Overview
Kafka (the paper was published in June 2011 [1]) is a system that combines the best of log processing and message queuing. With low latency, extremely high capacity, and throughput, it can be applied to both online services and offline business. To balance performance and scalability, Kafka made some design choices that seem counter-intuitive but are very practical in practice. Here is a routine summary of its design characteristics:
-
Storage-oriented message queue: This means that, in near real-time scenarios, it can increase the storage capacity of traditional message queues by several orders of magnitude. The implementation makes full use of sequential disk writes and the OS’s own cache; furthermore, to improve disk access and transmission efficiency, it employs techniques such as file segmentation, segment-level indexes, zero-copy, and batch fetching.
-
Flexible production and consumption patterns: Overall, it is a topic-based publish-subscribe architecture that supports both mutually exclusive consumption within a consumer group and duplicate consumption across different consumer groups. This involves two core design choices of message queues: pull-based consumption and client-side storage of consumption progress. Pull-based consumption may cause empty polling and slight latency, but the benefit is flexibility; client-side storage of consumption progress allows brokers to be stateless, enabling flexible scaling and fault tolerance. To simplify the implementation, each partition is consumed by at most one consumer at a time.
-
Zookeeper for metadata storage: Using the distributed consistency component Zookeeper to store system metadata in a registry format, including broker and consumer liveness, consumer-to-partition mapping, consumption progress for each partition, etc. Zookeeper, as a highly available component that organizes KV pairs in a prefix-tree form and supports publish-subscribe, can meet Kafka’s collaborative needs for consumption coordination and progress persistence.
-
Partition-level multi-replica design: This was not yet implemented in the paper; it was likely added later during the open-source evolution of the system. This feature enables fault tolerance for brokers.
-
Simple yet powerful consumer API: Kafka clients generally provide two layers of API abstraction. One is a high-level simple read/write interface that does not require attention to partition and offset information; the other is a low-level interface that allows flexible control over partition assignment and consumption progress. The paper only mentions the former to demonstrate its simplicity.
Author: Woodpecker’s Notes https://www.qtmuniao.com, please indicate the source when reposting
Introduction
Any internet company generates a large amount of “log” data, which mainly includes:
- User behavior events. Such as login, browsing, clicking, liking, sharing, commenting, etc. on social networking sites.
- System operations data. Such as the call stack of a service, call latency, error reports, and some machine runtime metrics: CPU, network, or disk usage.
For a long time, this data was only used for backend analysis or system bottleneck diagnosis. But a current trend is that this data is increasingly being used for online business, including:
- Search relevance analysis
- Data-driven recommendations
- Precise ad targeting
- Service blacklist filtering
- User homepage feed streams
And so on, too many to list. This behavioral data is usually several orders of magnitude larger than the user metadata itself, so the demand for real-time analysis poses new challenges to data systems. For example, search, recommendation, and advertising all require fine-grained click-through rate data, which requires not only counting all user click events but also counting data for pages that were not clicked.
Some early systems directly scraped system logs from the online environment to perform analysis for similar requirements. However, recently many companies have built specialized systems for this. For example, Facebook’s Scribe, Yahoo’s Data Highway, and Cloudera’s Flume. The goal of these systems is to collect log data and import it into data warehouses like Hadoop for offline processing. However, at LinkedIn, in addition to offline analysis requirements, we also have many of the aforementioned real-time processing requirements with latency of no more than a few seconds.
We built a brand-new messaging system for log processing, named Kafka. Kafka accommodates both log aggregation requirements and message queuing requirements. On the one hand, Kafka is a distributed system that supports smooth scaling and high throughput; on the other hand, Kafka provides an API similar to message queues and allows applications to consume log messages in real time. At the time the paper was published, Kafka had been online at LinkedIn for more than six months, satisfying both major aspects of our needs with a single system, thereby greatly simplifying our infrastructure.
Next, the paper will revisit the traditional forms of messaging systems and logging aggregators in Section 2. In Section 3, we first introduce the basic architecture of Kafka, and then discuss its fundamental design principles. Then in Section 4, we will look at Kafka’s deployment and performance metrics at LinkedIn.
Related Systems
Traditional enterprise messaging systems (such as ActiveMQ, IBM WebSphere MQ, Oracle Enterprise Messaging Service, TIBCO Enterprise Message Service) have existed for a long time, mainly serving as message bus and asynchronous decoupling. However, they cannot seamlessly adapt to log processing requirements for the following reasons:
- Different semantic focus
Traditional message queues focus on providing flexible message delivery guarantees, such as transactions across multiple queues, ACK confirmation of message delivery, strict message ordering, etc. These features are not in such high demand in log processing systems, but they greatly increase API complexity and system implementation difficulty.
