I had heard of LevelDB long ago. This time, on a whim, I went through the code roughly with some reference materials, and it truly lives up to its reputation. If you are interested in storage, want to use C++ elegantly, or want to learn how to architect a project, I highly recommend studying it. Not to mention that the authors are Sanjay Ghemawat and Jeff Dean.
If I don’t produce something after reading it, given my memory, I will surely forget it soon. So I wanted to write something about the beauty of LevelDB, but I didn’t want to take the usual route, starting with an architectural overview and ending with module analysis. While reading the code, I kept thinking about where to start. Just as I was finishing, what impressed me most was actually the various ingenious data structures in LevelDB: tailored to the scenario, built from scratch, appropriately trimmed, and precisely coded. Why not start the LevelDB series with these small corner components?
This series mainly wants to share three classic data structures commonly used in engineering in LevelDB: the Skip List used for fast read/write of memtable, the Bloom Filter used for fast filtering of sstable, and the LRUCache used for partial caching of sstable. This is the first article, on the Skip List.
Requirements
LevelDB is a single-machine KV storage engine. A KV engine essentially only provides three interfaces for data entries (key, val): Put(key, val), Get(key) val, and Delete(key). In implementation, when LevelDB receives a delete request, it does not actually delete the data, but writes a special mark for that key, so that when reading, it finds that the key does not exist, thus converting Delete into Put, and reducing the three interfaces to two. After this simplification, what remains is a trade-off between Put and Get performance. LevelDB’s choice is: sacrifice some Get performance for powerful Put performance, and then optimize Get as much as possible.
As we know, in the Memory hierarchy, memory access is much faster than disk, so LevelDB made the following design choices to achieve its goals:
- Write (Put): Make all writes happen in memory, and then flush to disk in batches when a certain size is reached.
- Read (Get): As data is continuously written, there will be a small portion of data in memory and the remaining majority on disk. When reading, if it’s not found in memory, it needs to be looked up on disk.
To ensure write performance while optimizing read performance, the in-memory storage structure needs to support efficient insertion and lookup simultaneously.
When I first heard of LevelDB, my most natural thought was that the in-memory structure (memtable) was a self-balancing binary search tree, such as a red-black tree or AVL tree, which could guarantee lg(n) time complexity for both insertion and lookup. Only after reading the source code did I learn that it uses a skip list. Compared to balanced trees, the advantage of skip lists is that they greatly simplify the implementation while guaranteeing read/write performance.
In addition, to periodically dump data to disk, the data structure also needs to support efficient sequential traversal. To summarize, the requirements for LevelDB’s in-memory data structure (memtable) are:
- Efficient lookup
- Efficient insertion
- Efficient sequential traversal
Author: Muniao’s Notes https://www.qtmuniao.com/2020/07/03/leveldb-data-structures-skip-list/, please indicate the source when reposting
Principles
The skip list was proposed by William Pugh in 1990. The relevant paper is: Skip Lists: A Probabilistic Alternative to Balanced Trees. From the title, we can see that the author aimed to design a data structure that could replace balanced trees. As he mentioned at the beginning:
Skip lists are a data structure that can be used in place of balanced trees.
Skip lists use probabilistic balancing rather than strictly enforced balancing and as a result the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
A skip list is a data structure that can replace balanced trees.
Skip lists use probabilistic balancing rather than strictly enforced balancing strategies, thus greatly simplifying and speeding up element insertion and deletion compared to balanced trees.
There is a key phrase in this passage: probabilistic balancing. I’ll leave it as a teaser for now.
Next, we will interpret skip lists from two perspectives: linked lists to skip lists, and skip lists to balanced trees.
From Linked List to Skip List
In short, a skip list is a linked list with additional pointers. To understand this relationship, let’s think about the process of optimizing the lookup performance of an ordered linked list.
Suppose we have an ordered linked list. We know that its query and insertion complexity are both O(n). Compared to arrays, the reason linked lists cannot perform binary search is that they cannot use index-based constant-time data access, and therefore cannot quickly filter out half of the current scale each time. So how can we modify a linked list to make binary search possible?
Use a map to construct a mapping from index to node? Although this would allow binary search, each insertion would cause the indices of all subsequent elements to change, thus requiring O(n) updates in the map.
Add pointers so that from any node you can directly jump to any other node? That would require constructing a fully connected graph. Not only would the pointers consume too much space, but each insertion would still require O(n) pointer updates.
The skip list provides an idea: step sampling, building indexes, decreasing layer by layer. Let’s use a figure from the paper to explain in detail.
