 cap-consistency-example.png
cap-consistency-example.png
Introduction
I was once asked in an interview to explain my understanding of CAP. At the time, relying on second-hand information I had googled while preparing for the interview, I stammered out a few words like a schoolchild reciting a textbook. The interviewer smiled wryly and concisely summarized the key points he was looking for, leaving me feeling deeply embarrassed. Naturally, I didn’t get the job. Later, while working, I occasionally came across this term. At first I couldn’t grasp its essence, but after understanding and verifying it from different sources and perspectives, I gradually pieced together a clearer picture. Here, I’d like to organize my thoughts and put this shadow onto paper for future reference.
The interviewer roughly summarized it this way: In a distributed system, failures are inevitable, and partition tolerance (P) is absolutely necessary; therefore, when designing a system, you need to make a trade-off between availability (A) and consistency ©. At the time, the lesson left a deep impression on me. Looking back now, this summary merely points out the tip of the iceberg.
Author: 木鸟杂记 https://www.qtmuniao.com, please indicate the source when reposting
History
Eric Brewer (which is why the CAP theorem is also known as Brewer’s theorem) had the initial idea around 1998, then published it as a principle in 1999, and finally formally proposed it as a conjecture at PODC in 1999. In 2002, Seth Gilbert and Nancy Lynch from MIT provided a proof under very restrictive conditions, turning it into a theorem.
One point worth making here is that when people refer to the CAP principle (similar meaning, this is an off-the-cuff name I’m giving it), they may mean a broadly defined, widely applicable principle that inspires distributed systems design. But the CAP theorem belongs to the realm of theoretical computer science, where each property has a strict mathematical definition and the conclusions are rigorously derived. Most people intend to express the former but use the terminology of the latter. Martin Kleppmann, author of DDIA, even wrote a piece griping about this.
Concepts
The CAP principle states that a distributed storage system cannot simultaneously satisfy the following three properties:
- Consistency (Consistency): For requests to different nodes, the system either returns a response containing the latest modification or returns an error.
- Availability (Available): Every request receives a non-error response, but the timeliness of the response data is not guaranteed.
- Partition Tolerance (Partition tolerance): When a network partition occurs between nodes in the system, the system can still respond to requests normally.
Consistency
Distributed systems typically contain multiple data nodes (Data Server). There are three common methods for distributing a dataset (Dataset) across multiple nodes:
- Replication (Replication): Store an identical full copy of the dataset on multiple nodes; each copy is called a replica (Replica).
- Partitioning (Partition**): Split the dataset into several appropriately sized shards and store them on different nodes.
- Replication and Partitioning: Split the dataset into multiple shards, each of which is replicated multiple times and stored on different nodes.
