Overview
Dynamo is a highly available KV storage system. To ensure high availability and high performance, Dynamo adopts an eventual consistency model, providing developers with a novel API that uses versioning and resolves conflicts with client-side assistance. Dynamo aims to provide uninterrupted service while guaranteeing performance and scalability. Since Amazon widely adopts a decentralized, highly decoupled microservices architecture, the availability requirements for the storage system underlying these microservices are particularly high.
S3 (Simple Storage Service) is another well-known storage service from Amazon. Although it can also be understood as a KV store, its target scenario differs from that of Dynamo. S3 is an object storage service for large files, mainly storing binary files and not providing cross-object transactions. Dynamo, on the other hand, is a document storage service for small files, mainly storing structured data (such as JSON). It allows indexing data and supports transactions across data items.
Compared to traditional relational databases, Dynamo can be seen as providing only a primary key index, thereby achieving higher performance and better scalability.
To achieve scalability and high availability while ensuring eventual consistency, Dynamo combines the following techniques:
- Consistent hashing for data partitioning and replication.
- Versioning mechanism (Vector Clock) to handle data consistency issues.
- Quorum and decentralized synchronization protocols to maintain consistency among replicas (Merkle Tree).
- Gossip Protocol for failure detection and replica maintenance.
In terms of implementation, Dynamo has the following characteristics:
- Fully decentralized, with no central node; all nodes are peers.
- Adopts eventual consistency, using version numbers to resolve conflicts, even requiring users to participate in conflict resolution.
- Uses hash values for data partitioning, organizing data distribution, and balancing data load.
Author: MUNIAO https://www.qtmuniao.com/2020/06/13/dynamo/, please cite the source when reposting
Background
Goals and Assumptions
Different design assumptions and requirements lead to completely different designs. Dynamo’s design goals are as follows:
Query Model. Using Dynamo only involves querying by primary key, generally without cross-data-item queries, so a relational model is not needed. Additionally, Dynamo assumes that the data it stores is relatively small, typically less than 1MB.
ACID Properties. Traditional relational databases (DBMS) usually require ACID properties to ensure the correctness and reliability of transactions. However, support for ACID significantly degrades performance. For high availability, Dynamo only provides weak consistency ©, does not provide isolation (I), and does not allow concurrent updates to a single key.
Efficiency. Most services at Amazon have strict latency requirements. To meet the SLAs of such services, Dynamo must be configurable, allowing users to choose among performance, efficiency, availability, and durability themselves.
Others. Dynamo is only used within Amazon’s internal services, so security does not need to be considered. Furthermore, many services use independent Dynamo instances, so the initial scalability target is at the level of hundreds of machines.
SLA
Due to the microservices architecture, rendering each page of the Amazon shopping website typically involves hundreds of services. To ensure user experience, strict limits must be placed on the latency of each service. Amazon adopts a three-nines SLA (99.9% of requests must be under 300ms). The state storage layer of a service is a critical node for providing this SLA. Therefore, a key design of Dynamo is to allow services to customize parameters such as durability and consistency on demand, enabling trade-offs among performance, cost, and correctness.
Design Considerations
For multi-replica systems, high availability and strong consistency are a trade-off. Traditional commercial systems often sacrifice some availability to guarantee strong consistency, but Dynamo is built for high availability and therefore chooses an asynchronous replication strategy. However, due to the frequent nature of network and server failures, the system must handle the inconsistencies or conflicts caused by these failures. How these conflicts are resolved mainly involves two aspects: when to resolve them, and who resolves them.
When to resolve. Traditional storage systems simplify reads by resolving conflicts on the write side — that is, rejecting writes when conflicts exist. However, to ensure that the shopping business is available to users at any time (for example, being able to add items to the cart at any time; after all, even a slight degradation in such processes affects significant revenue), Dynamo needs to provide an “always writable” guarantee. Therefore, the complexity of conflict resolution is deferred to the read time.
Who resolves. Should Dynamo resolve it, or should the application side? If Dynamo resolves it, the typical无脑 choice is “last write wins,” using newer changes to overwrite older ones. If the application resolves it, it can act according to its own needs — for example, it can merge multiple add-to-cart operations and return them to the user. Of course, this is optional, as many applications are fine with a general strategy (“last write wins”).
Other key design principles include:
Incremental scalability. Support dynamic addition and removal of nodes with minimal impact on the system and operations.
Symmetry. Every node in the system has the same responsibilities; there are no special nodes, simplifying construction and maintenance costs.
