ray.data 是基于 ray core 的一层封装。依赖 ray.data,用户用简单的代码,就可以实现数据大规模的异构处理(主要指同时使用 CPU 和 GPU)。一句话总结:很简单好用,同时也有很多坑。
在 上一篇中,我们从用户接口出发,浅浅地梳理了一下 ray.data 的主要接口。本篇,我们从宏观的角度,大概串一下 ray.data 的基本原理。之后,我们再用几篇,结合代码细节和使用经验,探讨下比较重要的几块内容:执行调度、数据格式和避坑指南。
本文来自我的专栏《系统日知录》,如果你觉得文章还不错,欢迎订阅支持我。
概述
从高层来理解,ray.data 的一次数据处理任务大致可以分成前后相继的三阶段:
- 数据加载:将数据从系统外部读到 ray 的 Object Store 中 (如 read_parquet)
- 数据变换:利用各种算子在 Object Store 中对数据进行变换(如 map/filter/repartition)
- 数据写回:将 Object Store 中的数据写回外部存储(如 write_parquet)
作者:木鸟杂记 https://www.qtmuniao.com/2024/07/07/ray-data-2/ 转载请注明出处
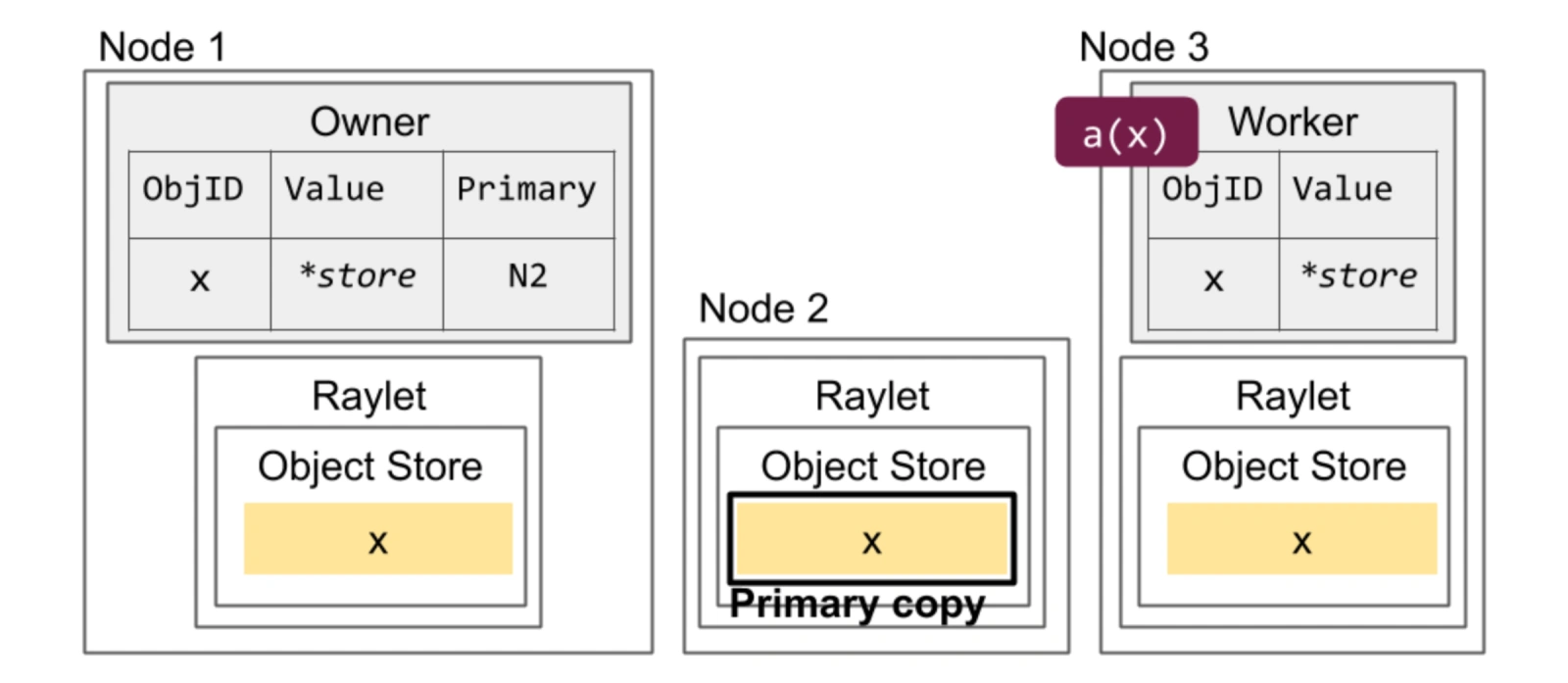 ray-object-store.png
ray-object-store.png
如上图,解释下提到的名词:
- Object Store 是由各个节点受控内存组成,用于存储上一个子任务的中间结果,供其他节点上的下一个子任务拉取使用。
- Raylet 是 ray 在集群中各节点的 daemon,负责本节点上各种 ray 任务的调度和执行。
数据抽象
ray.data 对使用三级粒度来组织一个数据集:数据集(Dataset)、数据块(Block)、数据条目(Row)。每个数据集在逻辑上是一张二维表,读入系统后,会按行切成多块分散到多个机器的 Object Store 中。
其中,数据块是不可变的(Immutable),是 ray.data 对数据进行存储和传输的基本单元,也是最基本的并行粒度。数据块在 Object Store 中以 Apache Arrow 的格式进行存储,其特点是按列存储、编程语言无关、支持零拷贝。
batch 非 block
ray data 中有一个很重要的向量化(batch 是按列组织传给算子的)处理算子 map_batches。可以通过一个例子来大致感受下其使用方法:
1 | from typing import Dict |
该算子涉及到了一个 batch 参数,这个 batch 和 block 是解耦的,其区别和联系是:
- block 是物理上的静态存储实体;而 batch 是将数据送给算子前动态生成的。
- ray.data 会将一个或者多个 block 组合成
batch_size大小,送给用户算子。 - 每个 batch 在经过算子处理后,会变成新的 block 写回 Object Store 。
注意最后一步,一个 batch 的经过处理后的输出不一定是一个 block,因为 ray data 对 block 的大小有控制:[1M, 128M] (可以通过 DataContext.target_min_block_size 和 DataContext.target_max_block_size 修改),过大了会切,但过小了好像不会合。