It is precisely the multi-machine replication and partitioning of data that gives rise to the consistency problem in distributed systems. Let’s illustrate with a simple example:
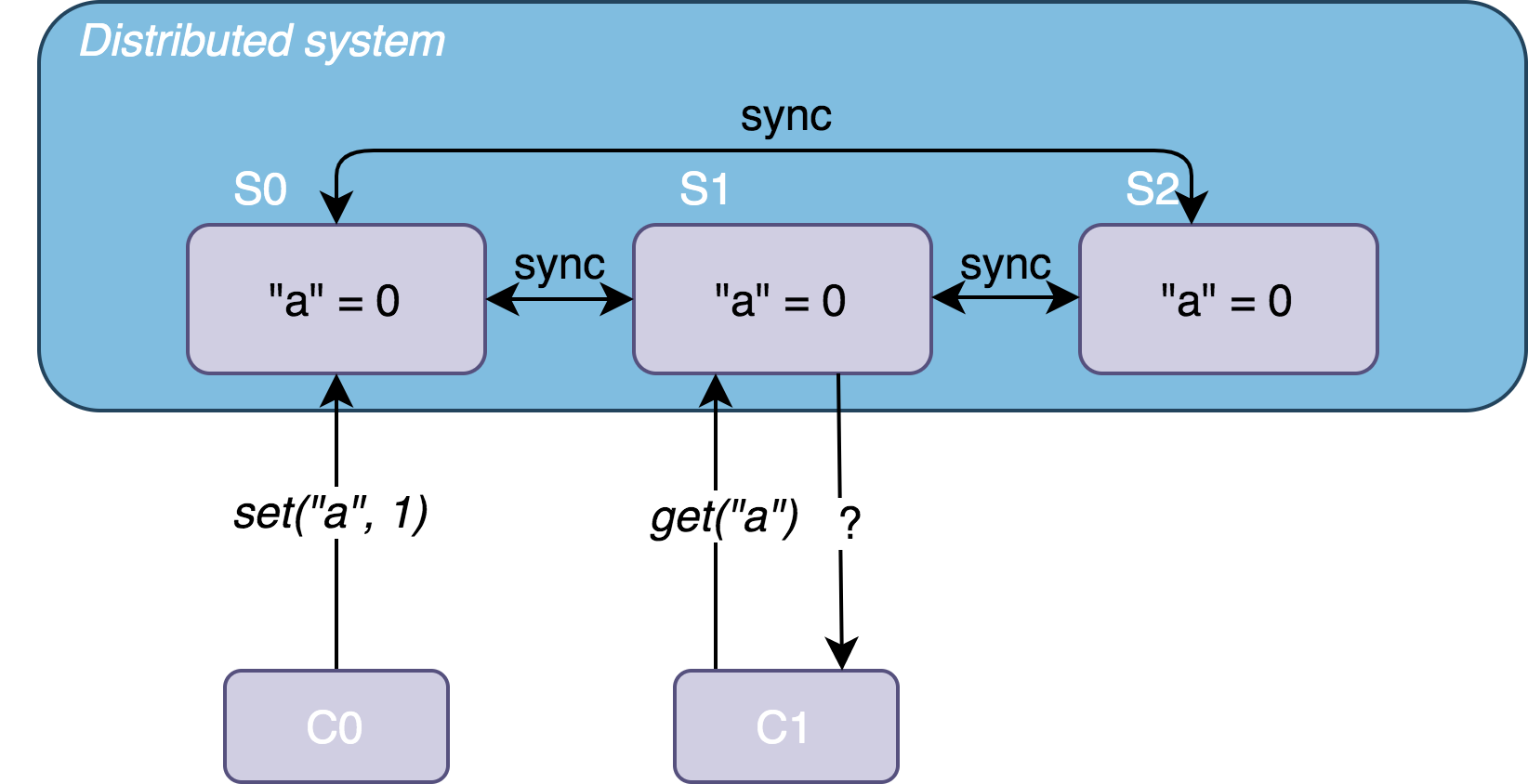
Take a strategy with only data replication. Suppose we have a data system consisting of three nodes, S0, S1, and S2, which store three replicas of a dataset D: D0, D1, and D2. This dataset is a simple key-value (Key-value) collection. Initially, the collection contains "a" = 0. At some time t, client C0 sends a write request set("a", 1) to S0 and receives a successful response; immediately after t, another client C1 sends a read request get("a") to S1.
cap-consistency-example.png
If the system is designed as follows:
- S0 changes the value of “a” and synchronizes it to S1, so C1 receives a response with the globally latest data
"a" = 1. - The system detects that S1 has not yet synchronized the latest data, so it returns an error response to C1, prompting it to retry.
Then the system satisfies consistency.
Availability
This property is relatively easy to understand: the system must return a non-error response within finite time. If the response time exceeds the tolerable limit by several orders of magnitude, the service is essentially unavailable. If the system responds quickly but returns an error response, such as bad file, data stale, etc., the service is still unavailable.
Partition Tolerance
This property used to trouble me quite a bit (and still does, to be honest), and I still cannot give a precise description of it. I can only characterize it from a few different angles.
The difficulty here lies in understanding network partitioning (network partitioning).
First, a simple understanding is that if one part of the system becomes network-isolated from other parts and can no longer communicate, and thus cannot complete data synchronization in a timely manner, then a network partition can be considered to have occurred. In the example above, if {S0} and {S1, S2} experience network isolation, the updated data in {S0} cannot be synchronized to {S1, S2} in time, resulting in a partition between {S0} and {S1, S2}.
Then, if we relax the constraints further: if there exist two parts of the system between which communication latency is so large that they cannot reach agreement within the time limit, a network partition can still be considered to have occurred. In the example above, after {S0} updates the data but before it synchronizes to {S1, S2}, C1’s request arrives, and the user will still access the old data. This too can be considered a partition between {S0} and {S1, S2}.
If the system can still provide service normally after a network partition occurs, then the system has partition tolerance.
Abstractly speaking, if the communication latency between system components is greater than the interval of system events (such as system requests), then a network partition will occur. This is the normal state of distributed systems. In the extreme case, if a system runs on a single machine, but the communication latency between components such as memory and CPU is very high, then this single machine can be considered a distributed system that has experienced a network partition.