Decentralization. No central control node; peer-to-peer technology is used to make the system highly available and easy to scale.
Heterogeneity. The system must be able to fully utilize heterogeneous nodes and allocate load according to node capacity.
System Architecture
The discussion centers on distributed technologies such as partitioning algorithms, replication strategies, versioning mechanisms, membership organization, error handling, and scalability.
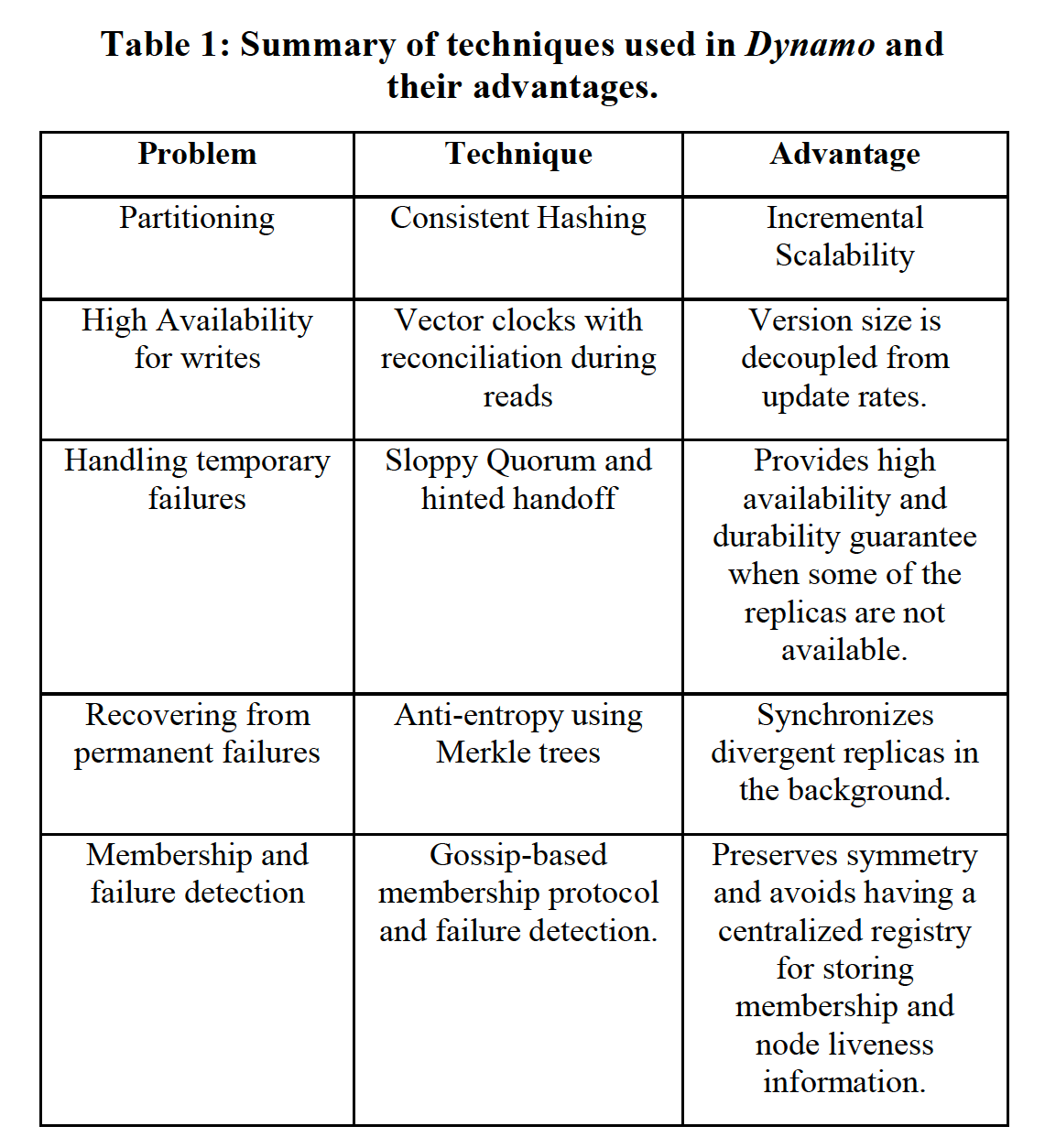 tech summary
tech summary
System Interface
Dynamo exposes two interfaces: put() and get():
get(key): Returns a single object corresponding to the key, or a list of objects with version conflicts.
put(key, context, object): Selects the replica machines where the object should be placed based on the key and persists the data. The context contains some system metadata transparent to the caller, such as the version information of the object. The context is stored together with the object to verify the legitimacy of the put request.
