Objective
To fully leverage the performance of modern SSD storage, and under the same API, significantly reduce the read/write amplification of LSM-trees to improve their performance.
Background
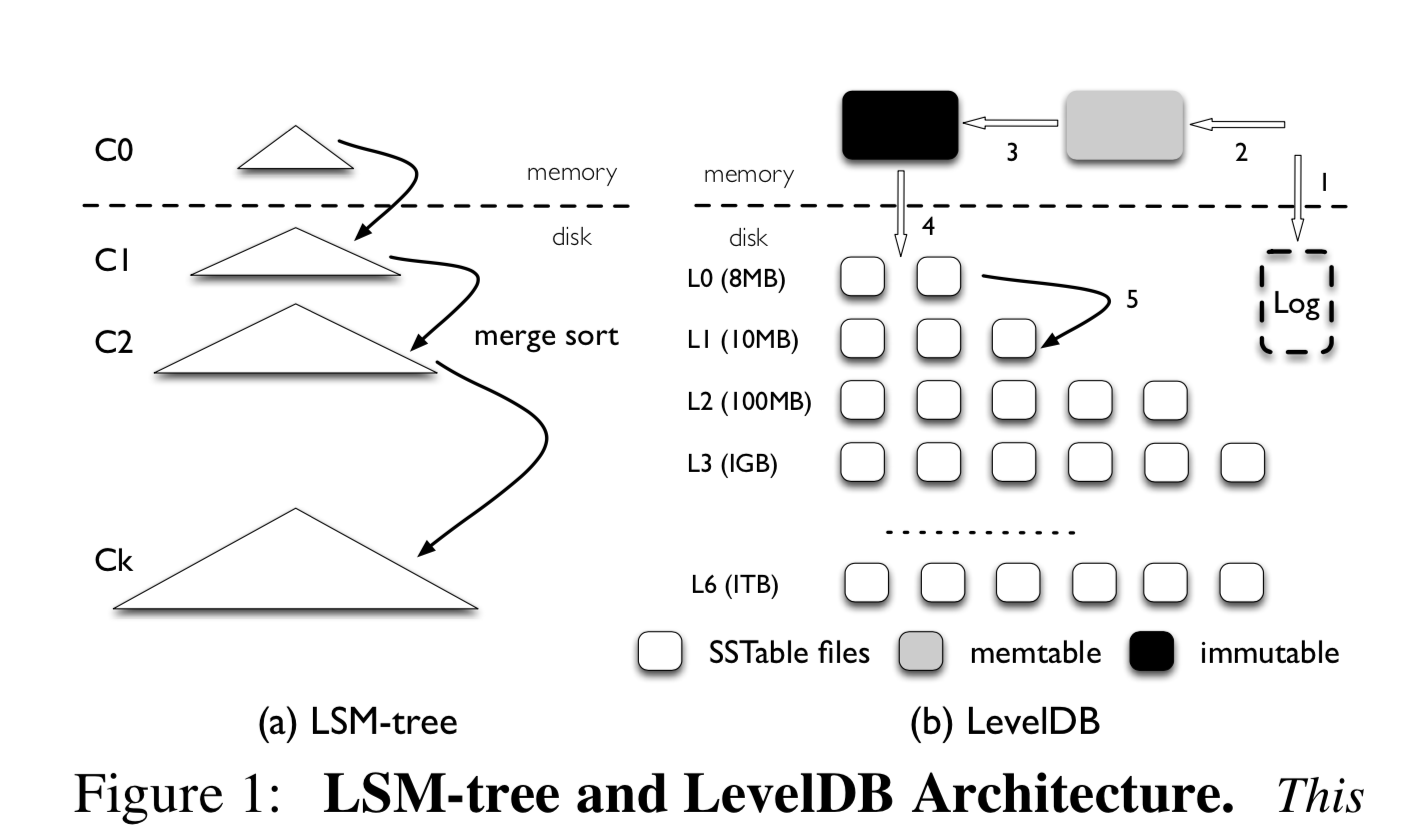
On traditional disks, sequential I/O performance is roughly 100x that of random I/O. LSM-trees build on this by implementing massive KV random reads/writes as in-memory random access + sequential flushing to disk + periodic merging (compaction), thereby improving read/write performance. This is especially suitable for scenarios with more writes than reads and strong temporal locality (recent data is accessed most frequently).