- Poor support for high throughput
Most traditional message queues do not take high throughput as their primary design goal. For example, JMS does not even have a batch interface, so every message sent uses a new TCP connection, which obviously cannot meet the high throughput requirements of our logging system.
- No support for distributed storage
These traditional messaging systems are usually not easy to partition (shard) to store on multiple machines. Therefore, when data volume is large, they cannot support smooth capacity expansion.
- Designed for real-time rather than accumulation
Another characteristic of these messaging systems is the assumption that consumption is near-immediate, so the volume of un-consumed messages is always small. Once messages accumulate, the performance of these small message systems drops significantly. Therefore, they struggle to support offline consumption and large-batch consumption tasks. In short, the design philosophy of traditional messaging systems is not oriented toward storage.
In recent years, some dedicated log aggregation systems have also emerged.
Such as Facebook’s Scribe. System-generated logs are written to remote Scribe machines via sockets; each Scribe machine periodically dumps the collected logs to HDFS or NFS clusters.
Another example is Yahoo, whose Data Highway also follows a similar data flow pattern. A group of machines aggregates logs collected from clients into files by the minute, and then writes them to HDFS.
Another example is Cloudera, which built a relatively novel log aggregation system: Flume. Flume provides extended semantics of pipes and sinks, allowing users to flexibly consume log streams. In addition, the system introduces more distributed features.
However, most of these systems are designed for offline consumption and expose too many unnecessary implementation details (i.e., they are not well abstracted and not flexible enough; for example, Yahoo even exposes things like minutes file). Furthermore, these systems basically adopt a “push” (push) model, where the broker pushes messages to consumers.
At LinkedIn, research found that the “pull” (pull) model is more suitable for our business scenarios. In this model, each consumer can decide its own consumption speed according to its preference, without worrying about being overwhelmed by fast consumers or dragged down by slow consumers [2]. The “pull” model also makes it easy to implement consumption rewind (rewind), which we will discuss in detail later.
Recently, Yahoo Research developed a distributed system called HedWig that supports publish/subscribe; it is easy to scale, highly available, and supports message persistence. However, the system functions more as a log storage system.
Kafka Architecture and Design Principles
Concepts
Due to the many limitations of the above systems, we developed a message-based log aggregation system — Kafka. First, let us introduce some Kafka concepts. A topic (topic) defines the type of a certain message (message) stream; a producer (producer) publishes messages to a topic, and these published messages are temporarily stored on a set of servers called brokers (broker). A consumer (consumer) can subscribe to one or more topics from the brokers and consume them in a pull-based manner.
API Design
A messaging system should be simple. To express this simplicity, we designed Kafka’s interface (API) to be very minimal. To avoid dry descriptions of these APIs, we use two very simple examples to show what Kafka’s APIs look like.
1 | // Sample producer code: |
As shown in the code, the format of a message is very simple: just a byte array. Users can serialize data according to their preferences (i.e., encoding an object instance into a byte array). To improve efficiency, a set of messages can be sent at once.
1 | // Sample consumer code: |
Consumers subscribe to a topic by creating one or more streams; messages published to the corresponding topic will gradually enter these streams created by the consumer. The API is that simple. As for how Kafka implements it, we’ll keep you in suspense and discuss it later. At the language level, we abstract each message stream as an Iterator; the consumer uses this iterator to retrieve the payload of each message for processing. Unlike ordinary iterators, our iterator never stops; when no new messages arrive, the iterator will block forever. We support two consumption modes: a group of consumers can perform mutually exclusive consumption of a topic, or each consumer can perform independent consumption of the same topic.
