Introduction
The essence of hashing is mapping from a larger space to a smaller space. Therefore, after inserting enough data, according to the pigeonhole principle, there will inevitably be position conflicts. Common hash tables (Hash Table or dictionary) handle conflicts through chaining, open addressing, and other methods. Single-bucket multi-function cuckoo hashing is a type of hash table that uses open addressing to handle conflicts; the difference is that when a conflict occurs, instead of linearly searching for a new position, it uses additional hash functions to find one.
Author: 木鸟杂记 https://www.qtmuniao.com/2021/12/07/cuckoo-hash-and-cuckoo-filter, please indicate the source when reposting
Principle
Cuckoo hashing was first presented by Rasmus Pagh and Flemming Friche Rodler at a conference in 2001 [1]. The basic idea is:
- Use two hash functions h1(x), h2(x) and two hash buckets T1, T2.
- Insert element x:
- If T1[h1(x)] or T2[h2(x)] is empty, insert into it; if both are empty, choose either one.
- If both T1[h1(x)] and T2[h2(x)] are full, randomly choose one (let it be y), kick it out, and insert x.
- Repeat the above process to insert element y.
- If there are too many kicks during insertion, it means the hash buckets are full. Then expand and rehash before inserting again.
- Query element x:
- Simply read T1[h1(x)] and T2[h2(x)] and compare with x.
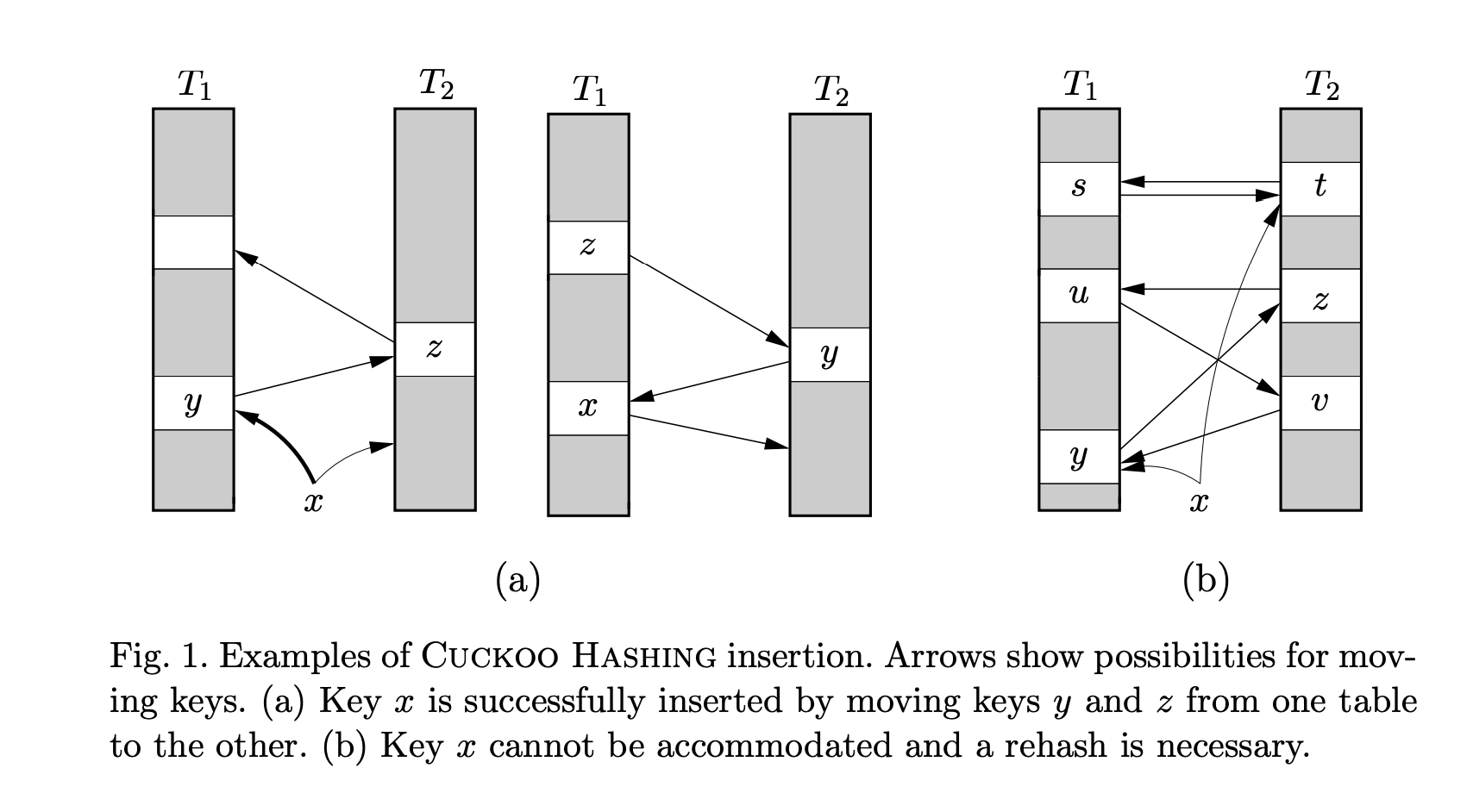 cuckoo-insert.png
cuckoo-insert.png
The cuckoo (Cuckoo), also known as the great spotted cuckoo, likes to lay eggs in other birds’ nests. After hatching, cuckoo chicks will kick out the other eggs and grow up in the borrowed nest. The key design of cuckoo hashing lies in the “kick out” action—both the design and the name are truly inspired.
Variants
Cuckoo hashing can have many variants, such as:
- Using two hash functions and one hash bucket.
- Using two hash functions and four-way hash buckets.
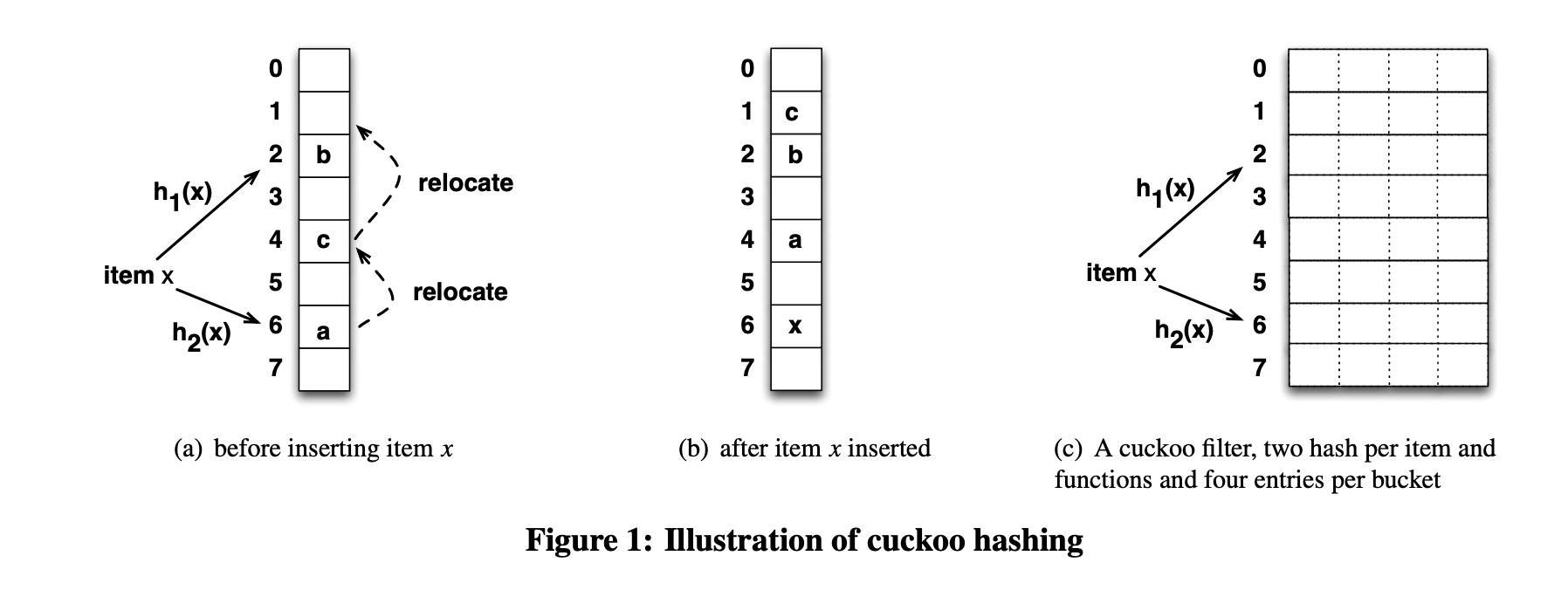 cuckoo-hash.png
cuckoo-hash.png
It can be proven that the latter has higher bucket utilization; interested readers can check the original paper [3] for the proof.
