Recently, while going through DuckDB’s execution engine related slides (Push-Based-Execution), I came across this paper: Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age. I had seen it referenced several times in articles about execution engines; moreover, NUMA architecture is very important for modern database architecture design, but my understanding of it was still shallow, so I decided to read it.
As can be seen from the title, the paper has two main keywords:
- NUMA-Aware
- Morsel-Driven
Based on this, here is a rough summary of the paper’s central idea:
- In the many-core era, due to the binding relationship between some CPUs and some memory, CPU memory access is non-uniform (NUMA). That is, for a given CPU core, some local memory has lower access latency, while other memory has higher latency.
- The traditional volcano model uses the Exchange operator for parallelism. Other operators are not aware of multithreading, and therefore cannot schedule computation close to memory (hardware affinity). That is, they are not NUMA-local.
- To solve this problem, the paper proposes, on the data dimension: horizontally partitioning the dataset, with one NUMA-node processing one data partition; vertically splitting each partition into segments (Morsel), and performing concurrent scheduling and preemptive execution at the Morsel granularity.
- On the computation dimension: pre-allocating one thread per CPU; during scheduling, each thread only accepts tasks whose data chunks (Morsel) are allocated to its local NUMA-node; when the execution progress of sub-tasks among threads is unbalanced, faster threads will “steal” tasks that were supposed to be scheduled to other threads, thereby ensuring that multiple sub-tasks of a Query finish approximately at the same time, without a “long tail” partition.
Author: Muniao’s Notes https://www.qtmuniao.com/2023/08/21/numa-aware-execution-engine Please indicate the source when reposting
Background
The paper mentions some terms that, if unfamiliar, may make it difficult to fully understand some key design points. Therefore, here is some background on the relevant concepts.
NUMA
NUMA is the abbreviation for Non-Uniform Memory Access, i.e., the non-uniform memory access architecture. The traditional UMA (uniform memory access) architecture is relatively easy to understand, and is also the memory access model we usually assume—all CPU cores accessing all local memory have consistent latency (image source):
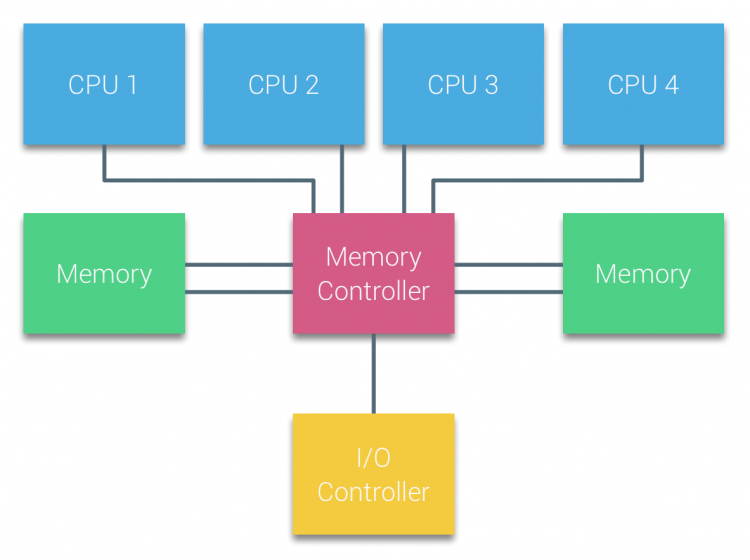 uma-architecture.png
uma-architecture.png
However, in the many-core era (nowadays, common servers easily have 50+ cores), the memory access bus becomes severely “contended,” causing memory latency to increase rapidly. Thus, the NUMA architecture emerged—splitting the local machine’s memory into several chunks, each bound to some CPUs. A bound group of CPUs and memory is usually called a NUMA-node or NUMA socket.
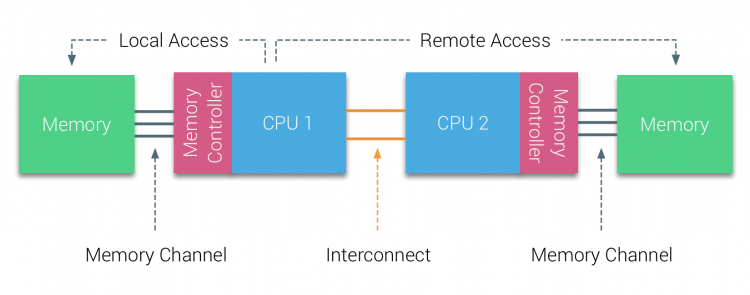 numa-architecture.png
numa-architecture.png
The above figure is only a schematic; usually a NUMA-node has many CPU cores, not just one as shown. Then, access to the local NUMA-node is Local Access, while access to memory on other NUMA-nodes is Remote Access, the latter typically being several times slower than the former.