Dynamo treats both keys and values as byte arrays, and applies the MD5 algorithm to the key to generate a 128-bit identifier for selecting storage nodes.
Partitioning Algorithm
To support incremental scaling, Dynamo uses consistent hashing for load distribution. However, the basic version of consistent hashing has two drawbacks:
- It cannot evenly distribute the load.
- It does not account for differences in node resources.
To solve these problems, Dynamo uses a variant of consistent hashing: introducing virtual nodes. The specific algorithm is:
- When a node joins the system, it generates a corresponding number of virtual nodes based on its capacity, with each virtual node randomly assigned a node ID.
- All virtual nodes are organized into a ring structure according to the size of their IDs, with the head and tail connected.
- When a request arrives, a data ID is generated within the same ID space as the nodes using the key and some hashing algorithm.
- According to this ID, the system searches clockwise around the virtual node ring for the first virtual node and routes the request to its corresponding physical node.
- When a node leaves, only its corresponding virtual nodes need to be removed, and the load will automatically migrate around the ring.
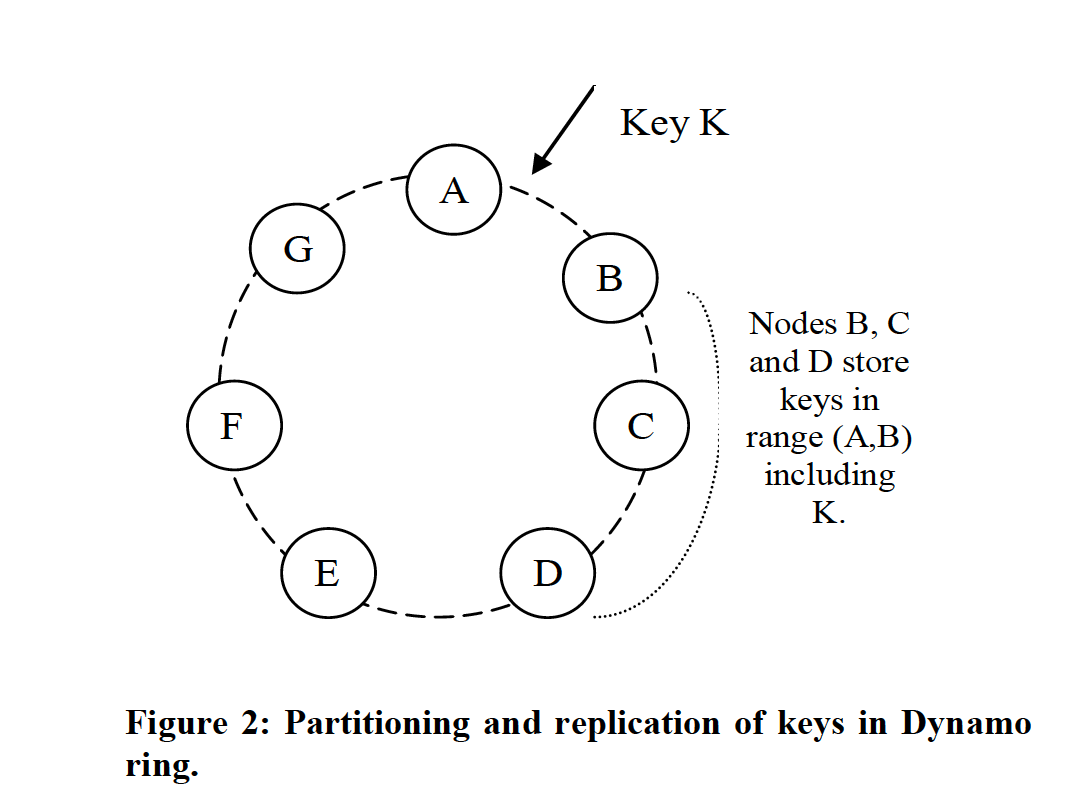 Key partitioning and replication in the Dynamo ring
Key partitioning and replication in the Dynamo ring
By assigning different numbers of virtual nodes, differences in node capacity are accommodated. By using a random algorithm to generate virtual node IDs, traffic is evenly distributed when nodes are added or removed.
