Zookeeper
This post introduces the paper by Patrick Hunt et al. published in 2010, still widely used today, positioned as a distributed system coordination component —— ZooKeeper: Wait-free coordination for Internet-scale systems. When programming with multiple threads and processes, we inevitably need synchronization and mutual exclusion; common methods include shared memory, message queues, locks, semaphores, etc. In distributed systems, different components also inevitably need similar coordination mechanisms, and thus Zookeeper was born. Combined with client libraries, Zookeeper can provide dynamic parameter configuration (configuration metadata), distributed locks, shared registers (shared register), service discovery, group membership, leader election, and a series of other distributed system coordination services.
Overall, Zookeeper has the following characteristics:
- Zookeeper is a distributed coordination kernel with relatively cohesive functionality, keeping the API simple and efficient.
- Zookeeper provides a set of high-performance, FIFO-guaranteed, event-driven non-blocking APIs.
- Zookeeper organizes data using a filesystem-like directory tree, offering powerful expressiveness and making it convenient for clients to build more complex coordination primitives.
- Zookeeper is a self-contained fault-tolerant system, using the Zab atomic broadcast (atomic broadcast) protocol to ensure high availability and consistency.
This article follows the order of the paper, briefly introducing Zookeeper’s service interface design and rough module implementation. For more details, please refer to the paper and the open source project homepage.
Author: 木鸟杂记 https://www.qtmuniao.com/2021/05/31/zookeeper, please indicate the source when reposting
Service Design
When designing service interfaces, we must first abstract the basic concepts involved in service organization and interaction, and then clarify the set of actions surrounding these basic concepts. For Zookeeper, these basic concepts are called Terminology (Terminology), and the set of actions is called the API (Application Programming Interface).
Terminology
- Client: client, the user of Zookeeper services.
- Server: server, the process that provides Zookeeper services.
- Data tree: data tree, all data in Zookeeper is organized in a tree structure.
- znode: znode, Zookeeper Node, a node in the data tree and the basic data unit.
- Session: session, a client and server establish a session to identify a connection; afterwards, each client request is made through this session handle. The lifecycle of Watch events is also bound to the session.
In the following text, the Chinese and English terms may be used interchangeably.
Data Organization
Zookeeper organizes stored data in a hierarchical tree structure similar to a file system, providing users with greater flexibility. For example, it can naturally represent namespaces (namespace), and use all children under the same parent node to represent membership (membership). A Path can locate a unique data node, thereby uniquely identifying a basic data unit.
