之前文章写了 Ray 的论文翻译。后来我花了些时间读了读 Ray 的源码,为了学习和记忆,后续预计会出一系列的源码解析文章。为了做到能持续更新,尽量将模块拆碎些,以保持较短篇幅。另外,阅历所限,源码理解不免有偏颇指出,欢迎大家一块讨论。
之前文章写了 Ray 的论文翻译。后来我花了些时间读了读 Ray 的源码,为了学习和记忆,后续预计会出一系列的源码解析文章。为了做到能持续更新,尽量将模块拆碎些,以保持较短篇幅。另外,阅历所限,源码理解不免有偏颇指出,欢迎大家一块讨论。
GFS 是谷歌为其业务定制开发的,支持弹性伸缩,为海量数据而生的分布式大文件存储系统。它运行于通用廉价商用服务器集群上,具有自动容错功能,支持大量客户端的并发访问。
GFS 是为大文件而生的,针对读多于写的场景。虽然支持对文件修改,但只对追加做了优化。同时不支持 POSIX 语义,但是实现了类似的文件操作的API。它是谷歌在 MapReduce 同时期,为了解决大规模索引等数据存储所实现的具有开创性的工业级的大规模存储系统。
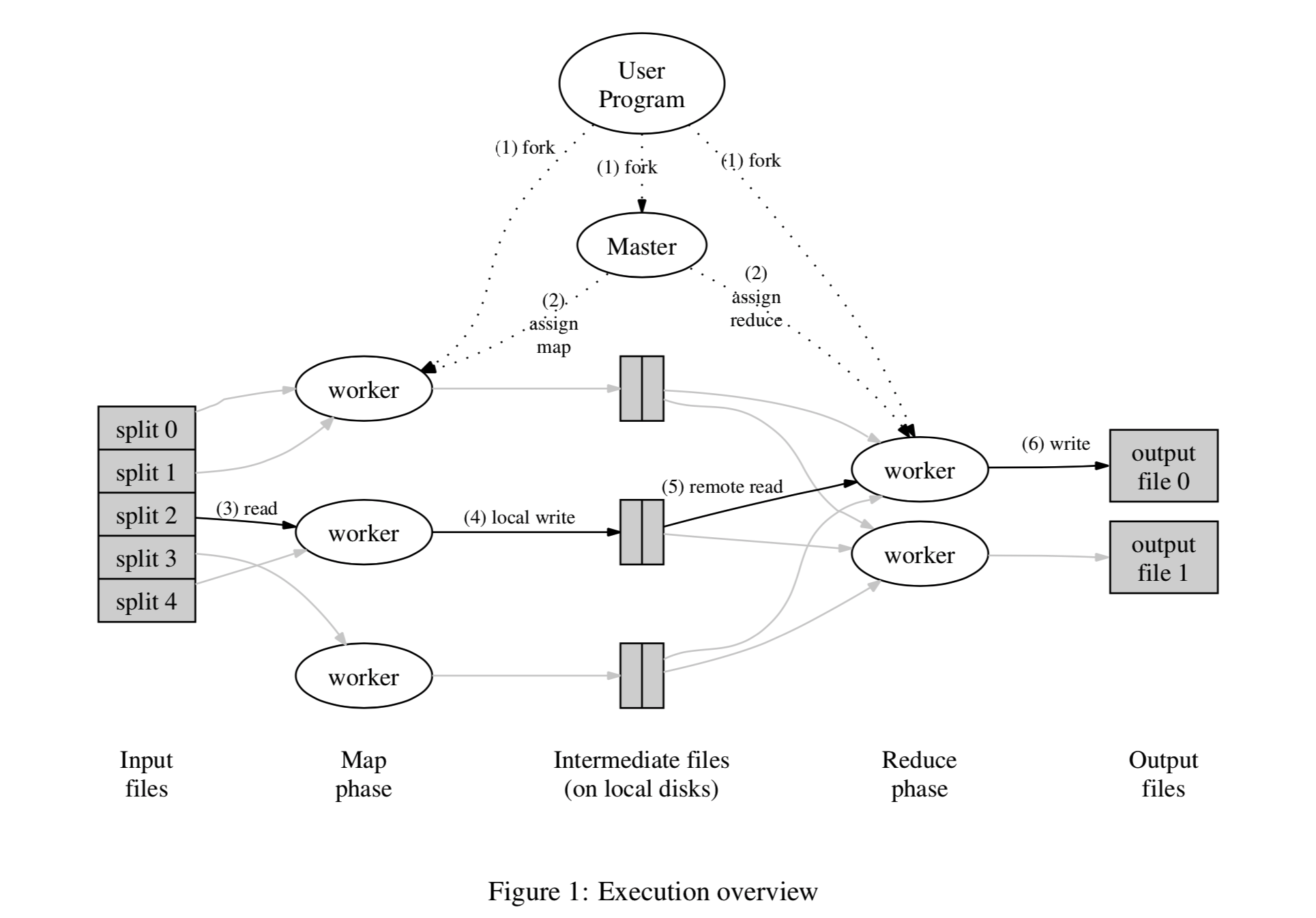
MapReduce 是谷歌 2004 年(Google 内部是从03年写出第一个版本)发表的论文里提出的一个概念。虽然已经过去15 年了,但现在回顾这个大数据时代始祖级别概念的背景、原理和实现,仍能获得对分布式系统的很多直觉性的启发,所谓温故而知新。