To accommodate node additions and deletions and facilitate replication, Dynamo has successively used three partitioning strategies:
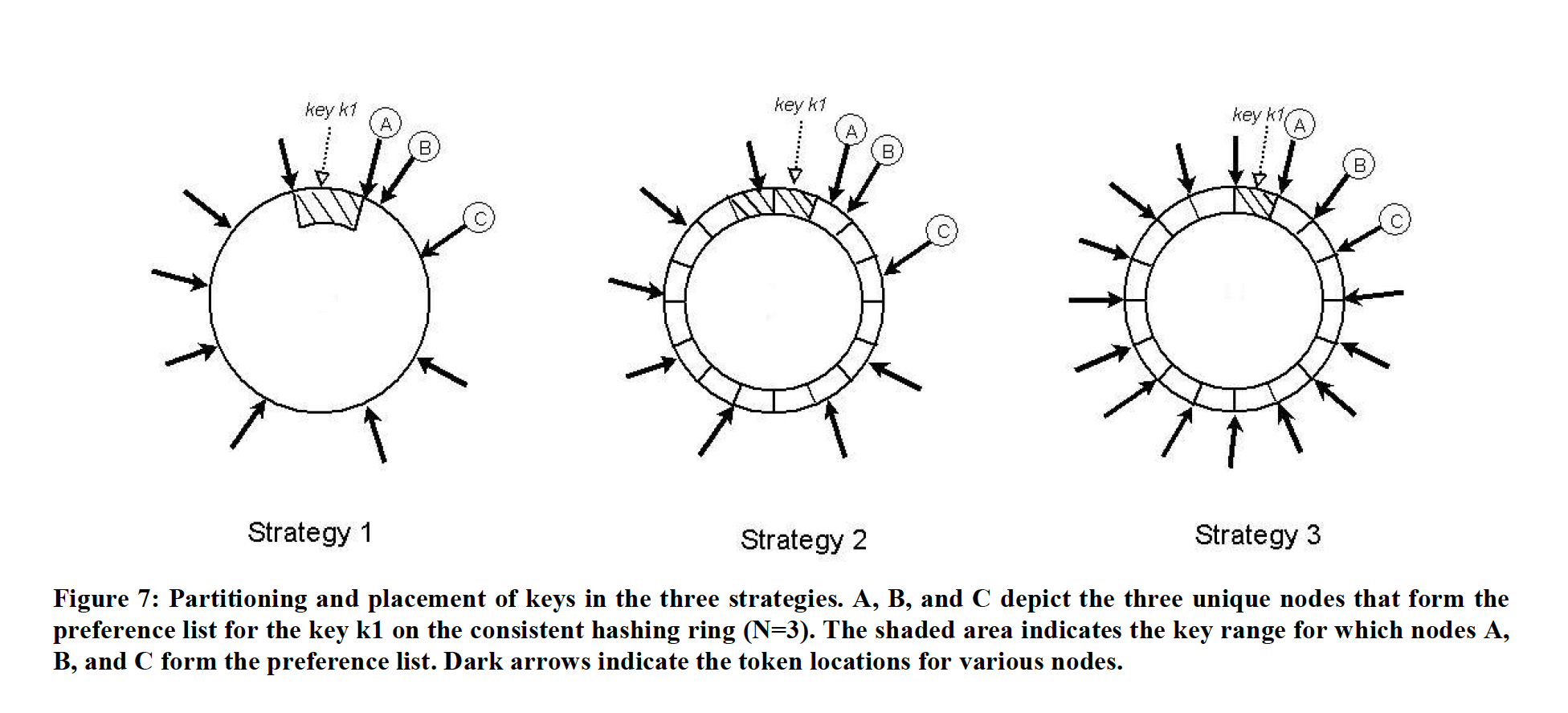 dynamo partition schema
dynamo partition schema
-
Each node is assigned T random numeric values (tokens), one per virtual node. The interval between the tokens of two adjacent virtual nodes in the hash ring constitutes a partition.
This initial strategy has the following drawbacks:
-
Migration scanning. When a new node joins the system, it needs to steal some data from other nodes. This requires scanning all data items in the successor nodes of the newly added virtual nodes to obtain the data to be migrated (presumably, to serve get requests, data on a node is generally organized and indexed by user key rather than the hash value of the key, so to get data for a certain hash value range, a full scan is required). This operation is quite heavy. To ensure availability, the running priority of the migration process must be lowered, but this makes the migration process last a long time.
-
Merkle Tree recalculation. The Merkle Tree, discussed below, can be roughly understood as a hierarchical signature of data on a per-partition basis. When a node joins or leaves the cluster, it causes key range splits or merges, which in turn trigger recalculation of the corresponding Merkle Tree. This is also a compute-intensive operation that causes heavy additional load, which is intolerable in a production system.