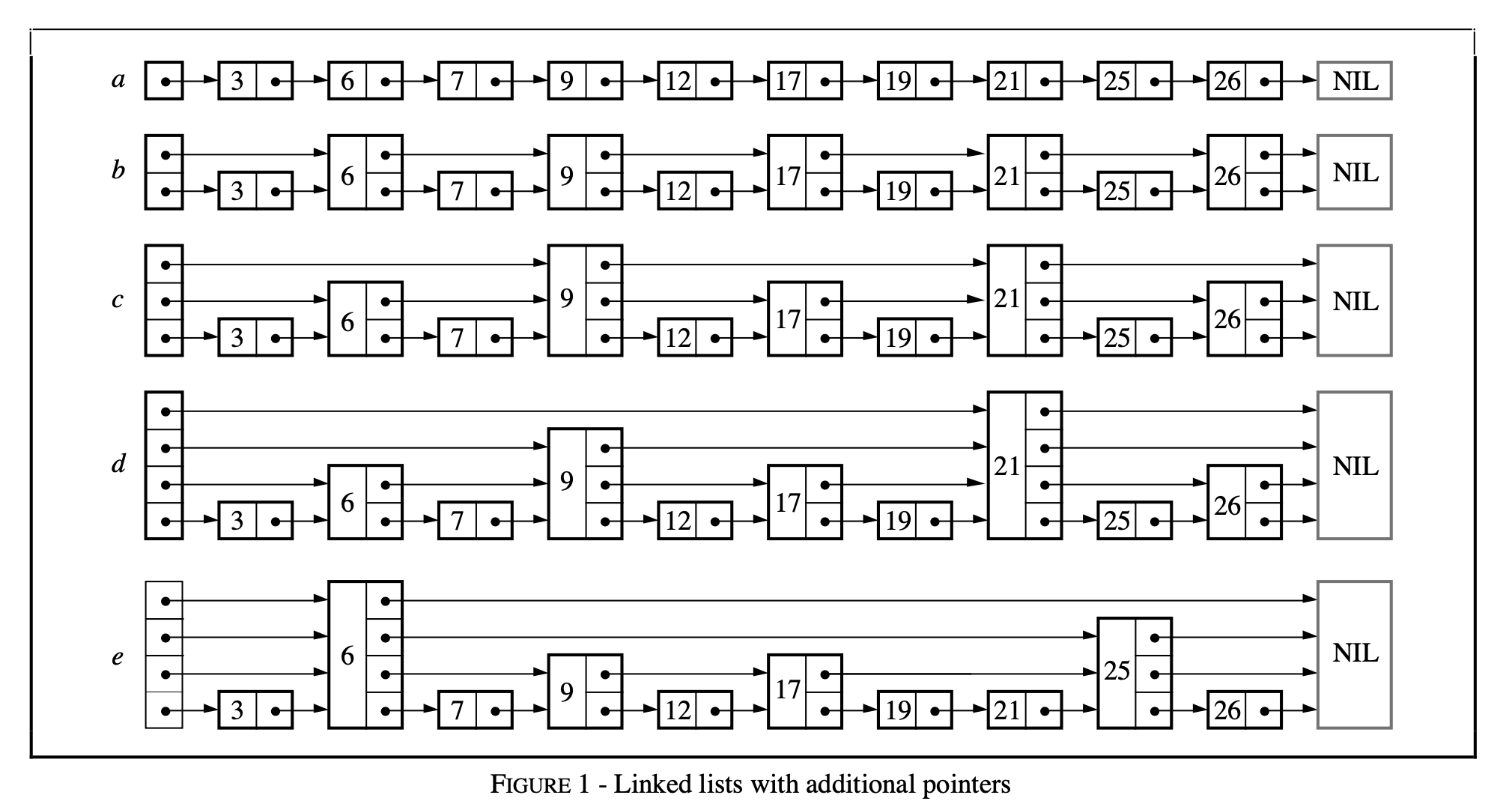 skiplist-linked-lists-with-additional-pointers.png
skiplist-linked-lists-with-additional-pointers.png
As shown in the figure, initially we have an ordered linked list a with a head node, and its lookup complexity is O(n). Then, we perform step sampling, connect the sampled nodes in order with pointers, and get table b. At this point, the lookup complexity is O(⌈n/2⌉ + 1) [Note 1]. After that, we perform step sampling again on the nodes sampled last time, connect them with pointers, and get table c. At this point, the lookup complexity is O(⌈n/4⌉ + 2). We repeat this process of step sampling and sequential connection until only one sampled node remains, as shown in figure e. At this point, the lookup complexity can be seen to be O(log2n) [Note 2].