初始 block 数
说完 block 和 batch 的关系后,我们很容易联想到一个问题:数据集加载到内存后,会分成多少个 block?
首先,我们可以在读取类算子中显式地指定其数量:override_num_blocks
1 | import ray |
其次,如果我们不指定,ray data 就会根据一系列规则进行估算。大致估算步骤是:
- 初始大小:初始 block 数量为 200
- 尺寸约束调整:采样大致估算总大小,以选择合适 block 数量,保证单个 block 大小落在 [1M, 128M] 区间
- 并行度约束调整:考虑可用 cpu 数量,使数据加载时尽量充分利用 cpu —— 保证 block 数量至少是 cpu 核数的两倍
最后一条涉及一个实现细节:ray.data 会为每一个 block 调度一个 read task,也即我们之前提到的 block 是基本的并行单位。
block 写出文件数
如果不加任何控制,将数据集落到系统外时,每个 block 会默认写成一个文件。如果想改变文件数量,比如,避免过多小文件,可以使用 Repartition 算子,对 block 数进行改变:
1 | Dataset.repartition(num_blocks: int, *, shuffle: bool = False) → Dataset[source] |
弱模式
我们前面提到,在逻辑上可以将数据集(Dataset)理解为一张大的二维表,但和关系型数据库中对每列类型进行强约束不同,ray data 对数据集中的列只进行了弱约束。毕竟,这是 Python 呀…
这个设计确实给了用户很大的灵活性,但也带来了非常多的坑,就跟 Python 这门语言一样——实现的怎么样,全靠用户水平。
但吊诡的是,ray.data 的数据集是有 schema 接口的,只不过是读第一行测算出来的。如下面代码中的年龄列,在同时有字符串类型和整形的情况下,ray.data 并不会报错,且将第一行的数据类型作为了该列的类型。
1 | def add_dog_years(batch: Dict[str, np.ndarray]) -> Dict[str, np.ndarray]: |
batch 是按列来组织数据的,即 batch 的类型是 Dict[str, np.ndarray],每一列是使用 numpy 来组织的。但如果 np.ndarray 中每个值是None、嵌套的、不定长的,ray 也不会做任何检查,只能由用户自己来保证。
这在实践中会有非常多的坑,包括:
- numpy 是不支持 Python 中 None 类型的,因此如果处理后生成的新数据中混入了 None 后,在转换为 block 存入 object store 前,会先绕个远——先转换成 Pandas,再转换为 arrow 后写入 Object Store。
- 如果 batch 中一列的输出结果是一个高维的 numpy,那 ray 会将包装成一个自定义的 ArrowTensorArray,假装它是多行的 numpy,但内存还是按高维 numpy 组织的。
这里各种隐式的转换会给新用户带来非常多的麻烦。
