boltdb 是市面上为数不多的纯 go 语言开发的、单机 KV 库。boltdb 基于 Howard Chu’s LMDB 项目 ,实现的比较清爽,去掉单元测试和适配代码,核心代码大概四千多行。简单的 API、简约的实现,也是作者的意图所在。由于作者精力所限,原 boltdb 已经封版,不再更新。若想改进,提交新的 pr,建议去 etcd 维护的 fork 版本 bbolt。
为了方便,本系列导读文章仍以不再变动的原 repo 为基础。该项目麻雀虽小,五脏俱全,仅仅四千多行代码,就实现了一个基于 B+ 树索引、支持一写多读事务的单机 KV 引擎。代码本身简约朴实、注释得当,如果你是 go 语言爱好者、如果对 KV 库感兴趣,那 boltdb 绝对是不可错过的一个 repo。
本系列计划分成三篇文章,依次围绕数据组织、索引设计、事务实现等三个主要方面对 boltdb 源码进行剖析。由于三个方面不是完全正交解耦的,因此叙述时会不可避免的产生交织,读不懂时,暂时略过即可,待有全貌,再回来梳理。本文是第三篇, boltdb 事务实现。
引子
在分析 boltd 的事务之前,我们有必要对事务概念做一个界定,以此来明确我们的讨论范围。数据库事务(简称:事务)是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成^1。wiki 上的定义有点拗口,理解时只需抓住几个关键点即可:
- 执行:计算层面
- 逻辑单位:意味着不可分割
- 操作序列有限:一般粒度不会太大
那为什么要有事务呢?事务出现于上世纪七十年代,是为了解放数据库用户的心智而出现的:事务帮助用户组织一组操作、并在出错时自动进行扫尾。后来,NoSQL 和一些分布式存储为了高性能而舍弃了完整事务的支持。然而,历史是螺旋上升的,事务的便利性让 NewSQL 等新一代分布式数据库又将其重新请回。
提起事务,最脍炙人口的便是 ACID 四大特性。 其实 ACID 更像一种易于记忆的口号而非严格的描述,因为他们在概念上并不怎么对称,而且依赖于一些上下文阐释。本文仍然会按照这四个方面对 boltdb 对事务的支持进行剖析,但在每个小结开始,会先参考 Martin Kleppmann 的演讲[^2],试着从不同角度先阐释其内涵;然后在再分析 boltdb 对其实现。
作者:木鸟杂记 https://www.qtmuniao.com/2021/04/02/bolt-transaction/ , 转载请注明出处
 transaction.png
transaction.png
boltdb 只支持一写多读的事务,即同时至多有一个读写事务,而可以有多个只读事务,算是一种弱化的事务模型,好处在于容易实现,坏处在于牺牲了写并发的性能。也因此,boltdb 适合读多写少的应用。