Architecture Diagram
The Kafka architecture diagram is as follows:
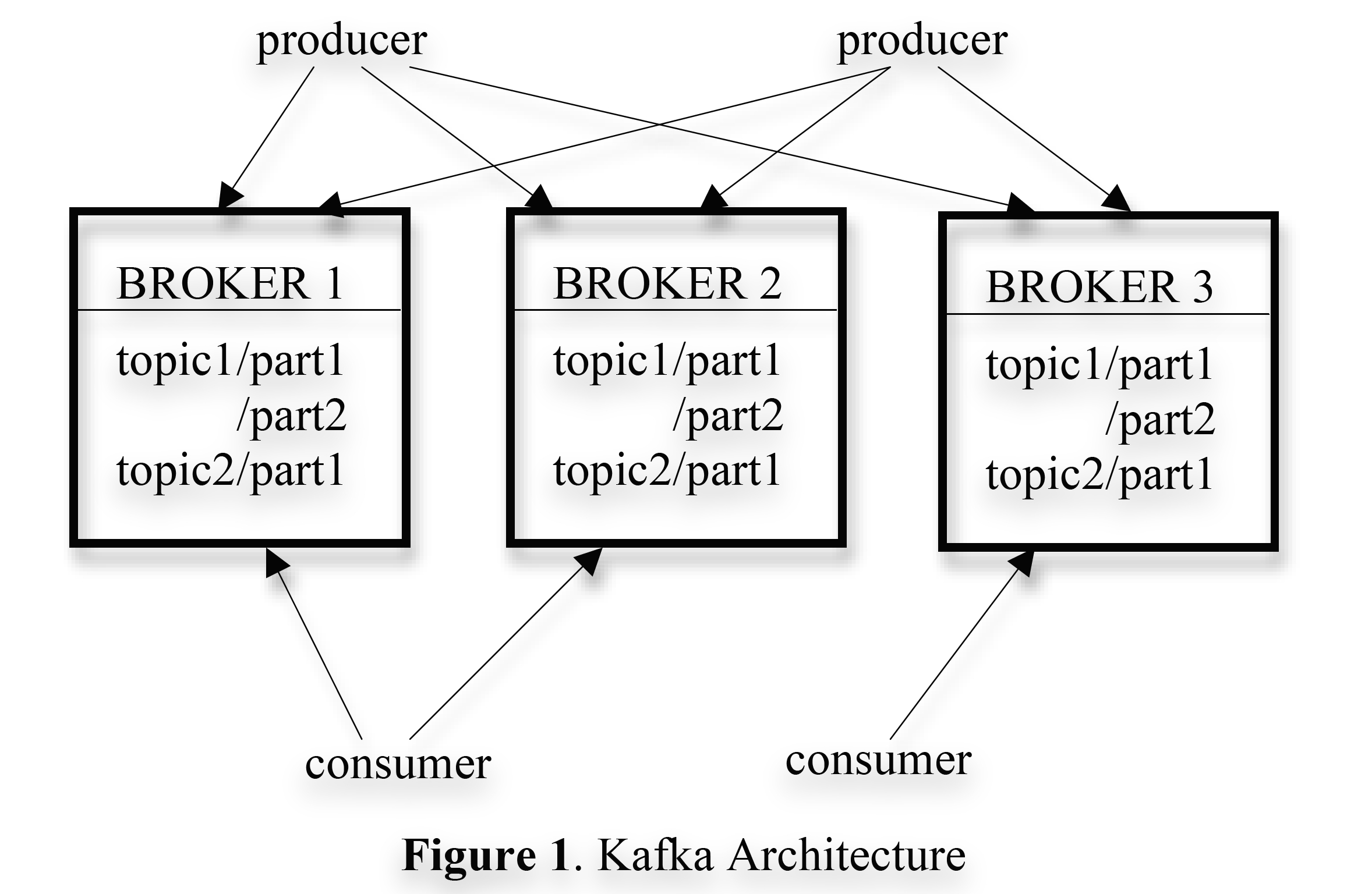 kafka-architecture.png
kafka-architecture.png
Kafka is a distributed system, so a Kafka cluster contains multiple broker machines. To balance the load, each topic is divided into multiple partitions, and each broker machine holds one or more partitions. Multiple producers and consumers can produce and consume messages simultaneously. In Section 3.1, we will introduce the layout of a single partition on a broker and discuss some design tradeoffs and choices to make a single partition efficiently consumable. In Section 3.2, we will describe how producers and consumers interact with multiple brokers in a distributed environment. Finally, in Section 3.3, we will discuss Kafka’s data delivery guarantees.
Efficiency of a Single Partition
We made a series of design decisions to ensure system efficiency.
Minimalist storage design. Each partition of a topic is logically a segment of a log. Physically, to prevent partition files from becoming too large, we further divide them into data segments. Data is always written to the newest segment; after reaching a set capacity (e.g., 1 GB), a new segment file is created to continue writing. Furthermore, to improve write performance, we cache log records in memory and only flush data to external storage when the number of logs reaches a set value or the cached data size reaches a set value. To ensure reliability, data is only exposed to consumers after being flushed to external storage.
Unlike traditional messaging systems, Kafka does not use an explicit message ID for each stored message; instead, messages are located solely by their offset within the partition. This saves us the extra overhead of building an index for random lookups. It is worth noting that our offsets are not continuous; rather, they are byte offsets similar to TCP’s SEQ — to calculate the offset of the next message, we need to add the length of the current message to its offset. Below, ID and offset may be used interchangeably, but they refer to the same thing.