-
Difficult global snapshots. Since the distribution of data in physical nodes is partitioned by the hash value of the key, the data is scattered in key space. It is difficult to take a global snapshot in key space, as this requires a global merge sort of data on all nodes, which is inefficient.
It can be seen that the fundamental problem with this strategy is that data partitioning and data placement are coupled together. Thus, we cannot add or remove nodes independently without affecting data partitioning. Therefore, a natural improvement is to decouple data partitioning from data placement.
-
-
Each node is still randomly assigned T IDs, but the hash space is equally divided into partitions.
Under this strategy, the node’s token is only used to construct the virtual node hash ring and is no longer used to cut partitions. The hash space is equally divided into Q parts, where Q >> S*T, and S is the number of physical nodes. That is, each virtual node can hold many partitions. This strategy can be understood from another angle: the smallest unit hosted by a node is no longer a key but a partition. Each time a node is added or removed, the partition is moved as a whole. This solves the problems of migration scanning and Merkle Tree recalculation during node additions and removals.
For key placement, each time a key is routed, its hash value is first calculated. Based on the last hash value of the partition (key range) where the hash value resides, a lookup is performed in the hash ring. The first N physical nodes encountered clockwise form the preference list.
-
Each node gets Q/S random IDs, and the hash space is equally divided into partitions.
Based on the previous strategy, this strategy forces each physical node to have an equal number of partitions. Since the number Q, and even the number of partitions per node (Q/S), is much greater than the number of nodes (S), when a node leaves, it is easy to distribute the partitions it hosts to other nodes while still maintaining this property. When a node joins, it is also easy for each node to give it a share.
Replication Strategy
Dynamo replicates each piece of data on N nodes, where N is configurable. For each key, there is a coordinator node responsible for its replication across multiple nodes. Specifically, the coordinator node is responsible for a key range.
When replicating, the coordinator selects the next N-1 nodes clockwise on the consistent hash ring, along with itself, to store N copies of the data item, as shown in Figure 2. These N nodes are called the preference list. Among them:
- The mapping from key to node differs depending on the three partitioning strategies described above.
- Nodes may crash and restart, so the preference list may sometimes contain more than N nodes.
- Since virtual nodes are used, without intervention, these N nodes might correspond to fewer than N physical machines. Therefore, when selecting nodes, we need to skip to ensure that the N nodes are on N physical machines.
Data Versioning
Dynamo provides an eventual consistency guarantee, allowing multi-replica asynchronous synchronization to improve availability. If there are no machine or network failures, multiple replicas will synchronize within a finite time. If failures occur, some replicas may never complete synchronization normally.
Dynamo provides availability at any time. If the latest data is unavailable, it needs to provide the next newest. To provide this guarantee, Dynamo treats each modification as a new, immutable version. It allows multiple versions of data to coexist. In most cases, newer versions of data can overwrite older ones, allowing the system to automatically select the authoritative version (syntactic reconciliation). However, when failures occur or there are parallel operations, conflicting version branches may appear. At this point, the system cannot automatically merge them and must hand over the task of collapsing multiple version data to the client (semantic reconciliation).
Dynamo uses a logical clock called a vector clock (vector clock) to express the causality among multiple versions of the same data. A vector clock consists of a sequence of <node, counter> pairs, corresponding to the synchronized versions of the same data. The relationship among multiple data versions can be determined by their vector clocks: whether they occurred in parallel (parallel branches) or have a causal relationship (casual ordering):
- If the counter in vector clock A is less than the counter for all nodes in vector clock B, then A is the predecessor of B and can be discarded. For example, A is [<node1, 1>] and B is [<node1, 1>, <node2, 2>, <node3, 1>]
- If A is not the predecessor of B, and B is not the predecessor of A, then A and B have a version conflict and need to be reconciled.
In Dynamo, when a client updates a data object, it must specify the version of the data object to be updated. The specific method is to pass the version information (vector clock) of the same data object obtained from the previous Get into the context of the update operation. Similarly, when a client reads data, if the system cannot perform automatic merging (syntactic reconciliation), it will return multiple version informations to the client via context. Once the client uses this information for a subsequent update, the system considers that the client has merged the multiple versions (semantic reconciliation). The following figure is a detailed example.
