization, trading off some read performance for powerful random write performance. Thus, this is also a classic trade-off.
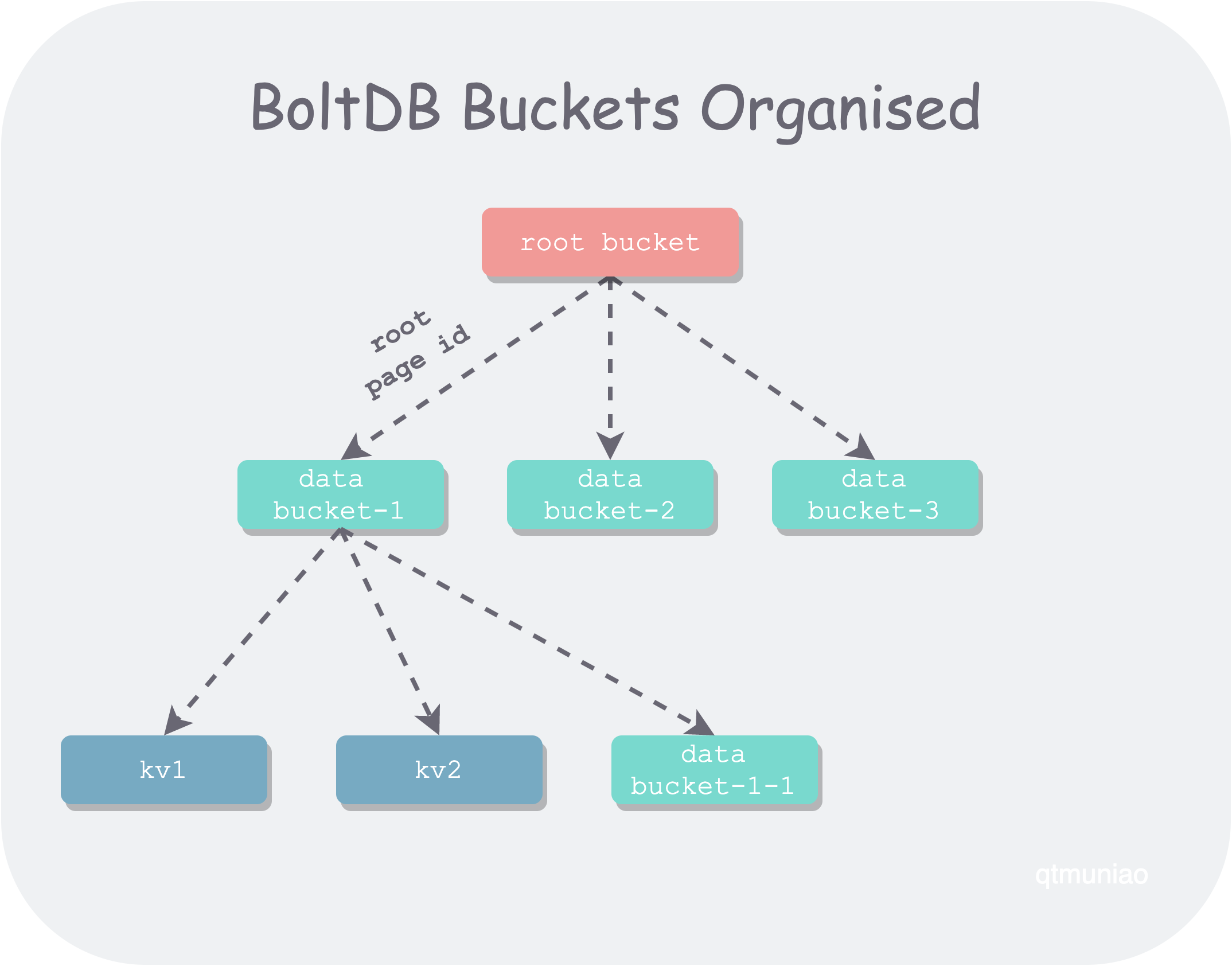
BoltDB logically organizes data into buckets. A bucket can be seen as a namespace—a collection of KV pairs, similar to the bucket concept in object storage. Each bucket corresponds to one B±tree, and namespaces can be nested, so BoltDB allows buckets to be nested as well. In terms of implementation, the child bucket’s root node page id is stored on the parent bucket’s leaf node to achieve nesting.