Application
Bin Fan et al. from CMU published a paper in 2014 titled: Cuckoo Filter: Practically Better Than Bloom [3]. The basic idea is to apply the concept of cuckoo hashing (key-value queries) to the set membership direction, which can replace the commonly used Bloom Filter in engineering. It has the following advantages:
- Supports deleting elements
- Higher query efficiency, especially at high load factors
- Easier to implement compared to other filters that support deletion
- If the desired false positive rate is below 3%, it uses less space than Bloom Filter
To achieve the above effects, the Cuckoo Filter made the following changes to the original Cuckoo Hash:
- To improve bucket utilization, it uses multi-way hash buckets.
- To reduce memory usage, it only stores key fingerprints.
In addition, when a value x is kicked out, its other position needs to be found. Cuckoo Hash calculates this through an additional hash function applied to x: h2(x). However, in Cuckoo Filter, to save memory, a fixed-length fingerprint finger(x) is stored instead of the original value x. When x is kicked out, how is its other position found? Intuitively, I have two ideas:
Method 1: Calculate the other position through h2(finger(x)). But when calculating the second position, this is equivalent to forcibly compressing the original data space into the fingerprint space, which loses a lot of information and increases the collision probability.
Method 2: Record the other position in the value, pair(finger, the other position), but this greatly increases space usage.
The Cuckoo Filter uses a clever approach: it obtains the other position by XORing the position (h1(x)) with the hash of the corresponding value (hash(finger(x))). We know that XOR satisfies the property: XORing any two of the three values yields the third. When the value at the other position is kicked out, the original position can also be obtained through the same method, as shown in the figure below.