All of the above are practical understandings. The theoretically strict definition of the conditions under which a network partition occurs is more stringent and will be explained in detail later.
Explanation
In a distributed system, network failures and node crashes are the norm, so network partitions are bound to occur. When a network partition occurs, based on business requirements, the system must choose between availability and consistency:
- Prioritize availability. The network partition makes some nodes unreachable, preventing the system from synchronizing data in time. Although the requested node attempts to return the latest data within its visible scope, it still cannot guarantee that this data is globally the latest—thus sacrificing consistency to ensure availability.
- Prioritize consistency. When the network partition prevents the requested node from guaranteeing that the data is globally the latest, it returns an error message to the user; or it returns nothing at all until the client times out.
But this principle does not mean that the system must abandon one of CAP at all times. For example, when the network is in good condition, there is no need to make a trade-off among the three; at this point, partition tolerance is not required, and both consistency and availability can be achieved.
To deeply understand this principle, one must grasp two key factors in distributed systems design: network environment and business requirements. It is especially important to note that principles are assertions under ideal conditions, while practice is about trade-offs in real-world scenarios. The CAP principle merely points out three important directions for system design trade-offs.
Network environment: Different systems face vastly different network environments.
If the network is in good condition and network partitions rarely occur, then partition tolerance does not need to be overly considered in system design. For example, the system could simply be designed to stop service when a partition occurs, or slightly better, allow the client to retry, etc. This may seem to sacrifice availability, but note that this situation rarely occurs, so the system may still be able to provide N-nines of service.
If the network is in poor condition and the cluster is very large, with network disconnections and node crashes being the norm, then the trade-off between availability and consistency in the event of a network partition must be carefully considered in system design. Here, it is worth emphasizing again that partition tolerance in the CAP theorem is highly idealized:
The network will be allowed to drop arbitrarily many messages sent from one node to another. — Gilbert, Lynch
If the network arbitrarily drops messages between nodes, classical distributed consensus protocols (such as Paxos and Raft) will be unable to stably elect a leader and provide normal service; industrial-grade distributed database systems (such as HBase and Dynamo) will also be unable to synchronize data across machines and provide normal storage services. But the network environments faced by most systems are not this bad. Therefore, we can achieve some degree of availability and consistency through consensus algorithms, redundant backups, and other means.
And this “some degree” is the business requirement we are about to discuss.
Business requirements: Designing for different business scenarios and preferences has given rise to the wide variety of distributed system middleware available on the market. Here, we only consider the two requirements of availability and consistency. It is also worth emphasizing again that in practice, most systems do not require atomic consistency (atomic consistency) or perfect availability (perfect availability).
For consistency, depending on requirements, there are choices such as strong consistency, weak consistency, and eventual consistency. Industrial-grade systems, in order to provide high availability, often choose weak consistency or eventual consistency within the tolerable range of the business, such as Amazon’s key-value store Dynamo.
For availability, aspects such as the volume of user requests, concurrency levels, and data size must be considered to define the system’s availability. No system can cover all scenarios. As long as the system design meets the business scenarios it targets, it can be said to satisfy the availability requirements. For example, a private cloud object storage service may face traffic of only a few dozen QPS per day, with reads far exceeding writes and very low concurrency. In this case, we can achieve both consistency and availability without making the system overly complex. But if this service were used in a scenario like Taobao’s Singles’ Day (11.11), the system’s availability would basically vanish.
Conclusion
Before distributed systems became widely popular, CAP summarized the important directions for trade-offs in distributed systems design. Today, with cloud computing and big data in full swing, a large number of excellent distributed systems have emerged, giving us more directions and practical details to consider in system design. Nowadays, when doing system design, there is no need to be too constrained by the CAP principle. Based on the business scenarios you face, make bold trade-offs.
Recommended Reading
- Wikipedia, CAP theorem: https://en.wikipedia.org/wiki/CAP_theorem
- Distributed Systems for Fun and Profit: http://book.mixu.net/distsys/abstractions.html
- Jeff Hodges, Notes on Distributed Systems for Young Bloods: https://www.somethingsimilar.com/2013/01/14/notes-on-distributed-systems-for-young-bloods/#cap
- https://codahale.com/you-cant-sacrifice-partition-tolerance/
- Recommended by 左耳朵耗子 (Chen Hao), Classic distributed systems architecture resources: https://www.infoq.cn/article/2018/05/distributed-system-architecture