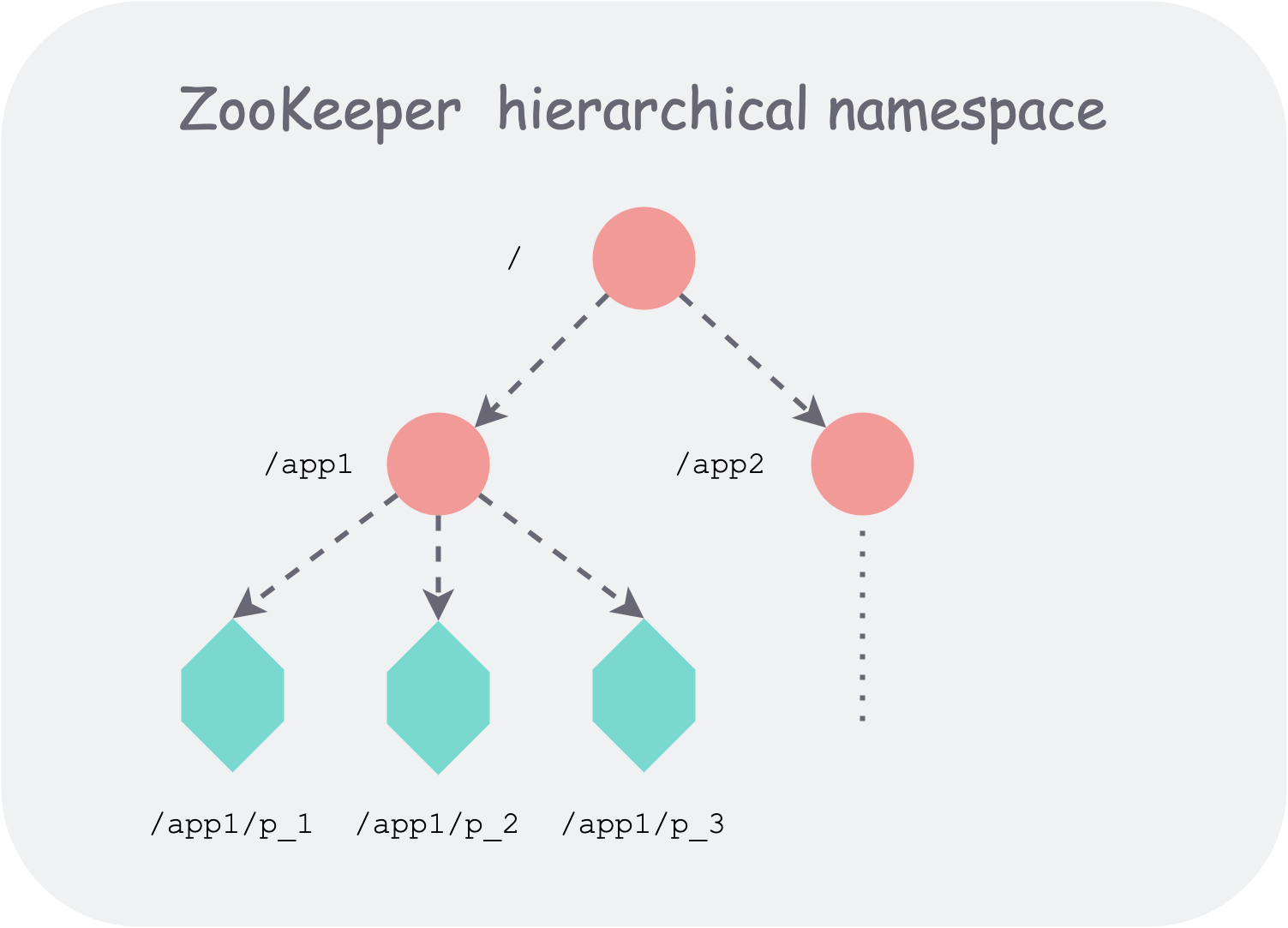 zookeeper hierarchical namespace organization
zookeeper hierarchical namespace organization
The tree supports two types of znodes:
- Regular node: Regular, with an infinite lifecycle; clients need to explicitly call interfaces to create or delete such nodes.
- Ephemeral node: Ephemeral, whose lifecycle is bound to a session; when the session is destroyed, the node is deleted.
In addition, Zookeeper allows clients to attach a sequential flag when creating a znode. Zookeeper will then automatically append a globally monotonically increasing counter as a suffix to the node name.
Zookeeper implements a subscription mechanism using a push model, i.e., after a user subscribes (sets a watch) on a node, when that node changes, the client receives a one-time notification (edge-triggered). A watch is bound to a session, so after the session is destroyed, the watched events also disappear.
Session mechanism (session). As can be seen, Zookeeper uses the session mechanism to manage the lifecycle of a client connection. In implementation, a session is associated with a timeout interval (timeout). If the client dies or disconnects from Zookeeper, and fails to send a heartbeat within the timeout period, Zookeeper will destroy the session on the server side.
Data model (Data model). Zookeeper essentially provides a hierarchically organized KV model. In addition to storing key-value data, Zookeeper more often uses its hierarchical structure and lifecycle management as expressive power to provide coordination semantics. Of course, Zookeeper also allows clients to attach some meta-data and configuration (configuration) to nodes, and provides version and timestamp support, thereby offering more powerful expressiveness.
API Details
Below are the API details and comments provided by Zookeeper for clients, listed in pseudocode. All operation objects are the data nodes (znode) corresponding to paths (path).
1 | // Creates a znode at path, stores data |
The above APIs have the following characteristics:
- Asynchronous support. All interfaces have both synchronous (synchronous) and asynchronous (asynchronous) versions. The asynchronous version is executed via callback functions; clients can choose to block and wait for important updates, or make asynchronous calls for better performance, according to business needs.
- Path rather than handle. To simplify interface design and reduce state maintained on the server side, Zookeeper uses paths rather than znode handles to provide operation interfaces for znodes. After all, handles are stateful, similar to sessions, which increases the implementation complexity of distributed systems. Using paths, combined with version information, allows for idempotent-like interfaces, making it easier to handle concurrency among multiple clients.
- Version information. All update operations (set/delete) need to specify the version number of the corresponding data; if the version number does not match, the update is aborted and an exception is returned. However, by specifying the special version number -1, the version check can be skipped.