1 | ~ numactl --hardware |
The above output shows the NUMA configuration of a physical machine via the numactl command. It can be seen that the machine has 56 cores in total, divided into two NUMA-nodes, each with 28 cores and 128GB of memory; the local access to remote access latency ratio is approximately 10:21.
Typically, the operating system tries to allocate threads and the memory they use to the same NUMA-node, especially for threads that only need a small amount of memory. But for systems like databases that use large amounts of memory (buffer pool), memory allocation can easily span NUMA-nodes, and therefore requires specialized design.
In a distributed environment, a machine node is essentially a resource container of a group of CPUs + a block of memory; on a single machine, a NUMA-node is the same. Therefore, viewing this paper with the mindset of distributed scheduling algorithms (scheduling computation close to storage) may make many aspects easier to understand.
Volcano Model
The volcano model is the most traditional and classic database execution engine model. In the volcano model, an SQL statement is transformed into an operator tree, where each operator implements open-next-close interfaces; data processing is completed through top-down (calling next) tree recursion.
A characteristic of operators in the volcano model is that they are not aware of which memory block their processed data is in, nor which CPU they are running on, or even whether they are executing in parallel. Of course, to utilize multi-core performance, the volcano model can be extended with the Exchange operator to implement shuffle operations similar to partition→parallel processing→merge, thereby executing the operator tree concurrently. The Exchange operator can be inserted at any position in the operator tree, changing local concurrency. Apart from this, other operators are unaware of parallel execution details. The advantage of this model is that it is concise, elegant, and expressive. But in the many-core era, this model obviously does not account for NUMA architecture characteristics.
For the above volcano model, we usually refer to its execution mode as pull-based. Because we always ask for data from the root of the operator tree, and the root recursively asks its child nodes for data, down to the leaf nodes (usually various scan nodes). Overall, it is like “pulling” data from the root node outward.
In contrast to pull-based, we also have push-based execution mode. Just as recursion can be transformed into iteration in code, push-based starts execution directly from the leaf nodes; after an operator finishes execution and generates new data, it pushes data to the downstream operator (the parent node in the operator tree).
The biggest difference between the two is that pull-based does not require operator-level scheduling; all data is “demand-driven production,” with downstream step-by-step requesting from upstream; while push-based requires a global scheduler to coordinate the data production and consumption relationship between upstream and downstream—pushing data produced by upstream to downstream when downstream is ready to accept it.