本质上在于,ray.data 没有做一套自己的类型系统,而是利用 numpy、pandas、pyarrow 来构造了一套类型系统及其序列化和反序列化方法,但是配合使用时又有诸多龃龉,从而引出很多非预期行为的 bug ,为此,ray.data 在不断迭代和疯狂 patch,经常几周就更新一个小版本。
任务执行
那么 ray.data 是如何对 pipeline 进行大规模的并行执行的呢?可以用两个词来简要概括:
- 微批模式(micro-batch)
- 算子并行(operator-pool)
任务类型
展开来说,ray.data 根据用户的定义,构建出一个由算子组成的 pipeline。对于 pipeline 中的每个算子,会根据用户配置的并行度,启动相应数量的 Task 或者 Actor:
- Task:针对用户传入的无状态函数,调用完即销毁。比如非常简单的增加计数的 map
- Actor:针对用户传入的有状态类,是常驻的。比如 map 中要进行推理,需要预先加载模型。使用 Actor 模式,就可以只在构造函数中加载一次,之后便可以进行多个 batch 的推理,直到整个任务结束。
调度逻辑
将所有算子的执行单元(Task 或者 Actor )启动起来之后,ray.data 的基本调度逻辑是:
- 为每个算子维护一个 input buffer 和一个 output buffer,存放 block 的引用(block 本尊在 object store 中)
- 对于所有算子,当其 input buffer 中有数据时,会调度一个任务(task 或者 actor)对其进行消费后放到 output buffer 中
- 下游算子的 input offer 就是上游的 output buffer
即通过阻塞队列(input/output buffer)将所有算子逻辑上桥接起来,根据用户给算子指定的并行粒度,调度任务驱动数据整体往前流动。
并且在数据快处理完时,会将 pipeline 中前面那些算子用不到的 Actor 释放掉(Task 是无状态的,调用完即释放,而 Actor 是常驻的)。
在新的版本中,Task 和 Actor 还支持配置动态的并行度区间,ray data 可以根据资源和需求进行伸缩式的调度,但是实现的还非常粗糙,实际体验并不理想。
此外,ray.data 还会根据下游 Object Store 的内存使用,对上游算子的执行做一定的背压。但如果你的下游算子使用的内存没落在 Object Store 中,而在进程的堆内,那 ray 就无能为力了。
局限性
ray.data 不适合做大规模的 shuffle。这里说一个 shuffle 的粗略定义:需要在多个节点间进行多对多的数据交换。比如 sort、rand_shuffle 等算子。
和 Spark 不同,ray.data 需要把所有的数据加载到内存中才能进行 shuffle,因此如果数据量比较大,在内存中装不下时,就会发生大量的 spill。但 ray.data 对于 spill 到外存的数据管理的很不好,shuffle 中各种优化(比如预排序、小文件合并)也做的非常不好。因此,大部分的 shuffle 场景,Ray 都不如 Spark 快。
更不用说,Ray 在接口层面就不支持 Join 算子(也是一种非常常见的 shuffle 算子)。
小结
本文从宏观上描述了下 ray.data 对于 block 的组织和变换、对于数据模式的处理以及基本的执行调度逻辑。之后,我们将深入代码细节,讲一下 ray.data 的执行引擎。