Each db file is a set of B±trees organized in a tree shape. As we know, in a B±tree branch nodes are used for lookup and leaf nodes store data.
- The top-level B±tree is special and is called the root bucket; all its leaf nodes store the page ids of child bucket B±tree roots.
- Other B±trees may be called data buckets; their leaf nodes may contain normal user data, or the page ids of child bucket B±tree roots.
 boltdb-buckets-organised.png
boltdb-buckets-organised.png
Compared to ordinary B±trees, boltdb’s B±tree has several special characteristics:
- The number of branches in a node is not a fixed range; instead, it is limited by the total size of the elements it stores, with the upper bound being the page size.
- The key stored in a branch node for each branch is the minimum key of the branch it points to.
- All leaf nodes are not linked together in a chain.
- It does not guarantee that all leaf nodes are at the same level.
In terms of code organization, the boltdb source files related to indexing are as follows:
- bucket.go: High-level encapsulation of bucket operations, including CRUD of KV pairs, CRUD of child buckets, and B±tree split and merge.
- node.go: Operations related to the elements stored in a node and relationships between nodes. Adding and deleting elements within a node, loading and persisting, accessing child/sibling elements, and the detailed logic of split and merge.
- cursor.go: Implements an iterator-like function that can walk freely over the leaf nodes of the B±tree.
This article is divided into three parts, revealing BoltDB’s index design from the local to the global. First, we will dissect the basic unit of the tree; second, analyze the bucket traversal implementation; finally, analyze the tree’s growth and balancing process.
Author: 木鸟杂记 https://www.qtmuniao.com/2020/12/14/bolt-index-design, please indicate the source when reprinting
Basic Unit — Node
The basic building block of a B±tree is the node, which corresponds to the page stored in the file system mentioned in the previous article. Nodes come in two types: branch nodes and leaf nodes. However, in the implementation they reuse the same struct, distinguished by a flag isLeaf:
1 | // node represents a deserialized page in memory |
Node/Page Conversion
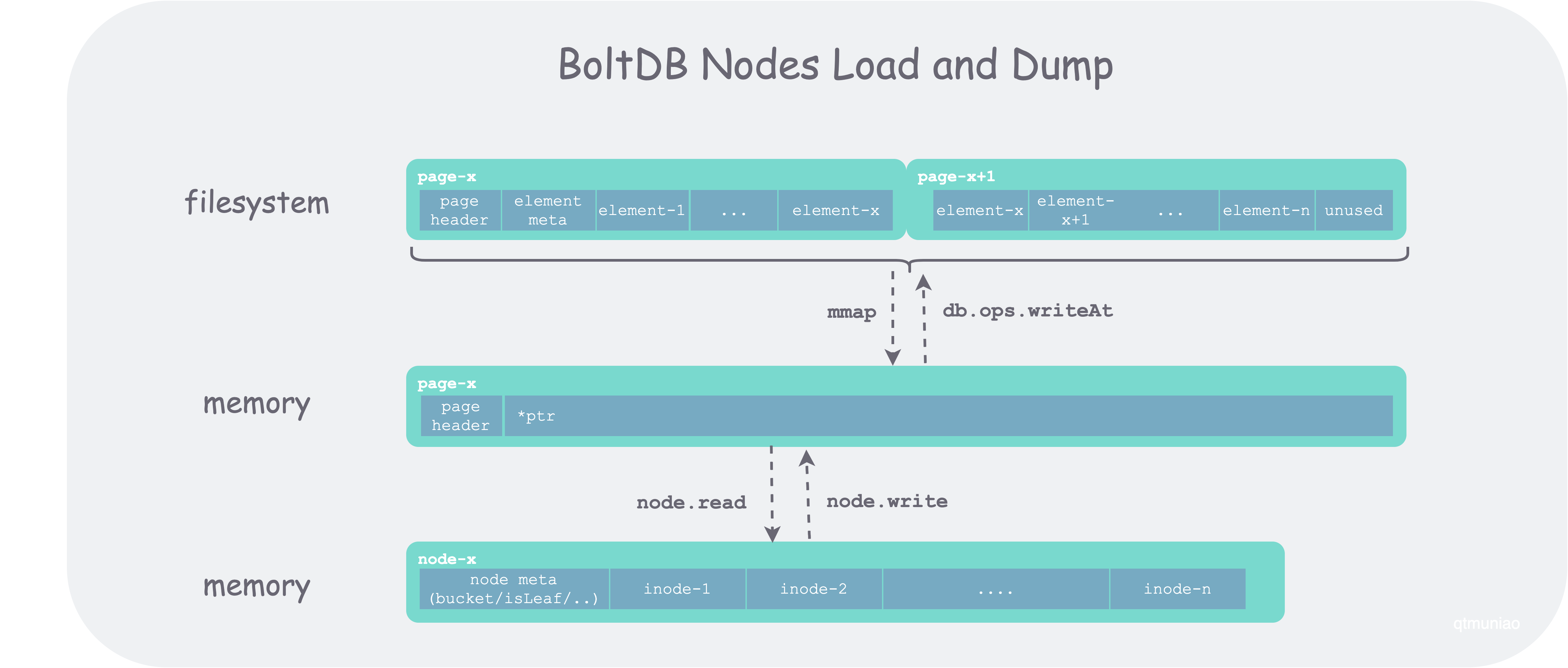
The correspondence between page and node is: a contiguous set of physical pages in the file system is loaded into memory as a logical page, which is then converted into a node. The figure below shows a contiguous segment of data occupying two page sizes on the file system, first mmap’d into memory space and converted to a page type, then converted to a node via node.read.