Pipeline
In push-based mode, we usually cut the operator tree into multiple linear pipelines (Pipeline), and perform execution scheduling at the Pipeline granularity (the dashed parts in the figure below). Each pipeline can also be called a pipeline segment, i.e., a part of the entire operator tree.
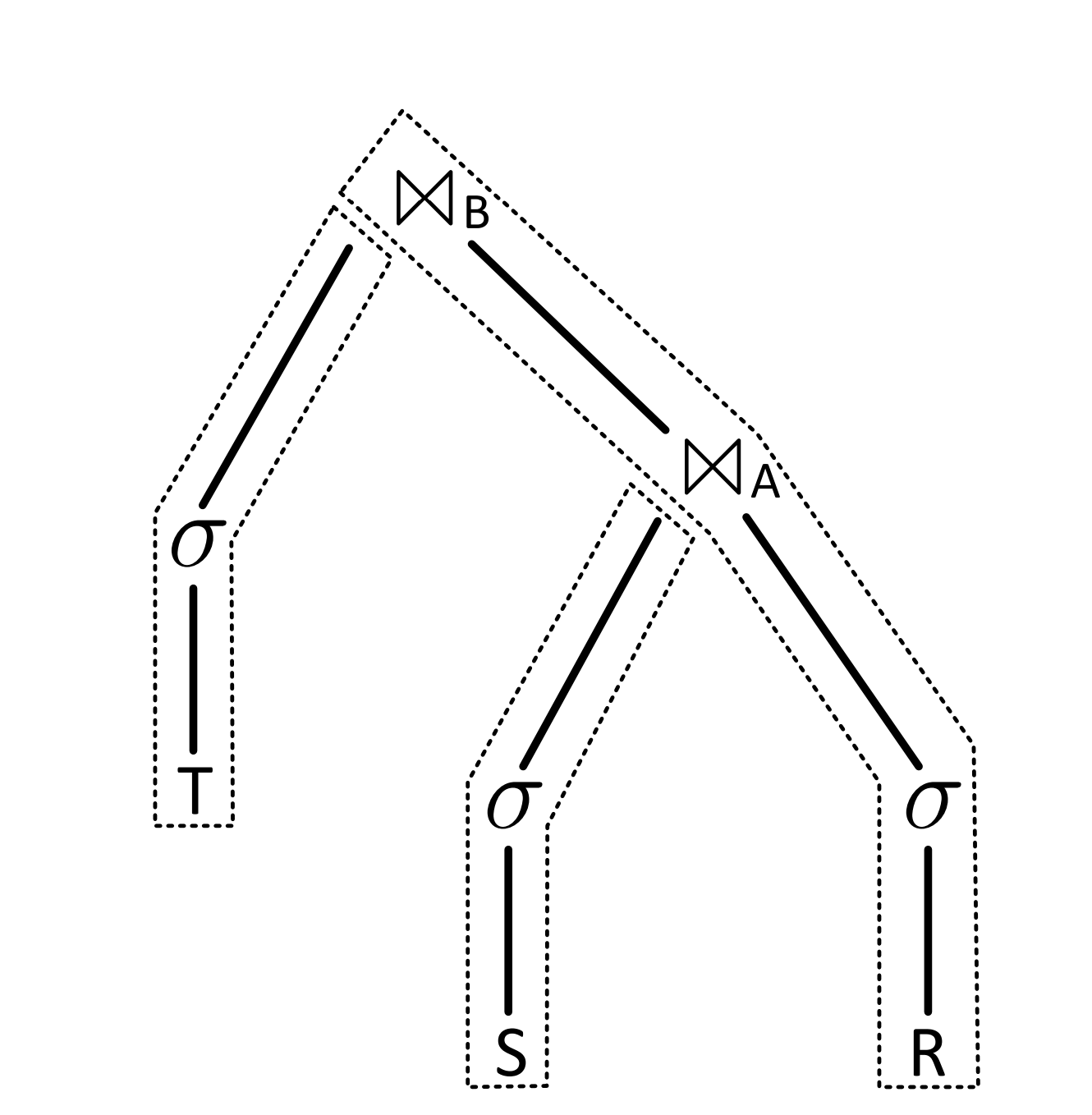 pipeline-split.png
pipeline-split.png
The cut points in a Pipeline are usually called Pipeline Breakers—that is, where the Pipeline cannot continue and must be split. If you happen to know about Spark’s Stage division, you will find that the principle is the same—splitting at Shuffle. And Shuffle usually occurs at Join.
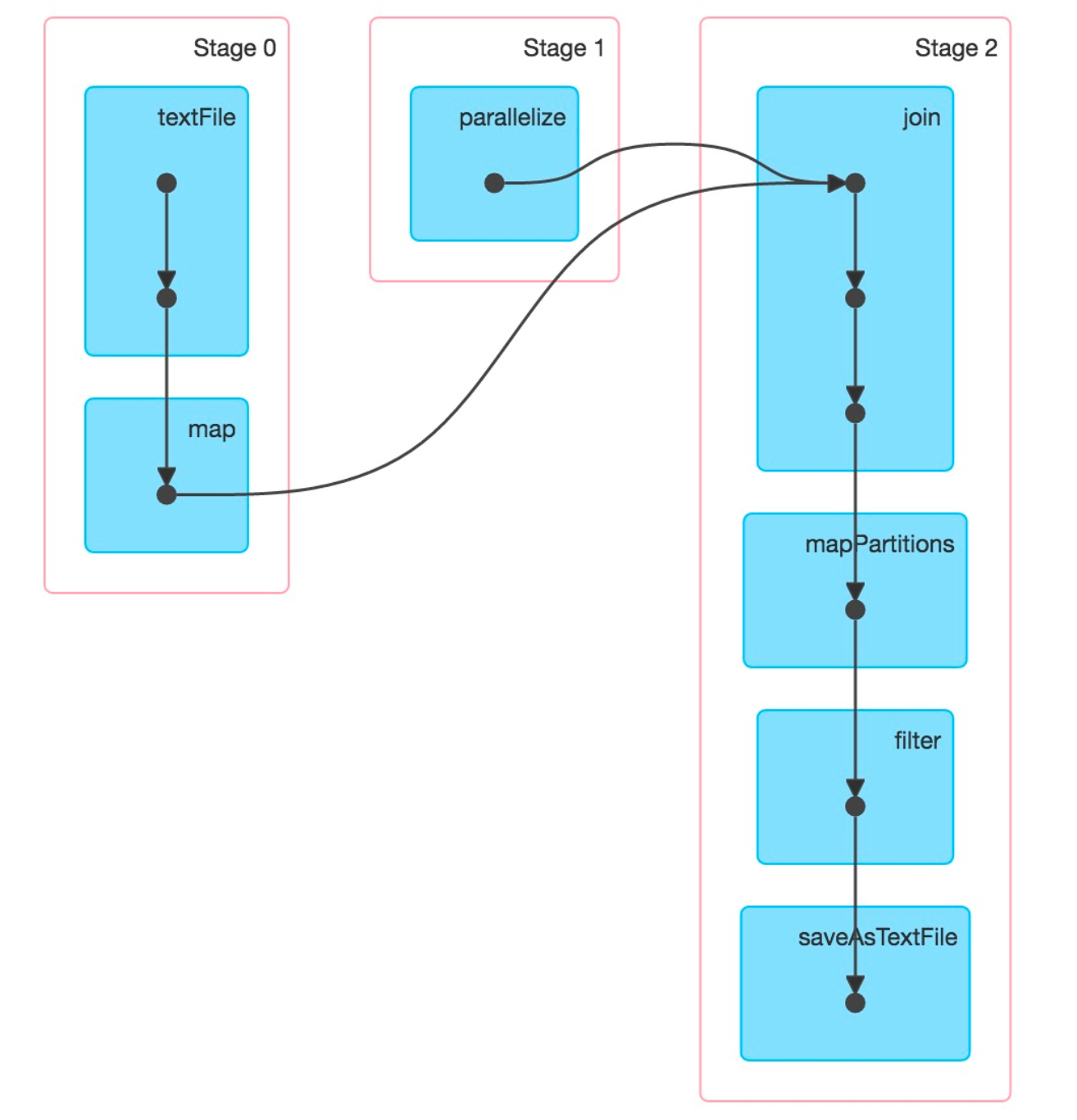 stage-split.png
stage-split.png
Morsel
Morsel is a concept similar to a “data block” proposed in this paper. It can be understood as multiple rows or tuples in a relational database. It is the smallest scheduling unit in this paper, corresponding to the parts marked with the same color in the figure below.
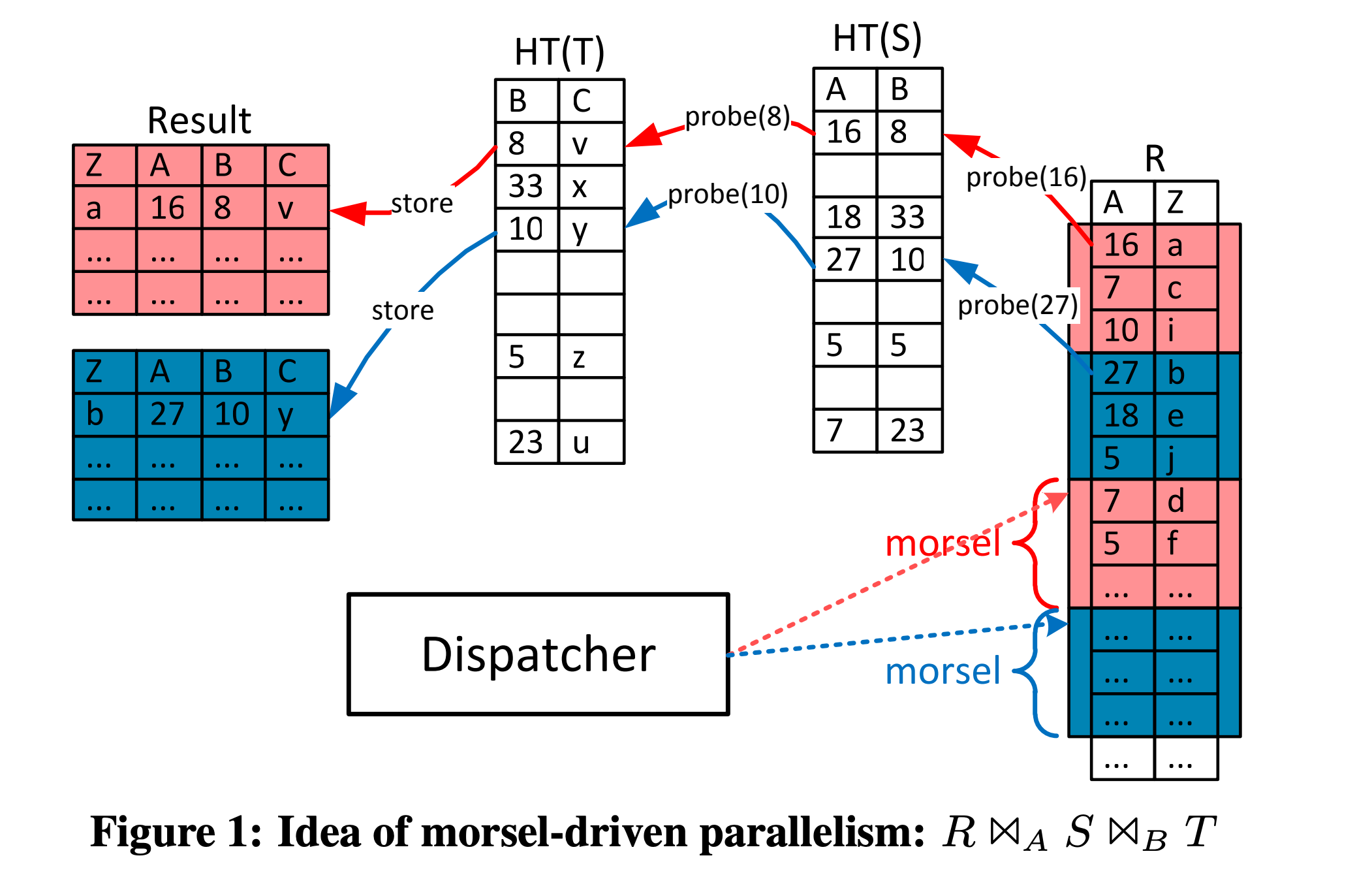 data-parallelism-morsel.png
data-parallelism-morsel.png
To understand morsel, one can compare it to CPU time slices. Only by dividing CPU time into appropriately sized time slices can we more easily design scheduling algorithms with high utilization (easier to do balanced scheduling), preemption (other tasks can take over time slices after a single time slice completes without waiting for the entire task to finish), and priorities (selecting tasks by priority when executing new time slices).
