There is a question on Zhihu: how to implement a database? I couldn’t resist writing another piece. Using the most common way of analyzing and understanding problems in computer science, we can think about how to implement a database from two dimensions: logical and physical.
Logical Dimension
Data Model (External, User-Facing)
If you want to implement a database, first you need to define what kind of data model to provide to users. In earlier years, this might not have been an issue—back then, database roughly equaled relational data, which roughly equaled Oracle/SQL Server/MySQL/PostgreSQL. But as data volumes continue to grow and user demands become increasingly refined, the relational model can no longer be a one-size-fits-all solution.
Author: Muniao Notes https://www.qtmuniao.com/2022/12/11/how-to-build-a-database Please indicate the source when reposting
Currently (2022), common models include the Relational model (Oracle), Document model (MongoDB), Search Engine (Elasticsearch), KV model (Redis), Wide Column model (Cassandra), Graph model (Neo4j), and Time Series model (InfluxDB). For more models and their products, see the DB-Engines ranking[1].
Data Organization (Internal, System-Facing)
A database is essentially about storing and retrieving data. From a programmer’s perspective, it is about how to organize data within the computer memory hierarchy[2].
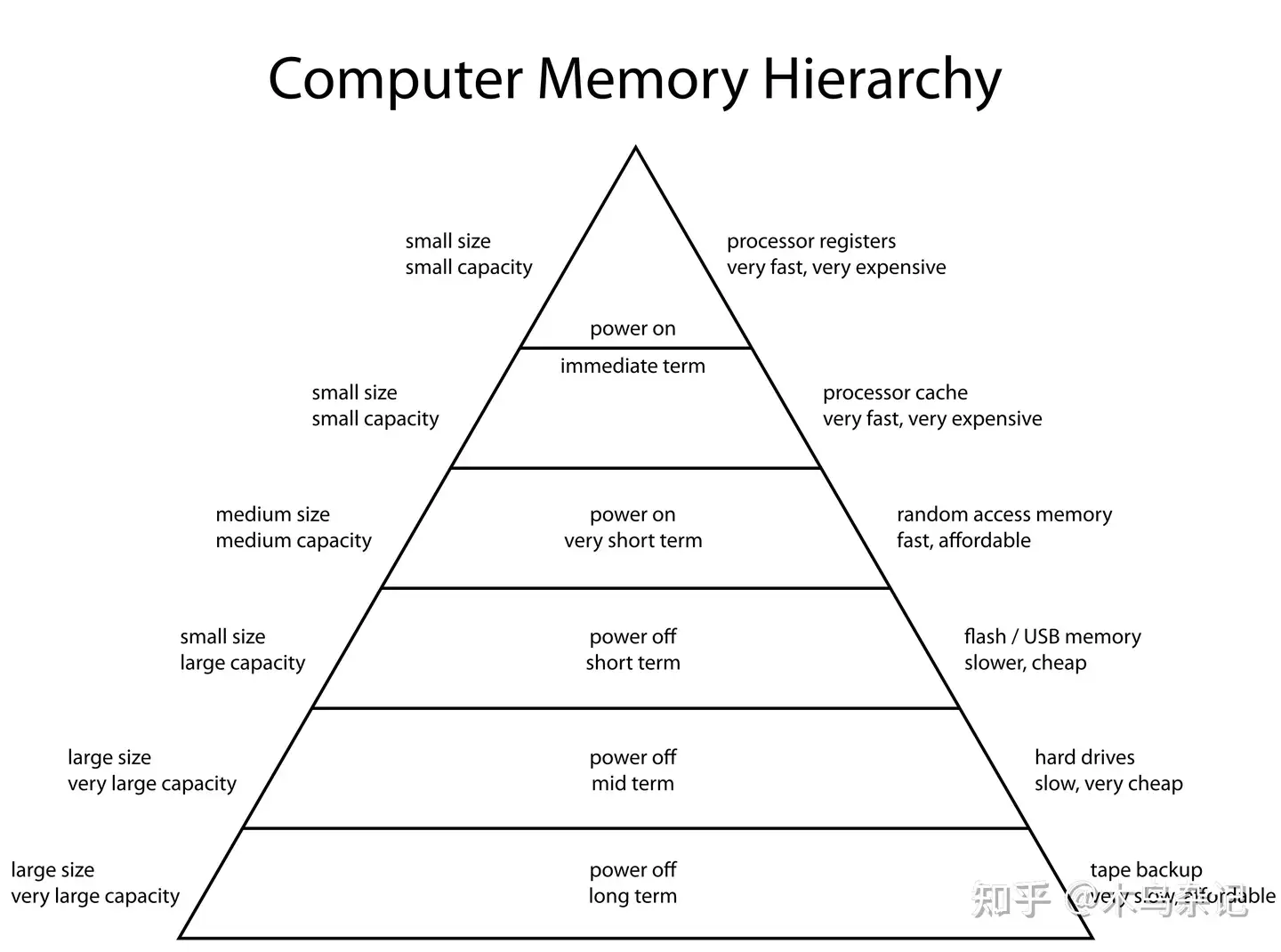 Computer Memory Hierarchy
Computer Memory Hierarchy
Anyone who has studied operating systems and computer architecture knows that for computers:
- The closer to the CPU, such as registers (Register), cache (Cache), and memory (Memory), the faster the speed, the smaller the capacity, and the more expensive the cost.