The cost is that we add a bunch of pointers. How many more? Let’s consider this question step by step. From the figure, we can see that each time we sample a certain number of nodes, we add that many pointers. Our sampling strategy is to sample at intervals from the previous set of nodes each time, starting with n nodes and continuing until only one node remains. Summing them up: (n/2 + n/4 + … + 1) = n. This is the same number of pointers as a binary tree with n nodes.
Here we avoid one question: what is the insertion time complexity of this structure? This actually leads to the essential question: how should we perform insertion.
Skip List and Balanced Tree
In practice, we often use binary search trees as dictionaries or ordered lists. During insertion, if the data has good randomness in the key space, then sequential insertion into a binary search tree can maintain good query performance. But if we insert data sequentially, it will cause the binary search tree to become severely unbalanced, causing both read and write performance to degrade significantly.
To ensure performance, adjustments are needed when imbalance is detected, leading to AVL trees and red-black trees. As we all know, the rotation strategies of AVL and the coloring strategies of red-black trees are somewhat complex. At least, I didn’t remember them after roughly reading twice, and it’s impossible to write them by hand in an interview.
The skip list, while guaranteeing the same query efficiency, uses a clever transformation that greatly simplifies the implementation of insertion. We cannot guarantee that all insertion requests have good randomness, or balance, in the key space; but we can control the balance of each node in other dimensions. For example, the probabilistic balance of the distribution of the number of pointers per node in a skip list.
Probabilistic Balancing
To better explain this problem, let’s sort out the structure of the skip list and the concepts involved. Each node in a skip list has 1 ~ MaxLevel pointers; a node with k pointers is called a level k node; the maximum level of all nodes is the MaxLevel of the skip list. The skip list has an empty head node, which has MaxLevel pointers.
According to the previous idea of building a skip list from an ordered linked list, each insertion of a new node becomes a difficult problem. For example, how many pointers should the inserted node have? How can we ensure that lookup performance does not degrade after insertion (i.e., maintain the balance of sampling)?
To solve this problem, Pugh made a clever transformation: decomposing the global, static index building into independent, dynamic index building. The key lies in maintaining the probability distribution of the number of pointers of global nodes in the skip list to maintain query efficiency. Analyzing the above process of building indexes by step sampling layer by layer, we can find that in the built skip list, 50% of the nodes are level 1 nodes, 25% are level 2 nodes, 12.5% are level 3 nodes, and so on. If we can maintain that the nodes in our constructed skip list have the same probability distribution, we can guarantee similar query performance. This seems intuitively correct. I won’t delve into the mathematical principles behind it here; interested students can go read the paper.
After such a transformation, the two problems raised above are solved:
- The number of pointers for a newly inserted node is determined by independently calculating a probability value, so that the number of pointers of global nodes satisfies a geometric distribution.
- No additional node adjustments are needed during insertion. We only need to find the position where it should be placed, and then modify the pointers of itself and its predecessors.
Thus, the time complexity of inserting a node is the sum of the lookup time complexity O(log2n) and the pointer modification complexity O(1) [Note 3], which is also O(log2n). The deletion process is similar to insertion and can also be transformed into a lookup and pointer modification, so the complexity is also O(log2n).
Source Code Analysis
After much anticipation, let’s get to the main topic. LevelDB’s implementation of SkipList adds code for optimizing multi-threaded concurrent access, providing the following guarantees:
- Write: When modifying the skip list, locking is required on the user code side.
- Read: When accessing the skip list (lookup, traversal), it is only necessary to ensure that the skip list is not destroyed by other threads; no additional locking is required.
That is, the user side only needs to handle write-write conflicts; LevelDB’s skip list guarantees no read-write conflicts.
This is because LevelDB makes the following invariants in its implementation:
- Unless the skip list is destroyed, skip list nodes will only increase and will not be deleted, because the skip list does not provide a deletion interface at all.
- Nodes inserted into the skip list are immutable except for the next pointer, and only insertion operations will change the skip list.
Interface
LevelDB’s Skip List mainly provides three external interfaces: insertion, query, and traversal.
1 | // Insert key into the skip list. |
For flexibility, LevelDB’s SkipList uses a class template (template class), allowing the caller to customize the type of Key and customize the comparison class Comparator based on that Key.
Before analyzing these interfaces in detail, let’s first look at the data structure of the basic element SkipList::Node. There is some synchronization code for multi-threaded read/write of shared variables in the code. This mainly involves instruction reordering, which I’ll briefly explain below.