 wisckey-lsm-tree.png
wisckey-lsm-tree.png
Author: Woodpecker’s Miscellany https://www.qtmuniao.com/2020/03/19/wisckey/, please indicate the source when reprinting
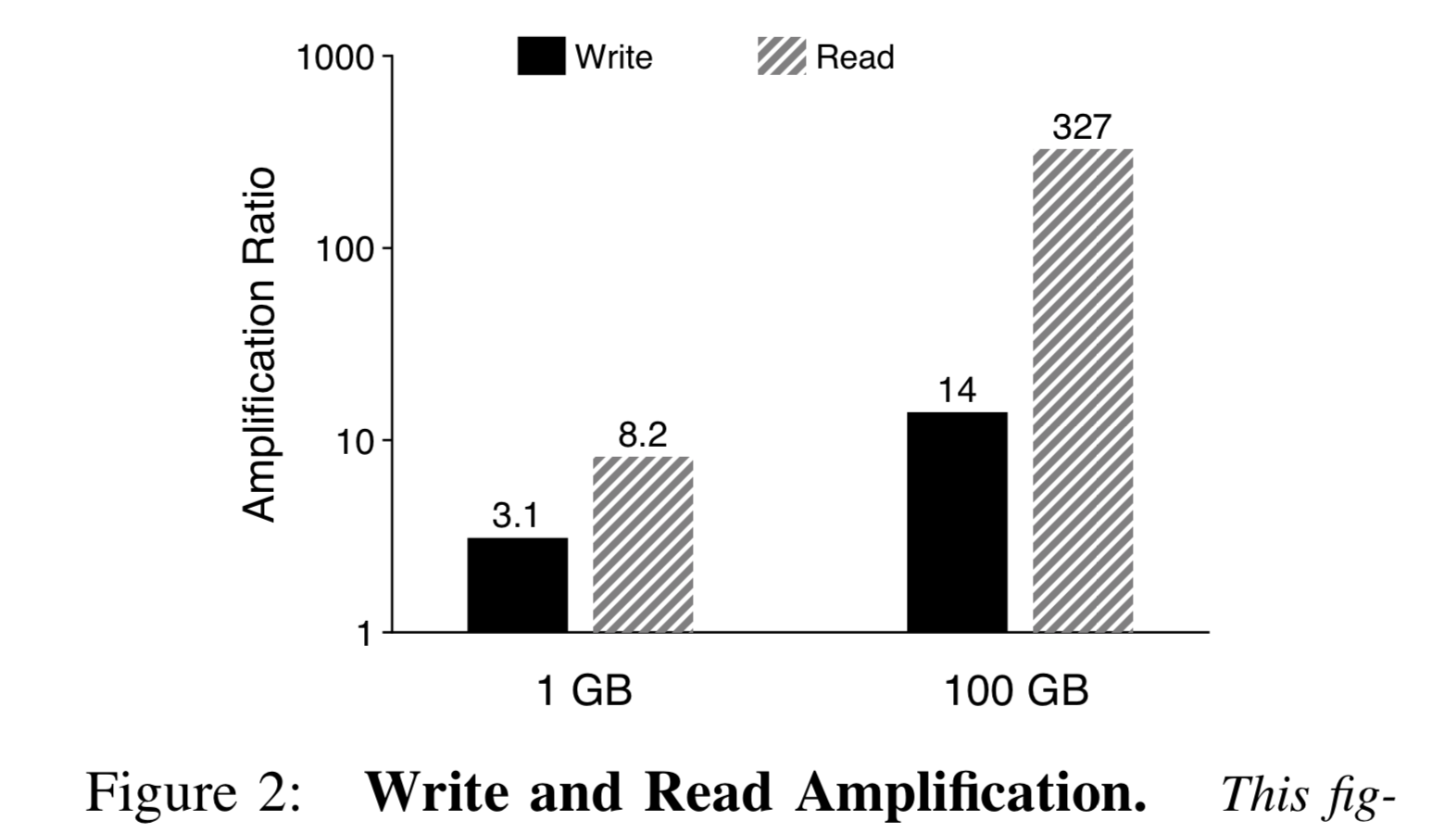
Read/Write Amplification. For write amplification, since LSM-trees have many levels, to speed up reads, continuous merge-sort compaction is needed, causing every KV pair to be read and written multiple times. For read amplification, vertically multiple levels must be queried to find a specific key; horizontally, since each level has multiple key ranges, binary search is required. Of course, to accelerate lookups, each level can be equipped with a bloom filter to quickly skip when the key does not exist in that level. As data volume grows, read/write amplification worsens.