boltdb 事务实现的主要代码在 tx.go 中,但这个源文件大抵算一个事务实现入口,事务提交时的一些行为,主要在数据库索引逻辑中实现,可以参考之前文章。
持久性(Durability)
在早期,数据库将数据刷到磁带上,即获得持久性,断电重启后数据不会丢失。后来磁带变成磁盘,再后来到分布式系统时代,海量磁盘场景下单盘不可靠,便又衍生出多副本等冗余策略。虽然策略一直在演变,但其目大抵相同:事务一旦提交,对应更改便会无视各种常见故障,而进行长久保持。
boltdb 是一个单机数据库引擎,因此暂不必考虑磁盘故障,数据刷到磁盘上即可认为完成了持久化。其实现代码在函数 func (tx *Tx) Commit() error 中。需要说明的是,boltdb 中只有读写事务才须提交,只读事务提交会报错,但只读事务需要在结束时调用 tx.Rollback 以释放资源(比如锁)。这个设定有点反直觉,毕竟对于只读事务来说,明明是关闭,却叫 Rollback。
读写事务提交时,为了保证事务的持久性,boltdb 主要做了两方面的工作:
- 改动数据刷盘
- 元信息刷盘
改动数据刷盘
在一个读写事务中,所有用户的直接改动(增加、删除、改动)都发生在叶子节点,但为了维持 B+ 树的性质,会在 Commit 前进行调整,会引起中间节点的级联变动。所有这些节点(Node)在 spill 阶段通过 node.write(p) 转化为页(Page),所有变动的页(包括复用 freelist 中的和新申请的)称为脏页(dirty pages)。在 spill 为 page 后,boltdb 会通过 func (tx *Tx) write() error 将这些脏页进行刷盘,大体逻辑为:
- 将脏页按 page id 排序后逐个遍历
- 将 page id 转化为 offset
- 通过
db.ops.writeAt将脏页在 offset 处刷盘 - 通过 page pool 复用 page size = 1 的脏页,以备 allocate 时复用
需要注意的是,这个过程中有个可配置项 db.NoSync。如果 db.Nosync = true ,每次 Commit 时不会立即刷盘,只是写到操作系统的缓冲区,由操作系统决定真正落盘时机,性能较好。但是意外宕机会导致缓冲区数据丢失,从而不能保证严格持久性。
元信息刷盘
元信息包括 freelist 表和整个 db 的元信息页刷盘,刷盘过程不再赘述。需要注意的是元信息页刷盘一定在最后,以保证事务所有改动生效的原子性,这个点在后面也会强调。
一致性(Consistency)
此处的一致性要和分布式系统中的一致性区分开来。在分布式系统中,一致性主要指多副本间的数据一致性。而此处的 C,更像是为了让 ACID 念着顺口来凑数的,他的官方表述是:在事务开始之前和事务结束以后,数据库能够保持某些不变性(invariants)。这表示写入的数据必须完全符合所有的预设约束、触发器、级联回滚等[^3]。举个例子来说,A 给 B 转账,转账前后,A 和 B 的账户总额应该保持不变。
