boltdb is one of the few pure-Go, single-node KV libraries on the market. boltdb is based on Howard Chu’s LMDB project, with a clean implementation; excluding unit tests and adapter code, the core code is just a little over four thousand lines. A simple API and minimalist implementation—that is precisely the author’s intent. Due to the author’s limited bandwidth, the original boltdb has been archived and is no longer updated. If you want to improve it and submit new PRs, the etcd-maintained fork, bbolt, is recommended.
For convenience, this series of guide articles is still based on the original, unchanging repo. The project is small but complete: with just over four thousand lines of code, it implements a single-node KV engine based on B+ tree indexing and supporting single-writer, multiple-reader transactions. The code itself is simple and unadorned, with adequate comments. If you are a Go enthusiast or interested in KV stores, boltdb is absolutely a repo not to be missed.
This series is planned as three articles, sequentially focusing on data organization, index design, and transaction implementation—the three main aspects of boltdb source code analysis. Since these three aspects are not fully orthogonal and decoupled, the narrative will inevitably interweave them. If something is unclear, just skip it for now and come back to sort it out once you have the full picture. This article is the third: boltdb transaction implementation.
Introduction
Before analyzing boltdb’s transactions, it is necessary to define the concept of a transaction to clarify the scope of our discussion. A database transaction (abbreviated: transaction) is a logical unit of work in the execution process of a database management system, consisting of a finite database operation sequence[^1]. The Wikipedia definition is a bit convoluted; you only need to grasp a few key points when understanding it:
- Execution: at the computation level
- Logical unit: implies indivisibility
- Finite operation sequence: generally not too large in granularity
Why do we need transactions? Transactions emerged in the 1970s to free database users from cognitive burden: transactions help users organize a set of operations and automatically clean up when something goes wrong. Later, NoSQL and some distributed storage systems sacrificed full transaction support for higher performance. However, history spirals upward—the convenience of transactions led NewSQL and other next-generation distributed databases to bring them back.
Speaking of transactions, the most famous concept is the four ACID properties. In fact, ACID is more like an easy-to-remember slogan than a strict description, because the properties are not very symmetric conceptually and depend on contextual interpretation. This article will still analyze boltdb’s transaction support from these four aspects, but at the beginning of each section, I will first draw on Martin Kleppmann’s talk[^2] to try to explain their meaning from different angles; then I will analyze how boltdb implements them.
Author: 木鸟杂记 https://www.qtmuniao.com/2021/04/02/bolt-transaction/ , please indicate the source when reposting
 transaction.png
transaction.png
boltdb only supports single-writer, multiple-reader transactions—that is, there can be at most one read-write transaction at any given time, while multiple read-only transactions are allowed. This is a weakened transaction model; the upside is that it is easy to implement, and the downside is that write concurrency performance is sacrificed. Consequently, boltdb is suitable for read-heavy, write-light applications.
boltdb’s main transaction implementation code is in tx.go, but this source file is roughly just an entry point for transaction implementation. Some behaviors during transaction commit are mainly implemented in the database indexing logic, which can be found in the previous article.
Durability
In the early days, databases achieved durability by flushing data to tape; after a power failure and restart, data would not be lost. Later, tape became disk, and later in the distributed systems era, with massive disk deployments where individual disks were unreliable, multi-replica and other redundancy strategies emerged. Although the strategies have been evolving, their purpose is roughly the same: once a transaction is committed, the corresponding changes will persist long-term despite various common failures.
boltdb is a single-node database engine, so it does not need to consider disk failures for now; data flushed to disk can be considered to have completed persistence. The implementation code is in the function func (tx *Tx) Commit() error. It should be noted that in boltdb only read-write transactions need to commit; committing a read-only transaction will return an error, but read-only transactions need to call tx.Rollback at the end to release resources (such as locks). This setting is a bit counter-intuitive—after all, for a read-only transaction, it is clearly a close operation, yet it is called Rollback.