Semantic Guarantees
When processing concurrent requests from multiple clients to Zookeeper, the API has two basic ordering guarantees:
- Linearizable writes (Linearizable writes). All update requests to Zookeeper state are serialized.
- FIFO client order (FIFO client order). Requests from a given client are executed in the order they are sent.
However, the linearizability here is a form of asynchronous linearization: A-linearizability. That is, a single client can have multiple outstanding operations (multiple outstanding operations) at the same time, but these requests are executed in the order they were issued. Read requests can be executed locally on each server (without going through the leader). Therefore, throughput for read requests can be increased by adding servers (Observers).
In addition, Zookeeper provides liveness and durability guarantees:
- Liveness (liveness): If more than half of the nodes in the Zookeeper cluster are available, it can provide normal service externally.
- Durability (durability): Any modification request that has been successfully returned to the client will be applied to the Zookeeper state machine. Even if nodes fail and restart continuously, as long as Zookeeper can provide normal service, this property will not be affected.
Zookeeper Architecture
To provide high reliability, Zookeeper uses multiple servers for redundant data storage. It then uses the Zab consensus protocol to process all update requests, writes them to WAL, and applies them to the local in-memory state machine (data tree).
In the Zab protocol, all nodes are divided into two roles, Leader and Followers; there is only one Leader, and the rest are Followers. However, in later practice, there may be Observers.
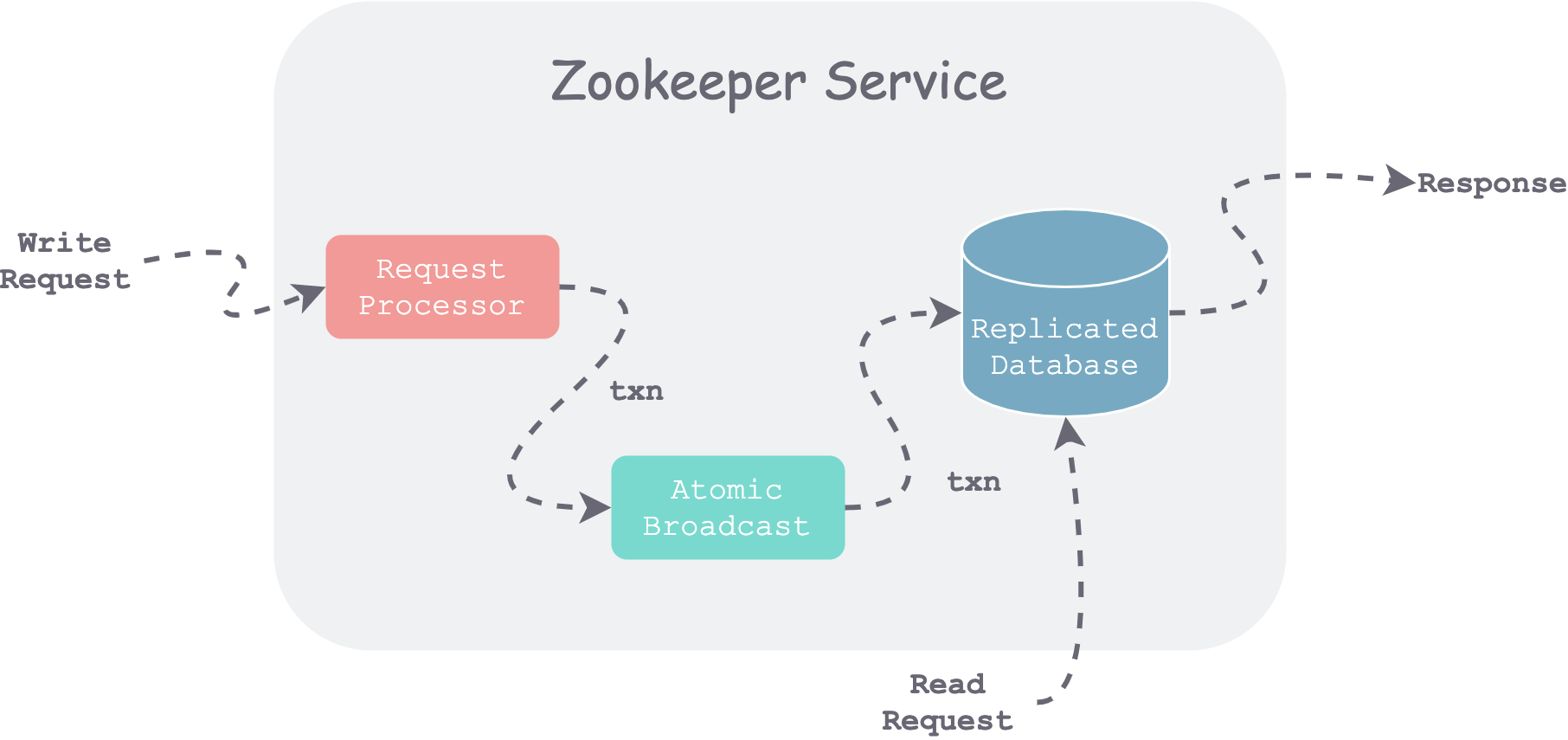 zookeeper components and request flow
zookeeper components and request flow
As shown in the figure above, when a Server receives a request, it first performs preprocessing (Request Processor). If it is a write request, consensus is reached through the Zab protocol (Atomic Broadcast), and then each server commits to its local database (Replicated Database). For read requests, it directly reads the local database state and returns.