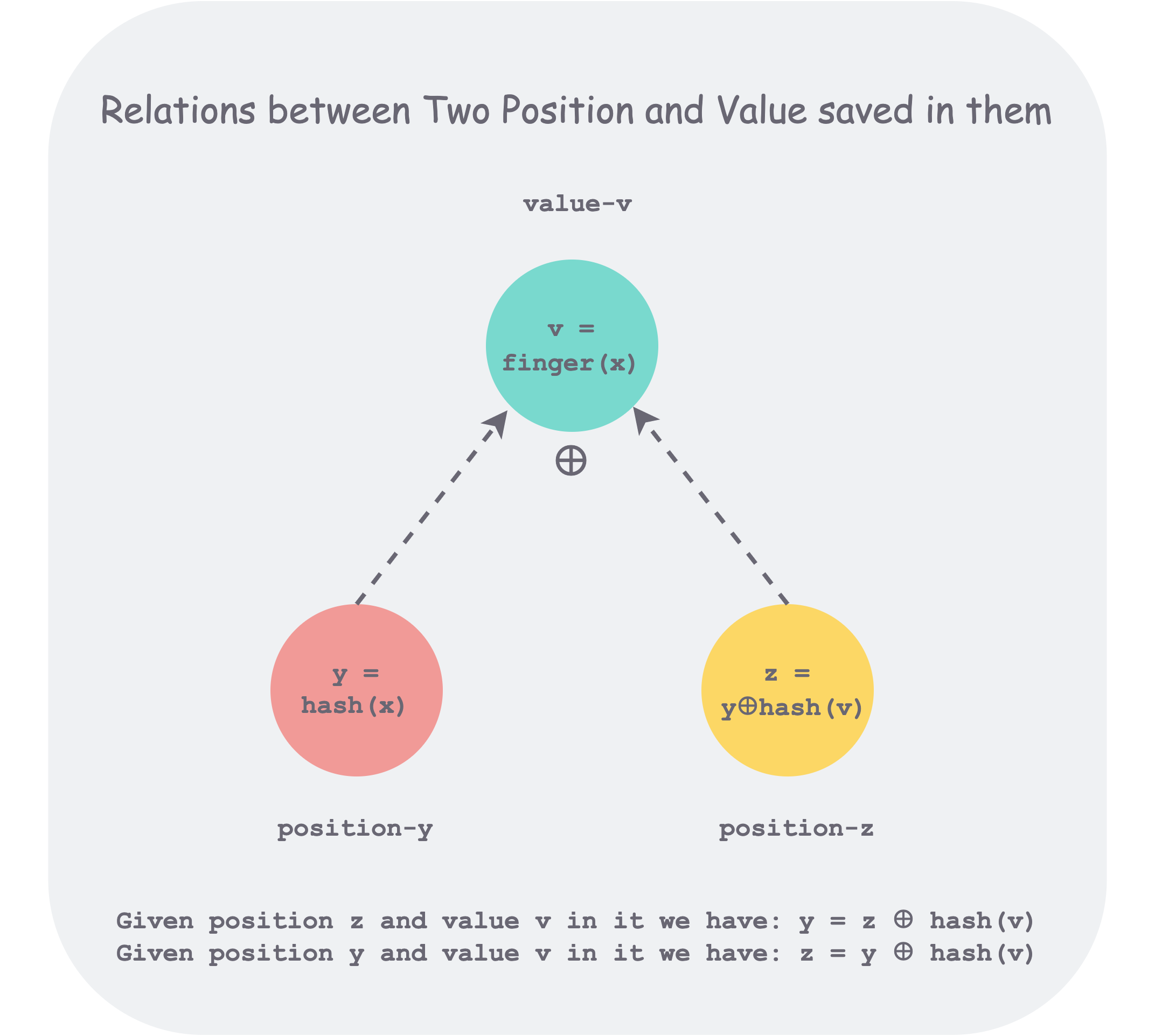 xor-position-val.png
xor-position-val.png
Why not directly XOR with finger(x) to calculate the other position? Because finger(x) generally has few bits, such as 8 bits. With this method, physically speaking, it means finding another position within ±2^8 = 256 of the original position, because XOR only changes the lower 8 bits. This range is too small and is not conducive to even distribution.
There are two additional points to note. First, without additional information, the Cuckoo Filter cannot be expanded, because we have lost the original value x and cannot calculate the new position hash(x) after expansion. Of course, if the corresponding key set is saved, it can also be reinserted after expansion. Second, if two different values x and y happen to satisfy hash(x) == hash(y) && finger(x) == finger(y), a false positive will occur. To understand false positives, we can start from the essence of hashing. As stated at the beginning, hashing is essentially mapping from a large space to a small space, so collisions will inevitably occur in the small space. If one of the two colliding original values exists, it will make people think the other also exists. Returning to the Cuckoo Filter, if both x and y exist in the Cuckoo Filter, when deleting x or y, deleting any one of the two identical fingerprints is sufficient.
Implementation
The implementation of the cuckoo filter is very simple; the paper also provides pseudocode, which is pasted here.
Insert(x)
1 | f = fingerprint(x); |
Lookup(x)
1 | f = fingerprint(x); |
Delete(x)
1 | f = fingerprint(x); |
References
Cuckoo Hash and Cuckoo Filter
- Cuckoo Hashing: https://www.itu.dk/people/pagh/papers/cuckoo-jour.pdf
- Cuckoo Hashing Wikipedia: https://en.wikipedia.org/wiki/Cuckoo_hashing#cite_note-Cuckoo-1
- Cuckoo Filter: Practically Better Than Bloom https://www.cs.cmu.edu/~binfan/papers/conext14_cuckoofilter.pdf
- Cuckoo Filter Implementation: [https://coolshell.cn/articles/17225.html]