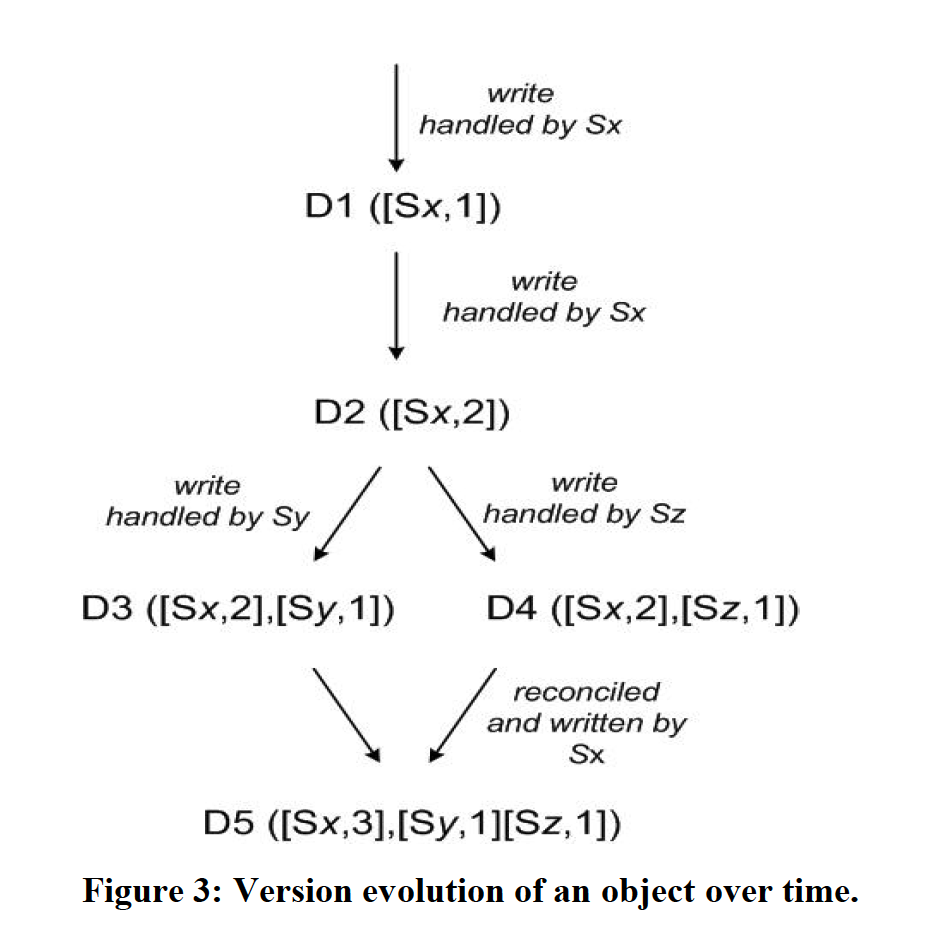 Version evolution of a data object
Version evolution of a data object
There are a few points to note:
- Each server node maintains an auto-incrementing counter, which is updated before processing a change request.
- To prevent the size of the vector clock from growing indefinitely, especially when network partitions or server failures occur, Dynamo’s strategy is that when the vector clock sequence exceeds a certain threshold (say, 10), the earliest clock pair in the sequence is discarded.
get() and put()
This section describes the interaction when the system has no failures. It is mainly divided into two processes:
- Select a coordinator in some way.
- The coordinator uses a quorum mechanism for multi-replica data synchronization.
Selecting the Coordinator
Dynamo exposes services via HTTP. There are mainly two strategies for selecting the coordinator:
- Use a load balancer to select a lightly loaded node.
- Use a partition-aware client to directly route to the corresponding coordinator responsible for the key (i.e., the first in the preference list).
In the first approach, the client does not need to save server node information. In the second approach, no forwarding is needed, resulting in lower latency.
For the first approach, if it is a put() request and the selected node S is not among the top N nodes in the preference list, S will forward the request to a machine in the preference list as the coordinator. If it is a get() request, regardless of whether S is in the preference list, it can directly act as the coordinator.
Quorum Mechanism
The quorum read-write mechanism is an interesting read-write approach with two key configuration parameters, R and W. Usually, R and W need to satisfy: 1. R + W > N 2. W > N/2, where N is the cluster replication count. It can be understood from two angles: one is an analogy to read-write locks, where the system cannot have multiple concurrent writes or concurrent reads and writes simultaneously, but with a smaller R, multiple reads can occur at the same time; the other is that more than half of the writes need to succeed to meet data durability characteristics. However, in Dynamo, none of these are hard requirements; users can flexibly configure them according to their needs.
When a put() request arrives, the coordinator generates a new vector clock version for the new data, writes it locally, and then sends the data to the N preferred replica nodes. Once W-1 nodes reply, the request is considered successful.