 wisckey-rw-amplification.png
wisckey-rw-amplification.png
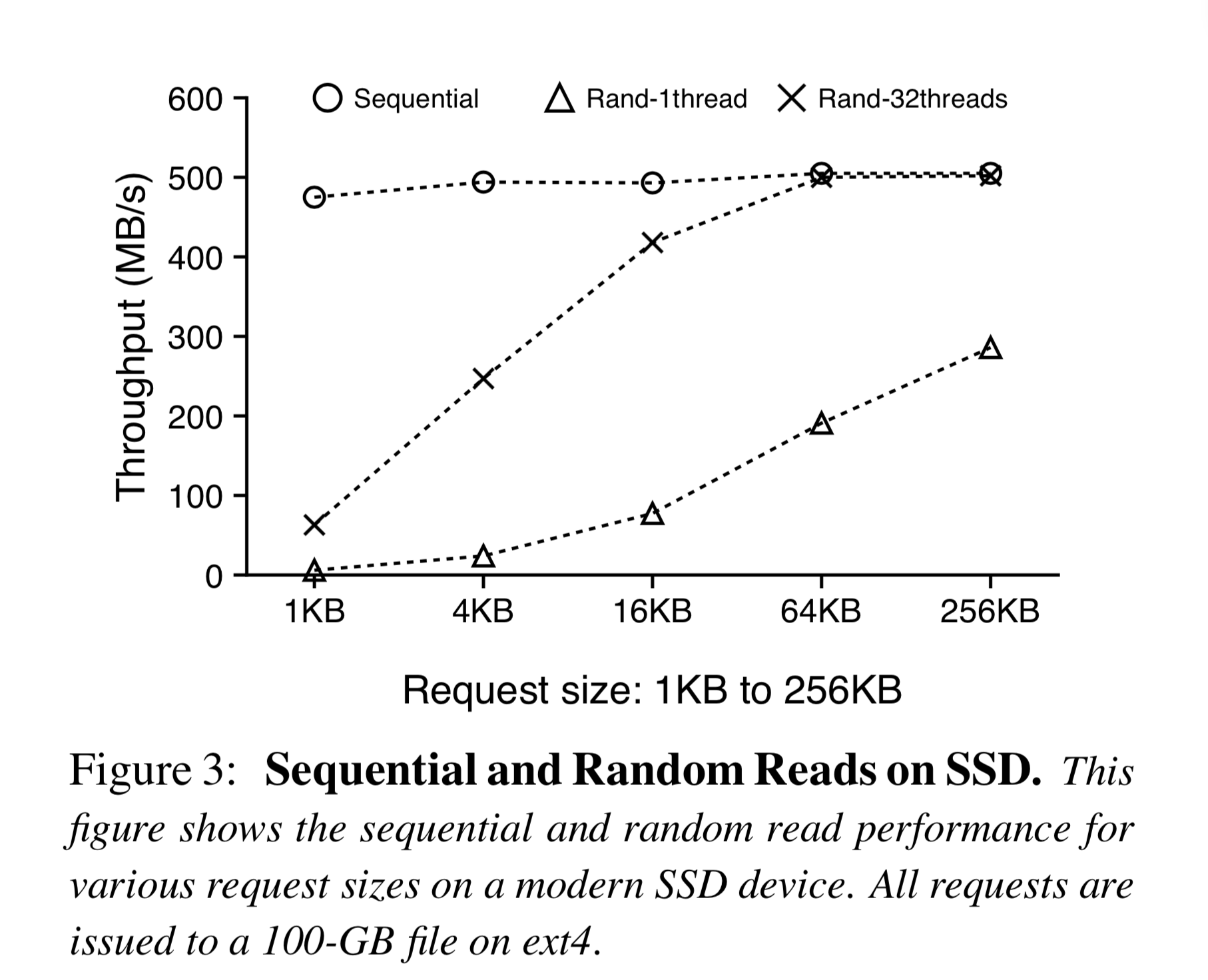
Today, as SSD prices continue to drop and adoption grows, the parallel random read performance of SSDs is quite good, not far behind sequential reads. Of course, random writes should still be avoided when possible, as they are not as uniformly fast as random reads and can reduce SSD lifespan.
 wisckey-ssd.png
wisckey-ssd.png
Core Design
WiscKey’s core design consists of the following four points:
- Key-value separation: Keys remain in the LSM-tree, while Values are stored in an additional log file (vLog).
- For unordered value data, leverage SSD parallel random reads to accelerate read speed.
- Use unique crash consistency and garbage collection strategies to efficiently manage the Value log file.
- Remove WAL without affecting consistency, improving write performance for small data traffic.
Design Details
Key-Value Separation
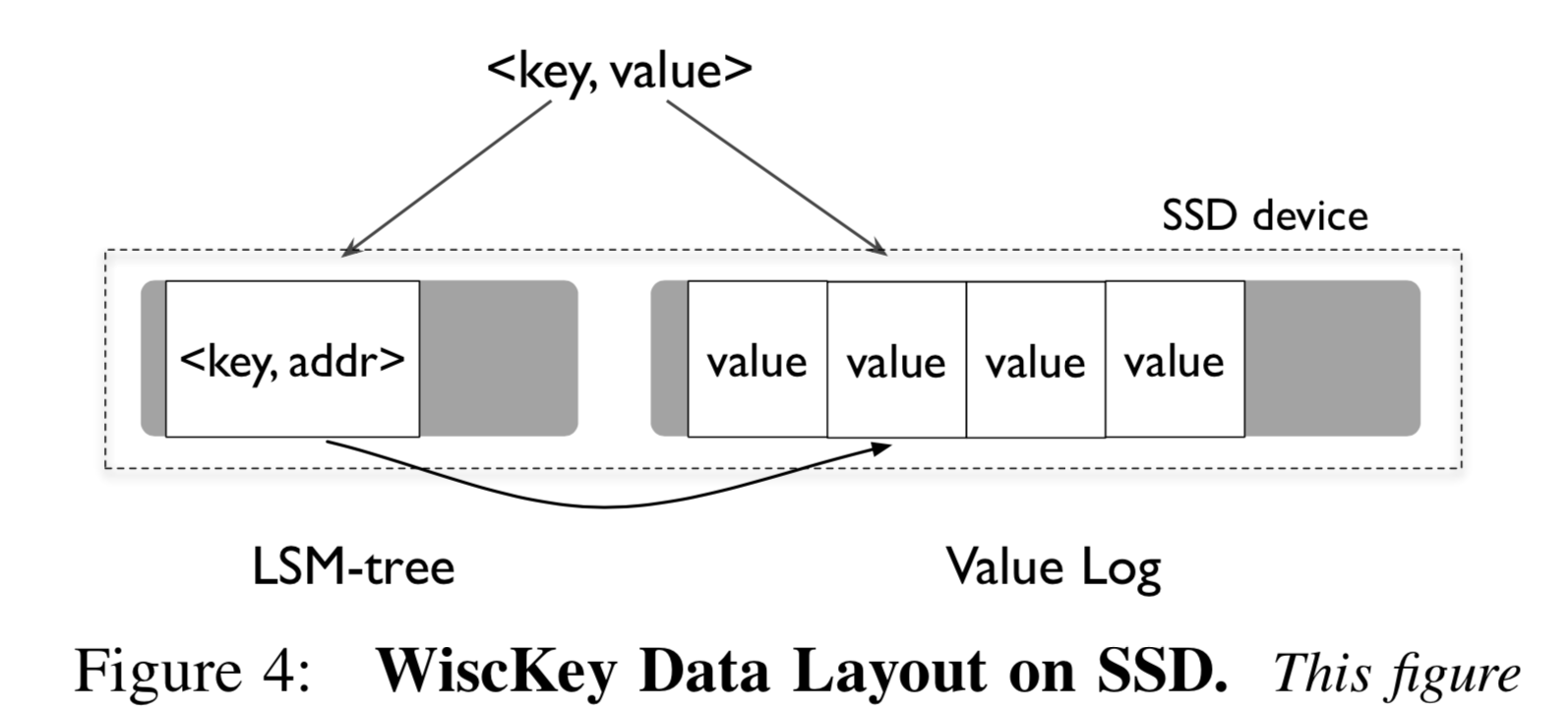
Keys are still stored in the LSM-tree structure. Since Keys typically occupy much less space than Values, the number of levels in WiscKey’s LSM-tree is small, resulting in little read/write amplification. Values are stored in an additional log file
[^log file]: A log file usually refers to a file that is appended to over time