Content Overview
Morsel-Driven Execution
The paper first gives an example of an inner join of three tables: σ...(R) ⋈ A σ...(S) ⋈ B σ...(T), where S and T are small tables. During the Join, after scanning them, a HashTable is built; R is a large table, so after the HashTables for S and T are built, it is scanned to Probe. Splitting HashJoin into HashBuild (building the HashTable) and HashProbe (matching using the HashTable) is the classic HashJoin execution process.
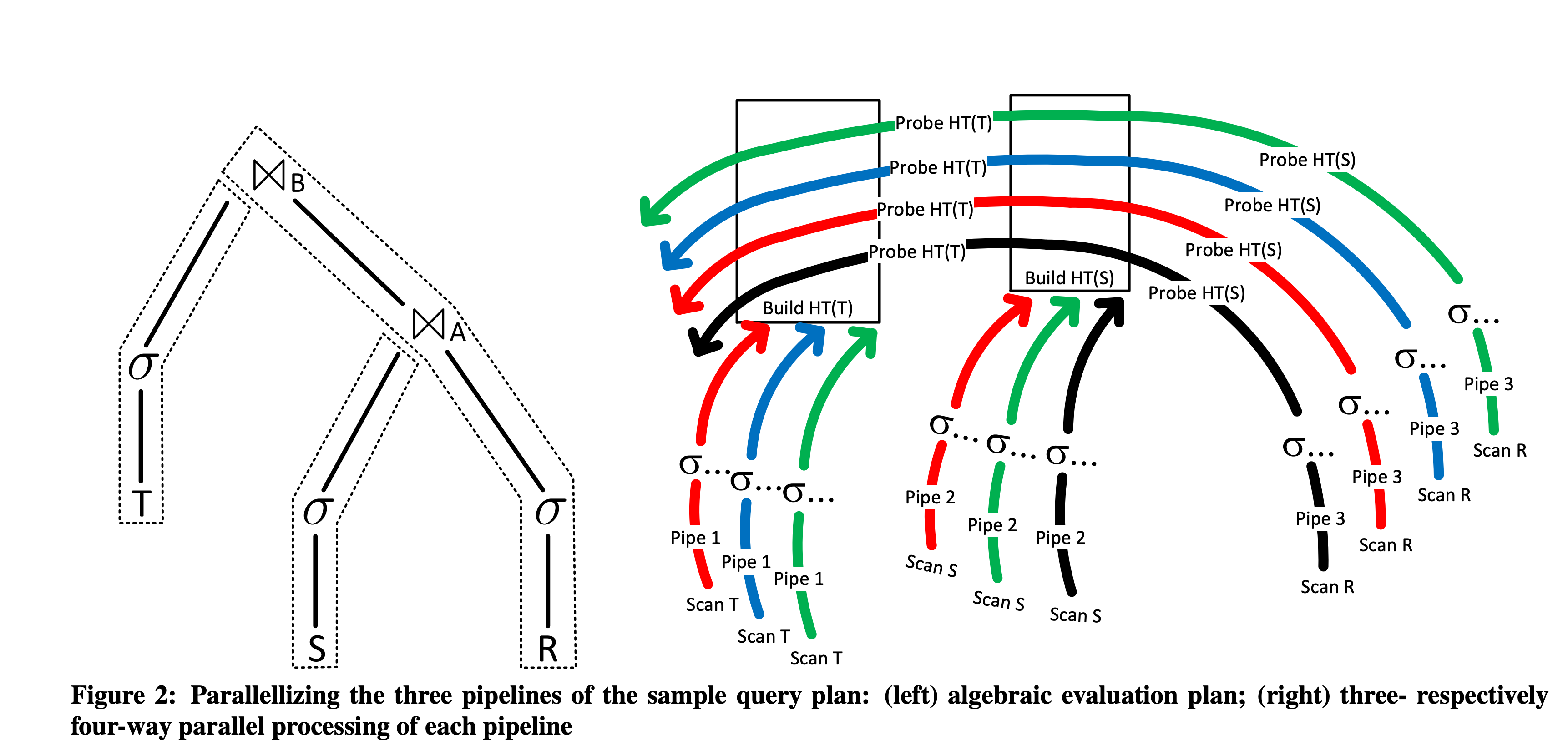 3-pipelines-parallelism.png
3-pipelines-parallelism.png
Combining the previous Pipeline background knowledge, we can infer that this execution plan will be divided into three Pipelines: HashTable(T) build, HashTable(S) build, and R Probe. Let’s discuss each:
HashTable Build. The build processes for the two HashTables are similar; taking HashTable(T) as an example, the build process is divided into two phases:
- Phase 1: The scan output of T is evenly distributed to the storage areas of several CPU cores at the morsel granularity, essentially a Partition process.