- The farther from the CPU, such as flash memory (SSD), disk (Disk), and tape (Tape), the slower the speed, the larger the capacity, and the cheaper the cost.
In recent years, some new products have emerged. For example, Persistent Memory[3], represented by Intel’s Optane[4], roughly sits between memory and SSD. However, due to its unclear positioning (not fast enough going upward, not cheap enough going downward), it has not yet been widely adopted. Another example is object storage in the cloud, represented by AWS S3[5], which roughly replaces several types of non-volatile storage. With attractive pricing, sufficient bandwidth, and strong scalability, it has achieved great success and become a cloud storage infrastructure. Any database that needs to move to the cloud will consider using object storage at the bottom layer.
Physical Dimension
Physically, a database can be roughly divided into a query engine and a storage engine. Intuitively, the storage engine is responsible for organizing data on external storage and loading data into memory, while the query engine is responsible for parsing user queries into read/write operations at the data layer and performing computations on data in memory.
Due to space constraints, we omit several other important modules here: concurrency control, crash recovery, etc.
Query Engine
Every data model has a data query method that fits it well. Of course, what we know best is SQL for the relational model. SQL is also a computer language, and as a language, it requires a set of processes similar to what all compiler front-ends need:
-
Parser: Parses the query syntax abstracted using formal languages, utilizing automata models to construct an abstract syntax tree[6]
-
Validator: Validates the syntax tree against the schema
The difference is that since query languages are declarative languages[7], there is considerable freedom in execution. Namely:
- Planner: Uses schema information to transform elements in the syntax tree that are meaningful to users (such as names) into internal identifiers (such as IDs)
- Optimizer: Uses relational algebra to perform logical transformations on the plan tree and leverages statistical information to select execution paths (such as which index to use), aiming to fulfill user query requirements at minimal cost
- Executor: Executes the optimized execution plan at the storage layer, truly accessing the data we store in the computer’s storage architecture
Trees are a data structure that is applied very deeply in data systems. Most data queries can be logically abstracted as continuous transformations of datasets, which map to trees as follows:
- Leaf nodes: Data sets. They have different granularities, such as a column, a row, or a table
- Intermediate nodes: Transformation operators. They have different types, such as selection, project, join, dedup, top, etc.
In a broad sense, big data middleware such as Hadoop, Spark, and Flink also have the shadow of a query engine, except that either the operators are simpler, or they focus on multiple machines, or they focus on streaming, etc.
Storage Engine
Corresponding to data organization, system programmers need to organize data in external storage (SSD and disk) based on the database application scenario. For example:
- Considering transactional or analytical workloads: weighing between column store and row store
- Considering the read/write ratio: weighing between in-place updates (B+ tree) and incremental updates (LSM-Tree)
- Considering security: weighing whether to encrypt or not
Then, consider how to move data from external storage to memory.
- We know that external storage is much larger than memory, so only part of the data can be loaded into memory for user access. Which data to load each time and which data to evict each time is a strategy or algorithm that needs to be designed—Buffer Pool, LRU
- We also know that IO is much slower than CPU, and data access often follows the principle of locality. Therefore, each time we fetch data from external storage, we tend to do so in “bulk.” The amount of each bulk fetch is also a point to consider—Block, Page
[8]
Finally, we also need to consider how to move data from memory to each CPU. Strictly speaking, this already falls within the scope of the query engine, but for logical coherence, we place it here.
- When single-core CPUs hit bottlenecks, we can only move toward multi-core. Then how to feed data in memory to each CPU—Cache Line alignment
- Multiple CPUs need to cooperate. How to orchestrate the execution of multiple CPUs and how to connect the input and output of multiple CPUs—locks, semaphores, queues
And how data is organized in memory is something that both engines are involved in.
- Row store or column store. The latter can be optimized using SIMD.
- Sparse or dense. How much NULL data there is.
- Homogeneous or heterogeneous. Whether dynamic types and nested types need to be supported.
However, the above only considers data organization on a single machine. If a single machine cannot provide the target storage capacity and throughput, a distributed system needs to be considered—connecting multiple machines via a network to serve externally as a whole.
Thus we introduce networks that are quite unreliable (compared to a single machine’s bus) and clocks that are difficult to strictly synchronize. How to handle alignment is another long story. Although contemporary databases all require multi-machine collaboration, due to space constraints, we will stop here. Those interested can check out our DDIA book club sharing: https://ddia.qtmuniao.com/
References
- DB-Engines Database Authority Ranking https://db-engines.com/en/ranking
- Computer Memory Hierarchy https://en.wikipedia.org/wiki/Memory_hierarchy
- Persistent Memory https://en.wikipedia.org/wiki/Persistent_memory
- Intel® Optane™ Persistent Memory https://www.intel.cn/content/www/cn/zh/architecture-and-technology/optane-dc-persistent-memory.html
- Amazon Simple Storage Service (Amazon S3) https://aws.amazon.com/cn/s3/
- Automata-based Programming https://en.wikipedia.org/wiki/Automata-based_programming
- Declarative Programming https://en.wikipedia.org/wiki/Declarative_programming
- Locality of Reference https://en.wikipedia.org/wiki/Locality_of_reference