在Google 的语境里,MapReduce 既是一种编程模型,也是支持该模型的一种分布式系统实现。它的提出,让没有分布式系统背景的开发者,也能较轻松的利用大规模集群以高吞吐量的方式来处理海量数据。其解决问题思路很值得借鉴:找到需求的痛点(如海量索引如何维护,更新和排名),对处理关键流程进行高阶抽象(分片Map,按需Reduce),以进行高效的系统实现(所谓量体裁衣)。这其中,如何找到一个合适的计算抽象,是最难的部分,既要对需求有直觉般的了解,又要具有极高的计算机科学素养。当然,并且可能更为接近现实的是,该抽象是在根据需求不断试错后进化出的海水之上的冰山一角。
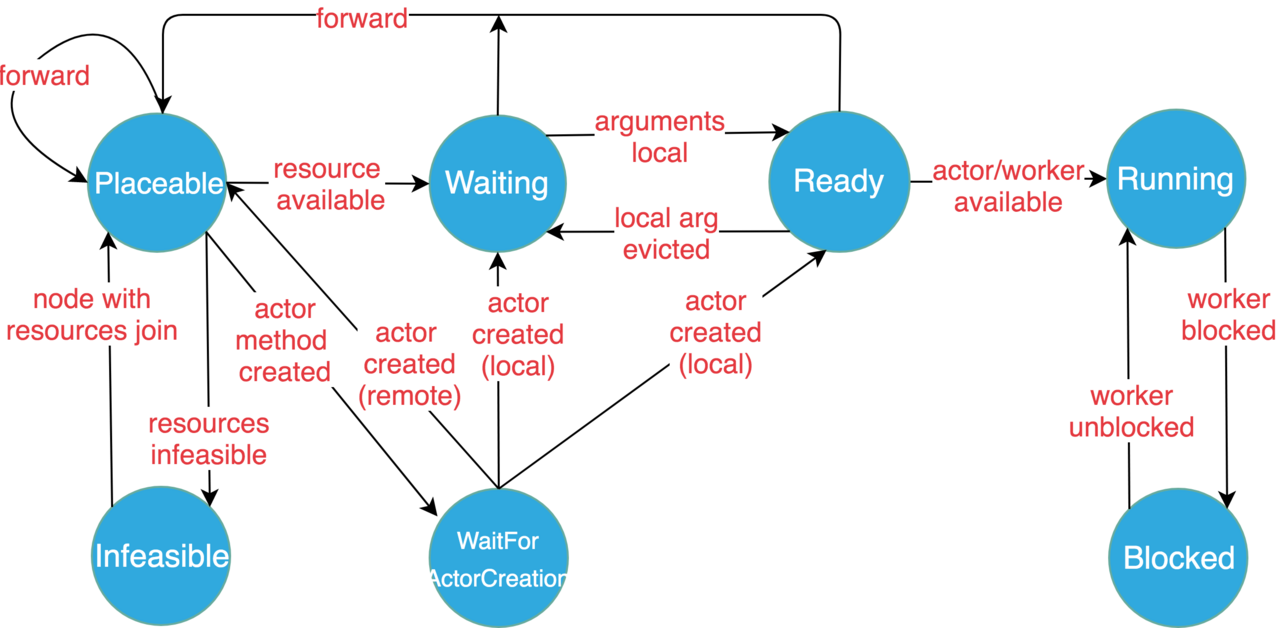
继 Spark 之后,UC Berkeley AMP 实验室又推出一重磅高性能AI计算引擎——Ray,号称支持每秒数百万次任务调度。那么它是怎么做到的呢?在试用之后,简单总结一下:
ray.remote 的装饰器并做一些微小改变,就能将单机代码变为分布式代码。这意味着不仅可以远程执行纯函数,还可以远程注册一个类(Actor模型),在其中维护大量context(成员变量),并远程调用其成员方法来改变这些上下文。当然,还有一些需要优化的地方,比如 Job 级别的封装(以进行多租户资源配给),待优化的垃圾回收算法(针对对象存储,现在只是粗暴的 LRU),多语言支持(最近支持了Java,但不知道好不好用)等等。但是瑕不掩瑜,其架构设计和实现思路还是有很多可以借鉴的地方。

