This article is based on the transcript of Amazon S3 VP Andy Warfield’s keynote speech at FAST '23, summarizing some of their experiences in architecting and maintaining an object storage system of such massive scale —— S3. As we know, Amazon S3 is one of the most important storage infrastructures of the cloud era. Nowadays, object storage services from various cloud providers are basically compatible with the S3 API, and all cloud-native infrastructure, such as cloud-native databases, ultimately relies on object storage as their final persistence layer.
Author: 木鸟杂记 https://www.qtmuniao.com/2023/11/15/s3-experience Please cite the source when reposting
As of 2023, Amazon S3 has turned 17 since its launch in 2006. Before we begin, let’s first look at a set of figures provided by Andy Warfield to get a sense of the scale that the world’s strongest object storage has reached:
 S3-metrics.png
S3-metrics.png
Namely,
- Capacity and throughput: Over 280 trillion objects, with an average QPS exceeding 100 million / s
- Events: S3 sends over 125 billion events to serverless applications every day
- Redundancy: Over 100 PB of data redundancy every week
- Cold storage retrieval: At least 1 PB of data is restored from S3 archival storage every day
- Data integrity checks: 4 billion integrity check computations performed per second
After gaining an intuitive understanding of this scale, let’s look at the experiences shared by Andy Warfield. For ease of narration, I will use the first person “we” below, referring to the S3 team.
The Impact of HDDs on S3 Design
Although SSDs have become increasingly affordable, HDDs are still widely used for storage at S3’s massive scale. One of the key reasons remains cost advantage (excellent storage density and lifespan). Compared to when they were first invented, HDDs have shrunk in size by over 5,000x, and the cost per byte has become cheaper by a factor of 6 billion! However, constrained by their mechanical characteristics, random access latency has only improved by about 150x.
When S3 was first launched, a fully loaded HDD’s IOPS was around 120, a figure that has remained largely unchanged over the years. This characteristic of HDDs —— ever-increasing storage density but stagnant access latency —— has had a significant impact on S3’s design: we must find ways to distribute traffic across different drives to avoid IO overload on any single disk.
Heat Management: Data Placement and Performance
For the reasons mentioned above, one of the most important and interesting problems S3 faces as it continuously scales is: how to manage and balance IO traffic across so many HDDs. We call this problem —— heat management.
The so-called heat: at any given point in time, refers to the IO requests a particular disk is handling. If not managed properly, severe skew in traffic between different disks will create localized access hotspots, leading to tail latency effects (“stragglers”). These tail requests get amplified layer by layer through S3’s software storage stack, potentially affecting request performance on a large scale. To solve this problem, we need to carefully consider data placement strategies.
Generally speaking, because it is impossible to predict the subsequent access patterns of data at write time (i.e., when the placement decision is made), it is difficult to eliminate all user access hotspots with a single strategy. However, due to S3’s scale and multi-tenant architecture, we can take a completely different approach.
We discovered a characteristic: the more workloads running on S3, the more decorrelated the requests for different objects become. For a single user’s storage unit (such as a set of Objects, or a Bucket), the typical access pattern is: long periods of dormancy followed by a sudden access spike far above the average. But when we aggregate millions of requests, something very interesting happens: the curve of total aggregated requests becomes very smooth, exhibiting some kind of inherent predictable pattern. You can get an intuitive feel by watching this video.