Each consumer always consumes data from each partition sequentially. If a consumer acknowledges (acks) an offset, it means all messages before that offset have been consumed. In terms of implementation, the consumer-side library code sends a series of requests to the broker to pull data into the consumer’s buffer for the application code to consume [3]. Each pull request contains a starting offset and an acceptable byte size. Each broker maintains in memory a mapping from segment-start offsets to the physical addresses of segments (likely organized using a search tree, as range lookups are needed). When a read request arrives, the broker locates the corresponding segment based on the requested offset, reads the specified amount of data based on the requested size, and returns it to the consumer. After receiving the messages, the consumer calculates the offset of the next message to issue the next pull request. The layout of logs on disk and indexes in memory in Kafka is shown in the figure below (the data in each box represents the offset of a certain message):
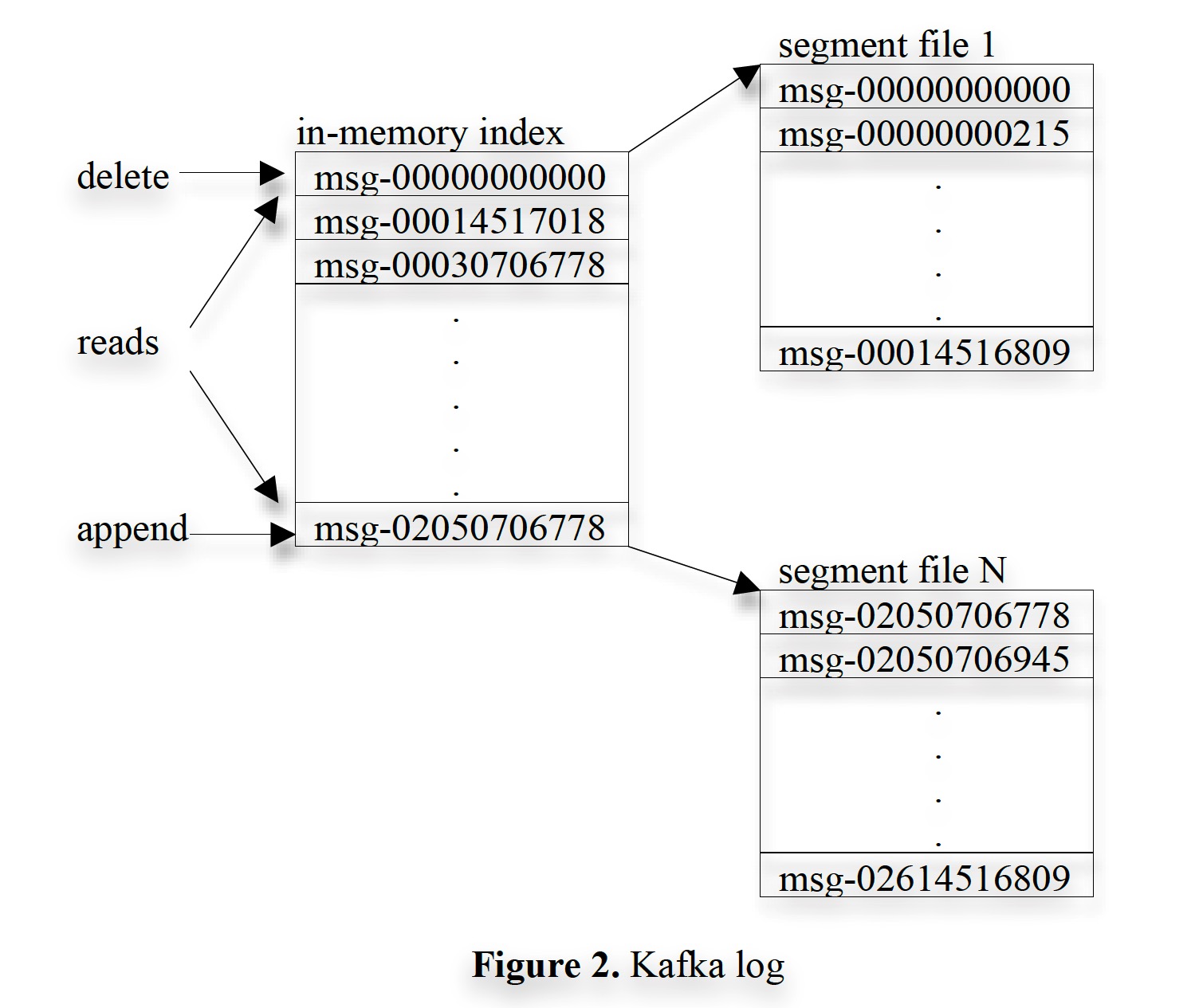 kafka-log.jpg
kafka-log.jpg
Efficient transmission optimization. Since network transmission overhead can be high, we carefully designed the data exchange flow between Kafka and the outside world. As mentioned earlier, for producers, our API allows sending a batch of messages at once. For consumers, although the API appears to consume messages one by one, the underlying layer also fetches in batches, such as pulling hundreds of KB at a time.