栽在 Python 的默认参数的“坑”中几次之后打算专门弄一篇博客来说一下这个事情。但是最近看到一篇很好地英文文章(Default Parameter Values in Python,Fredrik Lundh | July 17, 2008 | based on a comp.lang.python post),鞭辟入里。珠玉在前,就不舞文弄墨了。当然,也算是偷个懒,在这里简单翻译一下,希望更多的人能看到。
以下是翻译,意译,加了一些私货,不严格跟原文保持一致,语法特性以 Python3 为准。
首先说下 BLOB 的意思, 英文全称是 Binary Large OBjects,可以理解为任意二进制格式的大对象;在 Facebook 的语境下,也就是用户在账户里上传的的图片,视频以及文档等数据,这些数据具有一次创建,多次读取,不会修改,偶尔删除 的特点。
之前简单翻译了 Facebook 的前驱之作 —— Haystack,随着业务量发展,数据量进一步增大,过去玩法又不转了,如果所有 BLOG 都用 Haystack 存,由于其三备份的实现,在这个量级下,性价比很低。但是完全用网络挂载+传统磁盘+Unix-like(POSIX)文件系统等冷存储,读取跟不上。于是计算机科学中最常用的分而治之的思想登场了。
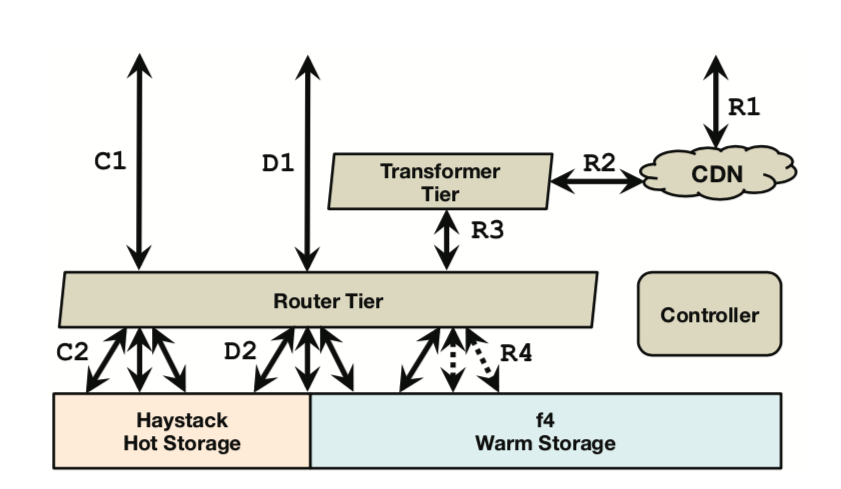
他们首先统计了 BLOBs 的访问频次与创建时间的关系,然后提出了随着时间推移 BLOB 访问出现的冷热分布概念(和长尾效应差不多)。并据此提出了热、温分开的访问策略:用 HayStack 当做热存储去应对那些频繁访问的流量,然后用 F4 去响应剩下的不那么频繁访问的 BLOB流量,在此假设(F4只存储那些基本不怎么变动,访问量相对不大的数据)前提下,可以大大简化 F4 的设计。当然有个专门的路由层于两者之上进行了屏蔽,并进行决策和路由。