- Phase 2: The thread corresponding to each CPU core scans the assigned data partition (containing many morsels) and builds a global (cross-thread) HashTable, essentially a Merge process.
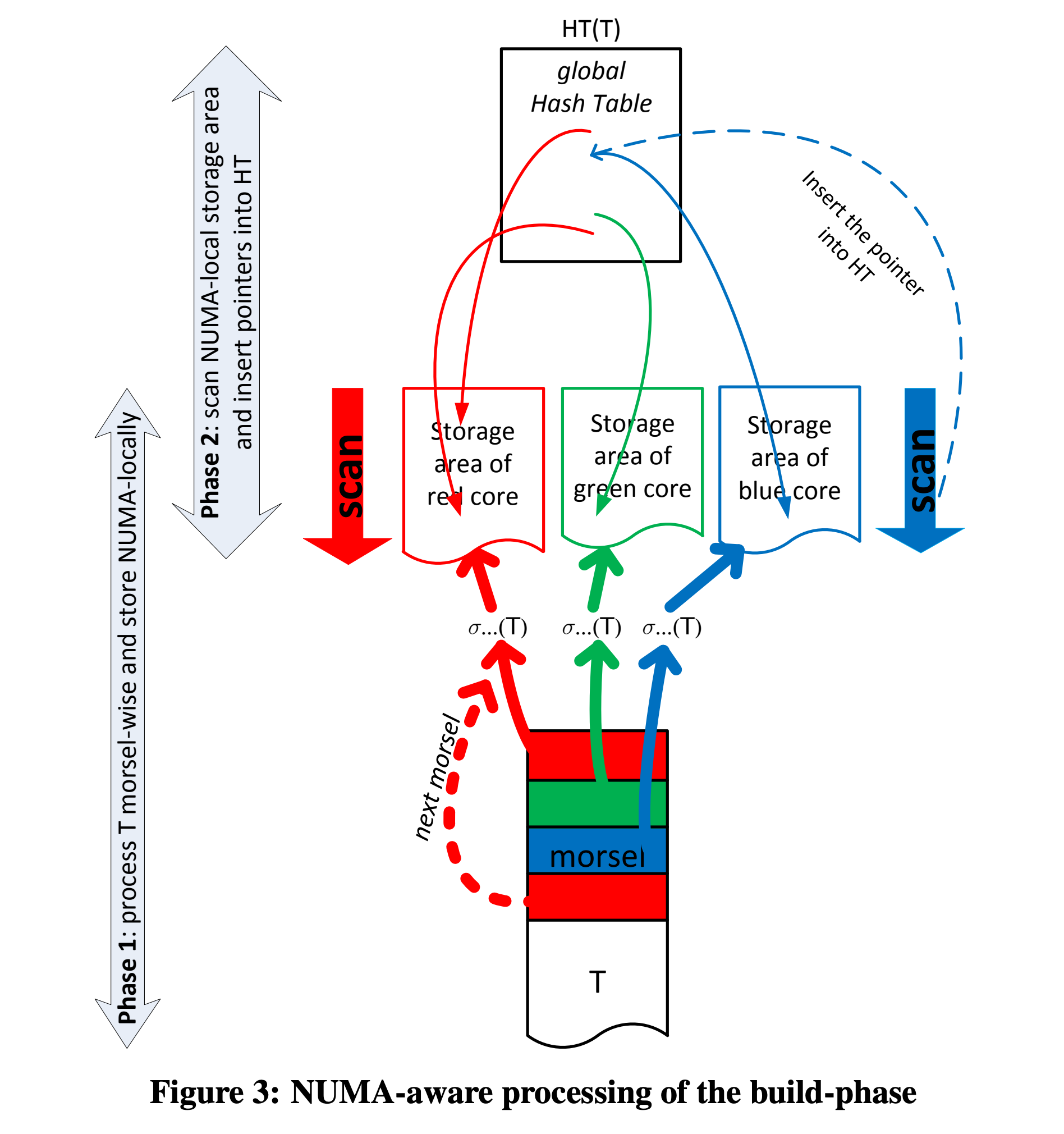 numa-aware-build-phase.png
numa-aware-build-phase.png
To process data in parallel, there is usually a data partitioning phase—splitting an input stream into multiple input streams in some way. Just as there is a split process before MapReduce.