 boltdb-node-load-and-dump.png
boltdb-node-load-and-dump.png
The code for node.read converting a page to a node is as follows:
1 | // read reads a page via mmap and converts it to a node |
Node Element: inode
inode represents the internal elements contained in a node; branch nodes and leaf nodes also reuse the same struct. For a branch node, a single element is key + reference; for a leaf node, a single element is user kv data.
Note that the reference type to other nodes here is pgid, not node*. This is because the element pointed to by inode is not necessarily loaded into memory. When boltdb accesses the B±tree, it converts accessed pages into nodes on demand, and stores their pointers in the parent node’s children field. The specific loading order and logic will be detailed in a later section.
1 | type inode struct { |
inode is used for routing in the B±tree—that is, in binary search.
Adding Elements
All data insertion happens at leaf nodes. If the B±tree becomes unbalanced after insertion, it will later be split and adjusted via node.spill. The main code is as follows:
1 | // put inserts a key/value. |
The main logic of this function is fairly simple: binary search to find the insertion position; if it’s an overwrite, overwrite directly; otherwise, add a new element and shift everything to the right to make room. But the function signature is interesting: it has both oldKey and newKey, which seemed strange at first. It is called in two places:
- When inserting user data into a leaf node,
oldKeyequalsnewKey, so the two parameters are redundant. - During the