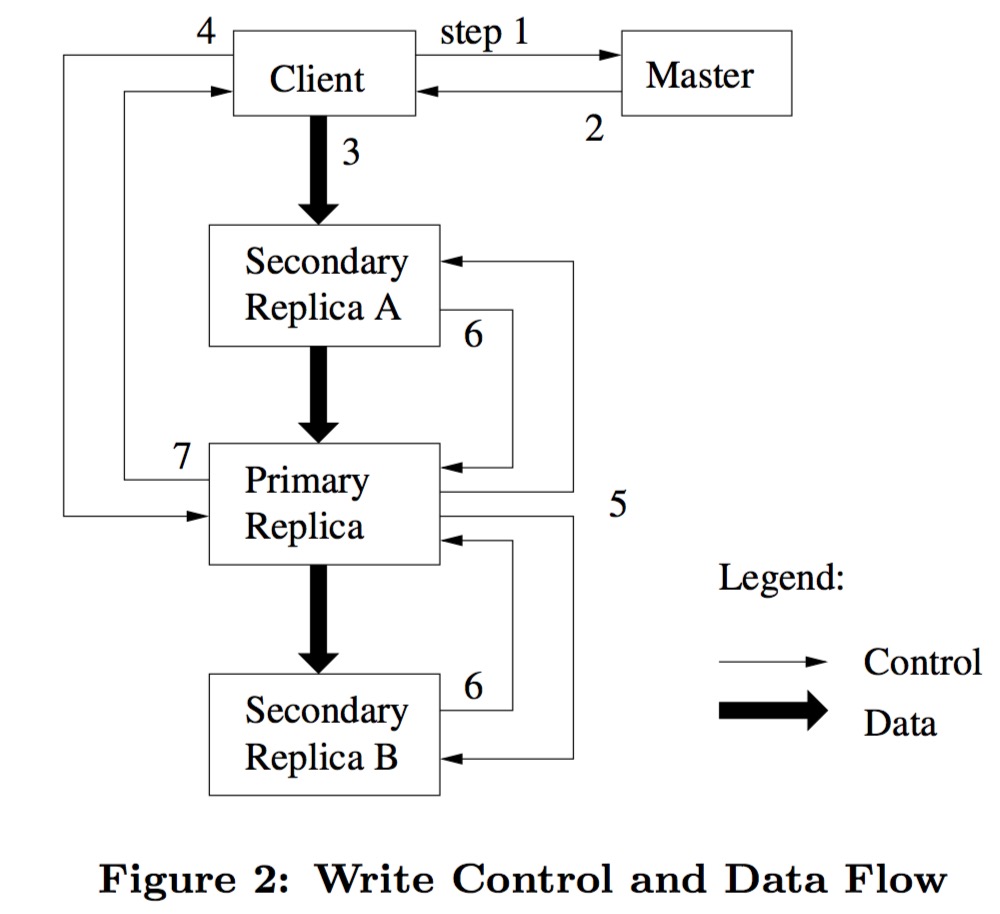
对于 Haystack 来说,从其论文出来时,已经过去了七年(07~14)。相对于当时,做了少许更新,比如说去掉了 Flag 位,在 data file,Index file 之外,增加了 journal file,专门用来记录被删除的 BLOB 条目。
对于 F4 来说,主要设计目的在于保证容错的前提下尽可能的减小有效冗余倍数(effective-replication-factor),以应对日益增长的温数据 存取需求。此外更加模块化,可扩展性更好,即能以加机器方式平滑扩展应对数据的不断增长。
我总结一下,本论文主要高光点就是温热分开,冗余编码,异地取或。
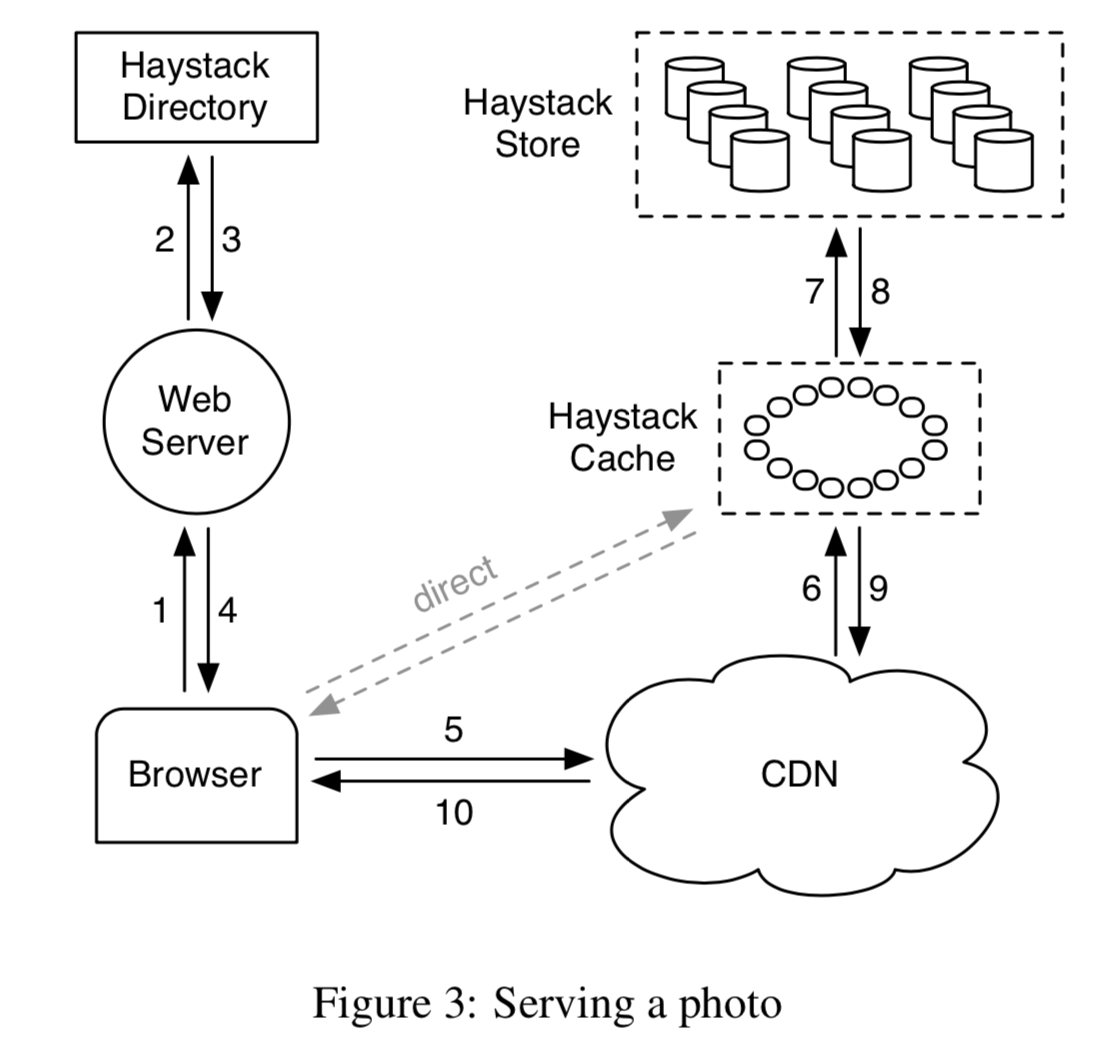
Haystack 的基本思想就是将索引信息放在内存中,避免额外的IO。为了做到这一点,主要进行了两方面的设计:
这样就可以将数据元信息减小到一个内存可以放的下的量级,基本上每次每次数据访问同一个一次 IO 就可以完成,而非以前的好几次。

某次在用到 Python 的 socketserver 时,看到了 ForkingMixIn 和 ThreadingMixIn。当时就对这种插件式语法糖感觉很神奇。最近自己写代码,也想写一些这种即插即用的插件代码,于是对 python 的 mix-in 机制探究了一番。
简单来说它是利用多继承的特性,通过插拔额外代码片段,对原类进行花样式增强的一种技术。