called vLog. Of course, some metadata for the Value, such as its position in the vLog, is stored along with the Key in the LSM-tree, but this occupies very little space.
 wisckey-architecture.png
wisckey-architecture.png
Read. Although Keys and Values need to be read separately (i.e., one read needs to be decomposed into one in-memory lookup (most likely) in the LSM-tree and one random lookup on the SSD), since both are faster than the original level-by-level lookup, the total time spent is not more than LevelDB.
Write. First, append the Value to the vLog to obtain its offset, vLog-offset. Then write the Key and <vLog-offset, value-size> together into the LSM-tree. One append operation and one in-memory write—both are very fast.
Delete. An asynchronous deletion strategy is adopted: only delete the key in the LSM-tree; the Value in the vLog will be reclaimed by a periodic garbage collection process.
Despite the above advantages, key-value separation also brings many challenges, such as Range Query, garbage collection, and consistency issues.
Challenge 1: Range Query
Range Query (sequentially iterating over KV pairs within a specified key range) is a very important feature of modern KV stores. In LevelDB, key-value pairs are stored in key order, so range queries can be performed by sequentially iterating the relevant MemTable and SSTable. However, WiscKey’s Values are unordered, requiring many random lookups. But as shown in Figure 3, we can use multi-threaded parallel random lookups to saturate SSD bandwidth, greatly improving query speed.
Specifically, when performing a range query, first sequentially load the required Keys from the LSM-tree, then use multi-threaded random reads on the SSD to prefetch them into a Buffer. The read Keys and the Values in the buffer can then be sequentially combined and returned to the user, achieving very high performance.
Challenge 2: Garbage Collection
LevelDB uses compaction for deferred garbage collection; WiscKey also uses the same mechanism for Key reclamation. But for Values, since they reside in the vLog, an additional garbage collection mechanism is needed.
The simplest and most brutal approach is to first scan the LSM-tree structure in WiscKey to obtain the set of active Keys; then scan the vLog and reclaim all Values not referenced by the Key set. Obviously, this is a heavy (very time-consuming) operation, and to maintain consistency, external service may need to be stopped, similar to the stop-the-world in early JVM GC.