spillphase when adjusting the B±tree,oldKeymay not equalnewKey; in this case it is useful, but its purpose is still quite subtle from the code.
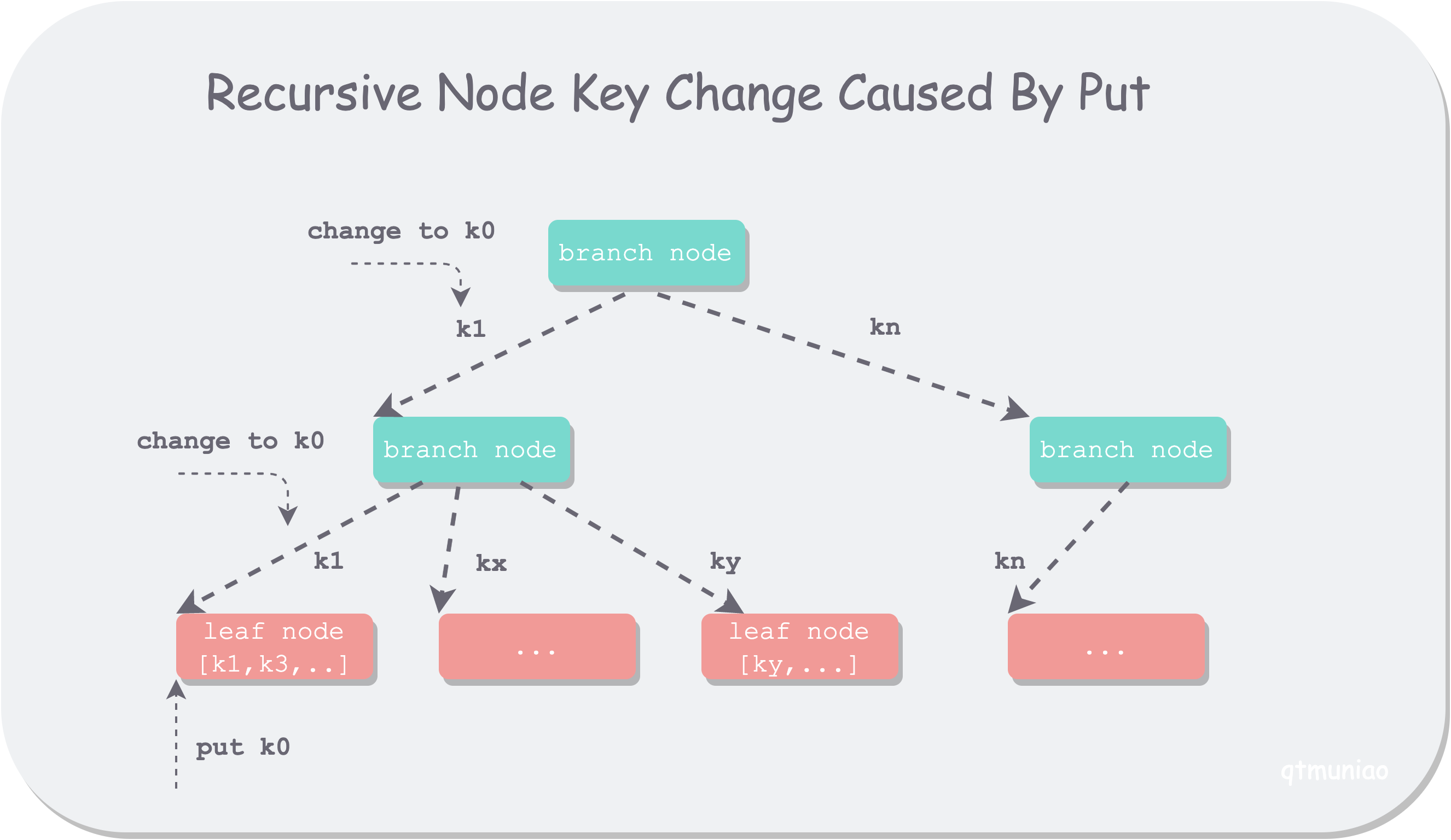
After discussing with friends, the conclusion is roughly as follows: to avoid a cascading update of ancestor nodes’ node.key when inserting a very small value at the leftmost side of a leaf node, the update is deferred to the final B±tree adjustment phase (spill function) for unified processing. At this point, the node.put function is used to update the leftmost node.key to node.inodes[0].key:
1 | // this code snippet is in the node.spill function |
 bolt-recursive-change.png
bolt-recursive-change.png
Node Traversal
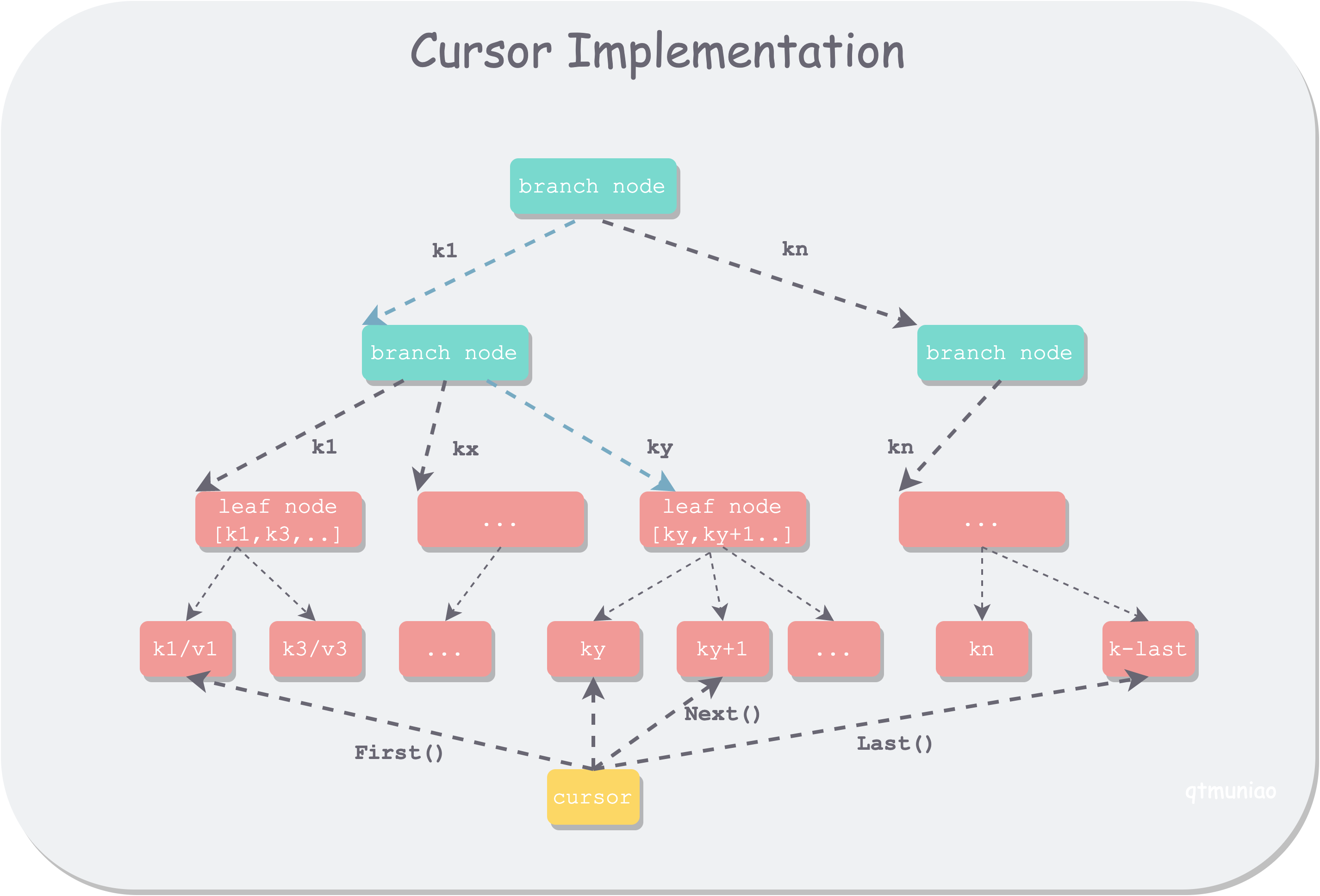
Since Golang does not support a Python-like yield mechanism, boltdb uses a stack to save traversal context and implements an iterator for in-order traversal of tree nodes: cursor. Logically, it can be understood as an iterator that traverses the elements stored in the leaf nodes of a B±tree. As mentioned earlier, boltdb’s B±tree does not use a linked list to connect all leaf nodes, so some extra logic is needed to handle various details during traversal.
This implementation increases traversal complexity but reduces the difficulty of maintaining the B±tree’s balance properties—another trade-off. Of course, the most important reason is to avoid cascading updates of all predecessor nodes when implementing transactions via COW.
 cursor-implementation.png
cursor-implementation.png
cursor is bound to a specific bucket and implements the following functions. Note that when the traversed element is a nested bucket, value = nil.
1 | type Cursor |
Because the left and right leaf nodes of boltdb’s B±tree are not linked together, traversal needs to record the path for backtracking. Its struct is as follows:
1 | type Cursor struct { |
The elemRef struct is as follows. Page and node are one-to-one corresponding; if a page has been loaded into memory (converted from a page), node is used preferentially, otherwise page is used; index indicates the position in inodes when the path passes through this node.
1 | type elemRef struct { |
Helper Functions
These APIs share some common logic in their implementation, so they can be extracted as building blocks. In particular, moving the cursor is implemented by adjusting the path represented by the cursor.stack array.
1 | // tail-recursive search for the node containing the key, recording the path in the cursor |
Composed Traversal
With the above building blocks, let’s go through the implementation of the main API functions:
1 | // 1. push the root node onto the stack |
These API implementations may seem somewhat tedious to describe, but as long as you grasp the main idea and pay attention to some boundaries and details, they are easy to understand. The main idea is quite simple: the cursor’s ultimate goal is to traverse the elements of all leaf nodes, but since leaf nodes are not linked together, a stack array is needed to record the traversal context—the path—to achieve fast access to predecessors and successors (because predecessors and successors likely share a prefix path with the current leaf node).