以前学 js 的时候第一次见到闭包,当时不甚了了,还为了应付面试强行记住了一个模棱两可的“定义”:在函数中嵌套定义函数,并且在外层将内层函数返回,一同返回了外层函数的环境。当时从字面意思以及当时一个经典例子试图去理解闭包,加之"闭包"这个翻译也很不容易让人味出其中的道理,导致对其总感觉懵懵懂懂。最近工作需要,用起 python,又遇到闭包,这次看到了一些新奇有趣的资料,这才算大致把一些字面上的概念(first-class functions,bind,scope等等)贯通在一起,反过来对闭包有了更深的理解。
引用资料列在最后,十分推荐大家去读读。
今年新年愿望之一,督促自己每周写博客。作为一个新的开始,打扫屋子清爽一番是我的一贯风格。加上感觉jeklly 引擎不怎么好使,就想换个新的引擎 hexo。去年注意到越来越多的博客开始用这个引擎,于是关注了下,感觉的确不错(主题,模式等等),说干就干。想着作为科班出身,看别人教程多low,于是直接看官方文档开搞,当然了,坑是不可避免的,下面来聊一下。
上一次在做完 lab2a 即 raft 的 leader 选举之后,一直卡在日志同步这一块(log replication);直到昨晚进行了一下 appendEntries 的优化(prevLog 不匹配时,一下跳过本 term 所有 logEntries),一直困扰的 TestBackup2B 竟然神奇 Passed 的了。跑了两遍还不大信,特地将其改回去,看到果然 Fail 才放心下来,看来是效率太低超时了。
趁着还新鲜,索性今晚就将这一段时间的血泪史记下来吧。