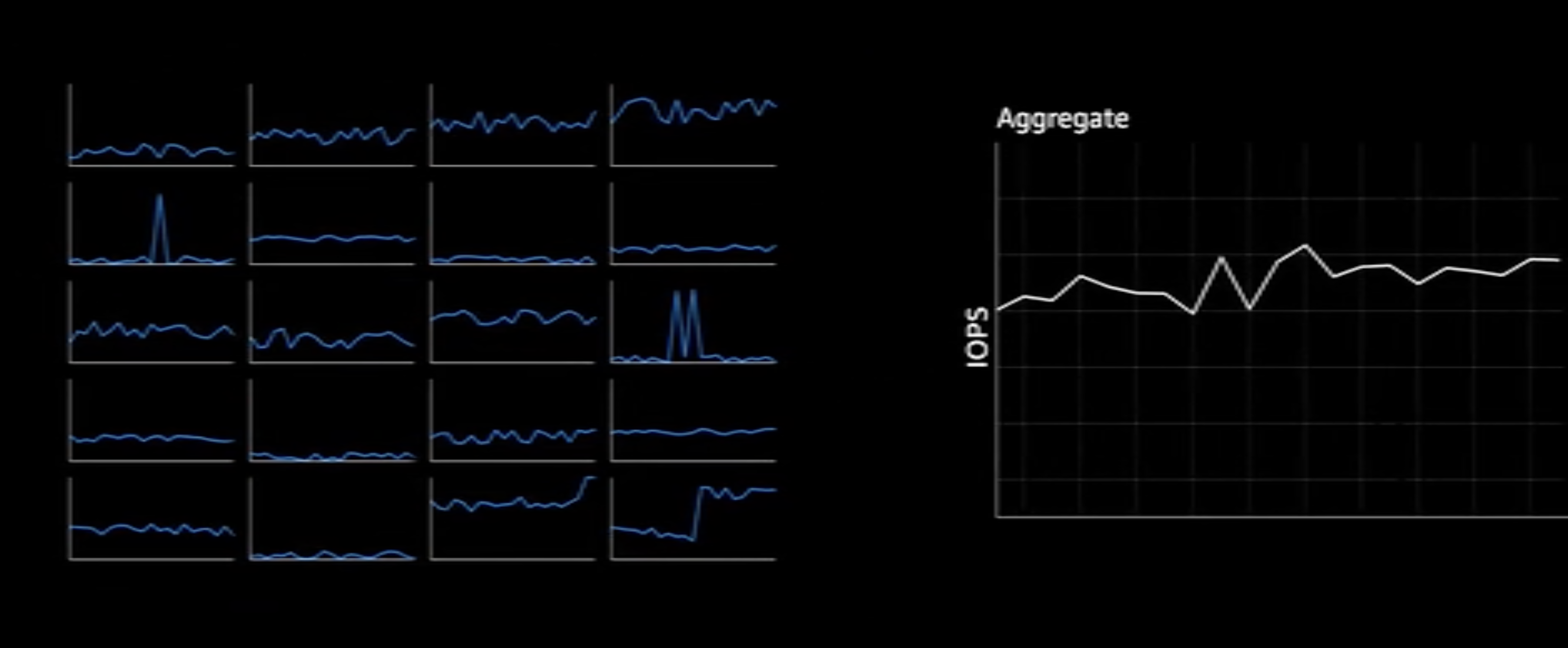 S3-aggreate.png
S3-aggreate.png
This also aligns with intuition: after thousands of uncorrelated access streams converge into an ocean, a single stream’s burst can hardly affect the overall trend. So our problem becomes: how to spread this relatively flat aggregated request rate across all disks, turning it into a relatively smooth IO access rate on each individual disk.
Data Replication: Data Placement and Durability
In storage systems, data redundancy is always used to protect data from hardware failures. But redundancy can also be used to manage heat. Having multiple replicas across multiple machines gives us the freedom to choose which machine to serve traffic from. From a storage capacity perspective, data redundancy drives up costs; but from an IO (at least read) perspective, data redundancy improves performance.
In addition to multi-replica redundancy, S3 naturally also uses EC (erasure coding) to reduce redundancy. The specific principles were introduced in our Facebook F4 article, which we won’t elaborate on here.
The Impact of Data Scale on Placement Strategies
Beyond using data redundancy to distribute traffic, the next thing we can do is: spread newly written object data as widely as possible across the drive pool. After spreading objects from the same bucket across different drives, a single user’s access traffic is also directed to different sets of drives. This approach has two benefits:
- Load isolation: If each user’s data only occupies a small area on a single disk, it is difficult for a single user’s access to “make waves” and create access hotspots on that disk.
- Hotspot smoothing: For any burst traffic, we can use an extraordinarily large-scale drive pool to smooth it out. This would be extremely expensive and unimaginable for small storage clusters.
