Overview
Facebook TAO[1], short for The Associations and Objects, uses nodes (Objects) and edges (Associations) — the most fundamental abstractions in a “graph” — making the name fitting for Facebook’s graph storage.
In summary, TAO is Facebook’s solution for updating ultra-large data and reading associations in social scenarios. Its core characteristics are:
- Provides a graph API specialized for Facebook’s social feed scenarios, such as point queries, first-degree association queries, and time-based range queries.
- Two-layer architecture: MySQL as the storage layer and MemCache as the caching layer; the caching layer can be further divided into primary and secondary layers.
- Can be extended across multiple data centers, highly optimized for read performance, and provides only eventual consistency guarantees.
Author: Woodpecker’s Notes https://www.qtmuniao.com/2021/10/07/facebook-tao/, please indicate the source when reposting
Historical Evolution
Facebook’s early data was stored on MySQL[2]. When MySQL could no longer handle the load, Zuckerberg introduced MemCache as a caching layer in 2005 to cope with higher-frequency read requests. Since then, MySQL and MemCache have become part of Facebook’s storage technology stack.
Facebook’s data request workloads typically exhibit temporal locality (i.e., recently updated data is most likely to be accessed) rather than spatial locality. However, data in MySQL is usually not stored in time order, so MySQL’s InnoDB engine’s built-in block cache does not match this characteristic. In addition, MemCache itself only provides an in-memory KV access model. To utilize this memory more efficiently, Facebook needed to customize caching strategies for social scenarios to maximize read request hits.
Exposing these engineering details — including the two-layer storage cluster and self-organized caching — to application-layer engineers brought significant engineering complexity, caused more bugs, and reduced product iteration speed. To solve this problem, Facebook built an abstraction layer on the server side using PHP in 2007, based on a graph storage model and providing APIs around nodes (objects) and edges (associations). Since social scenarios such as likes, events, and pages can be conveniently expressed through a graph model, this abstraction layer greatly reduced the cognitive burden on application-layer engineers.
However, as more APIs were needed, the drawbacks of separating the graph model layer (on the web server) from the data layer (on the MySQL and MemCache clusters) gradually became apparent:
- A tiny update to an edge set would cause the entire edge set to be invalidated, reducing cache hit rates.
- Requesting a tiny subset of an edge list also required pulling the entire edge list from the storage side to the server side.
- Cache consistency was difficult to maintain.
- The MemCache cluster at the time could hardly cooperatively support a pure client-side thundering herd avoidance strategy.
All these problems could be solved by redesigning a unified, graph-model-based storage layer. Starting in 2009, TAO began to be incubated within a team at Facebook. Since then, TAO has gradually evolved into a distributed service supporting tens of billions of reads per second and millions of writes, deployed across massive numbers of machines in multiple regions.
Graph Model & API
The most basic components of a graph are nodes and edges, which in TAO correspond to Objects and Associations. Both objects and associations can contain a series of attributes represented by key-value pairs.
1 | Object: (id) → (otype, (key value)*) |
Note: Edges in TAO are all directed edges.
Taking a social network as an example, objects can be users, check-ins, locations, and comments, while associations can be friend relationships, commenting, checking in, and checking in at a location, etc.
As shown in figure a) below, suppose there is an event on Facebook: Alice and Bob checked in at the Golden Gate Bridge, Cathy commented: “Wish I was there too.” David liked this comment.