We clearly need a more lightweight approach. WiscKey’s approach is quite clever. The basic idea is to treat all Value data in the vLog as a strip, keeping all active data in the middle of the strip, using two pointers to mark the head and tail of the valid data region in the middle. The head can only perform append operations, while the tail performs garbage collection. So how do we maintain this valid middle data region?
 wisckey-gc.png
wisckey-gc.png
When garbage collection is needed, read a chunk of data (Block, containing a batch of data entries, each entry containing four fields: <ksize, vsize, key, value>; reading a block at a time is to reduce I/O) from the tail into memory. For each data entry, if it is still in use, append it to the head of the vLog strip; otherwise discard it; then move the tail pointer past this data.
The tail pointer is a critical variable that needs to be persisted to handle crashes. WiscKey’s approach is to reuse the LSM-tree structure that stores Keys, using a special Key (<"tail", tail-vLog-offset>) to store it together with the Keys. The head pointer is simply the end of the vLog file and does not need to be saved. In addition, WiscKey’s garbage collection timing can be flexibly configured, such as periodic collection, threshold-triggered collection, collection during idle time, etc.
Challenge 3: Crash Consistency
When a system crashes, LSM-trees typically provide guarantees such as atomicity of KV insertions and ordering during recovery. WiscKey can also provide the same consistency, but because keys and values are stored separately, the implementation is slightly more complex (atomicity is at least somewhat harder).
For the atomicity of data insertion, consider the following. After crash recovery, when a user queries a Key,
- If it cannot be found in the LSM-tree, the system treats it as non-existent. Even if the Value may have already been appended to the vLog, it will be reclaimed later.
- If it can be found in the LSM-tree, check the corresponding data entry
<ksize, vsize, key, value>in the vLog, and verify in turn whether the entry exists, whether its position is within the valid middle segment, and whether the Key matches. If not, delete the Key and tell the user it does not exist. To prevent partial writes from leaving incomplete entries after a crash, a checksum can also be added to each data entry.
Through the above process, we can guarantee the atomicity of KV writes: from the user’s perspective, either both the KV pair exist, or neither exists.
For the ordering of data insertion, since modern file systems (such as ext4, btrfs, xfs) guarantee the ordering of appends—that is, if data entries D1, D2, D3 … Dx, Dx+1, … are sequentially appended to the vLog, and if Dx was not appended to the vLog at the time of system crash, then no subsequent entries will be in the system. This guarantees the ordering of data insertion.
As will be discussed below, to improve the append efficiency for small Values, WiscKey uses a write buffer. Therefore, some data entries may be lost during a crash. For this, WiscKey provides a synchronous write switch to let WiscKey abandon the buffer, force-flush the Value to the vLog file, and then write the corresponding Key into the LSM-tree.
Optimization 1: vLog Buffer
For intensive, small-size write traffic, if the user calls put(K, V) each time and then calls a write primitive to append a data entry to the vLog, such frequent I/O will lead to poor performance and fail to fully utilize SSD bandwidth, as shown below:
 wisckey-buffer-write.png
wisckey-buffer-write.png
Therefore, WiscKey uses a buffer to cache written Values, only actually appending to the vLog when requested by the user or when a set size threshold is reached. Queries also need to be modified accordingly: each query first looks in the buffer, then in the vLog. But the cost of doing this is that, as mentioned earlier, unflushed data in the buffer will be lost during a system crash.
Optimization 2: Eliminating WAL
WAL, Write Ahead Log, is a commonly used data recovery mechanism in database systems. In traditional LSM-trees, since data is written directly to memory, a log entry is recorded before each operation for crash recovery; during recovery, the log is read entry by entry to restore the in-memory data structure. However, this adds disk I/O to every write request, reducing system write performance.
Since the data entries in the vLog sequentially record all inserted Keys, the vLog can be reused as the WAL for WiscKey’s LSM-tree. As an optimization, the checkpoint of each unpersisted Key <"head", head-vLog-offset> can also be saved in the LSM-tree. During each crash recovery, first obtain this checkpoint, then read the Keys from the vLog after this point entry by entry to restore the LSM-tree.