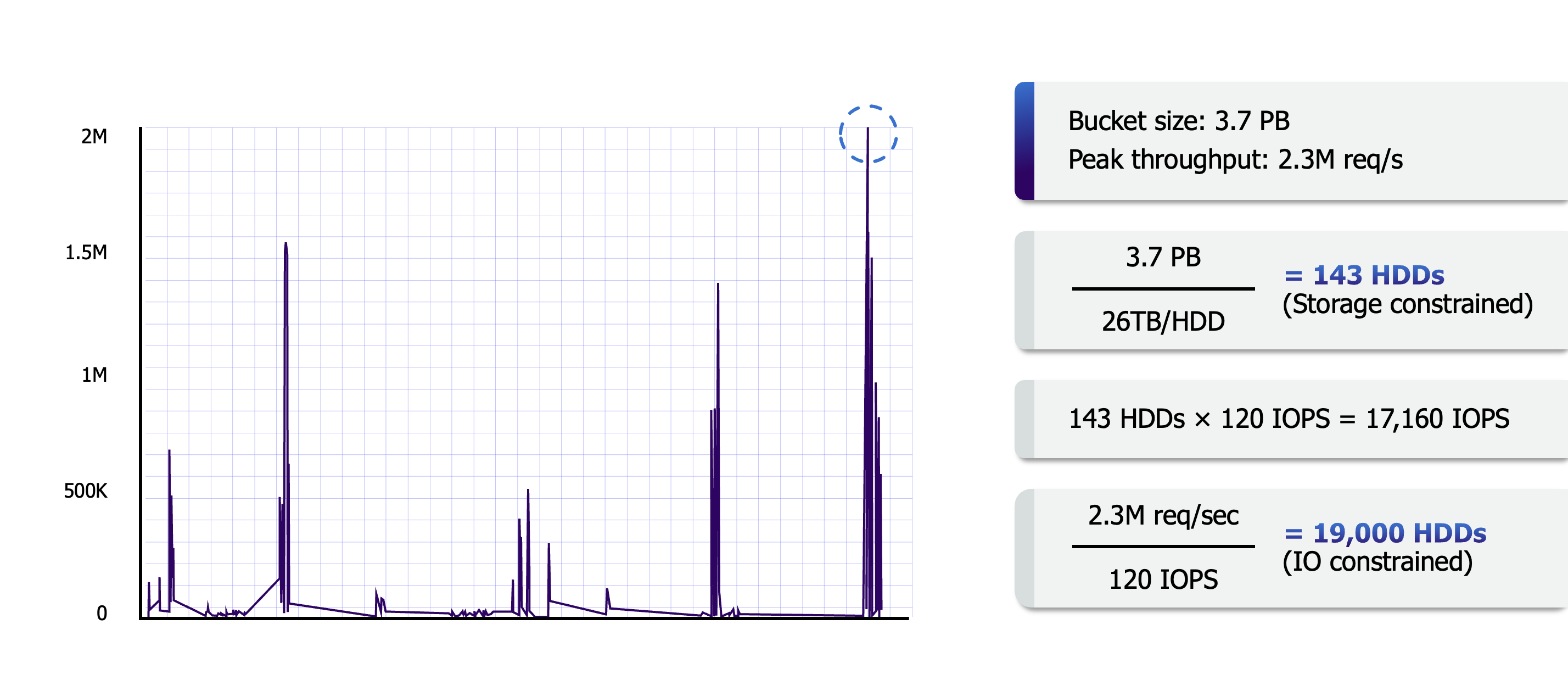 S3-flow-avg.png
S3-flow-avg.png
As shown in the figure above, a genomics research user might be using Lambda functions to perform large-scale parallel data analysis, with IOPS reaching 2.3M at one point, but we can easily meet this demand with millions of drives (as the calculation above shows, 20,000 fully loaded drives can meet it; with millions of drives, each only needs to operate at 1% capacity to suffice).
This scale of request handling is not unusual in S3. Currently, S3 clusters have at least tens of thousands of users whose buckets span across millions of drives. It is precisely S3’s massive volume of users and user data that makes this construction approach possible.
The Human Factor’s Impact on S3
This article is from my column “System Thinking Daily 2023”; there is more content in the column article. Your subscription is my greatest motivation for continuing to create high-quality content. The column currently has 82 articles, covering topics such as databases, storage, and systems. If you are interested in large-scale data systems, it is currently in a pre-completion discount period —— don’t miss out.