Another unconventional design decision is that we do not perform explicit message caching at the Kafka system level. That is, we only utilize the file system-level page cache to accelerate disk reads and writes. This has two benefits:
- Avoid multiple caching of messages
- Cache is not lost after a broker process restart
Because we do not cache at the Kafka level, garbage collection strategies at the memory level can be kept very simple. Therefore, it simplifies the difficulty of implementing the system using programming languages with their own VM.
In the scenarios Kafka targets, producers and consumers both access segment files sequentially, and consumers usually only slightly lag behind producers. The OS’s default heuristic caching strategies such as write-through and read-ahead naturally fit this scenario. We found that both producer and consumer read/write rates scale linearly with data size, up to several TB (the paper does not discuss beyond that).
Furthermore, we optimized the remote data access process for consumers. Because Kafka is a system that supports multiple subscriptions, a single message may be consumed by different consumers multiple times, so optimizing remote data access can greatly improve system performance. Traditionally, sending a piece of data from a local file to a socket usually involves the following steps:
- Read data from external storage into the OS page cache.
- Copy data from the page cache to the application buffer.
- Copy data from the application buffer to the kernel buffer.
- Copy data from the kernel buffer to the socket.
These steps involve four data copies and two system calls, which can be said to be very redundant and wasteful. In Linux and some other operating systems, there is a sendfile (zero copy) API that can directly transfer data from a file to a socket. Using this API, we can eliminate the two data copies and one system call introduced in steps (2) and (3), thereby allowing Kafka to efficiently transfer data from the broker’s segment files to consumers.
Stateless Broker. Unlike other message queues, in Kafka, the broker is not responsible for saving each consumer’s consumption progress. That is, each consumer needs to save its own consumption offset and other information itself, so that the broker’s design can be relatively simplified without maintaining too much state. However, because the broker does not know the consumption progress of all subscribers, it is difficult to decide when to delete a message. Kafka uses a seemingly tricky strategy — saving messages according to a time window. For example, only keeping the most recent seven days of data. Of course, each topic can be configured with different policies. This simple strategy is sufficient in most cases; even offline consumers usually consume daily, hourly, or near real-time, and seven days is enough. The fact that Kafka does not significantly degrade performance as data volume increases is the key guarantee that allows Kafka to use such a simple strategy.
Another important benefit brought by this large-storage-plus-pull design is that consumers can actively choose to rewind and re-consume. This requirement seems to violate the usual definition of a message queue, but it is very necessary in many cases. Here are two casual examples:
- When a consumer process crashes due to an error, it can selectively re-consume data from before and after the crash upon recovery. This is very important for scenarios such as ETL data import into Hadoop and other data warehouses.
- Consumers periodically flush the fetched data to persistent storage (such as in an inverted index system). If a consumer goes down, the portion of data that has already been fetched from the messaging system but not yet persisted will be lost. But for Kafka, consumers only need to remember the offset flushed to; after the next restart, they can pull from that offset onward. However, for traditional message queues without large caches, this data may be lost forever, or some complex error backup and recovery strategy must be implemented on the consumer side.
Distributed Coordination
Now let us discuss the behavior of multiple producers and consumers in a distributed environment. For producers, when sending data, they can randomly send to a broker hosting a partition; or, based on a Key and a routing function acting on the Key, they can send to a specific partition broker. For consumers, the behavior is slightly more complex and will be explained in detail next.
Kafka has a concept called consumer groups. A consumer group contains multiple consumers, and these consumers will mutually exclusively consume a set of topics; that is, for a single message, it will only be consumed by one consumer in the same group. Different consumer groups consume independently; each consumer group maintains its own consumption progress and does not need to coordinate with others. Each consumer within a consumer group can belong to different processes or even different machines. Our goal is to distribute messages evenly to each consumer without introducing too much extra overhead.
The first decision is to make each partition the smallest unit of parallelism. That is, each partition is consumed by at most one consumer; if we allowed multiple consumers to consume the same partition, it would inevitably introduce coordination mechanisms such as locks and require recording some state to track each consumer’s consumption status, which would increase implementation difficulty. In our design, coordination is only needed when the number of consumers changes and traffic needs to be rebalanced. To make each consumer’s traffic more balanced, it is recommended to make the number of partitions much larger than the number of consumers, which is easy to achieve by simply configuring more partitions for the topic.