The second phase involves cross-thread data writing, so some optimizations are needed for the implementation of the HashTable as a cross-thread global data structure:
- Determine the HashTable size in Phase 1, and pre-allocate the HashTable in one go, avoiding dynamic growth of the HashTable.
- Only insert pointers to data into the HashTable, avoiding cross-thread data copying.
- Use a lock-free structure for the HashTable, reducing performance degradation caused by contention during multi-threaded insertion.
HashTable Probe. After HashTable(T) and HashTable(S) are built, probing on table R begins. After scanning, R’s data is also distributed to multiple NUMA-nodes for parallel probing; after probing, output is also directed to the thread’s NUMA-local.
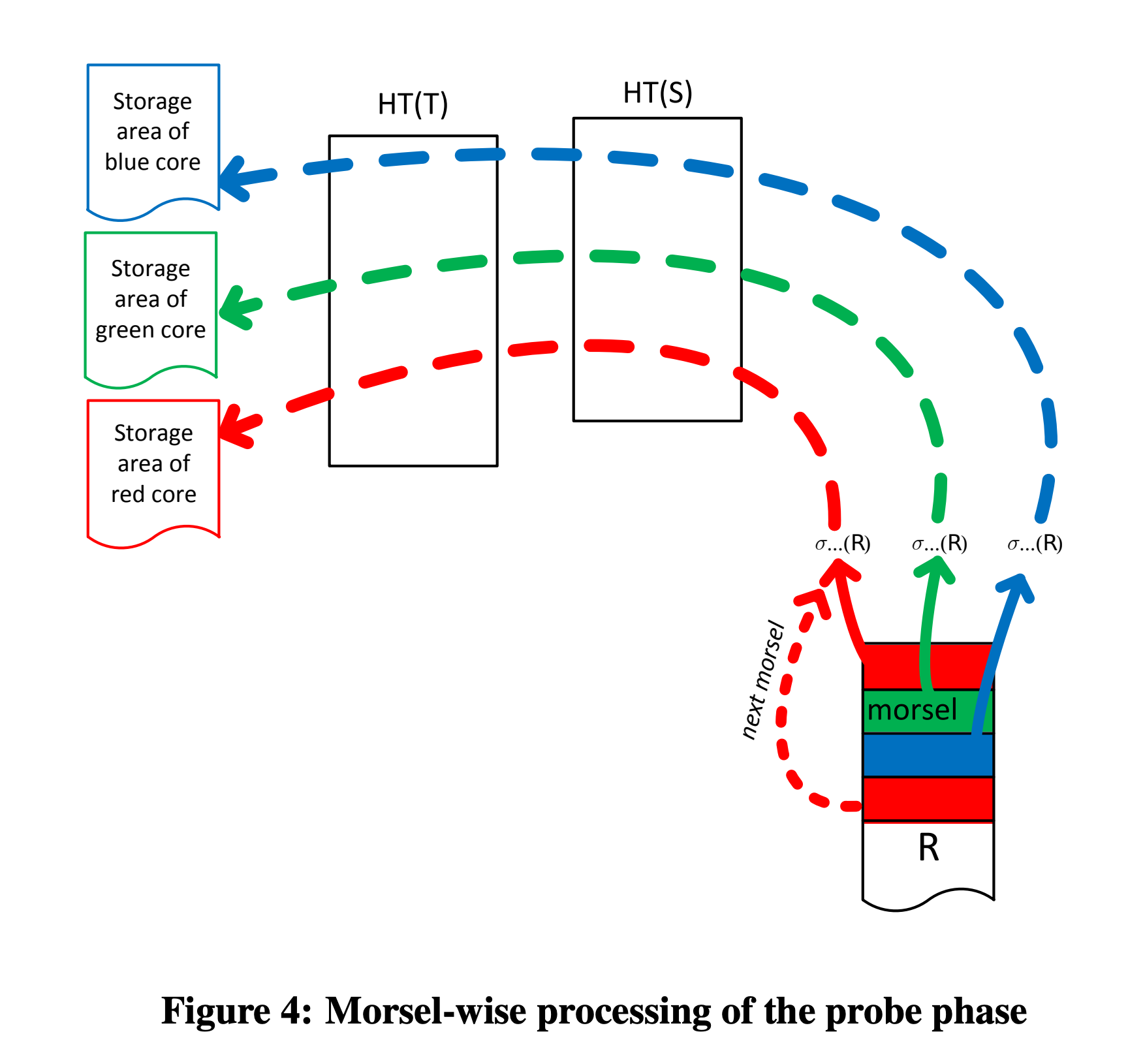 numa-aware-proble-phase.png
numa-aware-proble-phase.png
If there are other operators after probing, such as Top, Filter, Limit, etc., they will also be scheduled to execute on the NUMA-node where the Probe output resides.