Some additional boundaries and details to note are as follows:
- Each move needs to first find the node, then find the element within the node.
- If a node has already been converted to a node, access the node preferentially; otherwise, access the mmap’d page.
- The key of an element recorded in a branch node is the key of the node it points to, i.e., the minimum key of the elements contained in that node.
- Using Golang’s
sort.Searchto get the index of the first element less than the given key requires some extra handling. - Several boundary checks: whether the node has elements, whether the index exceeds the element count, whether the element is a child bucket.
- When the key does not exist, seek/search locates the point where the key should be inserted.
Tree Growth
We will explain the lifecycle of the B±tree in boltdb across several time points:
- Database initialization
- After a transaction starts
- When a transaction commits
Finally, on the basis of understanding the states at these stages, we will tie together the whole growth process.
At Initialization
When the database is initialized, the B±tree contains only one empty leaf node, which is the root node of the root bucket.
1 | func (db *DB) init() error { |
Afterward, the growth of the B±tree is driven by additions, deletions, and adjustments of B±tree nodes in write transactions. By design in boltdb, write transactions can only proceed serially. BoltDB modifies nodes using COW to ensure concurrent read transactions are not affected. That is, the page to be modified is read into memory, modified and adjusted, and then a new page is allocated to persist the changed node.
This approach conveniently enables read-write concurrency and transactions; the reasons will be analyzed in detail in the next article of this series. But undoubtedly, the cost is high: even modifying or deleting a single key will cause all nodes along the B±tree path of the corresponding leaf node to be modified and persisted. Therefore, if modifications are frequent, it is best to do them in batches within a single transaction.
When a Bucket Is Small
When a bucket contains very little data, no new page is allocated for it; instead, it is inlined into the parent bucket’s leaf node. The logic for determining whether a bucket can be inlined is in bucket.inlineable:
- Contains only one leaf node
- Data size is no more than 1/4 of a page
- Does not contain child buckets
After a Transaction Starts
At each transaction initialization, a copy of the root bucket handle is made in memory, to serve as the entry point for dynamically loading nodes along the modification path afterward.
1 | func (tx *Tx) init(db *DB) { |
In a read-write transaction, when the user calls bucket.Put to add or modify data, there are two stages:
- Lookup and positioning: use cursor to locate the page of the specified key
- Load and insert: load all nodes along the path and insert the kv into the leaf node
1 | func (b *Bucket) Put(key []byte, value []byte) error { |
Lookup and positioning. The implementation logic is in the cursor’s cursor.seek discussed in the previous section. Its main logic is: starting from the root node, repeatedly binary search and access the corresponding node/page until locating the leaf node where the kv is to be inserted. There is a key node access function here, bucket.pageNode, which does not load a page as a node, but merely reuses an already cached node, or directly accesses the relevant page mmap’d into memory.
Load and insert. In this stage, first all node indices saved in the cursor stack are loaded as node via cursor.node(), and cached to avoid repeated loading for reuse; then node.put uses binary search to insert the key-value data into the leaf node.
In a read-only transaction, only the lookup and positioning process occurs, so only page access via mmap happens, without the page-to-node conversion process.
For bucket.Delete operations, the two stages are similar, except load and insert becomes load and delete. It can be seen that all modifications at this stage happen in memory; the B±tree structure composed of previous pages saved in the file system is not damaged, so read transactions can proceed concurrently.
Before Transaction Commit
After a write transaction starts, the user may perform a series of insertions/deletions; a large number of related nodes are converted to nodes and loaded into memory. The modified B±tree is jointly composed of pages in the file system and nodes in memory. Due to data changes, some nodes may have too few elements while others have too many.
Therefore, before the transaction commits, the B±tree is first adjusted according to certain strategies to maintain good query properties; then all modified nodes are serialized into pages and incrementally written to the file system, forming a new, persistent, balanced B±tree.
This stage involves two core logics: bucket.rebalance and bucket.spill, corresponding to node merge and split respectively. They are the key functions for maintaining boltdb’s B±tree lookup properties; let’s go through them separately.
rebalance. This function aims to merge nodes that are too small (too few keys or overall size too small) into neighboring nodes. The main adjustment logic is in node.rebalance; bucket.rebalance is mainly a wrapper:
1 | func (b *Bucket) rebalance() { |
The main logic of node.rebalance is as follows:
- Check the
n.unbalancedflag to avoid repeated adjustment of a node. There are two reasons for using the flag: one is on-demand adjustment, and the other is to avoid repeated adjustment. - Determine whether the node needs to merge. The criterion is:
n.size() > pageSize / 4 && len(n.inodes) > n.minKeys(); if not needed, finish. - If the node is the root node and has only one child node, merge it with its only child.