When a read-write transaction commits, to ensure durability, boltdb mainly does two things:
- Flush modified data to disk
- Flush metadata to disk
Flushing Modified Data to Disk
In a read-write transaction, all direct user modifications (inserts, deletes, updates) happen in leaf nodes, but to maintain the properties of the B+ tree, adjustments are made before Commit, causing cascading changes in intermediate nodes. All these nodes are converted to pages (Page) via node.write(p) during the spill phase. All changed pages (including reused ones from the freelist and newly allocated ones) are called dirty pages. After spill turns them into pages, boltdb flushes these dirty pages to disk via func (tx *Tx) write() error. The general logic is:
- Sort dirty pages by page id and iterate over them one by one
- Convert page id to offset
- Flush the dirty page at the offset via
db.ops.writeAt - Reuse dirty pages with page size = 1 through the page pool, for later allocation reuse
It is worth noting that there is a configurable option db.NoSync in this process. If db.NoSync = true, disk flush does not happen immediately on each Commit; data is only written to the OS buffer, and the OS decides when to actually persist it to disk. This performs better, but an unexpected crash will cause buffer data loss, so strict durability cannot be guaranteed.
Flushing Metadata to Disk
Metadata includes flushing the freelist and the db’s metadata page; the flush process will not be repeated here. It is important to note that metadata page flush must happen last, to guarantee the atomicity of all changes in the transaction taking effect. This point will also be emphasized later.
Consistency
The consistency here should be distinguished from consistency in distributed systems. In distributed systems, consistency mainly refers to data consistency among multiple replicas. The C here feels more like a filler to make the ACID acronym catchy. Its official statement is: before a transaction begins and after it ends, the database is able to maintain certain invariants. This means written data must fully comply with all preset constraints, triggers, cascading rollbacks, etc.[^3]. For example, when A transfers money to B, the total balance of A and B’s accounts should remain unchanged before and after the transfer.
This property focuses on the application level, not the database itself. boltdb is a simple KV engine and does not support user-defined constraints, so it will not be expanded here.
Atomicity
Atomicity, literally understood, packages a set of operations contained in a transaction into a logical unit. But this angle is easily confused with atomicity in concurrent programming. In transactions, atomicity actually focuses more on rollback-ability (or abortability) when something goes wrong—that is, operations in a transaction cannot be partially executed; either all succeed or none are executed.
So how does boltdb implement atomicity? It can be analyzed from active and passive aspects.
Active aspect. When users encounter problems, they can actively call tx.Rollback to roll back, undoing all operations in the transaction so far. Its main logic includes rolling back the used freelist and releasing some resources (such as locks and node memory references). Read-only transactions must call the rollback function when ending, to close the transaction and prevent blocking read-write transactions. The reason was analyzed in previous articles (mainly competing for the lock during remap).
1 | // Rollback 关闭事务,并且放弃之前的更新. 只读事务结束时必须调用 Rollback。 |
Passive aspect. If a boltdb instance crashes unexpectedly while a read-write transaction is in progress, how does boltdb guarantee transaction atomicity after restarting? This is not reflected in specific code details, but in boltdb’s overall design:
- During read-write transaction execution, all changes are incremental and do not affect other read-only transactions
- When finally committing, only when the metadata page is successfully flushed to disk will all incremental changes become visible to users
In other words, the metadata page is used as a “global pointer”, and the write atomicity of this pointer is used to guarantee transaction atomicity. If the machine crashes before the metadata page write is complete, all changes will not take effect, achieving the effect of an automatic rollback.
Isolation
Isolation is an important topic in database systems. Speaking of isolation, four isolation levels are generally mentioned:
- Read uncommitted
- Read committed
- Repeatable read
- Serializable
From top to bottom, the isolation of the four levels gets progressively stronger, and performance gets progressively worse. When I first learned these isolation levels, I read about them several times without remembering them. Later I learned that they do not describe what (conceptual characteristics), but how (implementation details), and are implementations from specific databases in the last century. It is just that these terms have persisted, so if you have also been troubled by these terms, do not doubt yourself—the concepts themselves are problematic: their English names were not well chosen, and the Chinese translations are even worse.
I will not go into detail here, only roughly describing their intuitive understanding. I will write a separate article when I have time; there is quite a lot involved.
Isolation is caused by concurrency. The best isolation—serialization—has the worst performance. The key to understanding isolation is to notice that each transaction has a start and end time; it is not completed instantly. We can view each transaction’s execution process as a line segment on the time dimension; multiple line segments interleaving concurrently will lead to various isolation issues. And the worse the isolation, the harder it is for users to write code, because they need to handle various inconsistencies themselves. For example, a record you read at the beginning, when used later, needs to be checked again to see whether the read value is still consistent with the current database state.