Unlike the volcano model, these operators (such as HashJoin in the figure above) need to be aware of parallelism and require synchronization.
For the implementation of the Dispatcher and some specific operators, you can check out my system column.
References
- Paper by Viktor Leis et al., https://15721.courses.cs.cmu.edu/spring2016/papers/p743-leis.pdf
- draveness, NUMA Architecture Design: https://draveness.me/whys-the-design-numa-performance/
- dirtysalt, Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age: https://dirtysalt.github.io/html/morsel-driven-parallelism-framework.html
- Zhang Qiezi, Concurrent Execution and Scheduling of OLAP Tasks: https://io-meter.com/2020/01/04/olap-distributed/
This article is from my paid Xiaobot column “Daily System Notes”, focusing on distributed systems, storage, and databases. It includes series on graph databases, code reading, high-quality English podcast translations, database learning, paper reading, and more. Friends who like my articles are welcome to subscribe to the column to support me—your support is very important for my continued creation of high-quality articles. Below is the current article list:
Graph Database Series
- Graph Database Resources Collection
- Translation: Factorization & Great Ideas from Database Theory
- Memgraph Series (Part 2): Serializable Implementation
- Memgraph Series (Part 1): Multi-Version Data Management
- Graph Database Series 4: The “Fate” and “Conflict” with Relational Models
- Graph Database Series 3: Graph Representation and Storage
- Graph Database Series 2: A First Look at Cypher
- Graph Database Series 1: What is the Property Graph Model and Its Shortcomings 🔥
Database
- Translation: Fifty Years of Database Research Trends
- Translation: Code Generation in Databases (Codegen in Databas…
- Facebook Velox Execution Mechanism Analysis
- Distributed System Architecture (Part 2) — Replica Placement
- Recommended Reading: Pipeline Building in DuckDB
- Translation: Vector Databases Are All the Rage Lately, How Much Do You Know About Them?
- The Grand Unification of Data Processing — From Shell Scripts to SQL Engines
- Firebolt: How to Assemble a Commercial Database in Eighteen Months
- Paper: Appreciation of NUMA-Aware Query Evaluation Framework
- High-Quality Information Sources: Distributed Systems, Storage, Databases 🔥
- Vector Database Milvus Architecture Analysis (Part 1)
- The Modeling Philosophy Behind the ER Model
- What is a Cloud-Native Database?
Storage
- Storage Engine Overview and Resource Collection 🔥
- Translation: How RocksDB Works
- RocksDB Optimization Notes (Part 2): Prefix Seek Optimization
- RocksDB Optimization Notes (Part 3): Async IO
- Some Experiences Using RocksDB in Large-Scale Systems
Code & Programming
- Three “Codes” That Influenced How I Write Code 🔥
- Folly Asynchronous Programming with Futures
- On Interfaces and Implementations
- C++ Private Function Override
- ErrorCode or Exception?
- Infra Interview Data Structures (Part 1): Blocking Queue
- Data Structures and Algorithms (Part 4): Recursion and Iteration
Daily Database Learning Series
- Daily Database Learning Lecture #06: Memory Management
- Daily Database Learning Lecture #05: Data Compression
- Daily Database Learning Lecture #05: Workload Types and Storage Models
- Daily Database Learning Lecture #04: Data Encoding
- Daily Database Learning Lecture #04: Log-Structured Storage
- Daily Database Learning Lecture #03: Data Layout
- Daily Database Learning Lecture #03: Database and OS
- Daily Database Learning Lecture #03: Storage Hierarchy
- Daily Database Learning Lecture #01: Relational Algebra
- Daily Database Learning Lecture #01: Relational Model
- Daily Database Learning Lecture #01: Data Model
Miscellaneous
- Common Misconceptions in Database Interviews 🔥
- Life Engineering (Part 1): Multi-Round Decomposition🔥
- Some Interesting Concept Pairs in Systems
- Simplicity and Completeness in System Design
- The Cycle of Engineering Experience
- On Borrowing Names
- Cache and Buffer Are Both Caches, What’s the Difference?