该性质描述侧重于应用层面,而非数据库本身。boltdb 是一个简单的 KV 引擎,不支持用户自定义约束,这里不再展开。
原子性(Atomicity)
原子性,从字面意义上来理解是将事务所包含的一组操作打包为一个逻辑单元。但这个角度很容易和并发编程中的原子性相混淆。在事务中,原子性其实更侧重于出现问题时的可回滚性(rollback),或者说可丢弃性(abortability),即事务中的操作不能部分执行,要么都成功执行,要么都未执行。
那么 boltdb 是如何实现原子性的呢?可以从主动和被动两个方面来分析。
主动方面。用户遇到一些问题,可以主动调用 tx.Rollback 进行回滚,undo 该事务到目前为止的所有操作。其主要逻辑包括回滚使用的 freelist,释放一些资源(如锁和节点内存引用)。只读事务结束时必须要调用回滚函数,以关闭事务,防止对读写事务的阻塞,之前文章分析过原因(主要是争抢 remap 时候的锁)。
1 | // Rollback 关闭事务,并且放弃之前的更新. 只读事务结束时必须调用 Rollback。 |
被动方面。在读写事务进行到一半时,如果 boltdb 实例意外挂掉重启后,boltdb 如何保证事务的原子性?这个不体现在某些具体细节的代码中,而是体现在 boltdb 整体的设计里:
- 读写事务执行过程中,所有的改动都是增量改动,不影响其他只读事务
- 最后提交时,元信息页落盘成功,才会使得所有增量改动对用户可见
也就是说,使用元信息页作为“全局指针”,以该指针的写入原子性来保证事务的原子性。如果宕机时,元信息页没有写入完成,所有改动便不会生效,达到了自动回滚的效果。
隔离性(Isolation)
隔离性在数据库系统中是一块重要内容。说起隔离性,一般会提到四个隔离级别:
- 读未提交(Read uncommitted)
- 读已提交(Read committed)
- 可重复读(Repeatable read)
- 序列化(Serializable )
从上到下,四个级别的隔离性依次变强,性能依次变差。我在初学这几个隔离级别时,看过好几次都没有记住。后来才了解到描述的不是是什么(概念特征),而是怎么做(实现细节),而且是上个世纪特定数据库的实现。只不过这些名词后来延续了下来,所以如果你也曾为这些名词而苦恼,不要自我怀疑,是这些概念本身有问题——他们英文名字就没起好,中文翻译就更差了。
这里不会详细展开,只是粗略说下他们直觉上的理解,改天有时间单开一篇文章来说说,其中牵扯的东西还挺多。