When a get() request arrives, the coordinator sends requests to all nodes in the top N preferred nodes (including/excluding itself) that hold the key. Once R nodes return, it returns the multi-version result list to the user. Then, syntactic reconciliation is performed according to the vector clock rules, and the reconciled version is written back.
Failure Handling: Hinted Handoff
If strict quorum mechanisms were used for reads and writes, even a small number of node crashes or network partitions would make the system unavailable. Therefore, Dynamo uses a “sloppy quorum” algorithm that can select the first N healthy nodes in the consistent hash ring from the preference list.
Furthermore, when the preferred coordinator (say, A) fails, the request routed to another node (D) carries the first choice (A’s information) in its metadata. D has a resident background thread that, upon detecting A coming back online, moves this marked data to the corresponding machine and deletes the corresponding local replica. Through this hinted handoff approach, Dynamo ensures that requests can still be completed normally when there are node or network failures.
Of course, for high availability, W can be set to 1, so that any available node in the preference list can result in a successful write. But in practice, to ensure durability, it is generally not set this low. The following sections will detail the configuration of N, R, and W.
In addition, to handle datacenter-level failures, Dynamo configures the preferred node list to span different centers for disaster recovery.
Permanent Failure Handling: Replica Synchronization
Hinted Handoff can only handle occasional, temporary node crashes. To handle more severe failures and the consistency issues they bring, Dynamo uses a decentralized anti-entropy algorithm for data synchronization among shard replicas.
To quickly detect whether replica data is consistent and precisely locate differing areas, Dynamo uses Merkle Trees (also called hash trees, used in blockchain as well) to hierarchically sign all data in a shard on a per-shard basis. All leaf nodes are the hash values of real data, and all intermediate nodes are the hash values of their child nodes. Such a tree has two benefits:
- By comparing only the root node, one can determine whether the two replicas of a shard have consistent data.
- Each intermediate node represents the signature of all data in a certain range; if they are equal, the corresponding data is consistent.
- If there are only a few inconsistencies, one can quickly locate the inconsistent data position starting from the root node.
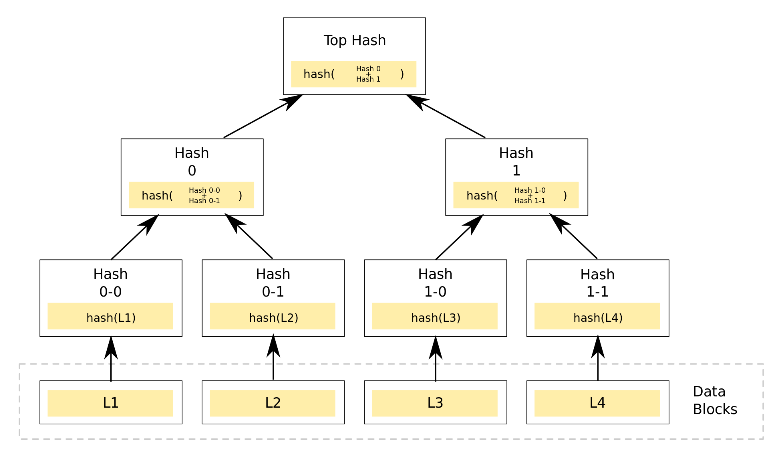 merkle tree
merkle tree
Dynamo maintains a Merkle Tree for each data partition (key range or shard; shard is the smallest logical storage unit). With the properties of the Merkle Tree, Dynamo can quickly compare whether the replica data of two data partitions is consistent. If not, it can locate the inconsistent position to minimize data transfer.
The downside of this approach is that if a node joins or leaves the cluster, it causes a large number of key range changes, requiring recalculation of Merkle Trees for the changed key ranges. Of course, as discussed earlier, the improved partitioning strategy mitigates this problem.
Membership and Failure Detection
Explicit membership management. In Amazon’s environment, nodes leaving the cluster due to failures or human error are usually rare or do not last long. If data partition placement were automatically adjusted every time a node went offline, it would cause unnecessary data churn and migration. Therefore, Dynamo adopts explicit membership management, providing corresponding interfaces for administrators to bring physical nodes online or offline. That is, a node going offline due to failure will not cause data partition movement.
Gossip-like algorithm to broadcast metadata. Membership changes are first perceived by the node handling the membership addition/deletion request, persisted locally, and then broadcast using a gossip-like algorithm. Each time, a node is randomly selected for propagation, eventually allowing all members to reach consensus on this. In addition, this algorithm is also used by nodes to exchange shard information and data distribution information when they first start up.