The second decision is to not introduce a central master node, and instead let all consumers coordinate in a decentralized manner. If a central node were used, we would also have to worry about its fault tolerance, introducing unnecessary complexity. To allow consumers to coordinate better, we introduced a highly available consistency service — Zookeeper. Zookeeper’s API is very similar to a file system, organizing KV pairs in a prefix-tree form (K is a path, with ‘/’ delimiting levels, and V can be any serializable value). This API supports creating a path, setting a value for a path, reading a path’s value, deleting a path, and listing all child node values under a path. In addition, Zookeeper has the following characteristics:
- Clients can register a callback function on a path to listen for changes to that path’s value or its child nodes.
- Paths can be created as ephemeral, meaning that when all clients of that path disappear, the path and its value are automatically removed.
- Zookeeper uses a consensus protocol to replicate its data across multiple machines, making the service highly reliable and highly available.
Kafka uses Zookeeper for the following purposes:
- Monitor the addition and removal of brokers and consumers.
- Initiate rebalancing tasks when brokers or consumers are added or removed.
- Maintain inter-consumer relationship states and track the consumption offset for each partition.
Specifically, when a broker or consumer starts up, it stores metadata in a registry in Zookeeper.
- The broker registry includes the broker’s hostname and port number, as well as the topics and partitions stored on it.
- The consumer registry includes the consumer group it belongs to and the topics it subscribes to.
Each consumer group has an associated ownership registry and offset registry in Zookeeper.
- We refer to a consumer consuming a partition as owning it; the ownership registry records the mapping between consumers and the partitions they own. The path name identifies a partition, and the recorded value is the owner of that partition.
- The offset registry records the consumption progress (i.e., offset) of each partition for all topics subscribed to by that consumer group.
The broker registry, consumer registry, and ownership registry in Zookeeper are ephemeral, while the offset registry is persistent. When a broker dies, all its partitions are automatically removed from the broker registry. When a consumer dies, its entry in the consumer registry is removed, and the partition ownership entries in the ownership registry are also removed. Each consumer monitors the broker registry and the consumer registry; when there is a broker change or a member change in the consumer group, it receives a notification.
When a consumer joins or a member changes in the consumer group, that consumer initiates a rebalancing process to decide which set of partitions it should consume. The pseudocode is as follows:
1 | Algorithm 1: rebalance process for consumer Ci in group G |
The algorithm is as above. Simply put, the consumer retrieves all topics from Zookeeper. For each topic, it gets the partition set Pt and the consumer set Ct of the consumer group it belongs to. Then it tries to divide the partition set into |Ct| equal parts as evenly as possible, and the consumer picks one of these parts according to a deterministic algorithm, such as sorting Ct and Pt in a specific way. After that, each consumer starts a thread for each of its own partitions to pull data, beginning consumption from the offset stored in the offset registry. As data in the partition is continuously consumed, the consumer constantly updates the offset in the registry.
When a consumer or broker changes, all consumers in the same consumer group receive a notification; due to network reasons, the time at which each consumer receives the notification may differ. When a consumer that receives the notification first runs the above algorithm to fetch data from new partitions, it may find that the partition is still owned by another consumer. For this situation, we adopt a very simple strategy: the consumer releases the partitions it owns, waits a short while, and then retries. In actual operation, the rebalancing program usually stabilizes after a few retries.
When a new consumer group is created, there is no offset record in the registry. At this time, using the API provided by the broker, the consumer group can choose to consume from the smallest offset or the largest offset for each partition (depending on the consumer group’s configuration).
Delivery Guarantees
In principle, Kafka only provides “at-least-once” (at-least-once) [4] delivery semantics. Exactly-once delivery semantics can be guaranteed by two-phase commit, but this is not necessary in our application scenarios. In fact, most of the time, in a general data center with good network conditions, most messages are consumed exactly once by the consumer group; only when a consumer process exits abnormally without performing normal cleanup (for example, not updating the last consumed offset to Zookeeper) will the new consumer, upon startup, re-consume the portion of data whose offset was not committed. If the application cannot tolerate this situation, it must add message deduplication logic in the application logic — for example, using a dictionary to store the IDs of recently consumed data for deduplication. This ID can be the offset of the message in Kafka, or a user-defined key that has a one-to-one correspondence with the message. This method performs better than using two-phase commit at the Kafka level to guarantee exactly-once semantics.