- If the node has no child nodes, delete the node.
- Otherwise, merge the node into its left neighbor. If the node is the first node and has no left neighbor, merge the right neighbor into it.
- Because this adjustment may lead to node deletion, recurse upward to see if further adjustment is needed.
It needs to be clear that only calls to node.del() will cause n.unbalanced to be marked. There are only two places that call node.del():
- The user calls
bucket.Deleteto delete data. - When a child node calls
node.rebalancefor adjustment, the merged node is deleted.
And 2 is caused by 1, so it can be said that only when a user deletes data in a write transaction will the main logic of node.rebalance actually be triggered.
spill. This function has two purposes: splitting nodes that are too large (size larger than one page) and writing nodes to dirty pages. Like rebalance, the main logic is in node.spill. The difference is that bucket.spill also contains considerable logic, mainly dealing with inline bucket issues. As mentioned earlier, if a bucket has too little content, it is directly inlined into the parent bucket’s leaf node. Otherwise, the child bucket’s spill function is called first, and then the child bucket’s root node pageid is placed in the parent bucket’s leaf node. It can be seen that spill adjustment is a bottom-up process, similar to a post-order tree traversal.
1 | // spill splits pages larger than one node and writes adjusted nodes to dirty pages |
The main logic of node.spill is as follows:
- Check the
n.spilledflag; the default is false, indicating all nodes need adjustment. If already adjusted, skip. - Because adjustment is bottom-up, recursive calls are needed to first adjust child nodes, then adjust this node.
- When adjusting this node, split the node according to page size.
- Allocate new pages of appropriate size for all new nodes, then write the node into the page (not yet written back to the file system at this point).
- If split generates a new root node, recursively call upward to adjust other branches. To avoid repeated adjustment, this node’s
childrenis cleared.
It can be seen that boltdb maintains B±tree lookup properties not like textbook B±trees, by keeping all branch nodes’ branch counts within a fixed range, but directly by whether a node’s elements can fit into one page. This reduces internal page fragmentation and the implementation is relatively simple.
Both functions use marks after put/delete to achieve on-demand adjustment, but the difference is that rebalance first merges itself, then merges child buckets; whereas spill first splits child buckets, then splits itself. In addition, there is a required calling order for adjustments: rebalance must be called first for blind merging, then spill is called to split by page size and write to dirty pages.
To summarize: at db initialization, only one page holds the root node of the root bucket. The B±tree is created when bucket.Create is called. Initially it is inlined in the parent bucket’s leaf node. Read transactions do not cause any change to the B±tree structure; all changes in a write transaction are first written to memory, and when the transaction commits, balancing adjustment is performed, then incrementally written to the file system. As more data is written, the B±tree continuously splits and deepens, and is no longer inlined in the parent bucket.
Summary
BoltDB uses a B±tree-like structure to organize database indexes. All data is stored in leaf nodes; branch nodes are only used for routing lookups. BoltDB supports nesting between buckets, which is implemented as nesting of B±trees, maintaining references between parent and child buckets via page id.
In boltdb’s B±tree, all leaf nodes are not linked together in a chain for the sake of simplicity. To support sequential traversal of data, an additional cursor traversal logic is implemented, which improves traversal efficiency and fast jumping by saving a traversal stack.
BoltDB’s B±tree growth is transaction-cycle-based, and growth only occurs in write transactions. After a write transaction starts, the root node of the root bucket is copied; then nodes involved in the changes are loaded into memory on demand and modified in memory. Before the write transaction ends, after adjusting the B±tree, all nodes involved in the changes are allocated new pages and written back to the file system, completing one growth cycle of the B±tree. Freed tree nodes, after no longer being occupied by read transactions, enter the freelist for later use.
Notes
Node: A node in the B±tree appears as a page in the file system or after mmap, and becomes a node after conversion in memory.
Path: A path in the tree refers to all nodes sequentially passed through from the tree’s root node to the current node.
References
- boltdb repo: https://github.com/boltdb/bolt