Request Processor (Request Processor)
All update requests are converted into idempotent transactions (txn). The specific method is to obtain the current state, compute the target state, encapsulate it as a transaction, and then process concurrent requests in a manner similar to CAS. Therefore, as long as all transactions are executed in a fixed order, data replica divergence on different servers can be avoided.
Atomic Broadcast (Atomic Broadcast)
All update requests are forwarded to the Zookeeper Leader. The Leader first appends the transaction to its local WAL, then broadcasts the change to each node using the Zab protocol. After receiving successful replies from a majority, the Leader commits the change to its local in-memory database and broadcasts this Commit to the Followers.
Since Zab uses a majority voting principle, a cluster of 2k+1 nodes can tolerate at most k node failures (failures).
To improve system throughput, Zookeeper uses a pipelined (pipelined) approach to optimize the processing of multiple requests.
Replicated Database (Replicated Database)
Each server maintains a replica (replica) of all Zookeeper state in its local memory. To cope with crash restarts, ZooKeeper periodically takes snapshots of the state. Unlike ordinary snapshots, Zookeeper calls its snapshots fuzzy snapshots, meaning no locks are held while taking the snapshot; it dumps the file tree to local storage via DFS traversal. After an abnormal crash and restart, it only needs to load the latest snapshot and then re-execute the WAL entries after the latest snapshot. Due to the idempotent nature of the transactions recorded in the WAL, even if the snapshot and WAL time points do not fully correspond, it will not affect consistency among replicas.
Client-Server Interactions (Client-Server Interactions)
Serial writes. Whether globally or locally on a specific Server, all update operations are serialized. When executing a data update on a certain Path, the Server triggers all Watch events subscribed to by Clients connected to it. Note that these events are only stored locally on the Server, because they are associated with sessions; if a Client disconnects from this Server, the session is destroyed, and these events also perish.
Local reads. To achieve ultimate performance, Zookeeper Servers process read requests directly locally. However, this may cause clients to obtain stale data (for example, another client updated the same Path on another Server). Therefore, Zookeeper designed the Sync operation, which synchronizes the latest committed data at the time Sync is called to the Server connected to that Client, and then returns the latest data to the Client. That is, Zookeeper leaves the choice between performance and freshness to the user, through whether or not to call Sync.
Consistent view. Zookeeper globally maintains a monotonically increasing transaction identifier: zxid, which is essentially a logical clock that can identify the data view of Zookeeper at a certain moment. When a Client restarts after a failure and reconnects to a new Server, if that Server has not executed up to the zxid stored by the client, then either the Server executes up to that zxid before replying to the Client, or the Client connects to a more up-to-date Server. In this way, it is guaranteed that the Client will not see a regressed view.
Session expiration. A session in Zookeeper essentially identifies a connection from a Client to a Server. Sessions have a timeout; if the Client does not send a request or heartbeat for a long time (longer than the timeout interval), the Server will delete the session.
Summary
Zookeeper uses a directory tree to organize data, the Zab protocol to synchronize data, and a non-blocking approach to provide interfaces, building a distributed coordination kernel with powerful expressiveness. It can be used in the control plane of distributed systems for coordination, scheduling, and control. In recent years, Etcd based on Raft holds a similar position.