隔离性是由并发引起的,最好的隔离——序列化,性能最差。理解隔离性的关键,是要注意到,每个事务有起止时间,不是瞬间完成。我们可以把每个事务执行过程看作是时间维度上的一个线段,多个线段并发交错,就会引出各种隔离性问题。而隔离性越差,用户代码编写就越难受,需要自行处理各种不一致的情况。比如你开始读到的一个记录,在后面使用时,还得再次进行检查读出的值是否和数据库当前状态仍然一致。
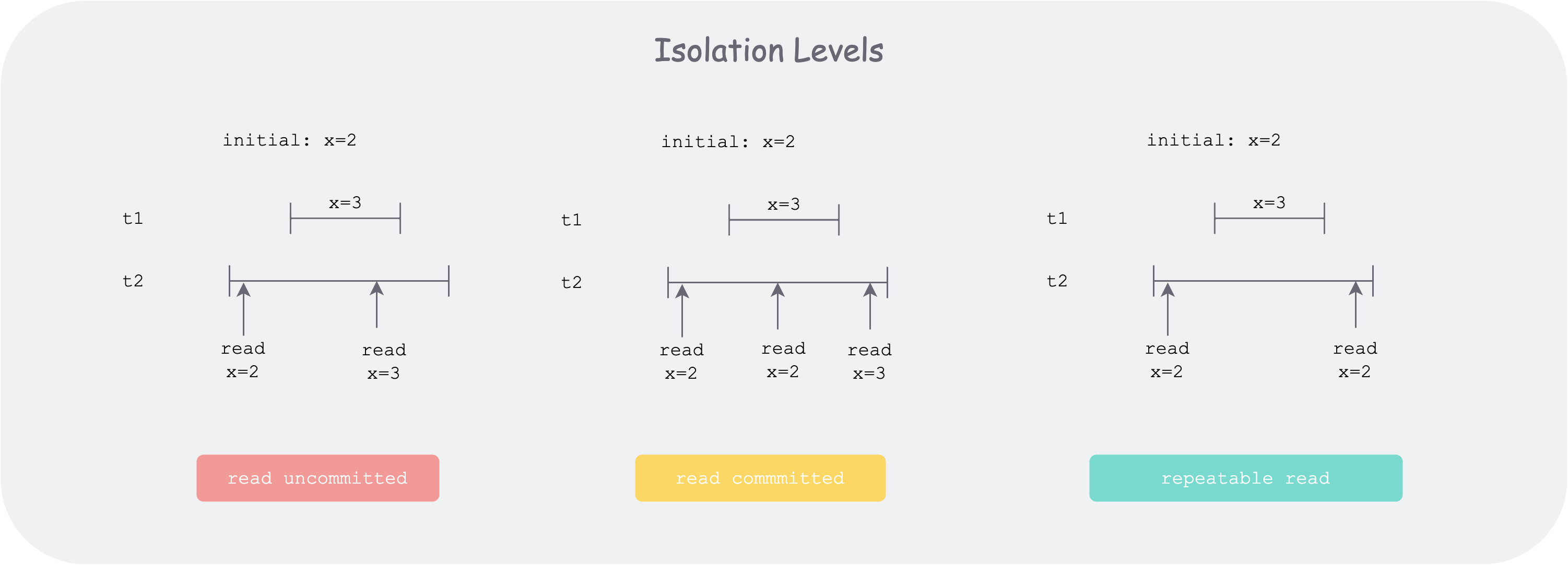 isolation-levels.png
isolation-levels.png
下面依次简单介绍下四种隔离级别:
-
读未提交 :对应脏读,在本事务的线段内,会读到其他线段的中间状态。
-
读已提交:对应不可重复读,比上个好一些。该级别下不能读到其他事务的未提交状态。但如上图,如果事务 t2 在执行时,多次读某个记录 x 的状态,在事务 t1 未启动前,发现 x = 2,在事务 t1 提交后,发现 x = 3,这便出现了不一致。
-
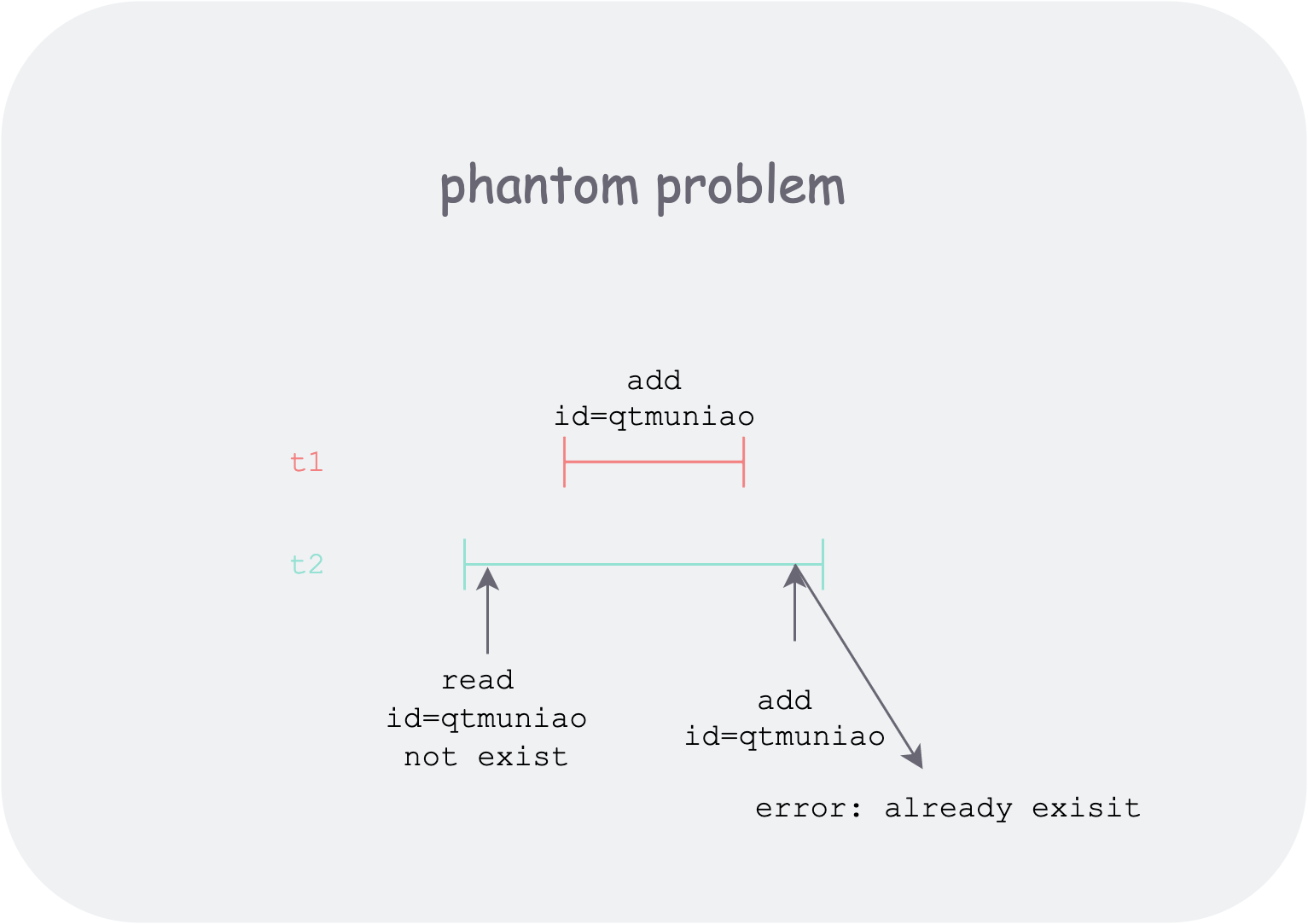
可重复读:如上图,事务 t2 在整个执行期间,多次读取数据库 x 的状态,无论他事务(如 t1)是否改变 x 状态并提交,事务 t2 都不会感觉到。但是会存在幻读的风险。怎么理解呢?最关键的原因在于写并发。因为读不到,不代表其他事务的影响不存在。比如事务 t2 开始时,通过查询发现
id = "qtmuniao"的记录为空,于是创建了id="qtmuniao"的记录,然而在提交时,发现报错说该 id 已经存在。这可能是因为有一个开始的比较晚的事务 t2,也创建了一个id="qtmuniao"的记录,但是先提交了。于是用户就郁闷了,明明你说没有,但我写又报错,难道我出现幻觉了?这就太扯淡了,但是此级别就只能做到这样了。反而,因为兼顾了性能和隔离性,他是大多数据库的默认级别。![phantom-problem.png]() phantom-problem.png
phantom-problem.png -
序列化:最简单的实现办法就是一把锁来串行化所有的事务。在此基础上如果能提高并发,就需要做很多优化。
对于 boltdb 来说,因为不允许并发写,可重复读和序列化在此含义就是一样的。总结来说,boltdb 实现隔离性的方法是:
- 增量写内存。
- 穿透读磁盘。
读写事务的变动都在内存中,而只读事务通过 mmap 直接读取的磁盘上的内容,因此读写事务的改动不会为只读事务所见。多个读写事务是串行的,也不会互相影响。而每个只读事务期间所看到的状态,就是该只读事务开始执行时的状态。
引用
[^2]: “Transactions: myths, surprises and opportunities” by Martin Kleppmann:https://www.youtube.com/watch?v=5ZjhNTM8XU8
[^3]: 维基百科ACID:https://zh.wikipedia.org/wiki/ACID