After representing it with a graph model, as shown in figure b):
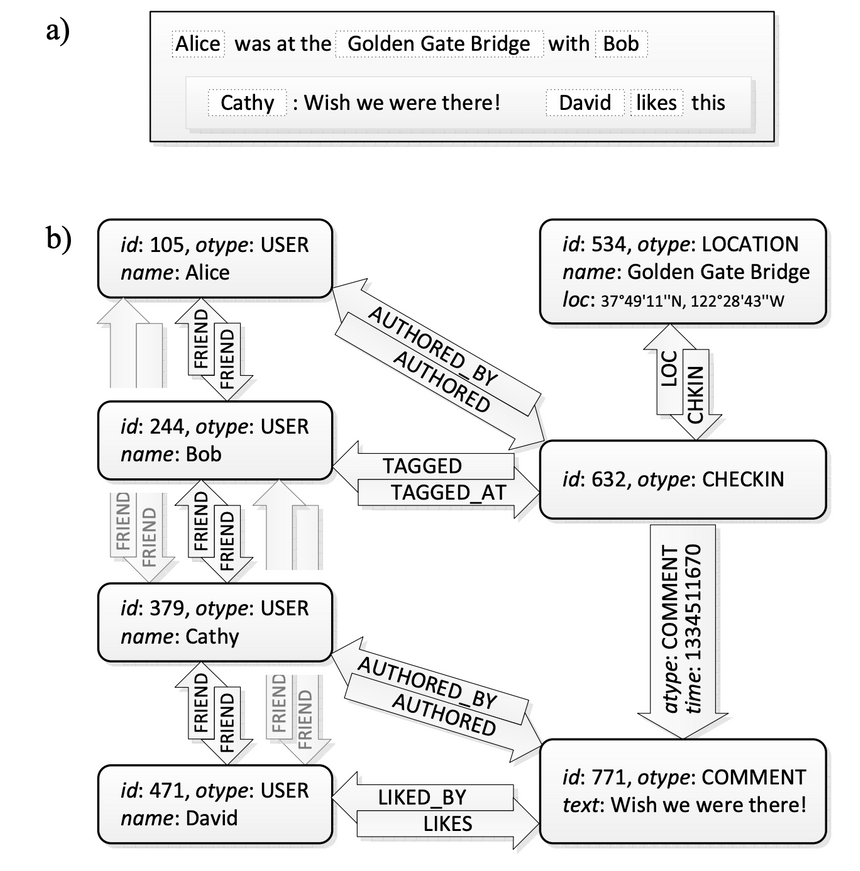 An Example
An Example
As you can see, all data entries such as users, locations, check-ins, and comments are represented as typed objects, while relationships between objects such as LIKED_BY, FRIEND, and COMMENT are represented as typed associations.
In addition, although associations in TAO are unidirectional, most relationships in practice are bidirectional. In this case, an inverse edge can be added to represent such a bidirectional relationship.
Finally, because associations are triples, there can be multiple edges of different types between two objects, but only one edge of the same type. However, in some non-social scenarios, multiple edges of the same type may be needed.
Object API
Operations around Objects are the common CRUD (create / delete / set-fields / get).
Objects of the same object type have the same set of attributes (fields, i.e., the (key value)* mentioned above), meaning that one object type corresponds to a fixed set of attributes. You can add or remove attributes by modifying the object type’s schema.
Association API
The basic operations around Associations are also CRUD. The create, delete, and update operations are as follows:
1 | assoc_add(id1, atype, id2, time, (k→v)*) – add or overwrite |
It is worth mentioning that if its inverse edge ((id1, inv(atype), id2)) exists, the above API will simultaneously apply to the inverse edge. Since associations in most scenarios are bidirectional, Facebook’s default behavior for edge APIs is to apply to both edges.
In addition, each Association is automatically stamped with an important special attribute: association time. Because Facebook’s workload has temporal locality, this timestamp can be used to optimize cached datasets to improve cache hit rates.
Association Query API
The query APIs around Associations are TAO’s core APIs and carry the most traffic. The workload types include:
- Point query specifying
(id1, type, id2), usually used to determine whether a corresponding association exists between two objects, or to get the attributes of the corresponding association. - Range query specifying
(id1, type), requiring the result set to be sorted in descending order by time. For example, a common scenario: What are the 50 most recent comments on this post? In addition, it is best to provide iterator-style access. - Out-edge count query specifying
(id1, type). For example, querying How many likes does a comment have? This kind of query is very common, so it is best to store it directly so that the result can be returned in constant time.
Although there are countless associations, recent ranges are the focus of queries (temporal locality), so the association query APIs mainly revolve around time-based range queries.
For this purpose, TAO defines the most basic association set as an Association List. An Association List is the set of all associations starting from id1 with out-edge type atype, sorted in descending order by time.
1 | Association List: (id1, atyle) -> [a_new, ..., a_old] |
Based on this, several more fine-grained interfaces are defined:
1 | // Returns the set of associations starting from id1 and ending at points contained in id2set |
Why is the result set sorted in descending order by time? Because when displaying a Facebook page feed, the newest content is always shown first, and then older data is loaded sequentially as the user scrolls down.