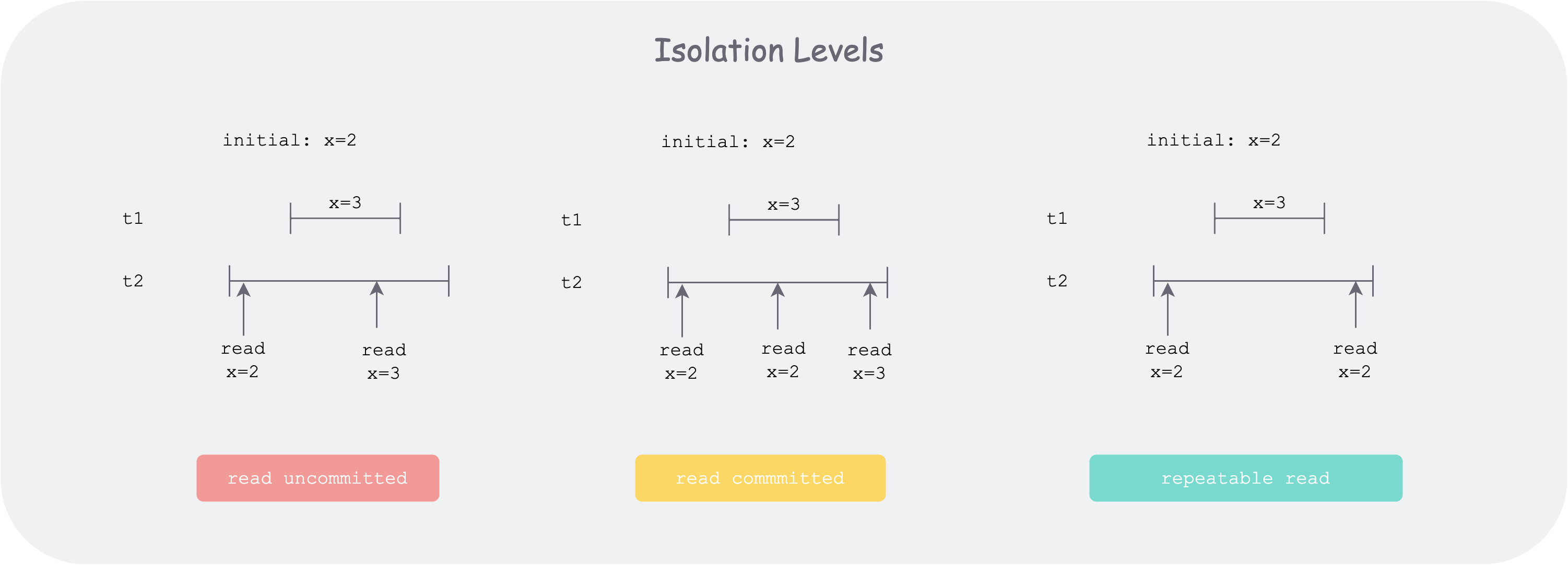 isolation-levels.png
isolation-levels.png
Below is a brief introduction to the four isolation levels in order:
-
Read uncommitted: corresponds to dirty read—within this transaction’s line segment, it will read the intermediate states of other line segments.
-
Read committed: corresponds to non-repeatable read, slightly better than the previous one. At this level, uncommitted states of other transactions cannot be read. But as shown in the figure, if transaction t2 executes multiple reads of a certain record x’s state, before transaction t1 starts it finds x = 2, and after transaction t1 commits it finds x = 3, which results in inconsistency.