Kafka guarantees that messages from the same partition are ordered, i.e., in offset size order, but ordering between different partitions is not guaranteed. To avoid data errors, Kafka saves a CRC checksum in each message. When a broker encounters IO issues, during recovery, it can delete messages with inconsistent CRC checksums. Since the CRC is stored in the message, both the production and consumption stages can check the CRC to avoid errors caused by network transmission.
When a broker goes down, all messages on it become unavailable. Furthermore, if the broker’s storage system is completely destroyed, the un-consumed messages on it will be lost forever. In the future, we plan to provide built-in multi-machine redundant backup to tolerate occasional failures of individual broker nodes (of course, this was already implemented by 2019).
Kafka Usage at LinkedIn
In this section, we briefly explain how Kafka is used at LinkedIn. The figure below is a simplified deployment diagram:
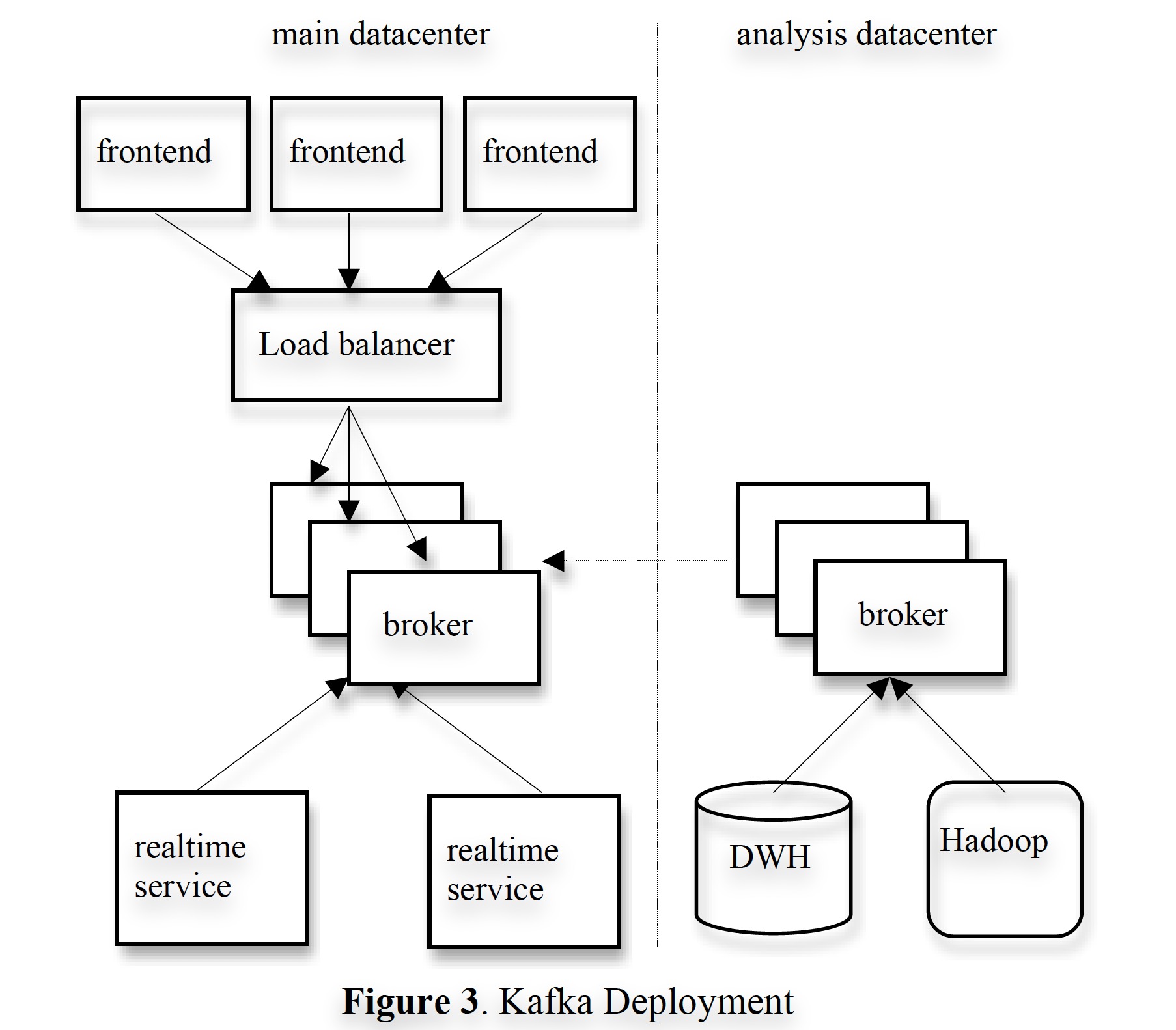 kafka-deployment.jpg
kafka-deployment.jpg
We deployed a Kafka cluster serving user business in each data center; front-end business sends various log data in batches to the Kafka cluster. We use hardware (load balancers) to distribute traffic as evenly as possible to each broker. To reduce network overhead, we deploy online consumer services and Kafka in the same physical cluster.