As we know, compilers/CPUs will reorder instructions as needed (to speed up execution, optimize memory, etc.) while ensuring the same effect. This is indeed fine for single-threaded code. But for multi-threading, instruction reordering can make the execution order of code between threads counterintuitive. Here’s an example in Go:
1 | var a, b int |
This code snippet may print 2 0!
The reason is that the compiler/CPU reordered the assignment order in f() or the print order in g(). This means that multi-threaded code written intuitively may have problems. Because you implicitly assume that the execution order within a single thread follows the code order, and that although code execution in multi-threading may interleave, each thread still maintains its own internal code order. But this is not the case. Due to compiler/CPU instruction reordering, without explicit synchronization, you cannot make any assumptions about the execution order between threads.
Back to the LevelDB skip list code, it mainly involves several memory orders newly supported in the C++11 atomic standard library, which specify some restrictions on instruction reordering. I’ll only explain the three used here:
std::memory_order_relaxed: No restrictions on reordering; only guarantees atomicity of related shared memory accesses.std::memory_order_acquire: Used in load, guaranteeing that subsequent reads/writes to related memory in the same thread will not be reordered before this load, and that stores with release from other threads to the same memory are visible.std::memory_order_release: Used in store, guaranteeing that subsequent reads/writes to related memory in the same thread will not be reordered before this store, and that all modifications in this thread are visible to other threads using load acquire.
1 | template <typename Key, class Comparator> |
Lookup
Lookup is the basis of insertion. Each node must first find a suitable position before insertion. Therefore, LevelDB abstracts a common function: FindGreaterOrEqual:
1 | template <typename Key, class Comparator> |
The meaning of this function is: find the first value in the skip list that is not less than the given key; if not found, return nullptr. If the parameter prev is not empty, during the lookup process, record the predecessor nodes of the node to be found at each level. Obviously, for a lookup operation, just specify prev = nullptr; for inserting data, a prev parameter of appropriate size needs to be passed.
1 | template <typename Key, class Comparator> |
This process is illustrated below using a figure from the paper:
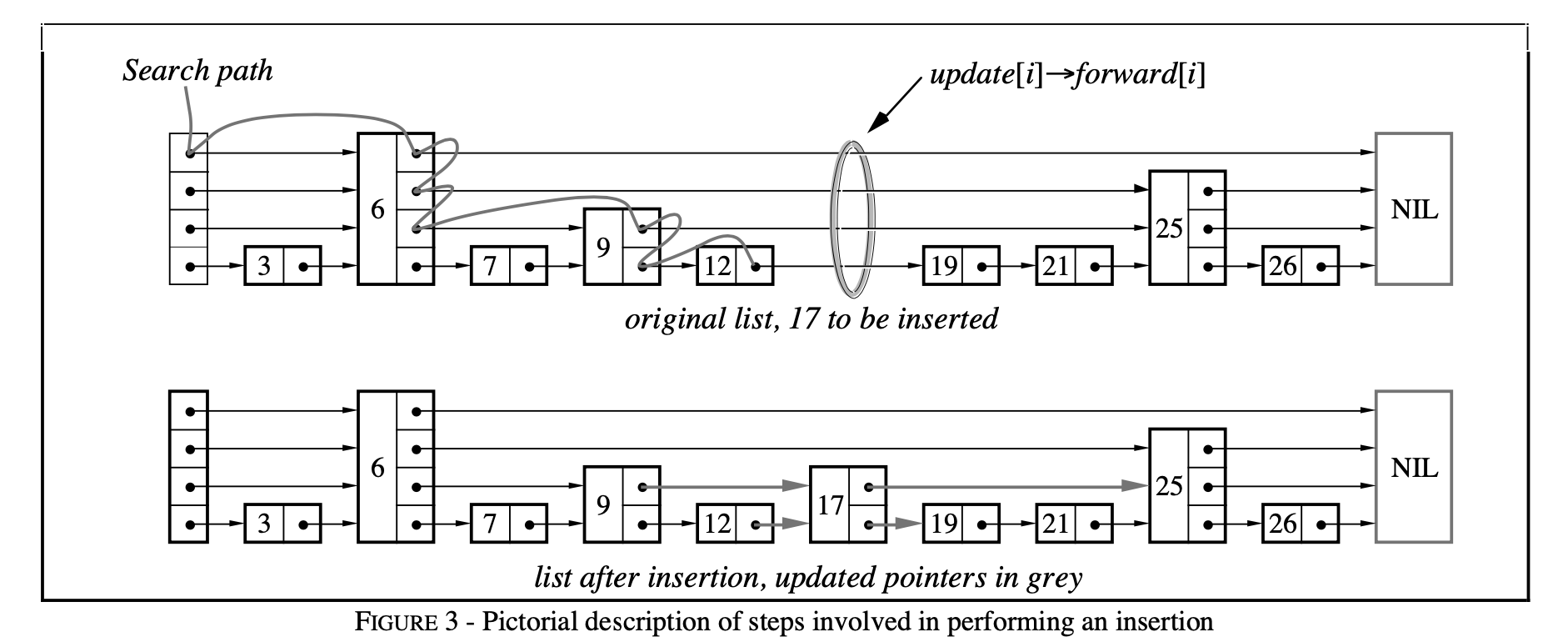 skiplist-search-insert.png
skiplist-search-insert.png
Insertion
On the basis of FindGreaterOrEqual, record the predecessor nodes of the node to be inserted at each level. For example, in the figure above, after calling FindGreaterOrEqual(17, prev), prev = [12, 9, 6, 6]. The insertion code is as follows:
1 | template <typename Key, class Comparator> |
The complexity of LevelDB’s skip list implementation lies in providing correctness guarantees for lock-free concurrent reads. But the key point of the algorithm is how to determine the level of each newly inserted node to satisfy probabilistic balancing, thereby providing efficient query performance. That is, the implementation of RandomHeight:
1 | template <typename Key, class Comparator> |