When each node first starts, it only knows its own node information and token information. As various nodes start up one after another and exchange information with each other through the algorithm, the topology of the entire hash ring (the mapping from key range to virtual node, and from virtual node to physical node) is incrementally constructed on each node. Thus, when a request arrives, it can be directly forwarded to the corresponding processing node.
Seed nodes to avoid logical partitions. Functional seed nodes are introduced for service discovery; each node connects directly to seed nodes so that each joining node is quickly known to other nodes, avoiding logical partitions caused by joining the cluster simultaneously without knowing each other.
Failure detection. To avoid continuously forwarding put/get requests and metadata synchronization requests to unreachable nodes, only local failure detection is sufficient. That is, if A sends a request to B and receives no response, A marks B as failed and starts heartbeats to detect its recovery. If A receives a request that should be forwarded to B and finds B failed, it selects an alternative node in the preference list for that key.
It can be seen that Dynamo separates permanent departure and temporary departure of nodes. Explicit interfaces are used to add or remove permanent members, and the member topology is broadcast via a gossip algorithm. Simple marking and heartbeats are used to handle occasional failures and appropriately forward traffic. In environments with few failures, such a divide-and-conquer approach can greatly improve the efficiency of reaching consensus and maximize the avoidance of unnecessary data migration caused by occasional node failures and network jitter.
Adding and Removing Nodes
As shown in the figure below, consider the case of three replicas (N=3) and using the simplest partitioning strategy. When a node X is added between nodes A and B, X will be responsible for the Key Ranges: (F,G], (G, A], (A, X]. At the same time, B will no longer be responsible for (F,G], C will no longer be responsible for (G, A], and D will no longer be responsible for (A, X]. Dynamo adapts to X’s joining by having B, C, and D actively push the relevant Key Ranges to X. There is a waiting-for-X-confirmation phase before pushing to avoid duplicate pushes.
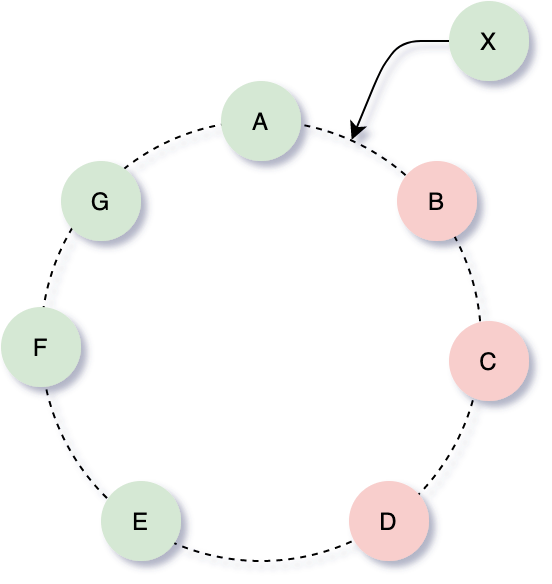 add member
add member
Implementation
Each node in Dynamo mainly consists of four components: request coordination, membership, failure detection, and a local persistence engine. All components are implemented in Java.
Dynamo’s local persistence component allows choosing among multiple engines, including Berkeley Database (BDB), MySQL, and an in-memory + persistence-based storage. Users can choose according to their business scenarios; most production environments use BDB.
The request coordination component is implemented using Java NIO channels, adopting an event-driven model where the processing of a message is divided into multiple stages. A state machine is initialized for each incoming read or write request. For example, for read requests, the following state machine is implemented:
- Send requests to all nodes holding replicas of the shard containing the key.
- Wait for the minimum required number of nodes ® to return for the read request.
- If R responses are not collected within the set time limit, return a failure message to the client.
- Otherwise, collect all version data and determine the version data to be returned.
- If versioning is enabled, perform syntactic reconciliation, and write the reconciled version into the context.
During the read process, if some replica data is found to be outdated, it is updated along the way. This is called read repair.
For write requests, one of the top N preferred nodes will act as the coordinator, usually the first one. But to improve throughput and balance load, usually all N nodes can act as coordinators. In particular, since most data is followed by a write shortly after being read (read to get the version, then write using the corresponding version), writes are often scheduled to the node that responded fastest in the last read. This node saved the context information from the read and can respond faster, improving throughput.
References
Comparison of S3 and Dynamo: https://serverless.pub/s3-or-dynamodb/
Optimistic replication: https://en.wikipedia.org/wiki/Optimistic_replication