We also deployed a Kafka cluster responsible for offline data analysis in another data center close to Hadoop clusters and other data warehouse infrastructure. On the one hand, this Kafka cluster has a built-in set of consumer processes that periodically pull data from the online Kafka cluster and write it into the local cluster. On the other hand, the cluster runs data loading jobs that periodically pull data from the Kafka cluster, process it, and load it into the Hadoop cluster and data warehouse for aggregation and analysis. We also use this cluster for prototype modeling and some ad-hoc query analysis work. Without special tuning, the end-to-end average latency is about 10 seconds, which is sufficient for our needs.
Currently, our Kafka clusters generate hundreds of millions of log messages per day, with a total volume of around hundreds of gigabytes. Once we fully migrate existing systems to Kafka, it is foreseeable that the data volume in Kafka will see more significant growth and will need to adapt to more data types. When operators take brokers offline due to hardware or software reasons, the rebalancing process can automatically rebalance consumption across multiple brokers.
We also have an audit system to check whether there is any data loss in the entire pipeline. Specifically, for each message, a timestamp and producer hostname tag are attached at production time; metadata about data production, i.e., the number of messages produced within a specific time window, is periodically submitted to another topic used for monitoring. Thus, consumers can use the additional information in each message to count the number of messages received for a topic within a specific time window and compare it with monitoring messages read from the monitoring topic to determine whether consumption is correct.
We customized a Kafka input format for Hadoop [5], allowing MapReduce jobs to use Kafka as a data source. MapReduce tasks read raw data from Kafka, classify and aggregate it, and compress it appropriately for efficient processing in the future. MapReduce tasks require idempotent consumption of Kafka; the statelessness of Kafka brokers and the feature of letting the consumer side [6] store offsets allow us to continue consuming from the last consumption point when a Map task fails and restarts, thereby ensuring no duplication or omission of message consumption. When the task completes, both the data and the offsets are stored on HDFS.
We use Avro as the serialization framework [7]; it is efficient and supports type inference. For each message, we send the schema identifier corresponding to the message data type and the serialized bytes together as the Kafka message payload. This pattern allows us to flexibly use multiple message types for the same message topic. When consumers receive a message, they obtain the corresponding Avro actual encoding type based on the schema identifier to decode the actual data into a specific object instance. This conversion process is simple because for each object type, only one lookup is needed.
Translator’s Notes
[1] Kafka’s paper was published in 2011, so many of the current situations mentioned in the text were relative to that time; by now (end of 2019), the messaging queue landscape is certainly different again.
[2] The push model has this problem: if two consumers (say A is fast, B is slow) differ too much in consumption speed, the broker inevitably has to maintain the messages that A has finished consuming but B has not yet consumed. Since traditional message queues do not have very large caches (because they are usually stored in memory), they will quickly reach the upper limit; either the system will explode, or the fast consumer must be throttled. The problem with pull is that to ensure real-time performance, constant polling is required; the push-pull tradeoff is also a classic problem.
[3] This design is clearly inspired by TCP; it can be said that it implements ordering, acknowledgment, and sliding window buffer designs at the application layer.
[4] Generally speaking, during data delivery, due to unexpected system crashes, network jitter, and other issues, some data entries may be lost. If we do not intervene, the semantics provided are at-most-once. If we retry lost data entries, multiple deliveries may occur, because the sender cannot determine whether the receiver had a network problem after receiving the data or before receiving it. Blind retry may cause the same data to be processed multiple times; in this case, what we provide is at-least-once delivery semantics. If we want to forcibly implement exactly-once delivery semantics, it is possible, such as using two-phase commit and other consistency methods to guarantee the atomicity of data consumption and offset updates, thereby providing exactly-once consumption semantics. However, this can still go wrong and makes the system more complex and time-consuming. So generally, if you are not sensitive to losing a small amount of data, at-most-once is enough; if you are sensitive, you can use at-least-once and deduplicate at the application layer.
[5] Input format, or input format, is an interface in Hadoop MapReduce for adapting to different data sources, equivalent to a conversion layer.
[6] This can rely on Zookeeper, or rely on Hadoop to persist offsets; combined with the context, it seems the latter is meant here.
[7] This serialization method was likely a user-side choice rather than a feature provided by the Kafka framework at the time.