For example:
1 | • "50 most recent comments on Alice's checkin" ⇒ assoc_range(632, COMMENT, 0, 50) |
Architecture
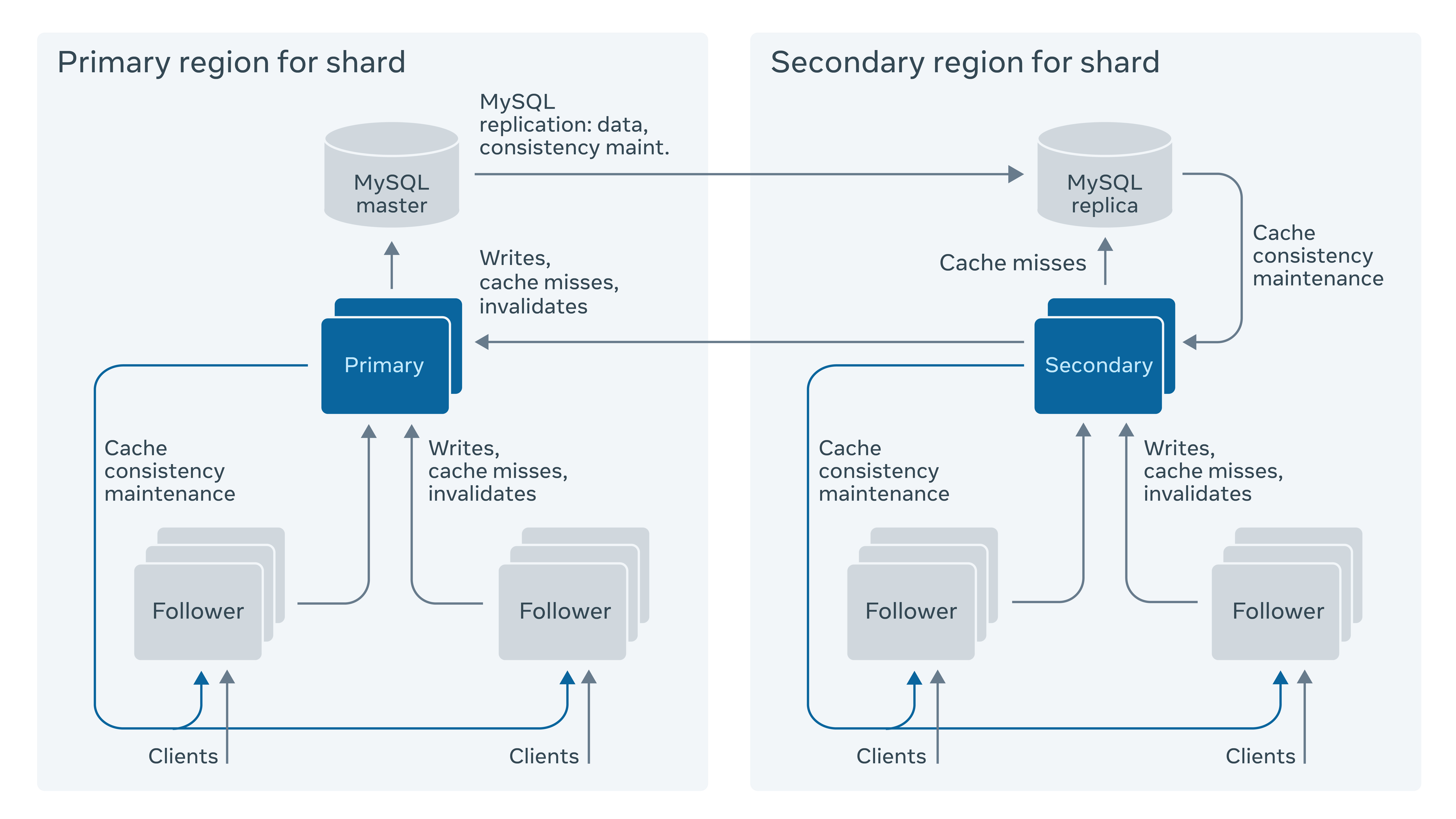 TAO Architecture
TAO Architecture
TAO’s architecture is divided into two layers overall: the caching layer and the storage layer.
Storage Layer
Due to the historical reasons mentioned above, TAO uses MySQL as the storage layer.
Therefore, TAO’s external APIs are eventually translated into MySQL statements that act on the storage layer, but the queries to MySQL are relatively simple. Of course, the storage layer could also use a NoSQL storage engine like LevelDB, in which case the queries would be translated into prefix traversals. Of course, choosing a storage engine depends not only on how convenient the API translation is, but also on non-API factors such as data backup, bulk import/export, and multi-replica synchronization.
A single MySQL service certainly cannot store all TAO data, so TAO uses a MySQL cluster to support the storage layer. To distribute data evenly across multiple MySQL machines, TAO uses consistent hashing to logically shard the data. Each shard is stored in one MySQL database. Each Object is associated with a shard when created, and the shard_id is embedded into the object_id, so the object’s shard will not change throughout its lifecycle.