LevelDB’s sampling is relatively sparse, sampling one out of every four, and the maximum level is kMaxHeight = 12. The specific implementation process is the construction of a geometric distribution with P = 3/4. The result is that among all nodes: 3/4 are level 1 nodes, 3/16 are level 2 nodes, 3/64 are level 3 nodes, and so on. Thus, the average number of pointers per node is 1/P = 4/3 = 1.33. Of course, the meaning of p in the paper is the sampling ratio between adjacent levels, and its relationship with the P I mentioned is: p = 1-P.
Choosing p = 1/4 compared to p = 1/2 is trading time for space, sacrificing some constant query efficiency for a reduction in the average number of pointers, thereby reducing memory usage. The paper also recommends p = 1/4 unless read speed requirements are particularly strict. In this case, it can support up to n = (1/p)^kMaxHeight nodes without degradation of query time complexity. If kMaxHeight = 12, the skip list can support up to n = 4 ^ 12 = 16M values.
Traversal
LevelDB constructs an inner class Iterator for the skip list, which takes SkipList as a constructor parameter and implements most of the functions of the Iterator interface exported by LevelDB, such as Next, Prev, Seek, SeekToFirst, SeekToLast, etc.
1 | template <typename Key, class Comparator> |
It can be seen that this iterator does not add an extra prev pointer to each node for reverse iteration, but instead chooses to search from the head. This is also a trade-off of time for space. Of course, the assumption is that forward traversal is relatively rare.
The implementation of FindLessThan and FindLast is similar in idea to FindGreaterOrEqual, so I won’t elaborate further.
1 | // Return the latest node with a key < key. |
Summary
The skip list is essentially an optimization of the linked list. It builds indexes by step sampling layer by layer to speed up lookup. Using the idea of probabilistic balancing, it determines the level of newly inserted nodes to satisfy a geometric distribution, simplifying the implementation of insertion while guaranteeing similar lookup efficiency.
LevelDB’s skip list implementation also specifically optimizes for multi-threaded reads, but writes still require external locking. In terms of implementation strategy, it adopts a time-for-space approach to optimize memory usage.
In the next article, we will continue to analyze another classic data structure used in LevelDB: the Bloom Filter.
Annotations
[1] First search at the upper level, then narrow down to a certain range and search at the lower level.
[2] It can be proven, or we can simply find the pattern: O(⌈n/2⌉ + 1) -> O(⌈n/4⌉ + 2) -> … -> O(1 + log2n), i.e., O(log2n).
[3] From the sampling process, we know that the probabilities of all nodes satisfy a geometric distribution with p = 0.5. The expected number of pointers per node is 1/p = 2, so each insertion requires modifying 2 * 2 pointers on average, which is a constant level.
References
- LevelDB handbook: https://leveldb-handbook.readthedocs.io/zh/latest/index.html
- Dissecting LevelDB - Data Storage: https://catkang.github.io/2017/01/17/leveldb-data.html
- C++ atomic memory order: https://en.cppreference.com/w/cpp/atomic/memory_order
The last thing
There is a simplified version of a skip list problem on LeetCode. After reading this article, you can take the opportunity to implement it: https://leetcode.com/problems/design-skiplist/
This is my implementation: https://leetcode.com/problems/design-skiplist/discuss/740881/C%2B%2B-clean-and-simple-solution-from-leveldb