-
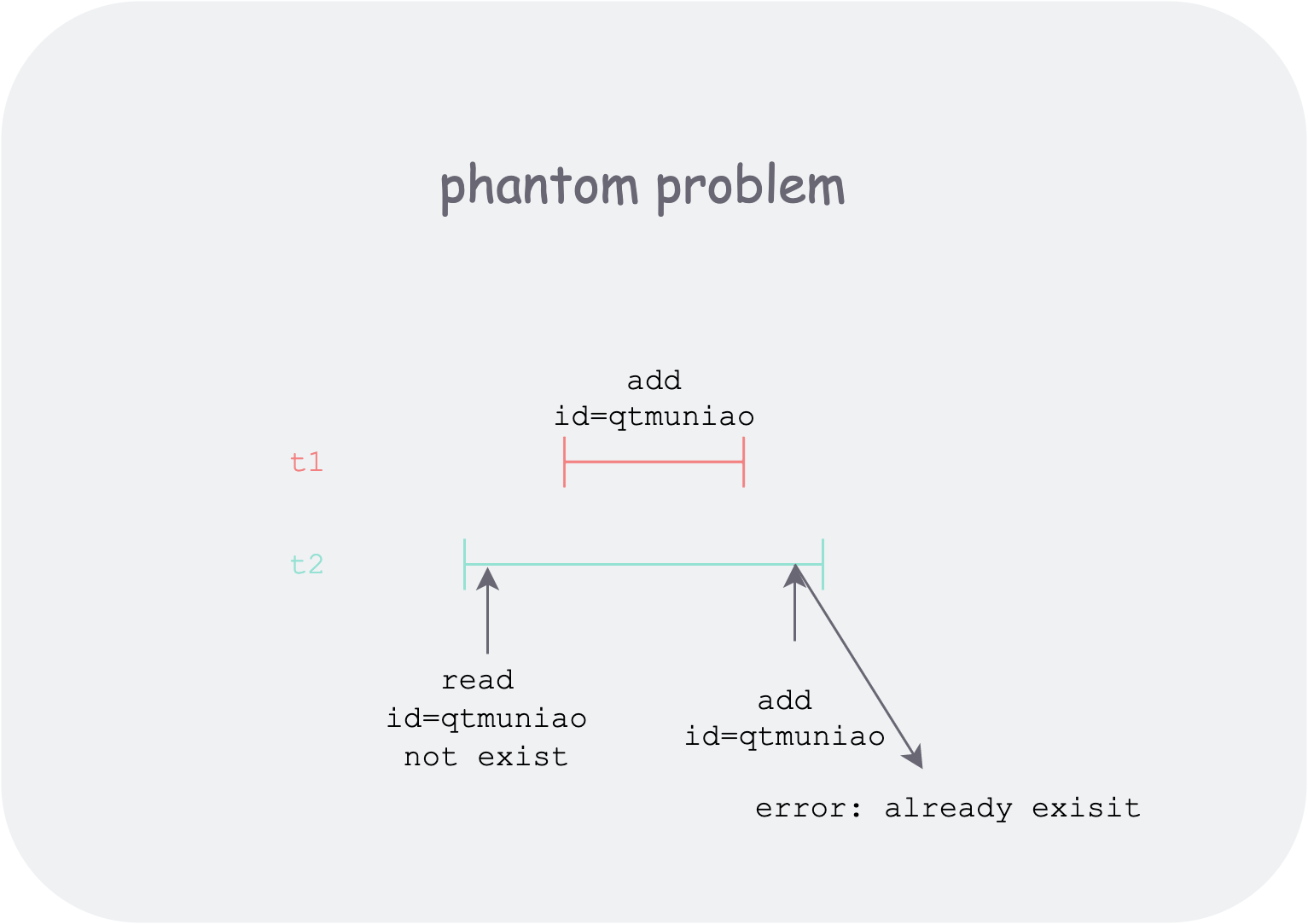
Repeatable read: as shown in the figure, during the entire execution of transaction t2, no matter whether other transactions (such as t1) change x’s state and commit, transaction t2 will not perceive it when reading the database x’s state multiple times. But there is a risk of phantom read. How to understand it? The most critical reason is write concurrency. Because not being able to read does not mean other transactions’ effects do not exist. For example, at the beginning of transaction t2, by querying it finds the record with
id = "qtmuniao"is empty, so it creates a record withid="qtmuniao", but at commit time it finds an error saying this id already exists. This might be because another transaction that started later also created a record withid="qtmuniao", but committed first. So the user is depressed—you clearly said it does not exist, but writing reports an error; did I hallucinate? This is too absurd, but this level can only do this much. On the contrary, because it balances performance and isolation, it is the default level of most databases.![phantom-problem.png]() phantom-problem.png
phantom-problem.png -
Serializable: the simplest implementation is to use a single lock to serialize all transactions. On this basis, if concurrency can be improved, many optimizations need to be done.
For boltdb, because concurrent writes are not allowed, repeatable read and serialization mean the same thing here. In summary, boltdb’s method of implementing isolation is:
- Incremental writes to memory.
- Direct reads from disk via mmap.
Read-write transaction changes are all in memory, while read-only transactions directly read content on disk via mmap, so read-write transaction changes will not be visible to read-only transactions. Multiple read-write transactions are serialized and will not affect each other. And the state seen by each read-only transaction during its lifetime is the state at the time the read-only transaction began execution.
References
[^1]: Wikipedia - Database transaction: https://zh.wikipedia.org/wiki/数据库事务
[^2]: “Transactions: myths, surprises and opportunities” by Martin Kleppmann: https://www.youtube.com/watch?v=5ZjhNTM8XU8
[^3]: Wikipedia - ACID: https://zh.wikipedia.org/wiki/ACID