Specifically, the data stored in MySQL mainly consists of two tables: a node table and an edge table. Nodes and their out-edges are stored in the same MySQL database to minimize the cost of association queries. All node attributes are serialized into a column called data when saved. This allows Objects of different types to be stored in one table. Edges are saved similarly to nodes, but an additional index is created on the id1, atype, andtime fields to facilitate range queries on out-edges based on a specific node. In addition, to avoid the high overhead of querying the count of associations, an additional table is used to store the count of associations.
Cache Layer
Read-through and write-through. TAO’s storage layer implements all external APIs, completely shielding the storage layer from clients. That is, Clients only interact with the caching layer, and the caching layer is responsible for synchronizing data to the storage layer. The caching layer is also composed of multiple cache servers; a group of cache servers that can serve any TAO request is called a Tier. A single request is routed to a single cache server and does not span multiple servers.
Caching strategy uses the classic LRU. It is worth mentioning that because TAO’s edges are bidirectional by default, when a Client writes an edge, the caching layer is responsible for turning it into two directed edges — an out-edge and an inverse edge — but TAO does not guarantee their atomicity. Failures will delete intermediate results through garbage collection.
Two-layer architecture. Each logical shard in TAO is basically homogeneous. The caching layer of each logical shard consists of a group of cache servers, composed of a single Leader cache server and a group of Follower cache servers.
Among them, Follower cache servers are the outer layer, and Leader servers are the inner layer. All clients only interact with Followers. Follower cache servers themselves are only responsible for read requests; if a read miss occurs or there is a write request, it is forwarded to the corresponding Leader cache server.
If read request load continues to increase, you only need to scale out the Follower cache servers.
If certain objects are accessed significantly more than others, TAO will identify them by recording access frequency, then perform client-side caching, and maintain consistency through version numbers.
Consistency. After receiving parallel write requests from multiple Followers, the Leader will sequence them, serialize them, and then perform synchronous reads and writes to the storage layer before returning. For write requests, it will also asynchronously notify other Follower servers to update the corresponding data. Therefore, TAO can ultimately only provide eventual consistency guarantees. The benefit of this is high throughput for read requests.
Multi-region extension. Because TAO’s read request frequency is about 25 times its write frequency, and a single data center cannot satisfy Facebook’s global scenarios. Therefore, TAO uses a primary-secondary architecture overall: two data centers each deploy a storage layer + caching layer as primary and secondary (Primary-Secondary). All write requests must be routed from the secondary data center’s Leader Cache to the primary data center (see figure above), and then the primary data center’s storage layer asynchronously syncs back to the secondary data center. However, the secondary data center’s Leader Cache does not wait for the local storage layer to sync back data before updating and notifying Followers to Refill from itself. TAO’s design maximizes the chance that a read request is satisfied within a single data center, at the cost of clients potentially reading stale data. That is, it sacrifices consistency to reduce request latency and improve throughput.
Consistency
When making trade-offs between consistency and availability, TAO chose the latter. For high availability and extreme performance, it chose a weaker consistency model — eventual consistency. Because in most of Facebook’s scenarios, unavailability is worse than incorrectness. In most common scenarios, TAO can achieve stronger read-after-write consistency.
For the same piece of data in TAO, first, it is backed up in a Master-Slave Region; second, in the same Region, a two-layer Leader-Follower Cache is used. During updates, data at different locations is not synchronized, which causes data inconsistency. In TAO, after an update, given enough time, all data replicas will converge to consistency and reflect the latest update. Usually, this time interval does not exceed 1s. This is acceptable in most scenarios at Facebook.
For those scenarios with special consistency requirements, the application layer can mark requests as critical. When TAO receives a request with this mark, it will forward it to the Master Region for processing, thereby obtaining strong consistency.
References
[1] TAO paper: https://www.usenix.org/system/files/conference/atc13/atc13-bronson.pdf
[2] Facebook Engineering Blog, TAO — The Power of the Graph: https://engineering.fb.com/2013/06/25/core-data/tao-the-power-of-the-graph/
[3] meetup TAO: https://www.notion.so/Meetup-1-Facebook-TAO-28e88836a3f649ba9b3e3ea83858c593
[4] Stanford 6.S897 slides: https://cs.stanford.edu/~matei/courses/2015/6.S897/slides/tao.pdf

